CVPR 2025 | Magma:多模态AI智能体的基础模型
编辑:陈萍萍的公主@一点人工一点智能

CVPR 2025 | Magma:多模态AI智能体的基础模型论文提出\x26quot;三位一体\x26quot;的设计理念使Magma区别于传统的视觉-语言模型(VL模型),具备了真正的空间-时间智能(spatial-temporal intelligence)。![]() https://mp.weixin.qq.com/s/ko5mDBvED671K9Z8tRqXPw
https://mp.weixin.qq.com/s/ko5mDBvED671K9Z8tRqXPw
01 简介
论文开篇提出了一个雄心勃勃的愿景——开发能够同时理解多模态输入并在数字和物理世界中执行任务的自主AI智能体。作者团队来自微软研究院、马里兰大学等知名机构,他们提出的Magma模型代表了当前多模态AI研究的前沿方向。开篇概括了Magma模型的三大核心能力:多模态理解(Multimodal Understanding)、多模态动作预测(Multimodal Action Prediction)以及在这两者基础上实现的智能体任务执行能力。这种"三位一体"的设计理念使Magma区别于传统的视觉-语言模型(VL模型),具备了真正的空间-时间智能(spatial-temporal intelligence)。

当前大多数VLA模型虽然冠以"通用"之名,但实际上仍是为特定任务或环境(如2D数字界面或3D物理世界)单独训练的,这种割裂的训练方式严重限制了模型的泛化能力。更为关键的是,作者指出现有模型在追求任务特定动作策略时,往往以牺牲通用多模态理解能力为代价,形成了所谓的"能力权衡"困境。Magma的创新之处在于,它通过统一的基础模型架构,同时保持了强大的多模态理解能力和跨领域的动作执行能力,这种双重能力的协同效应是本文最重要的理论贡献之一。
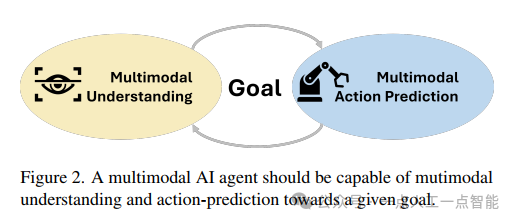
