[vela os_4] 处理器间通信(IPC)| 内存管理
第6章:处理器间通信(IPC)
欢迎回来!
在前几章中,我们已经学习了
- 如何使用第1章:Kconfig为我们的
openvela系统选择组件 - 第2章:构建系统如何将这些选择
转化为可运行软件 - 第3章:驱动程序如何让
系统与硬件通信 - 第4章:文件系统/VFS如何
提供统一的设备访问方式 - 第5章:网络协议栈如何
实现与外部世界的通信。
现在让我们思考嵌入式系统内部的通信。
现代嵌入式设备(尤其是高性能设备)通常包含需要协调工作的不同软件组件,甚至可能涉及多个协同工作的处理器核心。
这些不同的软件组件或处理器核心如何安全高效地相互传递信息?这就是处理器间通信(IPC)的用武之地。
什么是IPC?系统内部对话
设想openvela系统如同繁忙的工厂或小型城镇。
不同部门或建筑(软件组件、任务或独立的处理器核心)需要共享信息或请求操作以维持整体协调运转。
- 传感器读取任务需要向日志记录任务发送数据
- 网络处理任务接收需要转发给电机控制任务的指令
- 在多核芯片中,运行类Linux系统的核心可能需要通知运行实时进程的其他核心启动特定操作
直接访问彼此内部数据或随机调用函数会导致混乱和错误,特别是在任务运行速度不同或位于不同核心时。IPC为这些内部实体提供了结构化的通信方式。
可将IPC视为系统的内部邮政服务、电话线路或共享公告板,允许不同组件按照预定义规则进行交互。
为什么需要IPC?
即使在单个处理器上运行由第9章:任务调度管理的多个任务,IPC仍然至关重要:
- 数据交换:任务间传递信息
- 同步协调:协调操作(例如"在数据采集完成前暂不启动处理")
- 模块化:保持软件组件独立性,仅通过定义通道交互
在多核系统(多处理器系统)中,IPC更为关键,因为不同核心可能具有独立内存区域、不同操作系统或完全独立运行。IPC是其实现协作的唯一途径。
openvela中的常见IPC机制
openvela与多数操作系统类似,提供从简单消息传递到多核系统复杂机制的多种IPC方式。
让我们了解其中部分机制。
1. 管道(匿名管道)
管道是单向通信通道,通常用于关联任务(如由同一父任务创建的任务,或openvela中同一进程的线程)。
-
其工作原理类似导管:数据从一端写入后从另一端顺序读取(先进先出/FIFO)。
-
匿名特性指其不在文件系统中命名,通过文件描述符(第4章:文件系统/VFS)访问,类似于文件或设备操作。
管道使用示例:
