Day52 Python打卡训练营
1. 随机种子
2. 内参的初始化
3. 神经网络调参指南
a. 参数的分类
b. 调参的顺序
c. 各部分参数的调整心得
随机种子
import torch
import torch.nn as nn# 定义简单的线性模型(无隐藏层)
# 输入2个纬度的数据,得到1个纬度的输出
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()# 线性层:2个输入特征,1个输出特征self.linear = nn.Linear(2, 1)def forward(self, x):# 前向传播:y = w1*x1 + w2*x2 + breturn self.linear(x)# 创建模型实例
model = SimpleNet()# 查看模型参数
print("模型参数:")
for name, param in model.named_parameters():print(f"{name}: {param.data}")模型参数: linear.weight: tensor([[ 0.3268, -0.5784]]) linear.bias: tensor([0.6189])
随机种子
之前我们说过,torch中很多场景都会存在随机数
- 权重、偏置的随机初始化
- 数据加载(shuffling打乱)与批次加载(随机批次加载)的随机化
- 数据增强的随机化(随机旋转、缩放、平移、裁剪等)
- 随机正则化dropout
- 优化器中的随机性
import torch import numpy as np import os import random# 全局随机函数 def set_seed(seed=42, deterministic=True):"""设置全局随机种子,确保实验可重复性参数:seed: 随机种子值,默认为42deterministic: 是否启用确定性模式,默认为True"""# 设置Python的随机种子random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) # 确保Python哈希函数的随机性一致,比如字典、集合等无序# 设置NumPy的随机种子np.random.seed(seed)# 设置PyTorch的随机种子torch.manual_seed(seed) # 设置CPU上的随机种子torch.cuda.manual_seed(seed) # 设置GPU上的随机种子torch.cuda.manual_seed_all(seed) # 如果使用多GPU# 配置cuDNN以确保结果可重复if deterministic:torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = False# 设置随机种子 set_seed(42)介绍一下这个随机函数的几个部分
- python的随机种子,需要确保random模块、以及一些无序数据结构的一致性
- numpy的随机种子,控制数组的随机性
- torch的随机种子,控制张量的随机性,在cpu和gpu上均适用
- cuDNN(CUDA Deep Neural Network library ,CUDA 深度神经网络库)的随机性,针对cuda的优化算法的随机性
-
上述种子可以处理大部分场景,实际上还有少部分场景(具体的函数)可能需要自行设置其对应的随机种子。
日常使用中,在最开始调用这部分已经足够
内参的初始化
我强烈建议你自己在纸上,用笔推导一下简单的神经网络的训练过程。
我们都知道,神经网络的权重需要通过反向传播来实现更新,那么最开始肯定需要一个值才可以更新参数
这个最开始的值是什么样子的呢?如果恰好他们就是那一组最佳的参数附近的数,那么可能我训练的速度会快很多
为了搞懂这个问题,帮助我们真正理解神经网络参数的本质,我们需要深入剖析一下,关注以下几个问题:
- 初始值的区间
- 初始值的分布
- 初始值是多少
-
先介绍一下神经网络的对称性----为什么神经元的初始值需要各不相同?