文中提出的Set-of-Mark (SoM)和Trace-of-Mark (ToM)技术是解决多模态理解(主要是语义的)与动作执行(主要是空间的)之间鸿沟的关键。SoM通过在图像中标记可操作对象(如GUI中的可点击按钮),为模型提供了动作基础;而ToM则通过在视频中标记物体运动轨迹(如人手或机械臂的运动轨迹),增强了模型的动作规划能力。这两种技术的协同作用使得模型能够从海量的未标记视频数据中学习空间-时间智能,这是传统监督学习方法难以实现的。作者特别强调,Magma是首个能够在数字和物理环境中同时处理多模态输入理解、动作基础与规划,并适应下游未见任务的基础模型,这一创新定位为其在AI智能体领域确立了独特地位。
02 相关工作
论文对相关工作的梳理展现了研究团队对领域发展脉络的深刻把握。他们将现有研究划分为三大类:大型多模态模型(LMMs)、数字世界中的UI智能体以及机器人领域的视觉-语言-动作(VLA)模型,这种分类方式本身就反映了当前多模态AI研究的三个主要方向。
在LMMs部分,作者回顾了从纯文本大模型(如GPT系列、Llama)到视觉-语言模型的演进过程。特别值得注意的是,他们指出了当前区域级LMMs和视频LMMs的发展趋势,这与Magma处理空间标记(SoM)和时间轨迹(ToM)的能力形成了呼应。对于UI智能体,论文系统比较了两类方法:直接预测下一个动作的端到端模型(如Pixel2Act、WebGUM)与利用现有多模态模型(如GPT-4V)的方法,这种对比分析为Magma在UI任务上的创新提供了理论铺垫。
机器人VLA模型部分可能是最具洞察力的文献综述。作者不仅分析了RT-2、Open-VLA等代表性工作,还特别强调了当前模型在动作表示上的局限性——要么预测离散化的机器人动作token,要么预测潜在的VQVAE token。这些方法虽然有效,但缺乏对空间-时间关系的显式建模。Magma提出的SoM和ToM技术正是针对这一局限,通过视觉标记和轨迹预测来增强模型的空间-时间感知能力,这一创新点在与OpenVLA等模型的对比实验中得到了验证。
值得注意的是,作者在相关工作部分表现出了难得的批判性思维。他们不仅列举了已有成果,还明确指出了三个研究方向上存在的共性问题:环境特定性、泛化能力不足以及多模态理解与动作执行之间的不平衡。这些问题陈述实际上为Magma的创新价值提供了反向论证,使得论文的贡献定位更加清晰有力。
03 方法框架:SoM与ToM的统一建模范式
