java复习 09
不可以浮躁啊,考试不会很简单的...还是要做题避免一下太浮躁了,越是要考试我的脑袋里就越是有很多天马行空的想法和美好的靠后幻想,不要画大饼了,还是要好好学习啊...
1 extend可以继承父类里面的私有的成员变量吗,子类点调用会编译通过吗?
不可以继承私有的
会产生编译错误:若子类尝试通过this.私有变量名或super.私有变量名访问,编译器会报错。
2 什么是java的反射机制
Java 的反射机制是指在运行时动态地获取类的信息(如属性、方法、构造器等),并可以在运行时调用这些方法、访问或修改属性,甚至创建对象的能力。反射机制打破了传统编程中 "编译期确定类型" 的限制,使程序能够在运行时灵活地操作类和对象。
核心功能
- 获取类的信息:通过
Class对象获取类的完整结构(如字段、方法、构造器等)。 - 动态创建对象:通过构造器创建实例,无需在编译期确定具体类型。
- 调用方法:在运行时调用任意方法,无需在编译期确定方法名。
- 访问 / 修改属性:读写对象的私有或公有属性。
- 处理注解:获取类、方法或字段上的注解信息。
反射的核心类
java.lang.Class:代表一个类的字节码对象,是反射的基础。java.lang.reflect.Method:代表类的方法。java.lang.reflect.Field:代表类的字段(属性)。java.lang.reflect.Constructor:代表类的构造器。java.lang.reflect.Modifier:用于解析类、方法、字段的修饰符(如public、private等)。
反射的基本用法
1. 获取Class对象的三种方式
java
// 方式1:通过类名.class
Class<?> clazz1 = String.class;// 方式2:通过对象的getClass()方法
String str = "hello";
Class<?> clazz2 = str.getClass();// 方式3:通过全限定类名(用于动态加载类)
Class<?> clazz3 = Class.forName("java.lang.String");
2. 动态创建对象
java
// 获取构造器
Constructor<?> constructor = clazz.getDeclaredConstructor();
// 创建实例
Object instance = constructor.newInstance();
3. 调用方法
java
// 获取方法(参数为方法名和参数类型)
Method method = clazz.getDeclaredMethod("方法名", 参数类型.class);
// 调用方法(参数为实例对象和实际参数)
Object result = method.invoke(实例对象, 参数值);
4. 访问 / 修改属性
java
// 获取字段
Field field = clazz.getDeclaredField("字段名");
// 允许访问私有字段
field.setAccessible(true);
// 获取值
Object value = field.get(实例对象);
// 设置值
field.set(实例对象, 新值);
反射的应用场景
- 框架开发(如 Spring、Hibernate):通过配置文件动态加载类和依赖注入。
- JSON 序列化 / 反序列化(如 Gson、Jackson):根据字段名动态读写对象属性。
- 单元测试:测试私有方法或属性。
- 插件系统:动态加载第三方插件。
- 调试工具:分析类的结构。
反射的优缺点
优点
- 灵活性高:支持运行时动态扩展功能。
- 可扩展性强:适合开发通用框架。
缺点
- 性能开销大:反射操作比直接调用慢。
- 破坏封装性:可访问私有成员,违反面向对象设计原则。
- 代码可读性差:反射代码复杂,难以维护。
- 安全性风险:可能导致信息泄露或恶意操作。
注意事项
- 性能优化:避免频繁使用反射,可缓存反射结果。
- 安全检查:在安全敏感场景(如高权限操作)中谨慎使用。
- 兼容性问题:反射依赖类的具体结构,可能因版本变更而失效。
示例:动态调用私有方法
java
import java.lang.reflect.Method;public class ReflectionDemo {private void privateMethod(String message) {System.out.println("私有方法被调用:" + message);}public static void main(String[] args) throws Exception {// 创建实例ReflectionDemo demo = new ReflectionDemo();// 获取私有方法Method method = ReflectionDemo.class.getDeclaredMethod("privateMethod", String.class);// 允许访问私有方法method.setAccessible(true);// 调用方法method.invoke(demo, "Hello, Reflection!");}
}
通过反射,即使privateMethod是私有方法,也可以在运行时被调用。
总结
反射机制是 Java 提供的强大工具,用于在运行时操作类和对象。虽然它能极大提升灵活性,但代价是性能损耗和安全性风险。在实际开发中,应权衡利弊,优先使用传统编程方式,仅在必要时(如框架开发)才使用反射。
Java反射机制是Java语言的一个重要特性,它允许程序在运行时获取任何类的内部信息,并能直接操作任意对象的内部属性及方法。所有选项都是正确的,让我们逐一分析:
A选项正确:反射机制通过Class类的实例对象,可以在运行时判断任意一个对象所属的类。例如可以使用instanceof关键字或getClass()方法来实现这个功能。
B选项正确:通过反射机制,可以在运行时动态创建对象实例。使用Class类的newInstance()方法或Constructor类的newInstance()方法都可以实现对象的动态创建。
C选项正确:反射机制允许程序在运行时检查类的所有成员变量和方法。通过getDeclaredFields()可以获取所有成员变量,通过getDeclaredMethods()可以获取所有方法信息。
D选项正确:反射机制支持在运行时调用对象的任意方法。通过获取Method对象并调用invoke()方法可以实现动态方法调用。
总的来说,这些功能体现了Java反射机制的强大之处,它为我们提供了在运行时检查和操作类与对象的能力,是很多框架实现的基础,如Spring框架的依赖注入就大量使用了反射机制。
3 虽然x是private静态变量,但在同一个类中是可以直接访问的,所以第5行代码可以正常编译
私有的静态变量在同一个类里面可以编译!
