Tess4J:基于 Java 的 OCR 解决方案
在现代软件开发中,图像识别与文本提取已成为许多应用场景中的关键环节。OCR(Optical Character Recognition) 技术使得从图像中提取文字成为可能。Tess4J 是一个基于 Java 的 OCR 开发库,它封装了 Google Tesseract OCR 引擎的本地调用接口,使得 Java 开发者能够轻松地在项目中集成图像文字识别功能。
Tess4J 的核心优势在于其对原生 Tesseract 库的封装,不仅简化了 API 调用流程,还支持跨平台使用(Windows、Linux、MacOS 等),是 Java 图像识别领域的重要工具之一。
1. OCR 介绍
OCR(Optical Character Recognition,光学字符识别) 是一种将图像中的文字内容转换为可编辑、可搜索的文本格式的技术。它广泛应用于从扫描文档、照片、PDF 文件等图像中提取文字信息,实现自动化数据处理和分析。其核心是通过图像处理与模式识别算法来检测图像中的字符区域,并将其识别为计算机可理解的文本格式(如 ASCII 或 Unicode)。其主要流程包括:
- 图像预处理:去噪、二值化、灰度处理等,提高识别准确性。
- 文字区域检测:定位图像中包含文字的区域。
- 字符分割:将连在一起的文字或单词拆分为单个字符。
- 字符识别:使用机器学习模型或模板匹配技术识别每个字符。
- 后处理与输出:优化识别结果并输出为文本格式。
常见的 OCR 工具与服务:
| 工具/服务名称 | 平台/语言支持 | 支持语言 | 是否付费 | 特点说明 |
| Tesseract OCR | 跨平台(C/C++),支持 Java(Tess4J)等封装 | 英文为主,支持几十种语言(需加载对应 tessdata 文件) | 否 | 开源免费,适合本地部署,精度中等 |
| Google Vision API | 云端 REST API | 多语言支持:英文、中文、日文、韩文、法语等(共约 50+ 种语言) | 是 | 高精度识别,支持表格、手写体、复杂排版,需网络连接 |
| 百度 OCR | 云端 API / SDK | 中文、英文、数字、车牌、身份证、护照等特定场景 | 部分免费 | 中文识别强,适合国内应用场景,有免费额度限制 |
| ABBYY FineReader | Windows / macOS | 支持 190+ 种语言 | 是 | 商业软件,识别准确率高,界面友好,价格较高 |
| Microsoft Azure Computer Vision | 云端 API | 英文、中文、西班牙语、法语、德语、日语等主流语言 | 是 | 支持多语言和表格识别,集成于 Azure 生态 |
| Amazon Textract | AWS 云端服务 | 英文、中文、西班牙语等 | 是 | 提取文档中的文本、表格、表单结构,适合企业级文档处理 |
| OpenCV + 深度学习模型 | 自定义开发(Python、Java 等) | 取决于训练模型(可定制化) | 否 | 灵活但开发门槛高,适合有 AI 能力的团队 |