Magma方法部分的核心创新在于提出了一个统一框架,将看似迥异的多模态理解与动作执行任务整合到一个模型中。从技术角度看,这一整合面临两大挑战:不同任务的输入输出存在显著领域差异;现有视觉-语言-动作数据在数量和多样性上受限。论文提出的解决方案既巧妙又实用,体现了作者团队深厚的研究功力。
问题形式化部分给出了智能体π的数学定义(公式1):,其中输出O可以是语言token或空间token。这一公式的精妙之处在于其通用性——它统一了UI导航(输出包含动作类型和位置坐标)、机器人操作(输出6自由度位移)和多模态理解(纯文本描述)等不同任务。作者采用将各种输出统一转化为文本token的策略,既简化了模型设计,又保留了各任务的特殊性。
![]()
SoM(Set-of-Mark)技术的提出是针对动作基础问题的创新解决方案。给定图像观测It,算法首先提取K个候选可操作区域,然后用数字标记覆盖这些区域得到标记图像
(公式2)。这一过程的关键在于,它将原本困难的坐标回归问题转化为相对简单的标记选择问题,大幅降低了动作基础的学习难度。图3展示的实例表明,SoM适用于UI截图、机器人操作和人类视频等多种场景,这种跨领域的适用性正是Magma作为基础模型的核心优势。
![]()

ToM(Trace-of-Mark)技术则是对SoM在时间维度上的扩展,体现了作者对时序动态的深刻理解。给定视频帧序列,算法预测未来l帧中标记的轨迹
(公式3)。这一设计的精妙之处在于:一方面,它强制模型理解视频中的时间动态并"预见"未来状态;另一方面,相比预测整个下一帧(如世界模型常做的那样),预测轨迹点只需要少量token就能捕捉长时程的动作相关对象动态。论文中提到的可靠性验证(精度达0.89)为这一技术的有效性提供了坚实支撑。
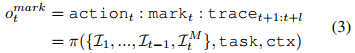

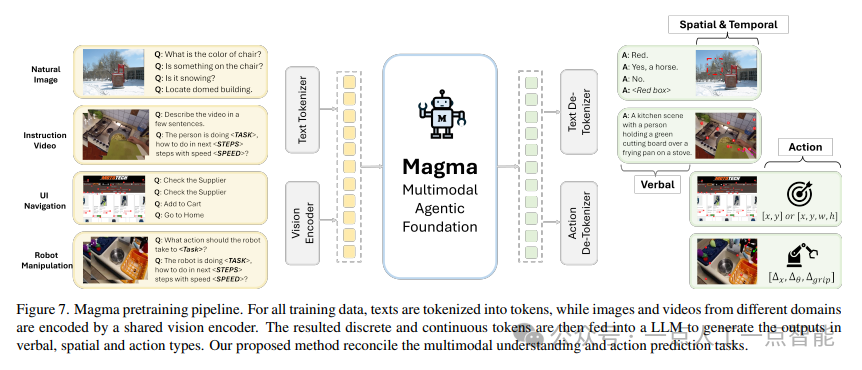
模型架构方面,作者选择了ConvNeXt作为视觉编码器,这一选择基于其对任意图像分辨率的原生支持,这对处理高分辨率UI截图(最高达2000像素)尤为重要。语言模型则采用LLaMA-3-8B,整体架构(图7)遵循了当前VLMs的常见设计,但通过SoM和ToM的桥梁作用,实现了多模态理解与动作执行的协同训练。这种在传统架构中注入创新元素的策略,既保证了模型的稳定性,又实现了性能的突破。