需要注意的关键点:
1. 静态变量被所有实例共享
2. 无论通过哪个实例访问静态变量,修改的都是同一个值
3. 创建新实例并不会重置静态变量的值
4. 可以通过类名或实例名访问静态变量(虽然建议用类名)
4 在 Java 中,子类构造方法不能同时调用 super() 和 this()
补充说明:
1. this()和super()都必须作为构造方法的第一条语句
2. 在同一个构造方法中,不能同时出现this()和super()
3. 如果构造方法中既没有this()也没有super(),编译器会默认添加super()
4. super关键字可以在子类的任何实例方法中使用,用于访问父类的成员
在 Java 中,this()和super()不能同时出现在同一个构造方法中,但this和super作为引用变量可以在非构造方法中同时使用。下面分情况说明:
1. 构造方法中不能同时使用this()和super()
- 原因:
this()和super()都必须是构造方法的第一条语句,而一个方法不能有两条 “第一条语句”。 - 示例(错误写法):
java
public class Child extends Parent {public Child() {this("参数"); // 错误:this()必须是第一条语句super(); // 错误:super()必须是第一条语句,与this()冲突} } - 正确用法:
- 要么调用当前类的其他构造方法(使用
this()):java
public Child() {this("参数"); // 调用本类的另一个构造方法 } - 要么调用父类的构造方法(使用
super()):java
public Child() {super(); // 调用父类的无参构造方法(默认省略) }
- 要么调用当前类的其他构造方法(使用
2. 非构造方法中可以同时使用this和super
在实例方法或代码块中,this和super作为引用变量可以共存,分别指向当前对象和父类对象。
- 示例:
java
public class Parent {protected String name = "父类";public void print() {System.out.println("父类方法");} }public class Child extends Parent {private String name = "子类";public void test() {// 同时使用this和superSystem.out.println(this.name); // 访问子类的nameSystem.out.println(super.name); // 访问父类的namethis.print(); // 调用子类的print()super.print(); // 调用父类的print()} }
3. 构造方法中默认的super()
- 如果构造方法中没有显式调用
this()或super(),编译器会自动在第一行插入super()(调用父类的无参构造方法)。 - 示例:
java
public class Child extends Parent {public Child() {// 编译器隐式插入:super();} } - 注意:如果父类没有无参构造方法,且子类构造方法中没有显式调用
super(参数),会导致编译错误。
总结
- 构造方法中:
this()和super()不能同时使用,必须二选一或都不选(默认调用super())。 - 非构造方法中:
this和super可以同时使用,分别引用当前对象和父类对象。
这种设计保证了构造方法调用链的唯一性,避免循环调用导致的栈溢出。
5 volatile与synchronized的区别:
volatile本质是在告诉jvm当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住.
volatile仅能使用在变量级别,synchronized则可以使用在变量,方法.
volatile仅能实现变量的修改可见性,但不具备原子特性,而synchronized则可以保证变量的修改可见性和原子性.
volatile不会造成线程的阻塞,而synchronized可能会造成线程的阻塞.