| MyScript | Web / SDK | 英文、中文、日文、阿拉伯语等 | 是 | 手写识别能力强,适合教育、笔记类应用 |
| PaddleOCR(百度飞桨) | Python / C++ / Java | 支持中英文、数字、符号、多种字体 | 否 | 开源项目,轻量级,适合本地部署或自定义训练 |
2. 简单验证码识别(无干扰项)使用步骤
1. 添加依赖
<dependency><groupId>net.java.dev.jna</groupId><artifactId>jna</artifactId><version>4.2.1</version>
</dependency>
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.1</version>
</dependency>2. 下载 Tesseract 数据
下载地址:https://github.com/tesseract-ocr/tessdata
这里以放在 resources/tessdata 目录为例:

常见语言包列表及用途说明:
参考文档:Traineddata Files for Version 4.00 + | tessdoc
| 文件名 | 语言 | 备注 |
| afr.traineddata | 南非语 (Afrikaans) | —— |
| amh.traineddata | 阿姆哈拉语 (Amharic) | —— |
| ara.traineddata | 阿拉伯语 (Arabic) | —— |
| asm.traineddata | 阿萨姆语 (Assamese) | —— |
| aze.traineddata | 阿塞拜疆语 (Azerbaijani) | —— |
| aze_cyrl.traineddata | 阿塞拜疆语(西里尔字母) | Cyrillic 字符集 |
| bel.traineddata | 白俄罗斯语 (Belarusian) | —— |
| ben.traineddata | 孟加拉语 (Bengali) | —— |
| bod.traineddata | 藏语 (Tibetan) | —— |
| bos.traineddata | 波斯尼亚语 (Bosnian) | —— |
| bre.traineddata | 布列塔尼语 (Breton) | —— |
| bul.traineddata | 保加利亚语 (Bulgarian) | —— |
| cat.traineddata | 加泰罗尼亚语 (Catalan; Valencian) | —— |
| ceb.traineddata | 宿务语 (Cebuano) | —— |
| ces.traineddata | 捷克语 (Czech) | —— |
| chi_sim.traineddata | 中文简体 (Chinese - Simplified) | 常用字识别 |
| chi_sim_vert.traineddata | 中文简体竖排 | 竖排文字识别 |
| chi_tra.traineddata | 中文繁体 (Chinese - Traditional) | —— |