![]()
04 实验设计
研究团队不仅在标准基准测试上验证模型性能,还设计了丰富的消融实验来剖析各技术组件的贡献,这种多层次评估策略大大增强了研究结果的可信度。
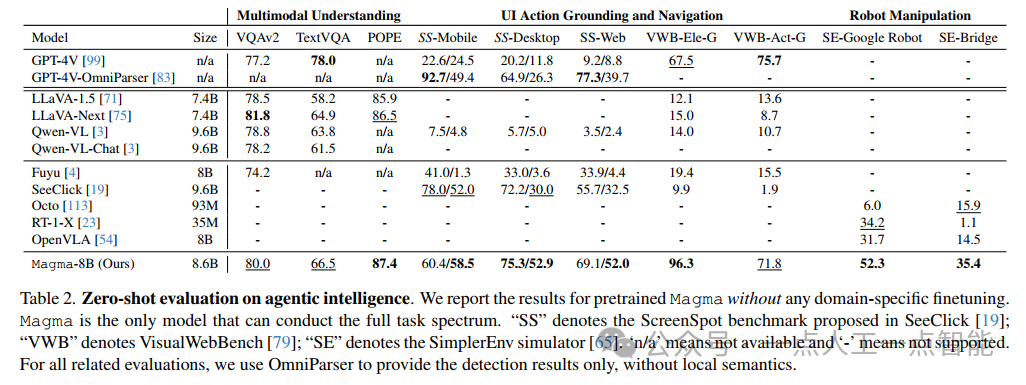
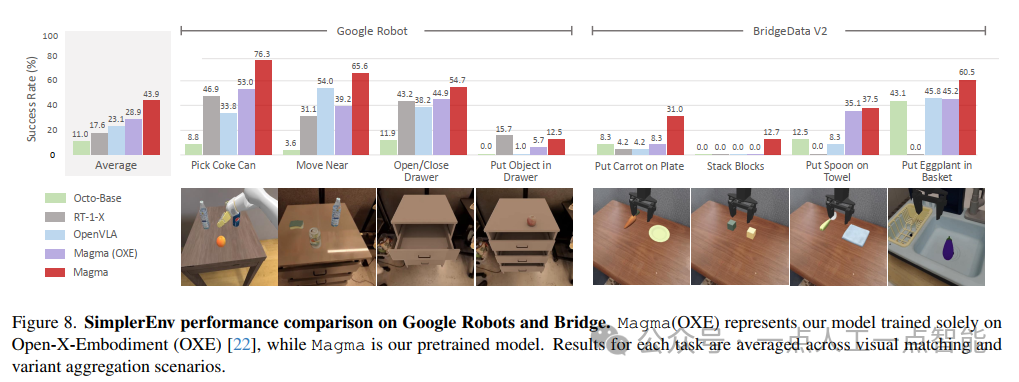
零样本评估部分涵盖了UI动作基础与导航、机器人操作以及通用多模态理解三大类任务。表2展示的结果令人印象深刻:在ScreenSpot基准上,Magma的移动设备准确率达到60.4%,远超GPT-4V+OmniParser的22.6%;在VisualWebBench上的动作基础任务更是达到96.3%的准确率。机器人操作方面,Magma在SimpleEnv模拟器上的表现尤为突出(图8),平均成功率比第二名OpenVLA高出19.6%,在"Put Object in Drawer"等复杂任务上实现了从零到一的突破。这些结果强有力地证明了SoM和ToM技术对提升空间智能的有效性。
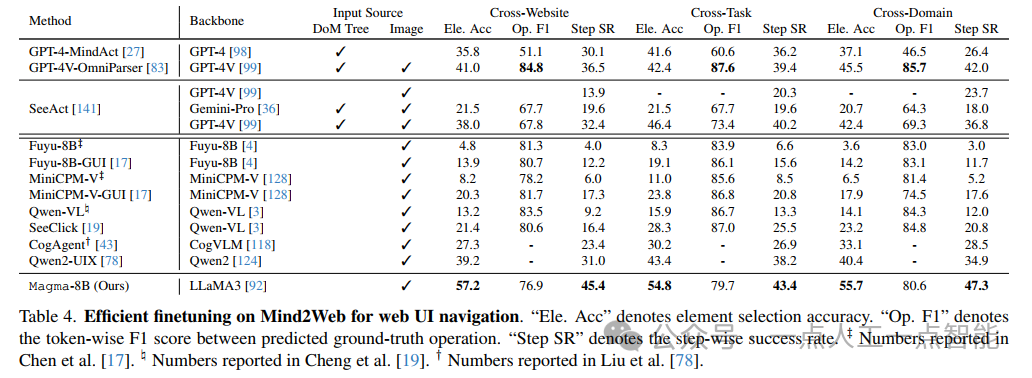
高效微调实验进一步展示了Magma的实用价值。在Mind2Web数据集(表4)上,经过微调的Magma在跨网站、跨任务和跨领域三个子任务中全面领先,元素选择准确率达到57.2%,比基于GPT-4V的方法高出近20个百分点。AITW移动UI导航任务(表5)的结果同样令人瞩目,Magma在"GoogleApps"等复杂场景下达到62.7%的准确率。这些结果表明,Magma不仅是一个强大的基础模型,也能通过少量微调快速适应特定下游任务。
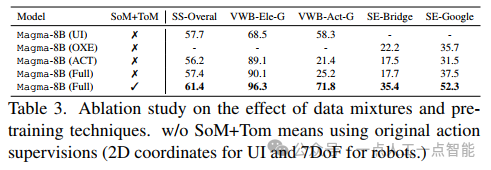
消融研究(表3)是论文中最具方法论价值的部分之一。作者系统地比较了不同数据组合和训练技术的效果,得出了几个关键结论:
1)简单合并UI和机器人数据反而会损害性能,证实了不同领域间的负迁移现象;
2)加入视频数据能略微提升性能,但仅靠视频叙述只能增强语言智能;
3)只有当应用SoM和ToM统一接口后,模型才能有效从异构数据中同时学习语言和空间智能。
这些发现不仅验证了Magma设计的合理性,也为后续研究提供了宝贵经验。
