强化学习 A2C算法
3.actor-critic方法
3.1 Reinforce 算法,也称为蒙特卡洛策略梯度。蒙特卡洛方差
第一节介绍了DQN
在上一节基于策略的方法中,我们的目标是直接优化策略,而无需使用价值函数。更准确地说,Reinforce 是 基于策略的方法 的一个子类,称为 策略梯度方法。这个子类通过使用梯度上升估计最优策略的权重来直接优化策略。
我们看到 Reinforce 运行良好。然而,因为我们使用蒙特卡洛采样来估计回报(我们使用整个 episode 来计算回报),所以我们在策略梯度估计中存在显着的方差。
请记住,策略梯度估计是回报增加最快的方向。换句话说,如何更新我们的策略权重,以便导致良好回报的动作有更高的概率被采取。蒙特卡洛方差,因为我们需要大量样本来缓解它,导致训练速度变慢。
为什么方差大,因为各个轨迹样本差异比较大,更新梯度也会比较乱,不稳定,样本足够多求平均方差会小一些。
!## 3.1 Reinforce 算法,也称为蒙特卡洛策略梯度。蒙特卡洛方差
在基于策略的方法中,我们的目标是直接优化策略,而无需使用价值函数。更准确地说,Reinforce 是 基于策略的方法 的一个子类,称为 策略梯度方法。这个子类通过使用梯度上升估计最优策略的权重来直接优化策略。
我们看到 Reinforce 运行良好。然而,因为我们使用蒙特卡洛采样来估计回报(我们使用整个 episode 来计算回报),所以我们在策略梯度估计中存在显着的方差。
请记住,策略梯度估计是回报增加最快的方向。换句话说,如何更新我们的策略权重,以便导致良好回报的动作有更高的概率被采取。蒙特卡洛方差,因为我们需要大量样本来缓解它,导致训练速度变慢。
为什么方差大,因为各个轨迹样本差异比较大,更新梯度也会比较乱,不稳定,样本足够多求平均方差会小一些。


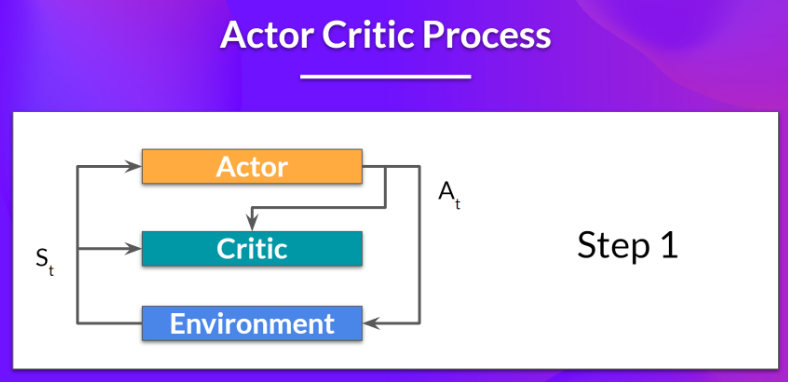
3.2 A2C方法 advantage actor-critic 主要步骤
-
actor我们的策略接收state并输出一个动作action
-
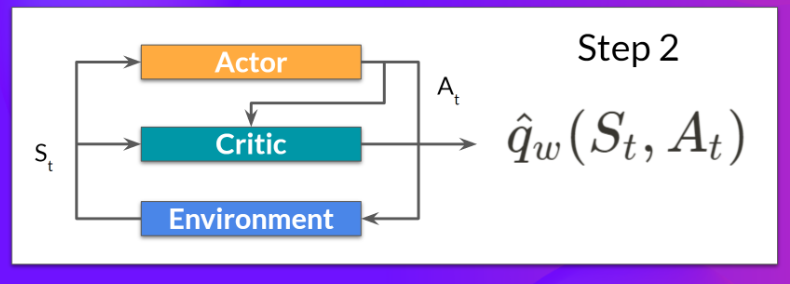
critic并使用state和action ,计算在该状态下采取该动作的价值:Q 值。
-
env给出 S_t+1 和R_t+1

-
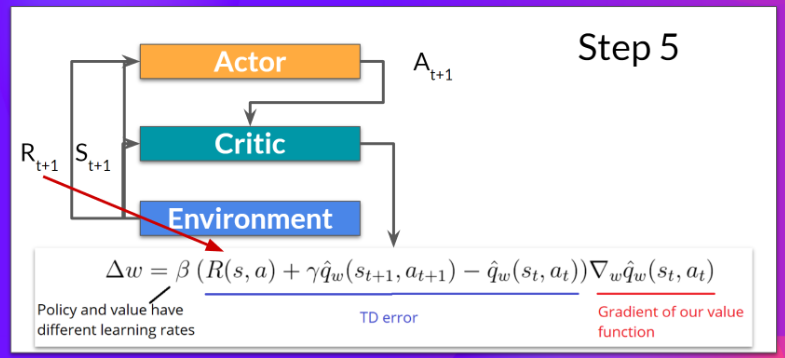
actor更新:策略梯度方法如下图, 如果是advantage ac方法,q会被替换为优势函数A(s,a)

-
critic更新:注意TD error计算决定了更新的方向
3.3 A2C方法loss



可以看出 A2C方法将上一节的策略梯度方法 拆分为2个网络,2个loss函数。更新更慢一些更稳定一些。策略梯度直接用最大化 概率乘回报。 A2C方法 actor最大化 概率乘预测的价值, 同时有个critic网络更新状态价值。

参考代码逻辑:
def compute_loss(agent, states, actions, rewards, next_states, dones, gamma=0.99):# 获取策略概率和状态价值action_probs, state_values = agent(states) # (B, action_dim), (B, 1)_, next_state_values = agent(next_states) # (B, 1)# 计算优势函数td_targets = rewards + gamma * next_state_values * (1 - dones) # (B, 1)advantages = td_targets.detach() - state_values # (B, 1)# 策略损失dist = Categorical(action_probs)log_probs = dist.log_prob(actions) # (B,)policy_loss = -(log_probs * advantages.squeeze()).mean() # scalar# 价值损失value_loss = F.mse_loss(state_values, td_targets.detach()) # scalar# 熵正则化entropy = -torch.sum(action_probs * torch.log(action_probs), dim=-1).mean() # scalar# 总损失total_loss = policy_loss + 0.5 * value_loss - 0.01 * entropyreturn total_loss, policy_loss, value_loss, entropy

3.4 A2C 核心代码原理
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categoricalclass ActorCritic(nn.Module):def __init__(self, state_dim, action_dim, hidden_dim=64):super(ActorCritic, self).__init__()# 共享的特征提取层self.fc1 = nn.Linear(state_dim, hidden_dim)# Actor层 - 输出动作概率self.fc_actor = nn.Linear(hidden_dim, action_dim)# Critic层 - 输出状态价值self.fc_critic = nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc1(x))# 动作概率 (batch_size, action_dim)action_probs = F.softmax(self.fc_actor(x), dim=-1)# 状态价值 (batch_size, 1)state_values = self.fc_critic(x)return action_probs, state_valuesdef compute_returns(rewards, gamma=0.99):"""计算折扣回报参数:rewards: 奖励序列 [r1, r2, ..., rT]gamma: 折扣因子返回:returns: 折扣回报序列 [R1, R2, ..., RT]"""R = 0returns = []for r in reversed(rewards):R = r + gamma * Rreturns.insert(0, R)return returnsdef a2c_update(agent, optimizer, states, actions, rewards, next_states, dones, gamma=0.99):"""A2C算法更新步骤参数:agent: ActorCritic网络r: 优化器states: 状态序列 (T, state_dim)actions: 动作序列 (T,)rewards: 奖励序列 (T,)next_states: 下一个状态序列 (T, state_dim)dones: 终止标志序列 (T,)gamma: 折扣因子"""# 转换为tensorstates = torch.FloatTensor(states) # (T, state_dim)actions = torch.LongTensor(actions) # (T,)rewards = torch.FloatTensor(rewards) # (T,)next_states = torch.FloatTensor(next_states) # (T, state_dim)dones = torch.FloatTensor(dones) # (T,)# 计算状态价值和下一个状态价值_, state_values = agent(states) # (T, 1)_, next_state_values = agent(next_states) # (T, 1)# 计算TD目标td_targets = rewards + gamma * next_state_values * (1 - dones) # (T, 1)# 计算优势函数advantages = td_targets.detach() - state_values # (T, 1)# 计算动作概率action_probs, _ = agent(states) # (T, action_dim)dist = Categorical(action_probs)# 计算策略梯度损失policy_loss = -dist.log_prob(actions) * advantages.squeeze() # (T,)policy_loss = policy_loss.mean()# 计算价值函数损失value_loss = F.mse_loss(state_values, td_targets.detach())# 熵正则化entropy_loss = -torch.sum(action_probs * torch.log(action_probs), dim=-1).mean() # scalar# 总损失loss = policy_loss + 0.5 * value_loss - 0.01 * entropy_loss # 0.5是价值损失系数# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()return policy_loss.item(), value_loss.item(), entropy_loss.item()
训练脚本
import gym
import numpy as np
from collections import deque
import matplotlib.pyplot as plt# 创建环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0] # 4
action_dim = env.action_space.n # 2# 初始化A2C智能体
agent = ActorCritic(state_dim, action_dim)
optimizer = optim.Adam(agent.parameters(), lr=0.001)# 训练参数
num_episodes = 1000
max_steps = 1000
gamma = 0.99# 训练循环
episode_rewards = []
for episode in range(num_episodes):state = env.reset()episode_reward = 0episode_states = []episode_actions = []episode_rewards = []episode_next_states = []episode_dones = []for step in range(max_steps):# 选择动作state_tensor = torch.FloatTensor(state).unsqueeze(0) # (1, state_dim)action_probs, _ = agent(state_tensor) # (1, action_dim)dist = Categorical(action_probs)action = dist.sample().item() # scalar# 执行动作next_state, reward, done, _ = env.step(action)# 存储经验episode_states.append(state)episode_actions.append(action)episode_rewards.append(reward)episode_next_states.append(next_state)episode_dones.append(done)state = next_stateepisode_reward += reward if done:break# 更新网络policy_loss, value_loss = a2c_update(agent, optimizer,episode_states, episode_actions, episode_rewards,episode_next_states, episode_dones, gamma)# 记录奖励episode_rewards.append(episode_reward)# 打印训练信息if (episode + 1) % 10 == 0:avg_reward = np.mean(episode_rewards[-10:])print(f"Episode {episode+1}, Avg Reward: {avg_reward:.1f}, Policy Loss: {policy_loss:.3f}, Value Loss: {value_loss:.3f}")# 绘制训练曲线
plt.plot(episode_rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('A2C Training Performance on CartPole')
plt.show()# 测试训练好的智能体
def test_agent(agent, env, num_episodes=10):for episode in range(num_episodes):state = env.reset()total_reward = 0done = Falsewhile not done:state_tensor = torch.FloatTensor(state).unsqueeze(0)with torch.no_grad():action_probs, _ = agent(state_tensor)action = torch.argmax(action_probs).item()next_state, reward, done, _ = env.step(action)total_reward += rewardstate = next_stateprint(f"Test Episode {episode+1}: Total Reward = {total_reward}")test_agent(agent, env)
也可以封装成class
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
from collections import deque
import gymclass A2CNetwork(nn.Module):"""A2C网络架构,包含共享特征提取层、Actor头和Critic头"""def __init__(self, input_dim, action_dim, hidden_dim=256):super(A2CNetwork, self).__init__()# 共享特征提取层# input_dim: 状态空间维度,例如(4,)表示4维状态# hidden_dim: 隐藏层维度self.shared_layers = nn.Sequential(nn.Linear(input_dim, hidden_dim), # shape: (batch_size, input_dim) -> (batch_size, hidden_dim)nn.ReLU(),nn.Linear(hidden_dim, hidden_dim), # shape: (batch_size, hidden_dim) -> (batch_size, hidden_dim)nn.ReLU())# Actor头:输出动作概率分布# action_dim: 动作空间维度,例如2表示2个离散动作self.actor_head = nn.Linear(hidden_dim, action_dim) # shape: (batch_size, hidden_dim) -> (batch_size, action_dim)# Critic头:输出状态价值self.critic_head = nn.Linear(hidden_dim, 1) # shape: (batch_size, hidden_dim) -> (batch_size, 1)def forward(self, state):"""前向传播Args:state: 状态张量,shape: (batch_size, input_dim)Returns:action_probs: 动作概率分布,shape: (batch_size, action_dim)state_value: 状态价值,shape: (batch_size, 1)"""# 特征提取features = self.shared_layers(state) # shape: (batch_size, hidden_dim)# Actor输出:动作概率分布action_logits = self.actor_head(features) # shape: (batch_size, action_dim)action_probs = F.softmax(action_logits, dim=-1) # shape: (batch_size, action_dim)# Critic输出:状态价值state_value = self.critic_head(features) # shape: (batch_size, 1)return action_probs, state_valueclass A2CAgent:"""A2C智能体实现"""def __init__(self, state_dim, action_dim, lr=3e-4, gamma=0.99, entropy_coef=0.01, value_coef=0.5):"""初始化A2C智能体Args:state_dim: 状态空间维度action_dim: 动作空间维度lr: 学习率gamma: 折扣因子entropy_coef: 熵正则化系数value_coef: 价值损失权重"""self.gamma = gammaself.entropy_coef = entropy_coefself.value_coef = value_coef# 创建网络self.network = A2CNetwork(state_dim, action_dim)self.optimizer = optim.Adam(self.network.parameters(), lr=lr)# 存储轨迹数据self.reset_trajectory()def reset_trajectory(self):"""重置轨迹存储"""self.states = [] # 状态序列,每个元素shape: (state_dim,)self.actions = [] # 动作序列,每个元素shape: ()self.rewards = [] # 奖励序列,每个元素shape: ()self.log_probs = [] # 对数概率序列,每个元素shape: ()self.values = [] # 状态价值序列,每个元素shape: ()def select_action(self, state):"""根据当前策略选择动作Args:state: 当前状态,shape: (state_dim,)Returns:action: 选择的动作,标量log_prob: 动作的对数概率,标量value: 状态价值,标量"""# 转换为张量并添加batch维度state_tensor = torch.FloatTensor(state).unsqueeze(0) # shape: (1, state_dim)# 前向传播action_probs, state_value = self.network(state_tensor)# action_probs shape: (1, action_dim)# state_value shape: (1, 1)# 创建分布并采样动作dist = torch.distributions.Categorical(action_probs)action = dist.sample() # shape: (1,)log_prob = dist.log_prob(action) # shape: (1,)return action.item(), log_prob.squeeze(), state_value.squeeze()def store_transition(self, state, action, reward, log_prob, value):"""存储一步转移Args:state: 状态,shape: (state_dim,)action: 动作,标量reward: 奖励,标量log_prob: 对数概率,标量张量value: 状态价值,标量张量"""self.states.append(state)self.actions.append(action)self.rewards.append(reward)self.log_probs.append(log_prob)self.values.append(value)def compute_returns_and_advantages(self, next_value=0):"""计算回报和优势函数Args:next_value: 下一个状态的价值(终止状态为0)Returns:returns: 回报序列,shape: (trajectory_length,)advantages: 优势序列,shape: (trajectory_length,)"""trajectory_length = len(self.rewards)# 计算回报(从后往前)returns = torch.zeros(trajectory_length)R = next_value # 从终止状态开始for t in reversed(range(trajectory_length)):R = self.rewards[t] + self.gamma * R # R = r_t + γ * R_{t+1}returns[t] = R# 转换values为张量values = torch.stack(self.values) # shape: (trajectory_length,)# 计算优势函数:A(s,a) = R - V(s)advantages = returns - values # shape: (trajectory_length,)return returns, advantagesdef update(self, next_value=0):"""更新网络参数Args:next_value: 下一个状态的价值"""if len(self.rewards) == 0:return# 计算回报和优势returns, advantages = self.compute_returns_and_advantages(next_value)# 转换为张量states = torch.FloatTensor(np.array(self.states)) # shape: (trajectory_length, state_dim)actions = torch.LongTensor(self.actions) # shape: (trajectory_length,)log_probs = torch.stack(self.log_probs) # shape: (trajectory_length,)# 前向传播获取当前策略下的概率和价值action_probs, state_values = self.network(states)# action_probs shape: (trajectory_length, action_dim)# state_values shape: (trajectory_length, 1)state_values = state_values.squeeze() # shape: (trajectory_length,)# 计算当前策略下的对数概率和熵dist = torch.distributions.Categorical(action_probs)new_log_probs = dist.log_prob(actions) # shape: (trajectory_length,)entropy = dist.entropy().mean() # 标量,策略熵# 计算损失# Actor损失:策略梯度损失actor_loss = -(new_log_probs * advantages.detach()).mean() # 标量# Critic损失:价值函数损失critic_loss = F.mse_loss(state_values, returns.detach()) # 标量# 总损失total_loss = actor_loss + self.value_coef * critic_loss - self.entropy_coef * entropy# 反向传播和优化self.optimizer.zero_grad()total_loss.backward()# 梯度裁剪,防止梯度爆炸torch.nn.utils.clip_grad_norm_(self.network.parameters(), max_norm=0.5)self.optimizer.step()# 重置轨迹self.reset_trajectory()return {'actor_loss': actor_loss.item(),'critic_loss': critic_loss.item(),'entropy': entropy.item(),'total_loss': total_loss.item()}import gym