使用pipe()函数创建管道,返回两个文件描述符:fd[0]用于读取,fd[1]用于写入。
#include <unistd.h> // 用于pipe(), read(), write(), close()
#include <stdio.h> // 用于printf()
#include <stdlib.h> // 用于exit(), EXIT_FAILUREint main() {int pipefd[2]; // 存储两个文件描述符的数组char buffer[20];const char *message = "来自写入端的问候!";// 创建管道if (pipe(pipefd) == -1) {perror("pipe"); // 打印错误信息exit(EXIT_FAILURE); // 创建失败时退出}printf("管道已创建:读取描述符 = %d,写入描述符 = %d\n", pipefd[0], pipefd[1]);// 示例:写入管道// 实际场景可能位于独立任务/线程printf("正在向管道写入消息...\n");write(pipefd[1], message, strlen(message) + 1); // +1包含终止符// 示例:读取管道// 实际场景可能位于其他任务/线程printf("正在从管道读取消息...\n");ssize_t bytes_read = read(pipefd[0], buffer, sizeof(buffer));if (bytes_read > 0) {printf("读取%zd字节:%s\n", bytes_read, buffer);} else {printf("管道读取失败\n");}// 使用完毕关闭管道close(pipefd[0]);close(pipefd[1]);printf("管道已关闭\n");return 0;
}
典型多任务场景中
- 写入端任务保持
pipefd[1]打开并关闭pipefd[0] - 读取端任务则保持
pipefd[0]打开并关闭pipefd[1]。 - 写入端数据可供读取端按序获取。读取操作通常在管道为空时阻塞(等待),写入操作在管道缓冲区满时可能阻塞。
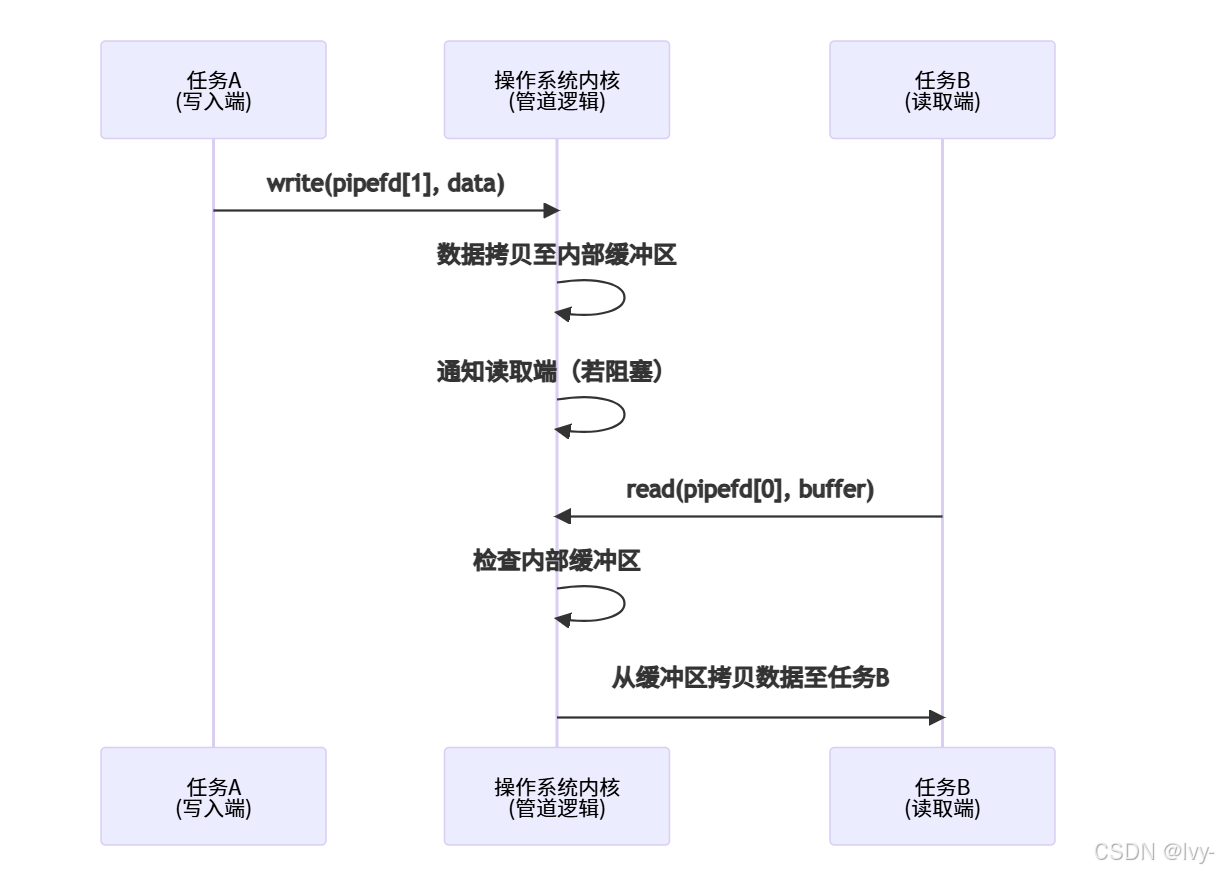
管道内部原理(简化版):
内核管理管道,创建时分配内部缓冲区(队列)和两个特殊文件描述符。
这些描述符通过第4章:文件系统/VFS层集成,允许标准read()/write()调用。
VFS识别管道描述符后,将调用路由至内核管道管理函数进行缓冲读写。