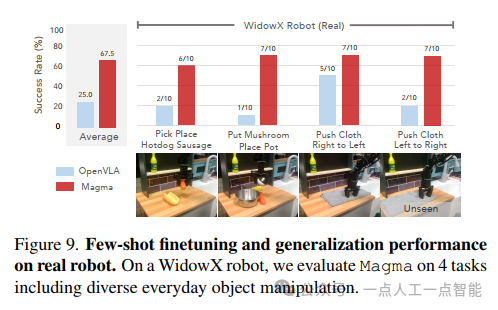
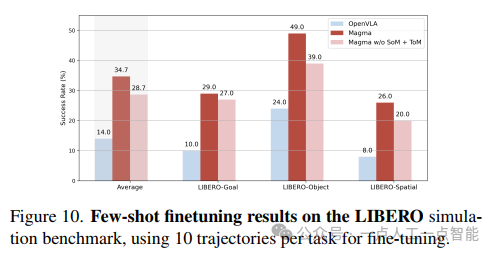
机器人操作的真实世界评估(图9)将研究推向了高潮。在WidowX 250机器人上的实验显示,Magma在"Pick Place Hotdog Sausage"等复杂任务上的成功率显著高于OpenVLA。特别值得注意的是,在未包含在微调数据集中的"Push Cloth Left to Right"任务上,Magma仍表现出强大的泛化能力,这说明通过SoM和ToM学习到的空间表示具有可迁移性。LIBERO基准上的少量样本微调结果(图10)进一步强化了这一结论,Magma在仅10条轨迹微调后就达到了较高的平均成功率。

05 创新价值
论文深入剖析了Magma的创新价值。作者从模型能力、技术贡献和社会责任三个维度进行了全面反思。
Magma的创新性主要体现在三个方面:首先,它首次将多模态理解与空间-时间推理能力整合到一个基础模型中,打破了数字与物理世界的界限;其次,SoM和ToM技术的提出为解决动作基础与规划问题提供了新思路;最后,大规模预训练数据集的构建方法为多模态学习提供了宝贵资源。这些贡献不仅具有学术价值,也为构建实用化AI智能体奠定了基础。
作者详细讨论了训练数据中可能存在的偏见问题,特别是教学视频中身份和活动分布的不均衡性。他们承诺在发布模型时会加入必要的免责声明,并明确限定了模型的推荐使用场景(受控的Web UI和Android模拟器,配备机械臂的封闭环境)。
从更广阔的视角看,Magma代表了AI智能体研究的一个重要转折点——从单一任务专家转向通用多模态代理。论文中强调的"语言智能"与"空间-时间智能"的协同,或许预示了下一代AI系统的发展方向。随着SoM和ToM技术的不断完善,我们有望看到更加强大、更加通用的AI智能体出现,这将从根本上改变人机交互的方式。
06 技术细节剖析
深入研读论文的附录部分,我们可以发现Magma在算法实现和工程优化上的诸多创新,这些细节往往决定着研究的可复现性和实际应用价值。
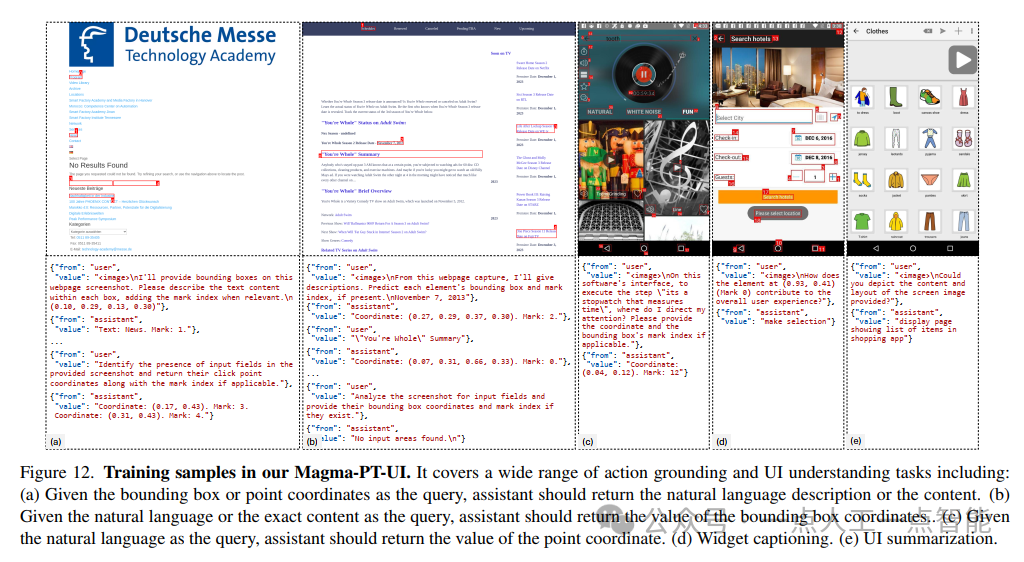