import matplotlib.pyplot as plt
from collections import dequedef train_a2c(env_name='CartPole-v1', num_episodes=1000, max_steps=500, update_freq=5):"""训练A2C智能体Args:env_name: 环境名称num_episodes: 训练回合数max_steps: 每回合最大步数update_freq: 更新频率(每多少步更新一次)"""# 创建环境env = gym.make(env_name)state_dim = env.observation_space.shape[0] # 状态维度,例如CartPole为4action_dim = env.action_space.n # 动作维度,例如CartPole为2print(f"状态维度: {state_dim}, 动作维度: {action_dim}")# 创建智能体agent = A2CAgent(state_dim, action_dim)# 训练记录episode_rewards = [] # 每回合总奖励recent_rewards = deque(maxlen=100) # 最近100回合的奖励for episode in range(num_episodes):state = env.reset() # shape: (state_dim,)episode_reward = 0step_count = 0for step in range(max_steps):# 选择动作action, log_prob, value = agent.select_action(state)# 执行动作next_state, reward, done, _ = env.step(action)# next_state shape: (state_dim,)# reward: 标量# done: 布尔值# 存储转移agent.store_transition(state, action, reward, log_prob, value)episode_reward += rewardstep_count += 1state = next_state# 定期更新或回合结束时更新if step_count % update_freq == 0 or done:# 计算下一个状态的价值(如果回合结束则为0)if done:next_value = 0else:with torch.no_grad():next_state_tensor = torch.FloatTensor(next_state).unsqueeze(0)_, next_value = agent.network(next_state_tensor)next_value = next_value.squeeze().item()# 更新网络loss_info = agent.update(next_value)if loss_info and episode % 100 == 0:print(f"Episode {episode}, Step {step}: "f"Actor Loss: {loss_info['actor_loss']:.4f}, "f"Critic Loss: {loss_info['critic_loss']:.4f}, "f"Entropy: {loss_info['entropy']:.4f}")if done:break# 记录奖励episode_rewards.append(episode_reward)recent_rewards.append(episode_reward)# 打印进度if episode % 100 == 0:avg_reward = np.mean(recent_rewards)print(f"Episode {episode}, Average Reward: {avg_reward:.2f}, "f"Current Reward: {episode_reward:.2f}")env.close()return agent, episode_rewardsdef test_agent(agent, env_name='CartPole-v1', num_episodes=10, render=True):"""测试训练好的智能体Args:agent: 训练好的A2C智能体env_name: 环境名称num_episodes: 测试回合数render: 是否渲染"""env = gym.make(env_name)test_rewards = []for episode in range(num_episodes):state = env.reset()episode_reward = 0done = Falsewhile not done:if render:env.render()# 选择动作(测试时不需要存储轨迹)action, _, _ = agent.select_action(state)state, reward, done, _ = env.step(action)episode_reward += rewardtest_rewards.append(episode_reward)print(f"Test Episode {episode + 1}: Reward = {episode_reward}")env.close()avg_test_reward = np.mean(test_rewards)print(f"\n平均测试奖励: {avg_test_reward:.2f}")return test_rewardsdef plot_training_results(episode_rewards):"""绘制训练结果Args:episode_rewards: 每回合奖励列表"""plt.figure(figsize=(12, 4))# 原始奖励曲线plt.subplot(1, 2, 1)plt.plot(episode_rewards, alpha=0.6)plt.title('Episode Rewards')plt.xlabel('Episode')plt.ylabel('Reward')plt.grid(True)# 移动平均奖励曲线plt.subplot(1, 2, 2)window_size = 100if len(episode_rewards) >= window_size:moving_avg = []for i in range(window_size - 1, len(episode_rewards)):moving_avg.append(np.mean(episode_rewards[i - window_size + 1:i + 1]))plt.plot(range(window_size - 1, len(episode_rewards)), moving_avg)plt.title(f'Moving Average Rewards (window={window_size})')plt.xlabel('Episode')plt.ylabel('Average Reward')plt.grid(True)plt.tight_layout()plt.show()# 主函数