管道Kconfig配置:
在openvela构建中启用管道需在menuconfig中选择:
CONFIG_PIPES=y # 启用管道支持
CONFIG_DEV_PIPE_SIZE>0 # 设置管道内部缓冲区大小
CONFIG_DEV_PIPE_SIZE决定写入阻塞前的管道容量。
命名管道和匿名管道
命名管道就像在文件系统中给管道取了一个固定的名称,任何知道这个名称的程序都可以通过它进行通信- 而
匿名管道则没有具体的名称,仅限于有亲缘关系的程序(如父子进程)之间使用,用于临时性的数据传输。
2. FIFO(命名管道)
-
FIFO(命名管道)与匿名管道相似——均为单向字节流通道,遵循先进先出原则。关键区别在于FIFO在文件系统中具有**命名路径」(通常位于
/dev或/var)。 -
这使得无关联任务/进程(无共同父进程文件描述符)可通过名称连接同一FIFO。某任务使用
mkfifo()创建FIFO后,其他任务即可通过open()打开进行读写。
FIFO使用示例:
首先创建特殊文件形式的FIFO:
#include <sys/stat.h> // 用于mkfifo()
#include <stdio.h> // 用于perror(), printf()
#include <stdlib.h> // 用于exit(), EXIT_FAILURE
#include <errno.h> // 用于errno, EEXIST
#include <unistd.h> // 用于unlink()#define FIFO_PATH "/var/my_fifo"int main() {// 创建具有读写权限的FIFOif (mkfifo(FIFO_PATH, 0666) == -1) {// 若已存在则忽略错误if (errno != EEXIST) {perror("mkfifo");exit(EXIT_FAILURE);}printf("FIFO '%s' 已存在\n", FIFO_PATH);} else {printf("FIFO '%s' 已创建\n", FIFO_PATH);}// ... 