| chi_tra_vert.traineddata | 中文繁体竖排 | —— |
| chr.traineddata | 切罗基语 (Cherokee) | —— |
| cym.traineddata | 威尔士语 (Welsh) | —— |
| dan.traineddata | 丹麦语 (Danish) | —— |
| dan_frak.traineddata | 丹麦语(Fraktur 字体) | 古德语字体风格 |
| deu.traineddata | 德语 (German) | —— |
| deu_frak.traineddata | 德语(Fraktur 字体) | —— |
| div.traineddata | 迪维希语 (Dhivehi) | —— |
| dzo.traineddata | 不丹语 (Dzongkha) | —— |
| ell.traineddata | 希腊语 (Greek, Modern) | —— |
| eng.traineddata | 英语 (English) | 推荐使用 |
| enm.traineddata | 中古英语 (Middle English) | 古英语识别 |
| epo.traineddata | 世界语 (Esperanto) | —— |
| est.traineddata | 爱沙尼亚语 (Estonian) | —— |
| eus.traineddata | 巴斯克语 (Basque) | —— |
| fas.traineddata | 波斯语 (Persian) | —— |
| fao.traineddata | 法罗语 (Faroese) | —— |
| fra.traineddata | 法语 (French) | —— |
| frm.traineddata | 中古法语 (Middle French) | —— |
| fry.traineddata | 弗里斯兰语 (Western Frisian) | —— |
| gla.traineddata | 苏格兰盖尔语 (Scottish Gaelic) | —— |
| gle.traineddata | 爱尔兰语 (Irish) | —— |
| glg.traineddata | 加利西亚语 (Galician) | —— |
| grc.traineddata | 古希腊语 (Ancient Greek) | —— |
| guj.traineddata | 古吉拉特语 (Gujarati) | —— |
| hat.traineddata | 海地克里奥尔语 (Haitian; Haitian Creole) | —— |
| heb.traineddata | 希伯来语 (Hebrew) | —— |
| hin.traineddata | 印地语 (Hindi) | —— |
| hrv.traineddata | 克罗地亚语 (Croatian) | —— |
| hun.traineddata | 匈牙利语 (Hungarian) | —— |