本质神经网络的每一个神经元都是在做一件事,输入x--输出y的映射,这里我们假设激活函数是sigmoid
y=sigmoid(wx+b),其中w是连接到该神经元的权重矩阵,b是该神经元的偏置
如果所有神经元的权重和偏置都一样,
- 如果都为0,那么所有神经元的输出都一致,无法区分不同特征;此时反向传播的时候梯度都一样,无法学习到特征,更新后的权重也完全一致。
- 如果不为0,同上
-
所以其实对于不同的激活函数 ,都有对应的饱和区和非饱和区,深层网络中,饱和区会使梯度在反向传播时逐层衰减,底层参数几乎无法更新;
注意下,这里是wx后才会经过激活函数,是多个权重印象的结果,不是收到单个权重决定的,所以单个权重可以取负数,但是如果求和后仍然小于0,那么输出会为0
所以初始值一般不会太大,结合不同激活函数的特性,而且初始值一般是小的值。最终训练完毕可能就会出现大的差异,这样最开始让每个参数都是有用的,至于最后是不是某些参数归0(失去价值),那得看训练才知道。
我们来观察下pytorch默认初始化的权重
import torch import torch.nn as nn import matplotlib.pyplot as plt import numpy as np# 设置设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 定义极简CNN模型(仅1个卷积层+1个全连接层) class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 卷积层:输入3通道,输出16通道,卷积核3x3self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)# 池化层:2x2窗口,尺寸减半self.pool = nn.MaxPool2d(kernel_size=2)# 全连接层:展平后连接到10个输出(对应10个类别)# 输入尺寸:16通道 × 16x16特征图 = 16×16×16=4096self.fc = nn.Linear(16 * 16 * 16, 10)def forward(self, x):# 卷积+池化x = self.pool(self.conv1(x)) # 输出尺寸: [batch, 16, 16, 16]# 展平x = x.view(-1, 16 * 16 * 16) # 展平为: [batch, 4096]# 全连接x = self.fc(x) # 输出尺寸: [batch, 10]return x# 初始化模型 model = SimpleCNN() model = model.to(device)# 查看模型结构 print(model)# 查看初始权重统计信息 def print_weight_stats(model):# 卷积层conv_weights = model.conv1.weight.dataprint("\n卷积层 权重统计:")print(f" 均值: {conv_weights.mean().item():.6f}")print(f" 标准差: {conv_weights.std().item():.6f}")print(f" 理论标准差 (Kaiming): {np.sqrt(2/3):.6f}") # 输入通道数为3# 全连接层fc_weights = model.fc.weight.dataprint("\n全连接层 权重统计:")print(f" 均值: {fc_weights.mean().item():.6f}")print(f" 标准差: {fc_weights.std().item():.6f}")print(f" 理论标准差 (Kaiming): {np.sqrt(2/(16*16*16)):.6f}")# 改进的可视化权重分布函数 def visualize_weights(model, layer_name, weights, save_path=None):plt.figure(figsize=(12, 5))# 权重直方图plt.subplot(1, 2, 1)plt.hist(weights.cpu().numpy().flatten(), bins=50)plt.title(f'{layer_name} 权重分布')plt.xlabel('权重值')plt.ylabel('频次')# 权重热图plt.subplot(1, 2, 2)if len(weights.shape) == 4: # 卷积层权重 [out_channels, in_channels, kernel_size, kernel_size]# 只显示第一个输入通道的前10个滤波器w = weights[:10, 0].cpu().numpy()plt.imshow(w.reshape(-1, weights.shape[2]), cmap='viridis')else: # 全连接层权重 [out_features, in_features]# 只显示前10个神经元的权重,重塑为更合理的矩形w = weights[:10].cpu().numpy()# 计算更合理的二维形状(尝试接近正方形)n_features = w.shape[1]side_length = int(np.sqrt(n_features))# 如果不能完美整除,添加零填充使能重塑if n_features % side_length != 0:new_size = (side_length + 1) * side_lengthw_padded = np.zeros((w.shape[0], new_size))w_padded[:, :n_features] = ww = w_padded# 重塑并显示plt.imshow(w.reshape(w.shape[0] * side_length, -1), cmap='viridis')plt.colorbar()plt.title(f'{layer_name} 权重热图')plt.tight_layout()if save_path:plt.savefig(f'{save_path}_{layer_name}.png')plt.show()# 打印权重统计 print_weight_stats(model)# 可视化各层权重 visualize_weights(model, "Conv1", model.conv1.weight.data, "initial_weights") visualize_weights(model, "FC", model.fc.weight.data, "initial_weights")# 可视化偏置 plt.figure(figsize=(12, 5))# 卷积层偏置 conv_bias = model.conv1.bias.data plt.subplot(1, 2, 1) plt.bar(range(len(conv_bias)), conv_bias.cpu().numpy()) plt.title('卷积层 偏置')# 全连接层偏置 fc_bias = model.fc.bias.data plt.subplot(1, 2, 2) plt.bar(range(len(fc_bias)), fc_bias.cpu().numpy()) plt.title('全连接层 偏置')plt.tight_layout() plt.savefig('biases_initial.png') plt.show()print("\n偏置统计:") print(f"卷积层偏置 均值: {conv_bias.mean().item():.6f}") print(f"卷积层偏置 标准差: {conv_bias.std().item():.6f}") print(f"全连接层偏置 均值: {fc_bias.mean().item():.6f}") print(f"全连接层偏置 标准差: {fc_bias.std().item():.6f}")SimpleCNN((conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(fc): Linear(in_features=4096, out_features=10, bias=True) )卷积层 权重统计:均值: -0.005068标准差: 0.109001理论标准差 (Kaiming): 0.816497全连接层 权重统计:均值: -0.000031标准差: 0.009038理论标准差 (Kaiming): 0.022097所以,无论初始值是否为 0,相同的权重和偏置会导致神经元在训练过程中始终保持同步。(因为神经网络的前向传播是导致权重的数学含义是完全对称的)具体表现为:
同一层的神经元相当于在做完全相同的计算,无论输入如何变化,它们的输出模式始终一致。例如:输入图像中不同位置的边缘特征,会被这些神经元以相同方式处理,无法学习到空间分布的差异。
所以需要随机初始化,让初始的神经元各不相同。即使初始差异很小,但激活函数的非线性(梯度不同)会放大这种差异。随着训练进行,这种分歧会逐渐扩大,最终形成功能各异的神经元。
所以,明白了上述思想,你就知道初始值之前的差异并不需要巨大。
事实上,神经网络的初始权重通常设置在接近 0 的小范围内(如 [-0.1, 0.1] 或 [-0.01, 0.01]),或通过特定分布(如正态分布、均匀分布)生成小值,有很多好处
避免梯度消失 / 爆炸: 以 sigmoid 激活函数为例,其导数在输入绝对值较大时趋近于 0(如 | x|>5 时,导数≈0)。若初始权重过大,输入 x=w・input+b 可能导致激活函数进入 “饱和区”,反向传播时梯度接近 0,权重更新缓慢(梯度消失)。 类比:若初始权重是 “大值”,相当于让神经元一开始就进入 “极端状态”,失去对输入变化的敏感度。
如果梯度相对较大,就可以让变化处于sigmoid函数的非饱和区
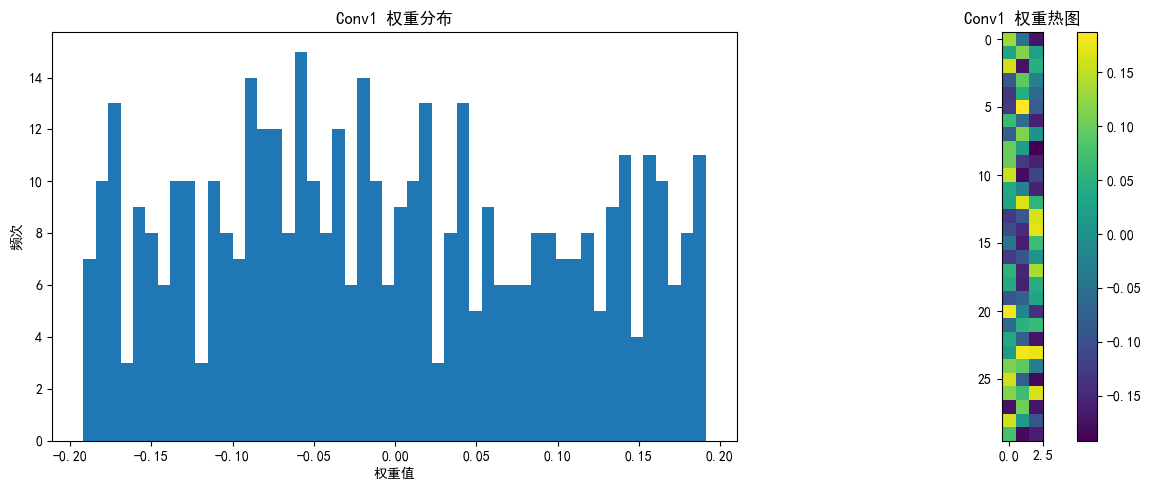
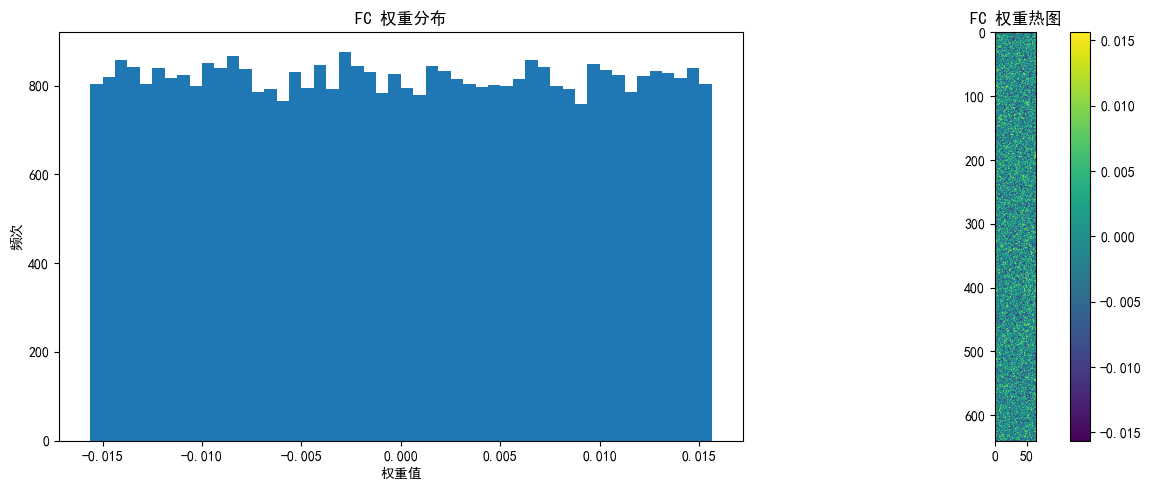
偏置统计: 卷积层偏置 均值: -0.031176 卷积层偏置 标准差: 0.086302 全连接层偏置 均值: 0.003063 全连接层偏置 标准差: 0.010418
上图怎么看自行询问ai
那我们监控权重图的目的是什么呢?