其他任务可通过open(FIFO_PATH, O_RDONLY)打开// 及open(FIFO_PATH, O_WRONLY)进行读写// 示例用法(读写操作应位于不同任务)// 任务A打开写入端:// int write_fd = open(FIFO_PATH, O_WRONLY);// write(write_fd, "示例数据", ...);// close(write_fd);// 任务B打开读取端:// int read_fd = open(FIFO_PATH, O_RDONLY);// read(read_fd, buffer, ...);// close(read_fd);// 清理FIFO文件// unlink(FIFO_PATH); // 通常由创建者或系统关闭时执行return 0;
}
-
创建后,任何任务均可通过
open()像常规文件一样打开FIFO_PATH,指定O_RDONLY或O_WRONLY。 -
标准
read()/write()用于数据传输。与匿名管道类似,空FIFO读取会阻塞,满FIFO写入会阻塞。
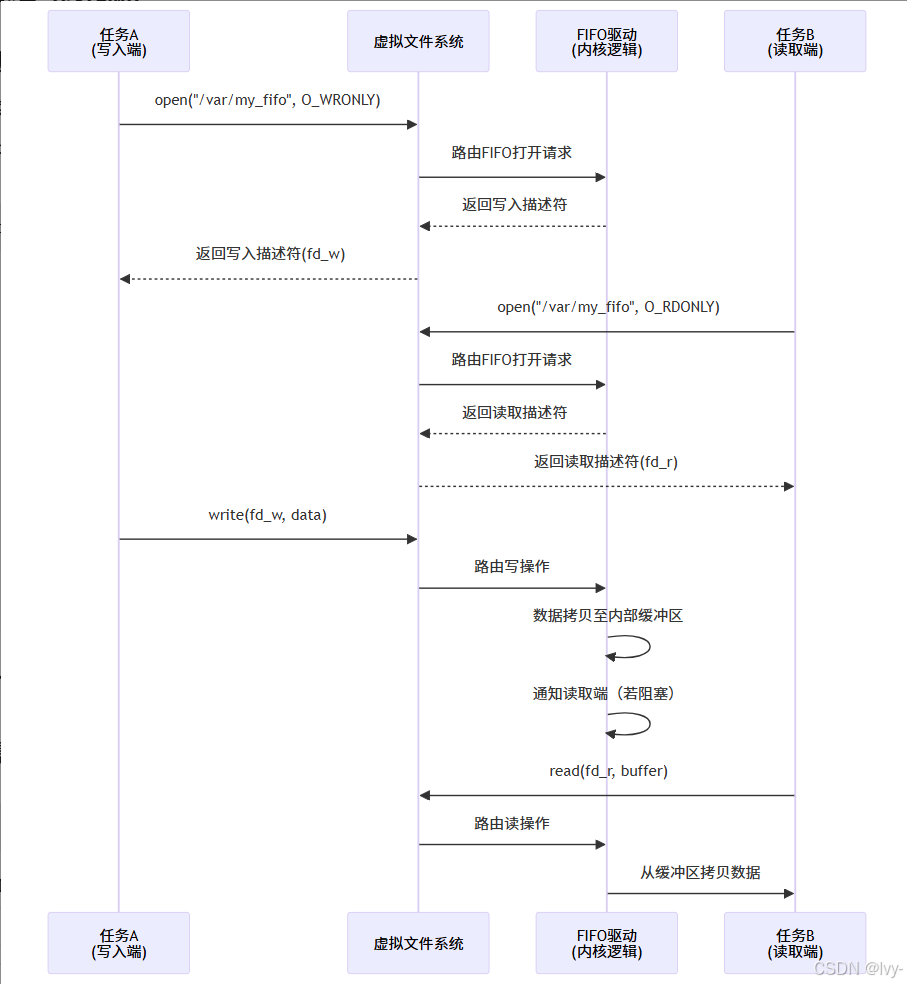
FIFO内部原理(简化版):
FIFO同样使用内核缓冲区。mkfifo()在指定路径创建第4章:文件系统/VFS树中的特殊条目(inode),标记为FIFO类型。
任务调用open()时,VFS识别为FIFO inode并将操作路由至内核FIFO驱动,确保获取共享缓冲区的文件描述符。read()/write()操作与匿名管道相同。
FIFO Kconfig配置:
启用FIFO需同时激活管道支持:
CONFIG_PIPES=y # 启用管道支持(包含FIFO框架)
CONFIG_DEV_FIFO_SIZE>0 # 设置FIFO内部缓冲区大小
3. 多处理器IPC:RPMsg与VirtIO
管道和FIFO适用于openvela单处理器环境。
但在多核系统(特别是运行不同操作系统或裸机代码的核心间),标准管道无法跨越隔离内存空间或异构OS内核。
此类非对称多处理(AMP)系统需要专用IPC机制。openvela支持RPMsg(远程处理器消息)和VirtIO等方案。
这些机制通常依赖:
- 共享内存:处理器共同访问的物理内存区域,用于传递数据或控制信息
- 通知/中断:通过硬件中断等方式通知数据就绪或请求处理
RPMsg(远程处理器消息)
- RPMsg是为处理器间通信设计的轻量级消息框架,特别适用于AMP系统(如某核心运行Linux,另一核心运行openvela等RTOS)。
- 它通过定义的通信端点(endpoints)在处理器间传递离散消息。
RPMsg使用共享内存存储消息数据,通过底层驱动处理处理器特定通知机制。
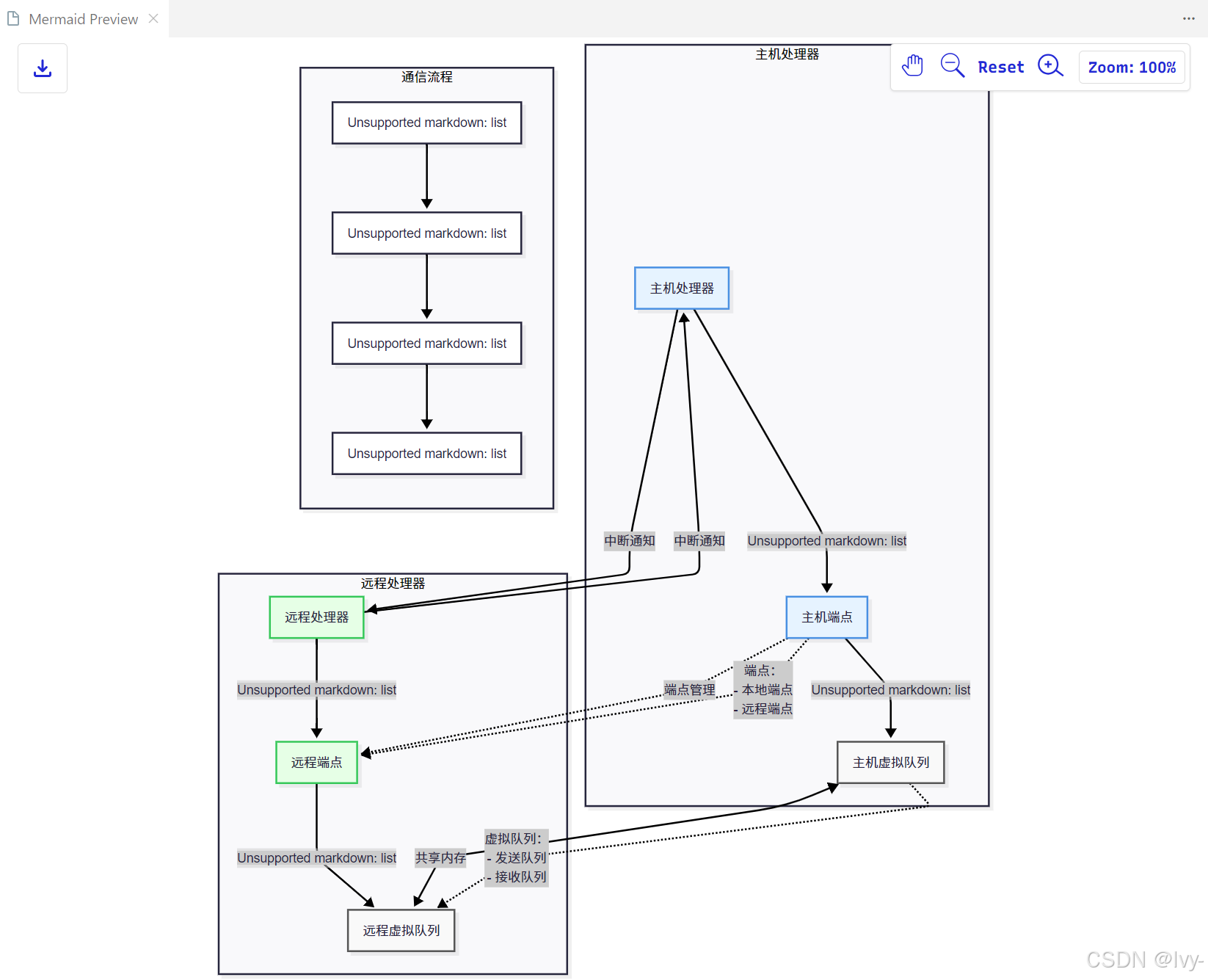
