ES集群的分布式存储
elasticsearc会进行不同的分片,这个时候当我们在不同的分片当中进行数据的新增和删除,为什么我们可以在不同的分片当中查询到相同的结果?
协调节点:客户端请求 “调度员 + 结果汇总员”。收到查询、写入等请求后,它会判断需要哪些数据节点参与(比如搜索请求要涉及哪些分片 ),把任务拆分发下去,等各个节点返回部分结果,再汇总合并(如搜索结果排序、分页 ),最后返回给客户端,
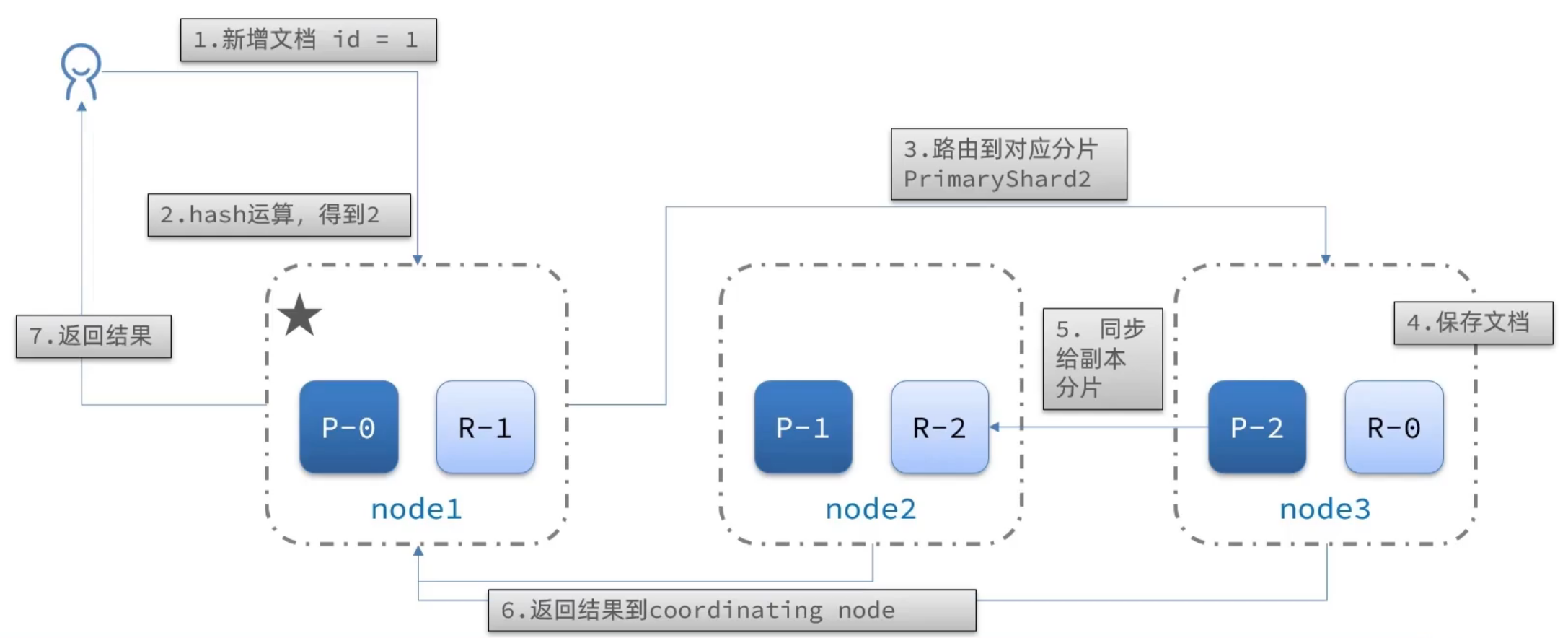
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:
shard =hash(_routing) % number_of_shards
说明:
-
routing默认是文档的id
-
算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档的流程:
当我们进行新增文档的时候,会通过新增文档的id值进行hash运算,然后通过运算的值,通过路由找到需要存入分片的节点位置再进行分片的存储,保存过后需要主分片会对自己的从分片进行数据的同步,等参与的节点完成复制之后,就会将结果返回给协调节点,再进行返回给客户端,这样的循环下来之后,就会使文档存储到应该存储的分片当中。
当我们不通过文档id来进行数据的查询等:
elasticsearch的查询分成两个阶段:
-
scatter phase:分散阶段,coordinatingnode会把请求分发到每一个分片
-
gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
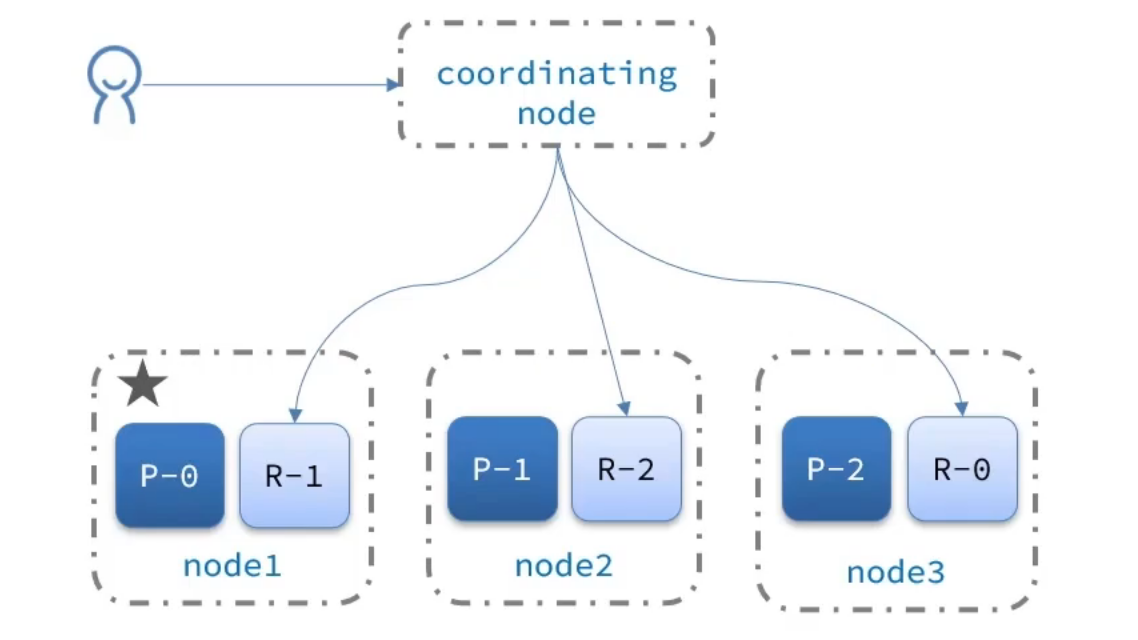
当我们没有数据的id的时候,ES会对每一个节点都进行请求的发送,然后再等所有的节点进行数据的汇总,才会返回给客户端。