训练时,权重会随反向传播迭代更新。通过权重分布图,能直观看到其从初始化(如随机分布)到逐渐收敛、形成规律模式的动态变化,理解模型如何一步步 “学习” 特征 。比如,卷积层权重初期杂乱,训练后可能聚焦于边缘、纹理等特定模式。
识别梯度异常:
- 梯度消失:若权重分布越来越集中在 0 附近,且更新幅度极小,可能是梯度消失,模型难学到有效特征(比如深层网络用 Sigmoid 激活易出现 )。
- 梯度爆炸:权重值突然大幅震荡、超出合理范围(比如从 [-0.1, 0.1] 跳到 [-10, 10] ),要警惕梯度爆炸,可能让训练崩溃。
-
借助tensorboard可以看到训练过程中权重图的变化
铺垫了这么多 我们也该进入正题,来回顾一下对于卷积神经网络到底有哪些超参数,以及如何调参
神经网络调参指南
大部分时候,由于光是固定超参数的情况下,训练完模型就已经很耗时了,所以正常而言,基本不会采用传统机器学习的那些超参数方法,网格、贝叶斯、optuna之类的,看到一些博主用这些写文案啥的,感觉这些人都是脑子有问题的,估计也没学过机器学习直接就学深度学习了,搞混了二者的关系。
工业界卡特别多的情况下,可能可以考虑,尤其是在探究一个新架构的时候,我们直接忽视这些即可,只有手动调参这一条路。
参数的分类
之前我们介绍过了,参数=外参(实例化的手动指定的)+内参,其中我们把外参定义为超参数,也就是不需要数据驱动的那些参数
通常可以将超参数分为三类:网络参数、优化参数、正则化参数。
- 网络参数:包括网络层之间的交互方式(如相加、相乘或串接)、卷积核的数量和尺寸、网络层数(深度)和激活函数等。
- 优化参数:一般指学习率、批样本数量、不同优化器的参数及部分损失函数的可调参数。
- 正则化参数:如权重衰减系数、丢弃比率(dropout)。
-
超参数调优的目的是优化模型,找到最优解与正则项之间的关系。网络模型优化的目的是找到全局最优解(或相对更好的局部最优解),而正则项则希望模型能更好地拟合到最优。两者虽然存在一定对立,但目标是一致的,即最小化期望风险。模型优化希望最小化经验风险,但容易过拟合,而正则项用来约束模型复杂度。因此,如何平衡两者关系,得到最优或较优的解,就是超参数调整的目标。
调参顺序
调参遵循 “先保证模型能训练(基础配置)→ 再提升性能(核心参数)→ 最后抑制过拟合(正则化)” 的思路,类似 “先建框架,再装修,最后修细节”。
我们之前的课上,主要都是停留在第一步,先跑起来,如果想要更进一步提高精度,才是这些调参指南。所以下面顺序建立在已经跑通了的基础上。
- 参数初始化----有预训练的参数直接起飞
- batchsize---测试下能允许的最高值
- epoch---这个不必多说,默认都是训练到收敛位置,可以采取早停策略
- 学习率与调度器----收益最高,因为鞍点太多了,模型越复杂鞍点越多
- 模型结构----消融实验或者对照试验
- 损失函数---选择比较少,试出来一个即可,高手可以自己构建
- 激活函数---选择同样较少
- 正则化参数---主要是droupout,等到过拟合了用,上述所有步骤都为了让模型过拟合
-
这个调参顺序并不固定,而且也不是按照重要度来选择,是按照方便程度来选择,比如选择少的选完后,会减小后续实验的成本。
初始化参数
预训练参数是最好的参数初始化方法,在训练前先找找类似的论文有无预训练参数,其次是Xavir,尤其是小数据集的场景,多找论文找到预训练模型是最好的做法。关于预训练参数,我们介绍过了,优先动深层的参数,因为浅层是通用的;其次是学习率要采取分阶段的策略。
如果从0开始训练的话,PyTorch 默认用 Kaiming 初始化(适配 ReLU)或 Xavier 初始化(适配 Sigmoid/Tanh)。
bitchsize的选择
一般学生党资源都有限,所以基本都是bitchsize不够用的情况,富哥当我没说。 当Batch Size 太小的时候,模型每次更新学到的东西太少了,很可能白学了因为缺少全局思维。所以尽可能高一点,16的倍数即可,越大越好。
学习率调整
学习率就是参数更新的步长,LR 过大→不好收敛;LR 过小→训练停滞(陷入局部最优)
一般最开始用adam快速收敛,然后sgd收尾,一般精度会高一点;只能选一个就adam配合调度器使用。比如 CosineAnnealingLR余弦退火调度器、StepLR固定步长衰减调度器,比较经典的搭配就是Adam + ReduceLROnPlateau,SGD + CosineAnnealing,或者Adam → SGD + StepLR。
比如最开始随便选了做了一组,后面为了刷精度就可以考虑选择更精细化的策略了
激活函数的选择
视情况选择,一般默认relu或者其变体,如leaky relu,再或者用tanh。只有二分类任务最后的输出层用sigmoid,多分类任务用softmax,其他全部用relu即可。此外,还有特殊场景下的,比如GELU(适配 Transformer)
损失函数的选择
大部分我们目前接触的任务都是单个损失函数构成的,正常选即可
分类任务:
- 交叉熵损失函数Cross-Entropy Loss--多分类场景
- 二元交叉熵损失函数Binary Cross-Entropy Loss--二分类场景