(基于Introduction_to_RPMsg.md概念图)
- RPMsg定义标准消息格式和端点寻址。
- 发送端应用向目标端点发送消息,本地RPMsg协议栈封装数据至共享内存,并通知接收核心。
- 接收端RPMsg协议栈获取通知后,从共享内存提取消息并递交给注册应用。
openvela的RPMsg实现基于OpenAMP并扩展,包含服务层(应用API)和传输层(处理特定多核硬件的共享内存与通知)。
RPMsg Kconfig配置:
CONFIG_RPMSG=y # 启用RPMsg支持
# 其他选项配置传输层(如VirtIO传输)
VirtIO
VirtIO最初为虚拟机与宿主机高效通信开发,提供标准化接口(块设备、网络设备等),宿主机实现具体功能以避免低效硬件模拟。
VirtIO已适配多处理器系统(如AMP),某处理器作为"Host",其他作为"Guest"。其使用
-
虚拟队列(Vrings):
共享内存结构进行通信。 -
虚拟队列(Vrings):位于共享内存的环形缓冲区,通过
**描述符**指针传递实际数据缓冲区地址。
(采用Mermaid绘制的导图,mmd原件上传在了github上,可以自行获取~)
(基于introduction_to_virtio.md概念图)
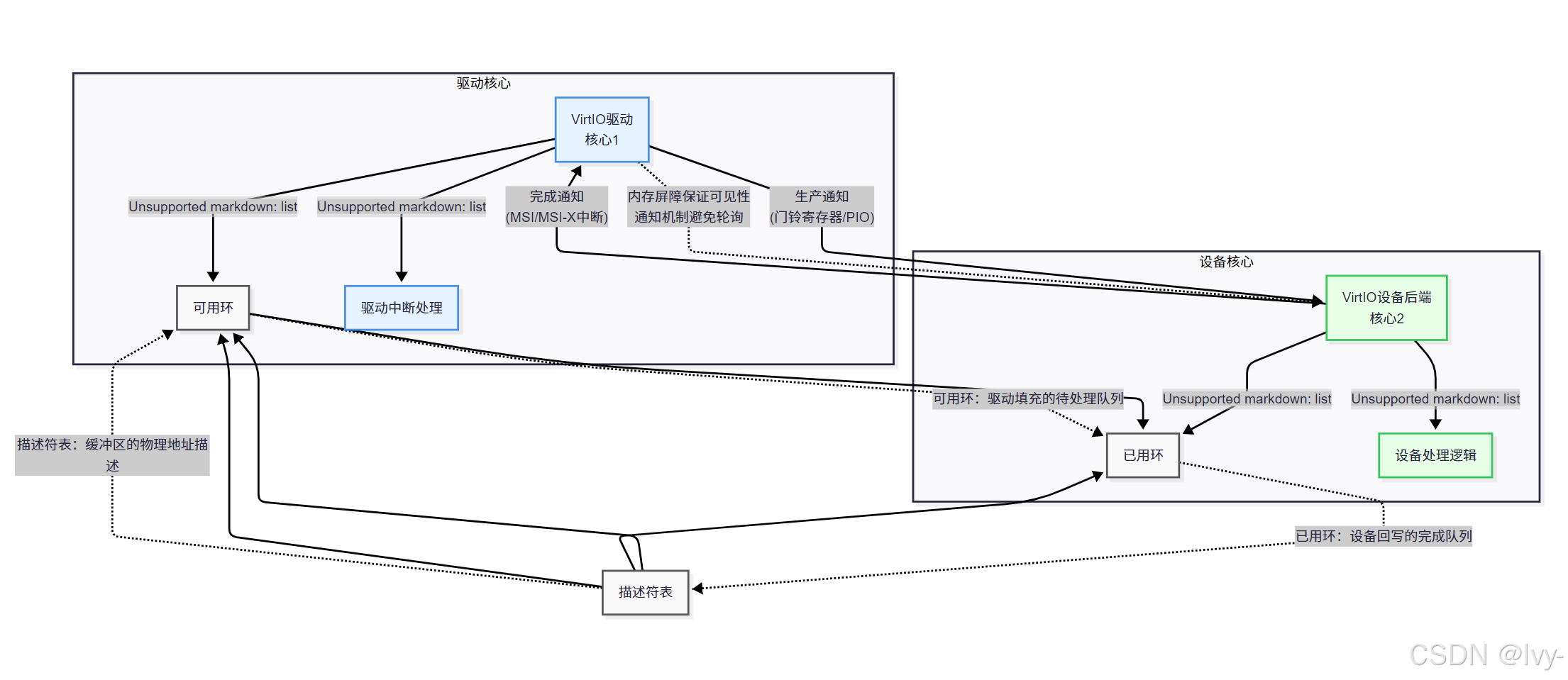
虚拟队列包含:
- 描述符表:描述数据缓冲区(地址、长度、标志)
- 可用环:生产者(驱动或设备)存放已填充描述符索引
- 已用环:消费者(设备或驱动)存放已处理描述符索引
该环形结构结合标志位和原子操作,实现无锁缓冲区所有权传递。
-
RPMsg可使用VirtIO作为多核传输层,利用虚拟队列机制传递消息。
-
其他
多核通信驱动(如核心间虚拟网络接口)也可基于VirtIO构建。
VirtIO Kconfig配置:
CONFIG_VIRTIO=y # 启用VirtIO框架
# 其他选项配置特定驱动(如VirtIO-MMIO、VirtIO-Remoteproc)
- RPMsg 主从的虚拟内存传输结构
- VirtIO 生产消费者模型+描述表的传输设计
进程间隔离限制
如Pipe.md所述,在缺乏硬件内存管理单元(MMU)或未配置严格进程隔离的openvela设备中需注意:
当前openvela环境因不支持进程隔离,所有进程共享相同地址空间。
-
这意味着虽然操作系统通过软件隔离文件描述符和环境变量,但底层内存对所有任务可见。
-
这可能导致问题,但也使得依赖共享内存的IPC机制(如管道/FIFO内核缓冲区,或RPMsg/VirtIO共享区域)可行。