volatile标记的变量不会被编译器优化,而synchronized标记的变量可以被编译器优化
6 有关线程❤❤❤
❤进程确实是一个独立的运行环境,可以看作一个程序或应用。线程是进程中的执行单元,共享进程的资源。Java运行环境是单进程的,而线程确实可以被称为轻量级进程,因为它们创建和维护的开销较小。
❤synchronized可以保证原子性和可见性,volatile只能保证可见性,不能保证原子性。
❤volatile关键字确保变量的改变对所有线程立即可见,但不能保证复合操作的原子性。而synchronized关键字通过互斥锁机制(很强大)可以同时保证原子性和可见性。
❤ThreadLocal确实用于创建线程的本地变量,这些变量在不同线程之间是独立的,不会相互影响。每个线程都拥有这个变量的一个独立副本。
7 抽象类和抽象方法的基本语法规则
1. 抽象方法必须以abstract关键字修饰
2. 抽象方法不能有方法体(花括号中的实现代码)
3. 抽象方法必须以分号结尾
4. 正确的抽象方法定义应该是:
abstract int sum(int x, int y);
8 并非所有异常都意味着程序存在错误需要调试修改。有些异常是正常业务流程的一部分,比如用户输入验证失败等情况。
Java的异常分为两大类:
1. 检测异常(checked exception):必须显式处理的异常!!!
2. 非检测异常(unchecked exception):RuntimeException及其子类,这类异常不强制要求显式处理
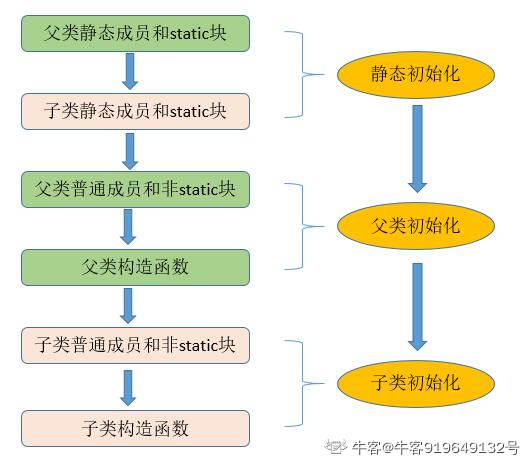
9 父子类初始化的顺序
10 有关栈和堆(作者:叶子压着花蕊)
栈是来存放值对象和引用的,堆是来存放具体的对象的。
Java中实例化对象是先在堆内存中实例化,然后在栈中存放一个对象的引用,也就是它在对中的地址
栈负责保存代码执行路径,而堆则负责保存对象的路径。堆用作保存信息而非保存执行路径,因此堆能够在任意时间被访问。
栈是自行维护的,内存自动维护栈。相反的,堆需要考虑垃圾回收,垃圾回收用于保持堆的整洁性
1、内存分配方面:
堆:由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。
注意:它与数据结构中的堆是两回事,分配方式是类似于链表。可能用到的关键字如下:new、malloc、delete、free等等。
栈:由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、申请方式方面:
堆:需要程序员自己申请,并指明大小。
栈:由系统自动分配。声明在函数中一个局部变量int b;系统自动在栈中为b开辟空间。
3、大小限制方面:
堆:是向高地址扩展的数据结构,是不连续的内存区域。系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于有效的虚拟内存。堆获得的空间比较灵活比较大。
栈:栈是向低地址扩展的数据结构,是一块连续的内存的区域。栈顶的地址和栈的最大容量是系统预先规定好的,如果申请的空间超过栈的剩余空间时,将提示overflow.
4、效率方面:
堆:是由new分配的内存,速度比较慢,而且容易产生内存碎片,不过用起来最方便。
栈:由系统自动分配,速度较快。但程序员是无法控制的。
5、存放内容方面:
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
栈:先进后出,在函数调用时第一个进栈的是主函数中后的下一条指令的地址然后是函数的各个参数,然后是函数中的局部变量。注意: 静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数。
一、程序的内存分配
1、栈区(stack)由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) 由程序员分配释放。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区),全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 程序结束后由系统释放
4、文字常量区 常量字符串就是放在这里的。
5、程序代码区 存放函数体的二进制代码。
原文链接:https://blog.csdn.net/hfy190616/article/details/49768573
11 控制访问权限
1、对同一类而言,权限没有意义:成员间可任意访问,不受权限制约;
2、对同一包中的类A和B,A不能访问B中的私有部分,其它均可访问;
3、跨包访问的要求极为苛刻,要求:只能访问public类的public成员;
4、拓展:允许包外的子孙访问自己的protected成员。