- Focal Loss----类别不平衡场景
-
注意点:
- CrossEntropyLoss内置 Softmax,输入应为原始 logits(非概率)。
- BCEWithLogitsLoss内置 Sigmoid,输入应为原始 logits。
- 若评价指标为准确率,用交叉熵损失;若为 F1 分数,考虑 Focal Loss 或自定义损失。
-
回归任务
- 均方误差MSE
-
此外,还有一些序列任务的损失、生成任务的损失等等,以后再提
后面会遇到一个任务中有多个损失函数构成,比如加权成一个大的损失函数,就需要注意到二者的权重配比还有数量级的差异。
模型架构中的参数
比如卷积核尺寸等,一般就是77、55、3*3这种奇数对构成,其实我觉得无所谓,最开始不要用太过分的下采样即可。
神经元的参数,直接用 Kaiming 初始化(适配 ReLU,PyTorch 默认)或 Xavier 初始化(适配 Sigmoid/Tanh)。
正则化系数
droupout一般控制在0.2-0.5之间,这里说一下小技巧,先追求过拟合后追求泛化性。也就是说先把模型做到过拟合,然后在慢慢增加正则化程度。
正则化中,如果train的loss可以很低,但是val的loss还是很高,则说明泛化能力不强,优先让模型过拟合,在考虑加大正则化提高泛化能力,可以分模块来droupout,可以确定具体是那部分参数导致过拟合,这里还有个小trick是引入残差链接后再利用droupout
L2权重衰减这个在优化器中就有,这里提一下,也可以算是正则化吧。
其他补充
对于复杂的项目,尽可能直接对着别人已经可以跑通的源码来改。----注意是可以跑通的,目前有很多论文的开源都是假开源。
在调参过程中可以监控tensorboard来关注训练过程。
无论怎么调参,提升的都是相对较小,优先考虑数据+特征工程上做文章。还有很多试验灌水的方法,自行搜索即可。实际上这些都是小问题,不做实验直接出结果的都大有人在,难绷
今天说的内容其实相对而言比较基础,非常多的trick现在提也没有价值,主要都是随便一试出来了好结果然后编个故事,不具有可以系统化标准化的理解,掌握到今天说的这个程度够用咯.大家现阶段能把复杂的模型跑通和理解已经实属不易。
- 绝对误差MAE 这个也要根据场景和数据特点来选,不同损失受到异常值的影响程度不同
作业:对于day'41的简单cnn,看看是否可以借助调参指南进一步提高精度。
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np from torch.cuda.amp import autocast, GradScaler# 设置中文字体支持 plt.rcParams["font.family"] = ["SimHei"] plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"使用设备: {device}")# 1. 数据预处理 # 训练集:增强数据以提高泛化能力 train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4), # 随机裁剪transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1), # 增强颜色抖动transforms.RandomRotation(15), # 随机旋转transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3)) # Cutout ])# 测试集:仅标准化 test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) ])# 2. 加载CIFAR-10数据集 train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform) test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)# 3. 创建数据加载器 batch_size = 64 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型 class CNN(nn.Module):def __init__(self, dropout_rate=0.3):super(CNN, self).