-
即使没有硬件内存保护,OS仍提供结构化和同步机制(如管道阻塞读写)。
但在多处理器系统中,各处理器可能具有独立内存空间或运行不同OS,此时硬件定义处理器间隔离,必须使用RPMsg/VirtIO等配置严格共享内存区域的机制。
总结
处理器间通信(IPC)是协调openvela系统各组件的重要机制,无论是单处理器任务还是多核系统设计。我们探讨了以下IPC方法:
- 管道:关联任务/线程间的单向字节流,通过文件描述符访问
- FIFO(命名管道):通过文件系统名称实现无关任务通信
- RPMsg(主从)与VirtIO(生消):多核系统专用框架,依赖共享内存和硬件通知
选择合适IPC机制需权衡需求——从简单的进程内通信到复杂的多核桥接。
所有这些机制(特别是涉及缓冲内存的)都依赖于系统的内存管理方案,这将是我们下章的主题。
内存管理
第7章:内存管理
我们已经了解了
如何选择功能(第1章:Kconfig)构建软件(第2章:构建系统)- 使用第3章:驱动程序
与特定硬件组件交互 - 通过第4章:文件系统/VFS
管理设备和文件 - 使用第5章:网络协议栈进行
外部通信 - 甚至通过第6章:处理器间通信(IPC)
实现软件不同部分或处理器核之间的通信。
所有这些软件组件和通信机制都需要在嵌入式设备的内存中拥有"生存"和"工作"的空间。
它们需要存储指令(代码)的空间、存放变量(数据)的空间,以及在主动运行时需要的临时空间。
这就引出了我们的核心概念:内存管理。
什么是内存管理?操作系统的"房产经纪人"
想象您嵌入式设备的可用RAM(随机存取存储器)就像一栋有限的建筑物或座位固定的餐厅。
-
许多不同的程序、操作系统组件和驱动程序都希望同时使用这个空间。
-
如果它们都随意抢占空间,将会导致混乱!程序可能覆盖彼此的数据、崩溃,或者最贪婪的程序可能霸占所有空间,导致其他程序无法运行。
内存管理是操作系统中负责
组织、分配和回收设备内存的系统。它就像是系统RAM的餐厅经理或房产经纪人:
- 跟踪记录: 精确掌握RAM的哪些部分空闲,哪些部分当前被谁使用
- 分配: 当程序或系统组件需要特定大小的内存来存储数据或运行时,它会向内存管理器申请。管理器找到合适的空闲区域并分配给请求者
- 回收(释放): 当程序使用完某块内存后,它会告知内存管理器。管理器随后将该内存标记为空闲,供其他程序使用
这个过程确保了有限的内存资源被高效使用,同时防止系统不同部分相互干扰内存空间。
为什么内存管理如此重要?