if __name__ == "__main__":print("开始训练A2C智能体...")# 训练智能体agent, rewards = train_a2c(env_name='CartPole-v1',num_episodes=1000,max_steps=500,update_freq=5)print("\n训练完成!开始测试...")# 测试智能体test_rewards = test_agent(agent, num_episodes=5, render=False)# 绘制结果plot_training_results(rewards)print("\n训练和测试完成!")
更多关于方差和偏差参考:Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning
https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565
在 RL 的情况下,方差现在是指有噪声但平均准确的值估计,而偏差是指稳定但不准确的值估计

3.2 A2C方法 advantage actor-critic 主要步骤
- actor我们的策略接收state并输出一个动作action

-
critic并使用state和action ,计算在该状态下采取该动作的价值:Q 值。

-
env给出 S_t+1 和R_t+1

-
actor更新:策略梯度方法如下图, 如果是advantage ac方法,q会被替换为优势函数A(s,a)

-
critic更新:注意TD error计算决定了更新的方向

3.3 A2C方法loss




参考代码逻辑:
def compute_loss(agent, states, actions, rewards, next_states, dones, gamma=0.99):# 获取策略概率和状态价值action_probs, state_values = agent(states) # (B, action_dim), (B, 1)_, next_state_values = agent(next_states) # (B, 1)# 计算优势函数td_targets = rewards + gamma * next_state_values * (1 - dones) # (B, 1)advantages = td_targets.detach() - state_values # (B, 1)# 策略损失dist = Categorical(action_probs)log_probs = dist.log_prob(actions) # (B,)policy_loss = -(log_probs * advantages.squeeze()).mean() # scalar# 价值损失value_loss = F.mse_loss(state_values, td_targets.detach()) # scalar# 熵正则化entropy = -torch.sum(action_probs * torch.log(action_probs), dim=-1).mean() # scalar# 总损失total_loss = policy_loss + 0.5 * value_loss - 0.01 * entropyreturn total_loss, policy_loss, value_loss, entropy

3.4 A2C 核心代码原理
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categoricalclass ActorCritic(nn.Module):def __init__(self, state_dim, action_dim, hidden_dim=64):super(ActorCritic, self).__init__()# 共享的特征提取层self.fc1 = nn.Linear(state_dim, hidden_dim)# Actor层 - 输出动作概率self.fc_actor = nn.Linear(hidden_dim, action_dim)# Critic层 - 输出状态价值self.fc_critic = nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc1(x))# 动作概率 (batch_size, action_dim)action_probs = F.softmax(self.fc_actor(x), dim=-1)# 状态价值 (batch_size, 1)state_values = self.fc_critic(x)return action_probs, state_valuesdef compute_returns(rewards, gamma=0.99):"""计算折扣回报参数:rewards: 奖励序列 [r1, r2, ..., rT]gamma: 折扣因子返回:returns: 折扣回报序列 [R1, R2, ..., RT]"""R = 0returns = []for r in reversed(rewards):R = r + gamma * Rreturns.insert(0, R)return returnsdef a2c_update(agent, optimizer, states, actions, rewards, next_states, dones, gamma=0.99):"""A2C算法更新步骤参数:agent: ActorCritic网络optimizer: 优化器states: 状态序列 (T, state_dim)actions: 动作序列 (T,)rewards: 奖励序列 (T,)next_states: 下一个状态序列 (T, state_dim)dones: 终止标志序列 (T,)gamma: 折扣因子"""# 转换为tensorstates = torch.FloatTensor(states) # (T, state_dim)actions = torch.LongTensor(actions) # (T,)rewards = torch.FloatTensor(rewards) # (T,)next_states = torch.FloatTensor(next_states) # (T, state_dim)dones = torch.FloatTensor(dones) # (T,)# 计算状态价值和下一个状态价值_, state_values = agent(states) # (T, 1)_, next_state_values = agent(next_states) # (T, 1)# 计算TD目标td_targets = rewards + gamma * next_state_values * (1 - dones) # (T, 1)# 计算优势函数advantages = td_targets.detach() - state_values # (T, 1)# 计算动作概率action_probs, _ = agent(states) # (T, action_dim)dist = Categorical(action_probs)# 计算策略梯度损失policy_loss = -dist.log_prob(actions) * advantages.squeeze() # (T,)policy_loss = policy_loss.mean()# 计算价值函数损失value_loss = F.mse_loss(state_values, td_targets.detach())# 熵正则化entropy_loss = -torch.sum(action_probs * torch.log(action_probs), dim=-1).mean() # scalar# 总损失loss = policy_loss + 0.5 * value_loss - 0.01 * entropy_loss # 0.5是价值损失系数# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()return policy_loss.item(), value_loss.item(), entropy_loss.item()