SoM生成算法(算法1)展现了作者团队对UI结构的深刻理解。对于网页截图,他们根据元素类型(如h1、a、button等)差异化采样,既保证了关键交互元素(如输入框)的全面覆盖,又避免了标记过度拥挤的问题。移动端处理则结合RICO数据集和OCR技术丰富了边界框注释,这种多层次的数据增强策略显著提升了模型的泛化能力。图12展示的训练样本清晰地呈现了SoM在UI理解任务中的应用方式,包括文本到坐标、坐标到文本、部件描述等多种任务类型。
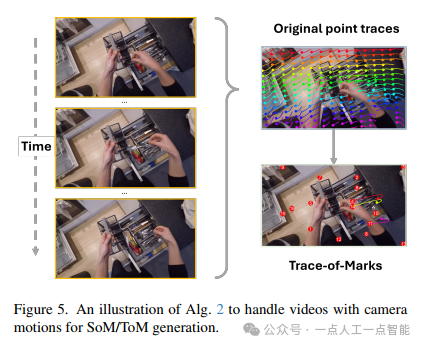
ToM生成算法(算法2)的设计则体现了对视频时序特性的精准把握。通过设置网格大小s、全局运动阈值η和前景阈值ε等参数,算法能够有效区分由任务驱动的前景运动和相机移动等背景干扰。图5展示的消除全局运动效果图直观地验证了单应变换的有效性,这种对技术细节的考究是Magma成功的关键。值得注意的是,作者还定量验证了CoTracker在YouCook2-BB数据集上的跟踪精度(0.89),这种对基础工具可靠性的验证展现了一流的工程素养。
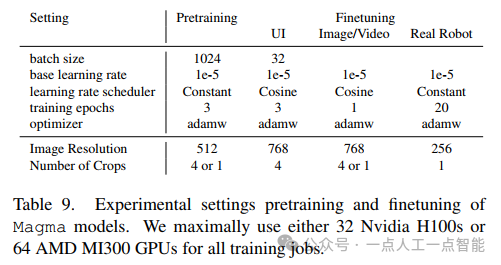
模型训练方面,表9总结的超参数设置反映了大规模多模态训练的实践经验。采用512作为基础图像尺寸,对UI和图像数据使用4种裁剪,而对视频和机器人数据使用1种裁剪,这种差异化的处理既考虑了计算效率,又兼顾了不同数据类型的特性。预训练阶段使用恒定的学习率1e-5,而微调阶段改用余弦调度,这种调整显然基于大量实验验证。值得一提的是,作者团队在H100和MI300X GPU上的分布式训练经验对于后续研究具有重要参考价值。
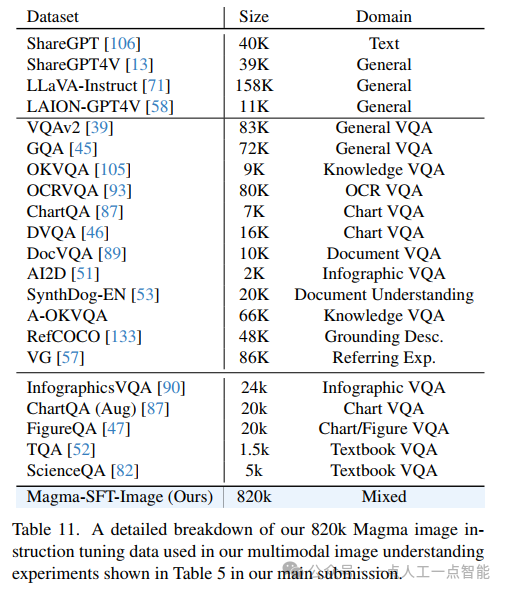
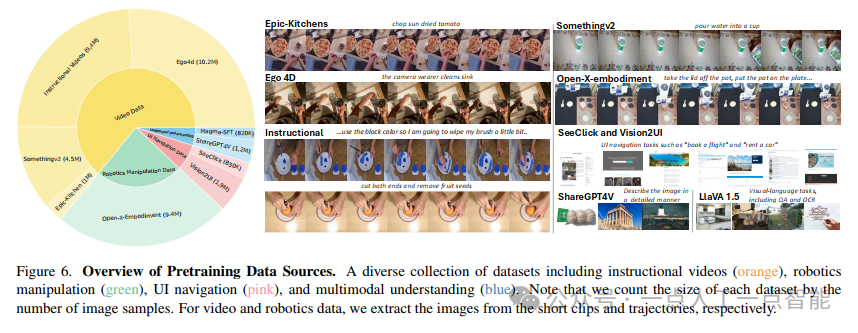
数据预处理流水线(图7)是另一个工程亮点。通过统一的视觉编码器处理不同来源的图像和视频,再与语言token一起输入LLM,这种设计在保持扩展性的同时降低了实现复杂度。附录中详细列出的820K图像指令微调数据(表11)和178K视频指令数据则为后续研究提供了宝贵的基准资源。特别是对ChartQA、DocVQA等专业数据集的包含,显著增强了模型在OCR和图表理解方面的能力。