__init__()# 第一个卷积块self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)# 第二个卷积块self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2)# 第三个卷积块self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(kernel_size=2)# Dropout for convolutional layersself.dropout_conv = nn.Dropout(p=dropout_rate)# 全连接层self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, 10)def forward(self, x):x = self.pool1(self.relu1(self.bn1(self.conv1(x))))x = self.pool2(self.relu2(self.bn2(self.conv2(x))))x = self.pool3(self.relu3(self.bn3(self.conv3(x))))x = self.dropout_conv(x)x = x.view(-1, 128 * 4 * 4)x = self.relu3(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return x# 5. 训练函数(带提前停止和混合精度) def train_with_early_stopping(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, patience=5):model.train()scaler = GradScaler() # 混合精度训练best_acc = 0patience_counter = 0all_iter_losses = []iter_indices = []train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()with autocast(): # 混合精度output = model(data)loss = criterion(output, target)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试test_acc, test_loss = evaluate(model, test_loader, criterion, device)test_acc_history.append(test_acc)test_loss_history.append(test_loss)scheduler.step(test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {test_acc:.2f}%')if test_acc > best_acc:best_acc = test_accpatience_counter = 0# torch.save(model.state_dict(), 'best_model.pth')else:patience_counter += 1if patience_counter >= patience:print("提前停止触发")break# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return best_acc# 6. 测试函数 def evaluate(model, test_loader, criterion, device):model.eval()test_loss = 0correct = 0total = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()test_loss /= len(test_loader)test_acc = 100. * correct / totalreturn test_acc, test_loss# 7. 绘制每个iteration的损失曲线 def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 绘制每个epoch的准确率和损失曲线 def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 9. 执行训练 if __name__ == "__main__":epochs = 50model = CNN(dropout_rate=0.3).to(device)criterion = nn.CrossEntropyLoss(label_smoothing=0.1) # 标签平滑optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4) # AdamW优化器scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5) # 余弦退火print("开始使用优化后的CNN训练模型...")final_accuracy = train_with_early_stopping(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, patience=5)print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# 保存模型# torch.save(model.state_dict(), 'cifar10_cnn_optimized.pth')# print("模型已保存为: cifar10_cnn_optimized.pth")@浙大疏锦行