训练脚本
import gym
import numpy as np
from collections import deque
import matplotlib.pyplot as plt# 创建环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0] # 4
action_dim = env.action_space.n # 2# 初始化A2C智能体
agent = ActorCritic(state_dim, action_dim)
optimizer = optim.Adam(agent.parameters(), lr=0.001)# 训练参数
num_episodes = 1000
max_steps = 1000
gamma = 0.99# 训练循环
episode_rewards = []
for episode in range(num_episodes):state = env.reset()episode_reward = 0episode_states = []episode_actions = []episode_rewards = []episode_next_states = []episode_dones = []for step in range(max_steps):# 选择动作state_tensor = torch.FloatTensor(state).unsqueeze(0) # (1, state_dim)action_probs, _ = agent(state_tensor) # (1, action_dim)dist = Categorical(action_probs)action = dist.sample().item() # scalar# 执行动作next_state, reward, done, _ = env.step(action)# 存储经验episode_states.append(state)episode_actions.append(action)episode_rewards.append(reward)episode_next_states.append(next_state)episode_dones.append(done)state = next_stateepisode_reward += rewardif done:break# 更新网络policy_loss, value_loss = a2c_update(agent, optimizer,episode_states, episode_actions, episode_rewards,episode_next_states, episode_dones, gamma)# 记录奖励episode_rewards.append(episode_reward)# 打印训练信息if (episode + 1) % 10 == 0:avg_reward = np.mean(episode_rewards[-10:])print(f"Episode {episode+1}, Avg Reward: {avg_reward:.1f}, Policy Loss: {policy_loss:.3f}, Value Loss: {value_loss:.3f}")# 绘制训练曲线
plt.plot(episode_rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('A2C Training Performance on CartPole')
plt.show()# 测试训练好的智能体
def test_agent(agent, env, num_episodes=10):for episode in range(num_episodes):state = env.reset()total_reward = 0done = Falsewhile not done:state_tensor = torch.FloatTensor(state).unsqueeze(0)with torch.no_grad():action_probs, _ = agent(state_tensor)action = torch.argmax(action_probs).item()next_state, reward, done, _ = env.step(action)total_reward += rewardstate = next_stateprint(f"Test Episode {episode+1}: Total Reward = {total_reward}")test_agent(agent, env)
也可以封装成class
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
from collections import deque
import gymclass A2CNetwork(nn.Module):"""A2C网络架构,包含共享特征提取层、Actor头和Critic头"""def __init__(self, input_dim, action_dim, hidden_dim=256):super(A2CNetwork, self).__init__()# 共享特征提取层# input_dim: 状态空间维度,例如(4,)表示4维状态# hidden_dim: 隐藏层维度self.shared_layers = nn.Sequential(nn.Linear(input_dim, hidden_dim), # shape: (batch_size, input_dim) -> (batch_size, hidden_dim)nn.ReLU(),nn.Linear(hidden_dim, hidden_dim), # shape: (batch_size, hidden_dim) -> (batch_size, hidden_dim)nn.ReLU())# Actor头:输出动作概率分布# action_dim: 动作空间维度,例如2表示2个离散动作self.actor_head = nn.Linear(hidden_dim, action_dim) # shape: (batch_size, hidden_dim) -> (batch_size, action_dim)# Critic头:输出状态价值self.critic_head = nn.Linear(hidden_dim, 1) # shape: (batch_size, hidden_dim) -> (batch_size, 1)def forward(self, state):"""前向传播Args:state: 状态张量,shape: (batch_size, input_dim)Returns:action_probs: 动作概率分布,shape: (batch_size, action_dim)state_value: 状态价值,shape: (batch_size, 1)"""# 特征提取features = self.shared_layers(state) # shape: (batch_size, hidden_dim)# Actor输出:动作概率分布action_logits = self.actor_head(features) # shape: (batch_size, action_dim)action_probs = F.softmax(action_logits, dim=-1) # shape: (batch_size, action_dim)# Critic输出:状态价值state_value = self.critic_head(features) # shape: (batch_size, 1)return action_probs, state_valueclass A2CAgent:"""A2C智能体实现"""def __init__(self, state_dim, action_dim, lr=3e-4, gamma=0.99, entropy_coef=0.01, value_coef=0.5):"""初始化A2C智能体Args:state_dim: 