2022年TASE SCI2区,学习灰狼算法LGWO+随机柔性车间调度,深度解析+性能实测
目录
- 1.摘要
- 2.术语
- 3.随机柔性车间调度
- 4.问题模型
- 5.LGWO算法
- 6.结果展示
- 7.参考文献
- 8.代码获取
- 9.算法辅导·应用定制·读者交流
1.摘要
本研究针对半导体制造环境中的具有受限额外资源和设备相关设置时间的随机柔性作业车间调度问题,这一问题属于NP-难问题。为了在合理的时间内获得可靠且高性能的调度结果,本文提出了一种基于学习的灰狼算法(LGWO)。LGWO设计了一种基于最优计算预算分配(OCBA)的方法,适用于两个来自实际制造环境的情境,用来实现计算资源的智能分配并提高搜索效率,该方法在理论上扩展了最优计算预算分配的应用领域。为了在迭代过程中获得合适的控制参数,本文引入了一种具有新设计延迟更新策略的强化学习算法,用于构建灰狼算法的参数调优机制,该机制能够有效平衡全局搜索与局部搜索之间的关系,从而提升算法性能。
2.术语


3.随机柔性车间调度
经典的作业车间调度问题(JSP)作为一种NP难题,要求将n个作业分配到m台机器上进行处理,并最大化性能。每个作业包含多个操作,这些操作需要按照特定的顺序完成。其推广形式为FJSP,其中多台机器可以处理作业。进一步的推广是随机版本,其中作业或机器的处理时间/设置时间通过随机分布描述,而不是固定的数值。原因在于许多工业过程中,系统可能会出现不可控的干扰,如机器故障、装卸时间变化和设备性能不稳定。
本研究提出了一种基于学习灰狼算法(LGWO),结合了强化学习(RL)和最优计算预算分配(OCBA),有效且高效地解决我们所考虑的问题。
4.问题模型
本文构建了一个混合整数规划模型。,假设所有作业和机器在初始时刻均可用,且一旦某个工序开始加工,中途不得中断。目标函数为最小化期望完工时间:
M i n i m i z e E [ C max ] \mathrm{Minimize~E}[C_{\max}] Minimize E[Cmax]
其中, N M N_M NM为每个个体基本采样次数,通过蒙特卡罗采样计算得到:
E [ C max ] = 1 N M ∑ y = 1 N M C max ( y ) \operatorname{E}[C_{\max}]=\frac{1}{N_M}\sum_{y=1}^{N_M}C_{\max}(y) E[Cmax]=NM1y=1∑NMCmax(y)
C max ( y ) = max i = 1 , ⋯ , n , u = 1 , ⋯ , O i , k = 1 , ⋯ , m t i , u , k c ( y ) C_{\max}(y)=\max_{i=1,\cdots,n,u=1,\cdots,O_{i},k=1,\cdots,m}t_{i,u,k}^{c}(y) Cmax(y)=i=1,⋯,n,u=1,⋯,Oi,k=1,⋯,mmaxti,u,kc(y)
其中, C m a x ( y ) C_{max}(y) Cmax(y)为第 y y y次模拟的最大跨度。操作分配约束:
∑ k ∈ E i , u x i , u , k = 1 , x i , u , k ∈ { 0 , 1 } i = 1 , ⋯ , n , u = 1 , ⋯ , N ˚ i \sum_{k\in\mathbf{E}_{i,u}x_{i,u,k}}=1,x_{i,u,k}\in\{0,1\}i=1,\cdots,n,u=1,\cdots,\mathring{N}_{i} k∈Ei,uxi,u,k∑=1,xi,u,k∈{0,1}i=1,⋯,n,u=1,⋯,N˚i
不确定处理时间约束:
大量柔性作业车间调度问题(FJSPs)的统计结果表明,加工时间通常服从伽马分布或正态分布。Muralidhar 等人建议使用给定的平均加工时间 t i , u , k p t_{i,u,k}^p ti,u,kp和参数 θ \theta θ,来生成第 y y y次采样下的加工时间 t i , u , k g ( y ) t_{i,u,k}^g(y) ti,u,kg(y),其表达为:
t i , u , k g ( y ) ∼ G a m m a ( α i , u , k , β ) t_{i,u,k}^g(y)\sim\mathrm{Gamma}(\alpha_{i,u,k},\beta) ti,u,kg(y)∼Gamma(αi,u,k,β)
加工时间约束决定了第 y y y次采样中工序 O i , u O_{i,u} Oi,u完成时间:
[ t i , u , k b ( y ) + t i , u , k g ( y ) ] x i , u , k = t i , u , k c ( y ) x i , u , k [t_{i,u,k}^b(y)+t_{i,u,k}^g(y)]x_{i,u,k}=t_{i,u,k}^c(y)x_{i,u,k} [ti,u,kb(y)+ti,u,kg(y)]xi,u,k=ti,u,kc(y)xi,u,k
机器相关的设置时间限制:
为了维护不同操作的时间表,作业需要切换到下一台机器。如果一个作业的操作及其后续操作在不同的机器上处理,则需要设置时间。
t i , u + 1 , k b ≥ t i , u , k ′ c + t k ′ , k s t^{b}_{i,u+1,k} \geq t^{c}_{i,u,k'} + t^{s}_{k',k} ti,u+1,kb≥ti,u,k′c+tk′,ks
τ i , u , j , c , k + τ j , c , i , u , k = x i , u , k x j , c , k \tau_{i,u,j,c,k} + \tau_{j,c,i,u,k} = x_{i,u,k} x_{j,c,k} τi,u,j,c,k+τj,c,i,u,k=xi,u,kxj,c,k
机器容量限制:
t i , u , k b ≥ t j , c , k c − D ( 1 − τ i , u , j , c , k ) t_{i,u,k}^b\geq t_{j,c,k}^c-\mathrm{D}(1-\tau_{i,u,j,c,k}) ti,u,kb≥tj,c,kc−D(1−τi,u,j,c,k)
有限的额外资源约束:
∑ k = 1 m η ( k , T ) ⋅ R k ( y ) ≤ R , ∀ T \sum_{k=1}^m\eta_{(k,T)}\cdot\mathbf{R}_k(y)\leq\mathbf{R},\forall T k=1∑mη(k,T)⋅Rk(y)≤R,∀T
5.LGWO算法