在嵌入式系统中,高效的内存管理至关重要,因为:
- 内存有限:
嵌入式设备通常比台式机或智能手机的RAM少得多。每个字节都很重要! - 多程序/任务: openvela是多任务操作系统。许多不同的程序或任务看似同时运行,都需要自己的空间
- 动态需求: 程序通常无法预先知道需要多少内存。它们可能需要更多空间来处理更大的网络数据包、存储传感器数据或处理更大的文件。这需要程序在运行时动态申请内存的能力
- 稳定性: 良好的内存管理可以防止程序访问不该访问的内存,避免崩溃或安全漏洞
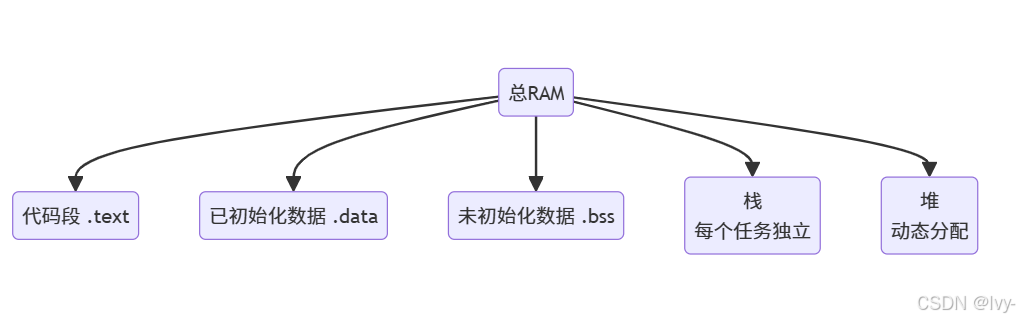
内存的不同区域
设备的总RAM并不是一个无差别的大块。当系统构建(第2章:构建系统)并启动时,内存通常被划分为不同用途的区域:
- 代码段(.text): 存储程序指令(编译后的代码本身),通常为只读
- 已初始化数据段(.data): 存储程序启动时具有明确初始值的
全局和静态变量 - 未初始化数据段(.bss): 存储未显式初始化的全局和静态变量,程序启动时通常
置零- 芯片移植指南提到在启动时清空BSS段
- 栈: 用于函数调用和函数内的局部变量,
每个任务/线程通常有自己的栈空间,随函数调用自动增长/收缩- 芯片移植指南提到空闲线程栈大小(
CONFIG_IDLETHREAD_STACKSIZE)
- 芯片移植指南提到空闲线程栈大小(
- 堆: 用于动态内存分配,程序可以在运行时
按需申请内存块
openvela的内存管理模块主要管理堆区域,因为这是动态请求发生的地方。
动态内存分配:堆
应用程序与内存管理系统最常见的交互方式是通过堆申请内存。
这被称为动态内存分配,因为内存量是在程序运行时动态确定的,而非编译时固定。
C语言中用于动态内存分配的标准函数是malloc()、calloc()、realloc()和free()。
openvela的内存管理(mm)模块实现了这些标准函数(如memory_mgt.md片段所述)。
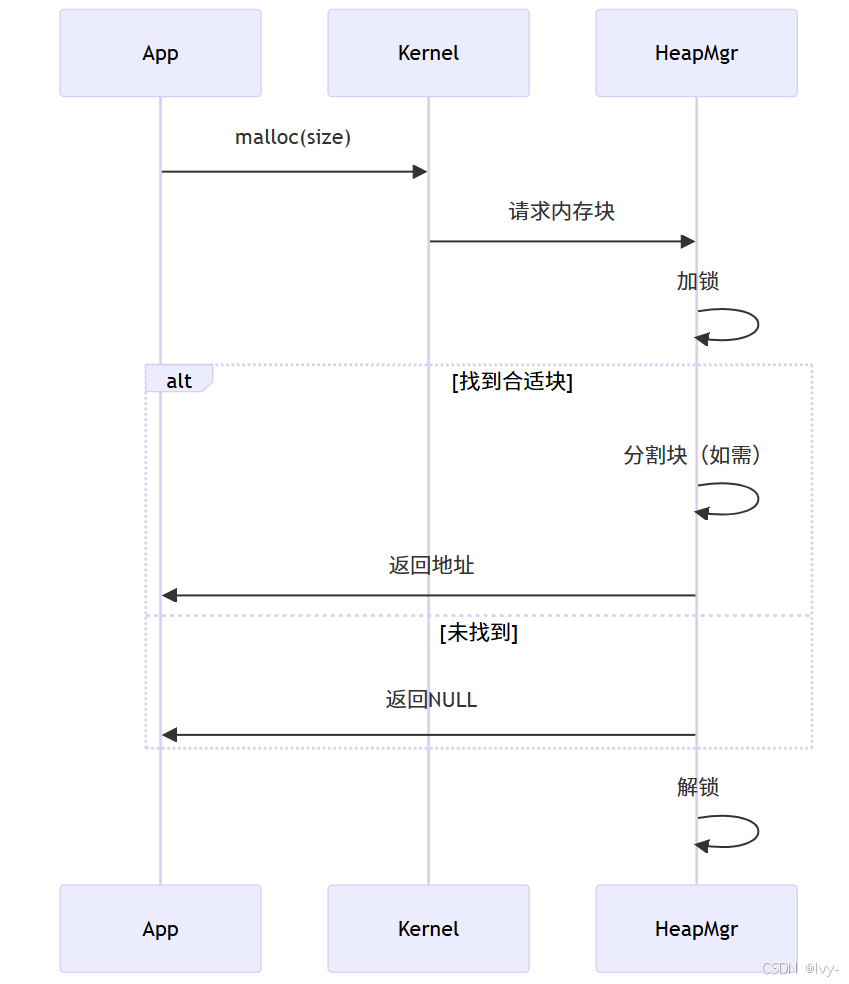