| hye.traineddata | 亚美尼亚语 (Armenian) | —— |
| iku.traineddata | 因纽特语 (Inuktitut) | —— |
| ind.traineddata | 印度尼西亚语 (Indonesian) | —— |
| isl.traineddata | 冰岛语 (Icelandic) | —— |
| ita.traineddata | 意大利语 (Italian) | —— |
| ita_old.traineddata | 意大利语(旧字体) | —— |
| jav.traineddata | 爪哇语 (Javanese) | —— |
| jpn.traineddata | 日语 (Japanese) | 含平假名、片假名和常用汉字 |
| jpn_vert.traineddata | 日语竖排 | —— |
| kan.traineddata | 卡纳达语 (Kannada) | —— |
| kas.traineddata | 克什米尔语 (Kashmiri) | —— |
| kat.traineddata | 格鲁吉亚语 (Georgian) | —— |
| kat_old.traineddata | 格鲁吉亚语(旧字体) | —— |
| kaz.traineddata | 哈萨克语 (Kazakh) | —— |
| khm.traineddata | 高棉语 (Central Khmer) | —— |
| kir.traineddata | 吉尔吉斯语 (Kyrgyz) | —— |
| kmr.traineddata | 库尔德语北部方言 (Northern Kurdish) | —— |
| kor.traineddata | 韩语 (Korean) | —— |
| kor_vert.traineddata | 韩语竖排 | —— |
| lao.traineddata | 老挝语 (Lao) | —— |
| lat.traineddata | 拉丁语 (Latin) | —— |
| lav.traineddata | 拉脱维亚语 (Latvian) | —— |
| lit.traineddata | 立陶宛语 (Lithuanian) | —— |
| ltz.traineddata | 卢森堡语 (Luxembourgish) | —— |
| mal.traineddata | 马拉雅拉姆语 (Malayalam) | —— |
| mar.traineddata | 马拉地语 (Marathi) | —— |
| mkd.traineddata | 马其顿语 (Macedonian) | —— |
| mlt.traineddata | 马耳他语 (Maltese) | —— |
| mon.traineddata | 蒙古语 (Mongolian) | —— |
| mri.traineddata | 毛利语 (Maori) | —— |
| msa.traineddata | 马来语 (Malay) | —— |
| mya.traineddata | 缅甸语 (Burmese) | —— |