状态空间维度action_dim: 动作空间维度lr: 学习率gamma: 折扣因子entropy_coef: 熵正则化系数value_coef: 价值损失权重"""self.gamma = gammaself.entropy_coef = entropy_coefself.value_coef = value_coef# 创建网络self.network = A2CNetwork(state_dim, action_dim)self.optimizer = optim.Adam(self.network.parameters(), lr=lr)# 存储轨迹数据self.reset_trajectory()def reset_trajectory(self):"""重置轨迹存储"""self.states = [] # 状态序列,每个元素shape: (state_dim,)self.actions = [] # 动作序列,每个元素shape: ()self.rewards = [] # 奖励序列,每个元素shape: ()self.log_probs = [] # 对数概率序列,每个元素shape: ()self.values = [] # 状态价值序列,每个元素shape: ()def select_action(self, state):"""根据当前策略选择动作Args:state: 当前状态,shape: (state_dim,)Returns:action: 选择的动作,标量log_prob: 动作的对数概率,标量value: 状态价值,标量"""# 转换为张量并添加batch维度state_tensor = torch.FloatTensor(state).unsqueeze(0) # shape: (1, state_dim)# 前向传播action_probs, state_value = self.network(state_tensor)# action_probs shape: (1, action_dim)# state_value shape: (1, 1)# 创建分布并采样动作dist = torch.distributions.Categorical(action_probs)action = dist.sample() # shape: (1,)log_prob = dist.log_prob(action) # shape: (1,)return action.item(), log_prob.squeeze(), state_value.squeeze()def store_transition(self, state, action, reward, log_prob, value):"""存储一步转移Args:state: 状态,shape: (state_dim,)action: 动作,标量reward: 奖励,标量log_prob: 对数概率,标量张量value: 状态价值,标量张量"""self.states.append(state)self.actions.append(action)self.rewards.append(reward)self.log_probs.append(log_prob)self.values.append(value)def compute_returns_and_advantages(self, next_value=0):"""计算回报和优势函数Args:next_value: 下一个状态的价值(终止状态为0)Returns:returns: 回报序列,shape: (trajectory_length,)advantages: 优势序列,shape: (trajectory_length,)"""trajectory_length = len(self.rewards)# 计算回报(从后往前)returns = torch.zeros(trajectory_length)R = next_value # 从终止状态开始for t in reversed(range(trajectory_length)):R = self.rewards[t] + self.gamma * R # R = r_t + γ * R_{t+1}returns[t] = R# 转换values为张量values = torch.stack(self.values) # shape: (trajectory_length,)# 计算优势函数:A(s,a) = R - V(s)advantages = returns - values # shape: (trajectory_length,)return returns, advantagesdef update(self, next_value=0):"""更新网络参数Args:next_value: 下一个状态的价值"""if len(self.rewards) == 0:return# 计算回报和优势returns, advantages = self.compute_returns_and_advantages(next_value)# 转换为张量states = torch.FloatTensor(np.array(self.states)) # shape: (trajectory_length, state_dim)actions = torch.LongTensor(self.actions) # shape: (trajectory_length,)log_probs = torch.stack(self.log_probs) # shape: (trajectory_length,)# 前向传播获取当前策略下的概率和价值action_probs, state_values = self.network(states)# action_probs shape: (trajectory_length, action_dim)# state_values shape: (trajectory_length, 1)state_values = state_values.squeeze() # shape: (trajectory_length,)# 计算当前策略下的对数概率和熵dist = torch.distributions.Categorical(action_probs)new_log_probs = dist.log_prob(actions) # shape: (trajectory_length,)entropy = dist.entropy().mean() # 标量,策略熵# 计算损失# Actor损失:策略梯度损失actor_loss = -(new_log_probs * advantages.detach()).mean() # 标量# Critic损失:价值函数损失critic_loss = F.mse_loss(state_values, returns.detach()) # 标量# 总损失total_loss = actor_loss + self.value_coef * critic_loss - self.entropy_coef * entropy# 反向传播和优化self.optimizer.zero_grad()total_loss.backward()# 梯度裁剪,防止梯度爆炸torch.nn.utils.clip_grad_norm_(self.network.parameters(), max_norm=0.5)self.optimizer.step()# 重置轨迹self.reset_trajectory()return {'actor_loss': actor_loss.item(),'critic_loss': critic_loss.item(),'entropy': entropy.item(),'total_loss': total_loss.item()}import gym
import matplotlib.pyplot as plt