malloc():内存分配,请求指定字节大小的内存块。成功时返回内存块起始地址指针,失败返回NULLfree():释放先前分配的内存块,内存管理器将其标记为空闲。必须及时释放内存防止内存泄漏!
使用示例:
#include <stdlib.h>
#include <stdio.h> int main() {size_t buffer_size = 100;char *my_buffer = (char *)malloc(buffer_size);if (my_buffer == NULL) {printf("内存分配失败!\n");return 1;}// 使用缓冲区...for (size_t i = 0; i < buffer_size; i++) {my_buffer[i] = (char)('A' + (i % 26));}free(my_buffer);return 0;
}
堆管理原理(简化版)
堆管理核心逻辑位于nuttx/mm/mm_heap目录。内存管理器将堆视为由"块"或"节点"组成的内存池,每个节点代表已分配或空闲的内存块。
关键数据结构:
struct mm_allocnode_s:描述已分配块,包含大小和前驱块信息struct mm_freenode_s:描述空闲块,包含双向链表指针struct mm_heap_s:表示堆实例,包含空闲节点列表和互斥锁
其他内存概念
- 粒度分配器(
mm_gran):固定大小的内存分配器,用于DMA等需要对齐的场景 - 共享内存(
shm):内核模式下多进程共享内存的机制,使用shmget/shmat等函数
Kconfig配置选项
关键配置选项:
CONFIG_MM_HEAP_SIZE:主堆大小CONFIG_MM_GRAN:启用粒度分配器CONFIG_ARCH_SHM_MAXREGIONS:共享内存区域配置
结论
内存管理是操作系统的核心功能,有效管理有限的RAM资源。
malloc/free机制通过mm_heap模块实现智能内存管理,mm_gran和shm提供专用内存管理能力。
理解内存管理对开发稳定高效的嵌入式应用至关重要。
下一章我们将探讨中断系统,了解操作系统如何快速响应硬件事件。
中断系统