| nep.traineddata | 尼泊尔语 (Nepali) | —— |
| nld.traineddata | 荷兰语 (Dutch; Flemish) | —— |
| nor.traineddata | 挪威语 (Norwegian) | —— |
| oci.traineddata | 奥克西坦语 (Occitan) | —— |
| ori.traineddata | 奥里亚语 (Oriya) | —— |
| osd.traineddata | 方向与段落检测 | —— |
| pan.traineddata | 旁遮普语 (Eastern Punjabi) | —— |
| pap.traineddata | 帕皮阿门托语 (Papiamento) | —— |
| pol.traineddata | 波兰语 (Polish) | —— |
| por.traineddata | 葡萄牙语 (Portuguese) | —— |
| pus.traineddata | 普什图语 (Pashto) | —— |
| que.traineddata | 克丘亚语 (Quechua) | —— |
| ron.traineddata | 罗马尼亚语 (Romanian; Moldavian; Moldovan) | —— |
| rus.traineddata | 俄语 (Russian) | —— |
| san.traineddata | 梵语 (Sanskrit) | —— |
| sin.traineddata | 僧伽罗语 (Sinhala) | —— |
| slk.traineddata | 斯洛伐克语 (Slovak) | —— |
| slv.traineddata | 斯洛文尼亚语 (Slovenian) | —— |
| snd.traineddata | 信德语 (Sindhi) | —— |
| spa.traineddata | 西班牙语 (Spanish; Castilian) | —— |
| spa_old.traineddata | 西班牙语(旧字体) | —— |
| sqi.traineddata | 阿尔巴尼亚语 (Albanian) | —— |
| srp.traineddata | 塞尔维亚语 (Serbian) | —— |
| srp_latn.traineddata | 塞尔维亚语(拉丁字母) | —— |
| sun.traineddata | 巽他语 (Sundanese) | —— |
| swa.traineddata | 斯瓦希里语 (Swahili) | —— |
| swe.traineddata | 瑞典语 (Swedish) | —— |
| syr.traineddata | 叙利亚语 (Syriac) | —— |
| tam.traineddata | 泰米尔语 (Tamil) | —— |
| tat.traineddata | 鞑靼语 (Tatar) | —— |
| tel.traineddata | 泰卢固语 (Telugu) | —— |