from collections import dequedef train_a2c(env_name='CartPole-v1', num_episodes=1000, max_steps=500, update_freq=5):"""训练A2C智能体Args:env_name: 环境名称num_episodes: 训练回合数max_steps: 每回合最大步数update_freq: 更新频率(每多少步更新一次)"""# 创建环境env = gym.make(env_name)state_dim = env.observation_space.shape[0] # 状态维度,例如CartPole为4action_dim = env.action_space.n # 动作维度,例如CartPole为2print(f"状态维度: {state_dim}, 动作维度: {action_dim}")# 创建智能体agent = A2CAgent(state_dim, action_dim)# 训练记录episode_rewards = [] # 每回合总奖励recent_rewards = deque(maxlen=100) # 最近100回合的奖励for episode in range(num_episodes):state = env.reset() # shape: (state_dim,)episode_reward = 0step_count = 0for step in range(max_steps):# 选择动作action, log_prob, value = agent.select_action(state)# 执行动作next_state, reward, done, _ = env.step(action)# next_state shape: (state_dim,)# reward: 标量# done: 布尔值# 存储转移agent.store_transition(state, action, reward, log_prob, value)episode_reward += rewardstep_count += 1state = next_state# 定期更新或回合结束时更新if step_count % update_freq == 0 or done:# 计算下一个状态的价值(如果回合结束则为0)if done:next_value = 0else:with torch.no_grad():next_state_tensor = torch.FloatTensor(next_state).unsqueeze(0)_, next_value = agent.network(next_state_tensor)next_value = next_value.squeeze().item()# 更新网络loss_info = agent.update(next_value)if loss_info and episode % 100 == 0:print(f"Episode {episode}, Step {step}: "f"Actor Loss: {loss_info['actor_loss']:.4f}, "f"Critic Loss: {loss_info['critic_loss']:.4f}, "f"Entropy: {loss_info['entropy']:.4f}")if done:break# 记录奖励episode_rewards.append(episode_reward)recent_rewards.append(episode_reward)# 打印进度if episode % 100 == 0:avg_reward = np.mean(recent_rewards)print(f"Episode {episode}, Average Reward: {avg_reward:.2f}, "f"Current Reward: {episode_reward:.2f}")env.close()return agent, episode_rewardsdef test_agent(agent, env_name='CartPole-v1', num_episodes=10, render=True):"""测试训练好的智能体Args:agent: 训练好的A2C智能体env_name: 环境名称num_episodes: 测试回合数render: 是否渲染"""env = gym.make(env_name)test_rewards = []for episode in range(num_episodes):state = env.reset()episode_reward = 0done = Falsewhile not done:if render:env.render()# 选择动作(测试时不需要存储轨迹)action, _, _ = agent.select_action(state)state, reward, done, _ = env.step(action)episode_reward += rewardtest_rewards.append(episode_reward)print(f"Test Episode {episode + 1}: Reward = {episode_reward}")env.close()avg_test_reward = np.mean(test_rewards)print(f"\n平均测试奖励: {avg_test_reward:.2f}")return test_rewardsdef plot_training_results(episode_rewards):"""绘制训练结果Args:episode_rewards: 每回合奖励列表"""plt.figure(figsize=(12, 4))# 原始奖励曲线plt.subplot(1, 2, 1)plt.plot(episode_rewards, alpha=0.6)plt.title('Episode Rewards')plt.xlabel('Episode')plt.ylabel('Reward')plt.grid(True)# 移动平均奖励曲线plt.subplot(1, 2, 2)window_size = 100if len(episode_rewards) >= window_size:moving_avg = []for i in range(window_size - 1, len(episode_rewards)):moving_avg.append(np.mean(episode_rewards[i - window_size + 1:i + 1]))plt.plot(range(window_size - 1, len(episode_rewards)), moving_avg)plt.title(f'Moving Average Rewards (window={window_size})')plt.xlabel('Episode')plt.ylabel('Average Reward')plt.grid(True)plt.tight_layout()plt.show()# 主函数
if __name__ == "__main__":print("开始训练A2C智能体...")# 训练智能体agent, rewards = train_a2c(env_name='CartPole-v1',num_episodes=1000,max_steps=500,update_freq=5)print("\n训练完成!开始测试...")# 测试智能体test_rewards = test_agent(agent, num_episodes=5, render=False)# 绘制结果plot_training_results(rewards)print("\n训练和测试完成!")
更多关于方差和偏差参考:Making Sense of the Bias / Variance Trade-off in (Deep) Reinforcement Learning
https://blog.mlreview.com/making-sense-of-the-bias-variance-trade-off-in-deep-reinforcement-learning-79cf1e83d565
在 RL 的情况下,方差现在是指有噪声但平均准确的值估计,而偏差是指稳定但不准确的值估计