采用双段编码向量作为编码器,该向量由机器分配向量和操作顺序向量两部分组成。两个向量的长度均等于操作数,并使用区间 [ 0 , 1 ] [0,1] [0,1]内的正实数作为编码值。
OCBA的目标函数为:
max N 1 , ⋯ , N N p 1 − ∑ h = 1 , h ≠ ∗ N p P { J ~ ∗ > J ~ u } , \max_{N_1,\cdots,N_{N_p}}1-\sum_{h=1,h\neq*}^{N_p}\mathbb{P}\{\tilde{J}^*>\tilde{J}_u\}, N1,⋯,NNpmax1−h=1,h=∗∑NpP{J~∗>J~u},
s . t . ∑ h = 1 N p I h ≤ I T , h = 1 , ⋯ , N p \mathrm{s.t.}\sum_{h=1}^{N_p}I_h\leq I_T,\quad h=1,\cdots,N_p s.t.h=1∑NpIh≤IT,h=1,⋯,Np

在操作前使用RL离线训练参数调优方案。应用强化学习建立参数调优方案的三个重要问题是状态表示、动作构造和奖励函数定义。状态向量需要描述个体的主要特征并跟踪个体的变化:
s = { E t , D t D 0 , V t V 0 , U t U 0 , t N C } T \mathbf{s}=\left\{E^t,\frac{D^t}{D^0},\frac{V^t}{V^0},\frac{U^t}{U^0},\frac{t}{N_C}\right\}^T s={Et,D0Dt,V0Vt,U0Ut,NCt}T
奖励函数:
r ( s , a ) = ∣ ∑ h = 1 N p ψ ( h , a ) N p − ω ∣ r(\mathbf{s},a)=\left|\sum_{h=1}^{N_p}\frac{\psi_{(h,a)}}{N_p}-\omega\right| r(s,a)= h=1∑NpNpψ(h,a)−ω
ψ ( h , a ) = { 1 , f ( x h , a ) − f ( x h ) < 0 0 , f ( x h , a ) − f ( x h ) ≥ 0 \psi_{(h,a)}= \begin{cases} 1, & f(\mathbf{x}_h,a)-f(\mathbf{x}_h)<0 \\ 0, & f(\mathbf{x}_h,a)-f(\mathbf{x}_h)\geq0 & \end{cases} ψ(h,a)={1,0,f(xh,a)−f(xh)<0f(xh,a)−f(xh)≥0
具有延迟更新策略更新:
Q ( s , a ) ← Q ( s , a ) + β ⋅ [ r ( s , a ) + γ ⋅ max Q ( s ′ , a ′ ) − Q ( s , a ) ] \begin{aligned} \mathbf{Q}(\mathbf{s},a) & \leftarrow\mathbf{Q}(\mathbf{s},a) \\ & +\beta\cdot[r(\mathbf{s},a)+\gamma\cdot\max\mathbf{Q}(\mathbf{s}^{\prime},a^{\prime})-\mathbf{Q}(\mathbf{s},a)] \end{aligned} Q(s,a)←Q(s,a)+β⋅[r(s,a)+γ⋅maxQ(s′,a′)−Q(s,a)]

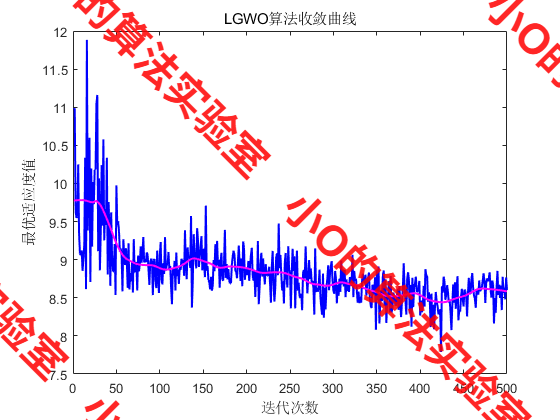
6.结果展示
7.参考文献
[1] Lin C, Cao Z, Zhou M C. Learning-based grey wolf optimizer for stochastic flexible job shop scheduling[J]. IEEE Transactions on Automation Science and Engineering, 2022, 19(4): 3659-3671.
8.代码获取
xx