| tgk.traineddata | 塔吉克语 (Tajik) | —— |
| tgl.traineddata | 他加禄语 (Tagalog) | —— |
| tha.traineddata | 泰语 (Thai) | —— |
| tir.traineddata | 提格利尼亚语 (Tigrinya) | —— |
| ton.traineddata | 汤加语 (Tonga) | —— |
| tur.traineddata | 土耳其语 (Turkish) | —— |
| uig.traineddata | 维吾尔语 (Uighur; Uyghur) | —— |
| ukr.traineddata | 乌克兰语 (Ukrainian) | —— |
| urd.traineddata | 乌尔都语 (Urdu) | —— |
| uzb.traineddata | 乌兹别克语 (Uzbek) | —— |
| uzb_cyrl.traineddata | 乌兹别克语(西里尔字母) | —— |
| vie.traineddata | 越南语 (Vietnamese) | —— |
| yid.traineddata | 意第绪语 (Yiddish) | —— |
| yor.traineddata | 约鲁巴语 (Yoruba) | —— |
3. 编写识别代码
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;import java.io.File;public static void main(String[] args) {String dataPath = "src/main/resources/tessdata";String imagePath = "src/main/resources/image/img.png";try {// 获取本地图片File file = new File(imagePath);// 创建Tesseract对象ITesseract tesseract = new Tesseract();// 设置字体库路径tesseract.setDatapath(dataPath);// 设置识别语言tesseract.setLanguage("eng");// 执行ocr识别String result = tesseract.doOCR(file);System.out.println("识别的结果为:" + result);} catch (Exception e) {e.printStackTrace();}
}3. 复杂验证码识别(带干扰项)使用步骤
1. 加入maven依赖
<dependency><groupId>org.openpnp</groupId><artifactId>opencv</artifactId><version>4.9.0-0</version>
</dependency>2. 选择和 maven 依赖相同版本的 opencv下载
下载地址:https://sourceforge.net/projects/opencvlibrary/files/
以该示例为例,Windows 版本下载如下图所示:
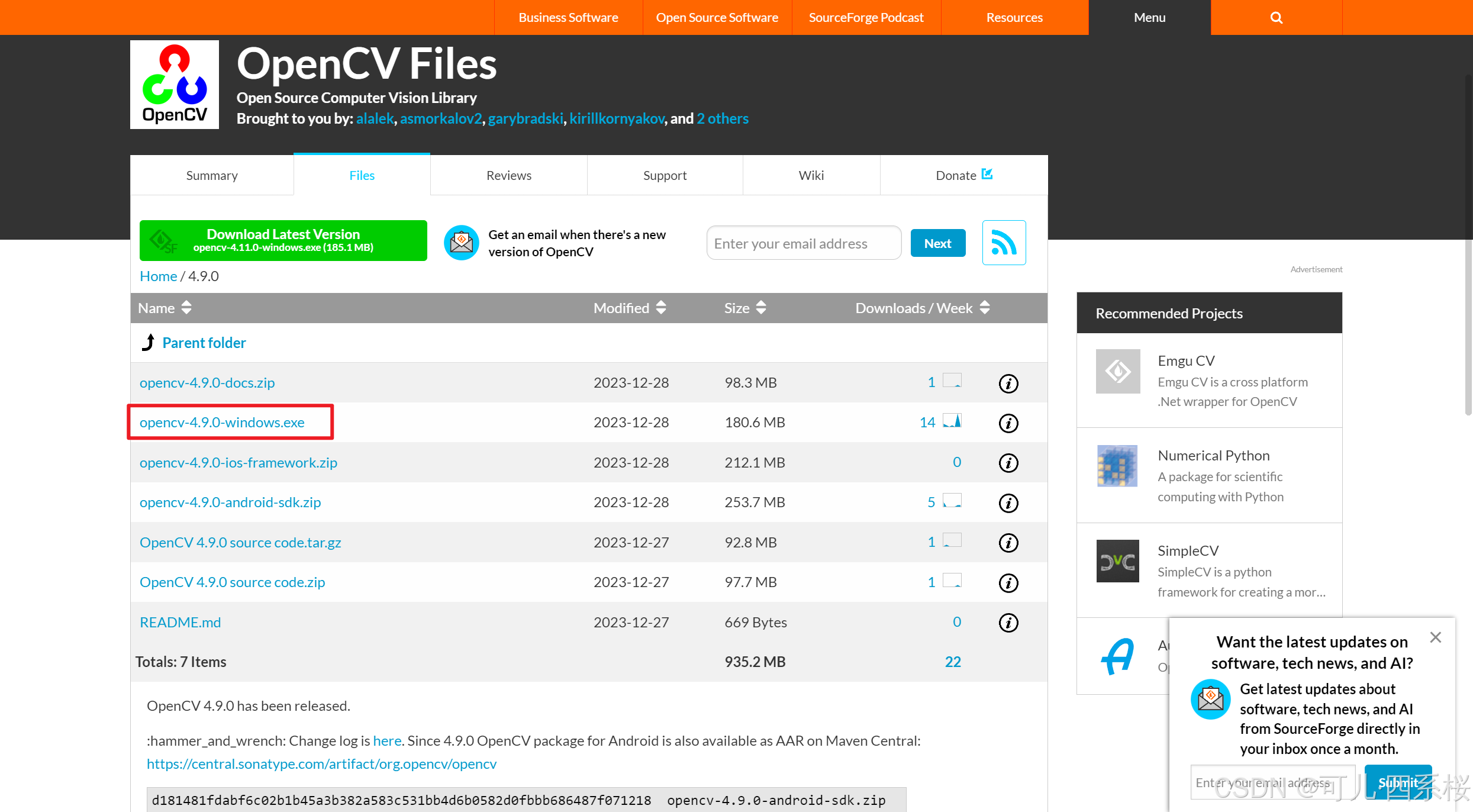
选择下载位置后点击安装即可。
选择版本说明:
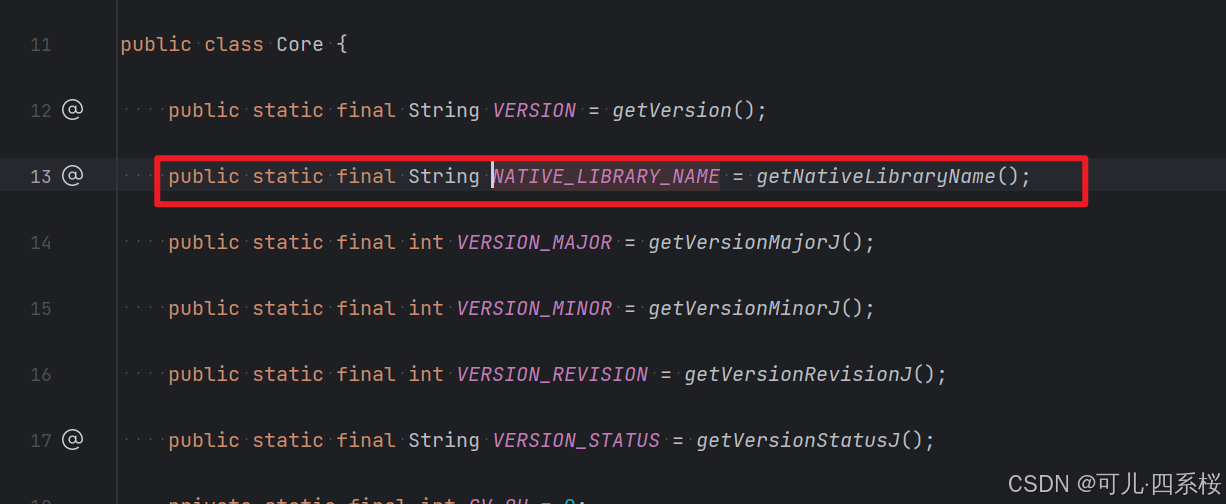
1. 点击 Core.NATIVE_LIBRARY_NAME 常量:
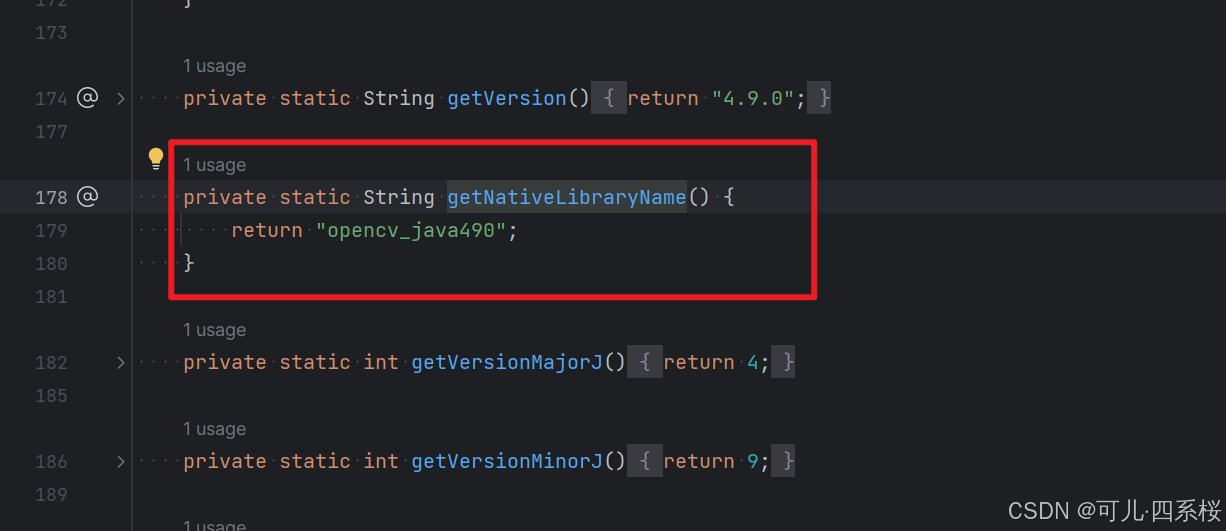
2. 点击 getNativeLibraryName() 方法:
这个就是要找的 dll 文件,即 opencv 的版本。这个常量根据 opencv 版本的不同,常量也随之变化。
3. 带干扰项验证码处理(灰度化、二值化等操作)
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import org.opencv.core.Core;
import org.opencv.core.Mat;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.imgproc.Imgproc;import java.io.File;
import java.io.IOException;public class CaptchaPreprocessor {static {//在使用OpenCV前必须加载Core.NATIVE_LIBRARY_NAME类,否则会报错System.loadLibrary(Core.NATIVE_LIBRARY_NAME);}public static void main(String[] args) throws IOException {String imagePath = "src/main/resources/img.png";String outputImagePath = "src/main/resources/img/img.png";String tessDataPath = "src/main/resources/tessdata";try {// 1. 使用 OpenCV 预处理图像Mat src = Imgcodecs.imread(imagePath, Imgcodecs.IMREAD_COLOR);if (src.empty()) {System.err.println("无法加载图像,请检查路径是否正确:" + imagePath);return;}Mat processed = new Mat();// 灰度化Mat gray = new Mat();Imgproc.cvtColor(src, gray, Imgproc.COLOR_BGR2GRAY);// 对比度增强(CLAHE)Mat clahe = new Mat();Imgproc.createCLAHE(2.0, new org.opencv.core.Size(8, 8)).apply(gray, clahe);// 自适应二值化Mat binary = new Mat();Imgproc.adaptiveThreshold(clahe, binary, 255, Imgproc.ADAPTIVE_THRESH_GAUSSIAN_C,Imgproc.THRESH_BINARY, 11, 2);// 形态学操作去干扰线Mat kernel = Imgproc.getStructuringElement(Imgproc.MORPH_RECT, new org.opencv.core.Size(1, 3));Imgproc.morphologyEx(binary, processed, Imgproc.MORPH_OPEN, kernel);// 保存处理后的图像File destF = new File(outputImagePath).getParentFile();if (!destF.exists()) {destF.mkdirs();}boolean success = Imgcodecs.imwrite(outputImagePath, processed);if (!success) {System.err.println("图像保存失败,请检查路径或 Mat 是否为空");}// 2. 使用 Tess4J 进行 OCR 识别ITesseract tesseract = new Tesseract();tesseract.setDatapath(tessDataPath); // 设置 tessdata 路径tesseract.setLanguage("eng"); // 英文识别tesseract.setPageSegMode(7); // 单行文本识别File imageFile = new File(imagePath);String result = tesseract.doOCR(imageFile);// 输出识别结果System.out.println("识别结果: " + result.trim());} catch (Exception e) {System.err.println("识别失败: " + e.getMessage());e.printStackTrace();}}
}4. 配置 VM options,添加 -Djava.library.path=安装位置\opencv\build\java\x64。(如果 java -jar 启动的话,可以直接添加 -Djava.library.path=安装位置\opencv\build\java\x64 或 --java.library.path=安装位置\opencv\build\java\x64)
以配置 VM options 为例,具体操作流程如下图所示:
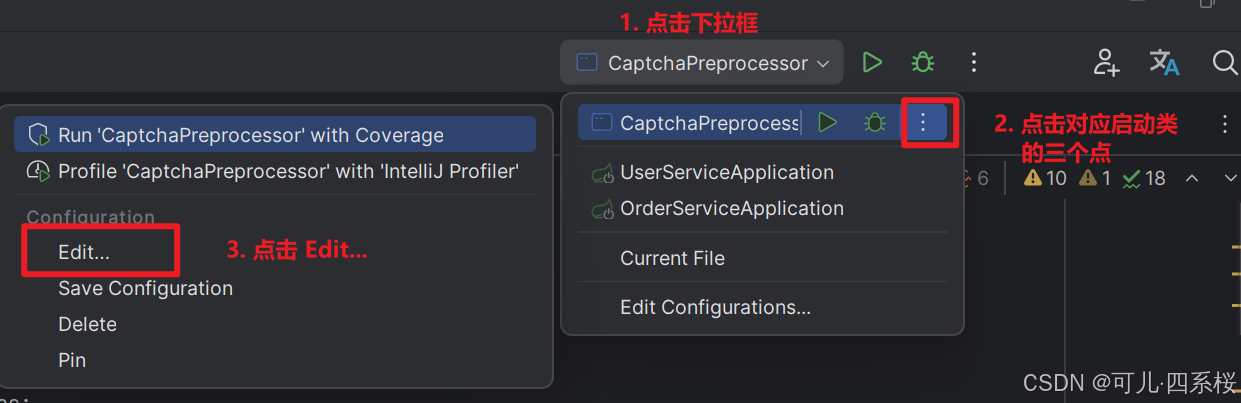
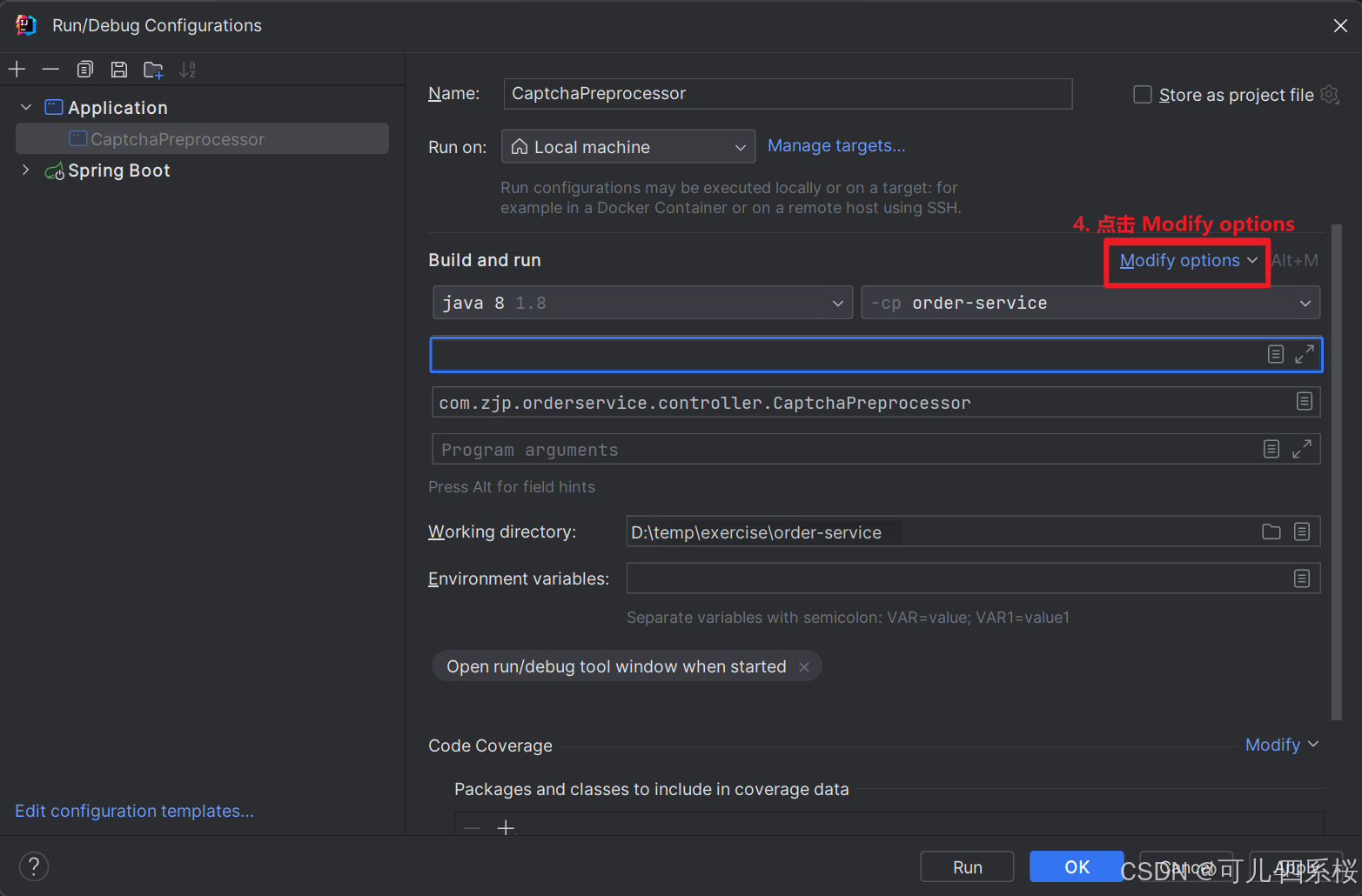
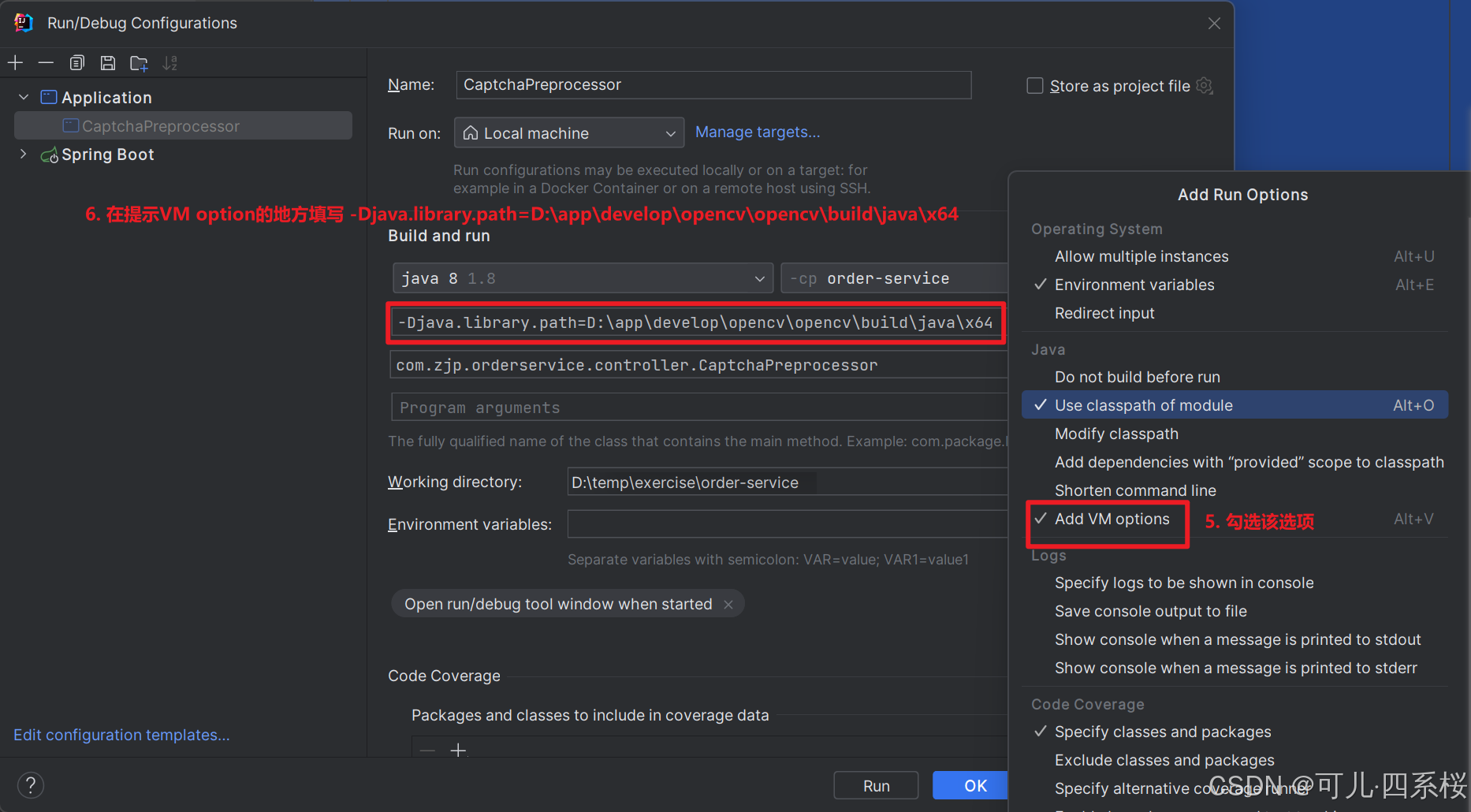
关于配置 java.library.path 说明:
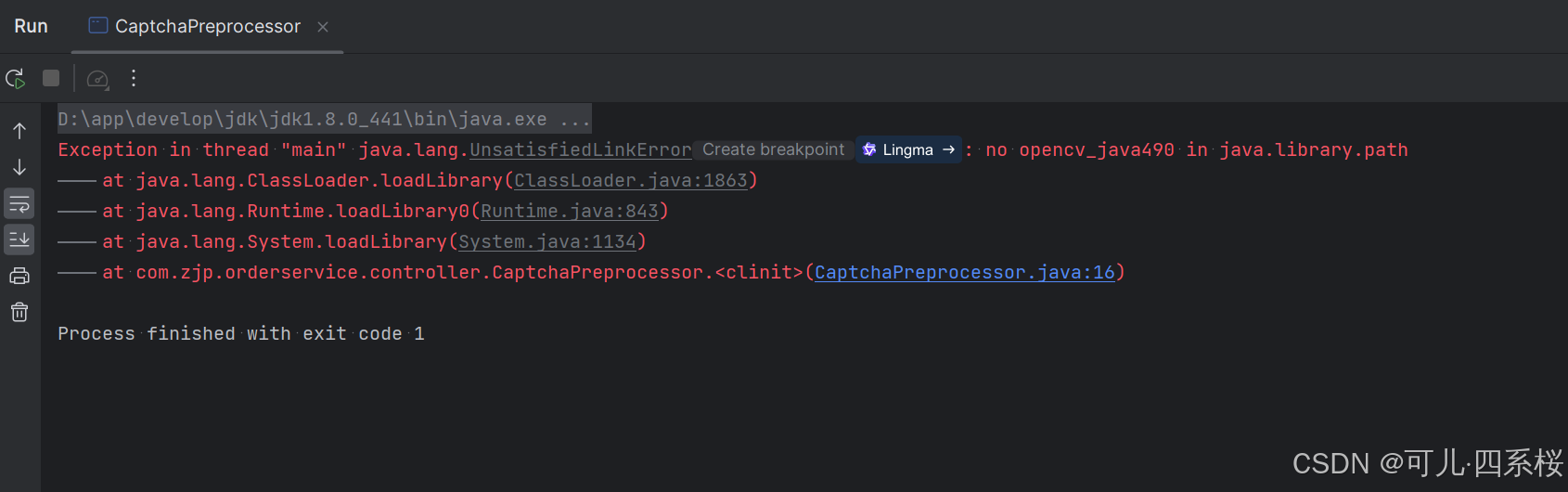
1. 在未配置 -Djava.library.path 之前启动项目会报如下错误:
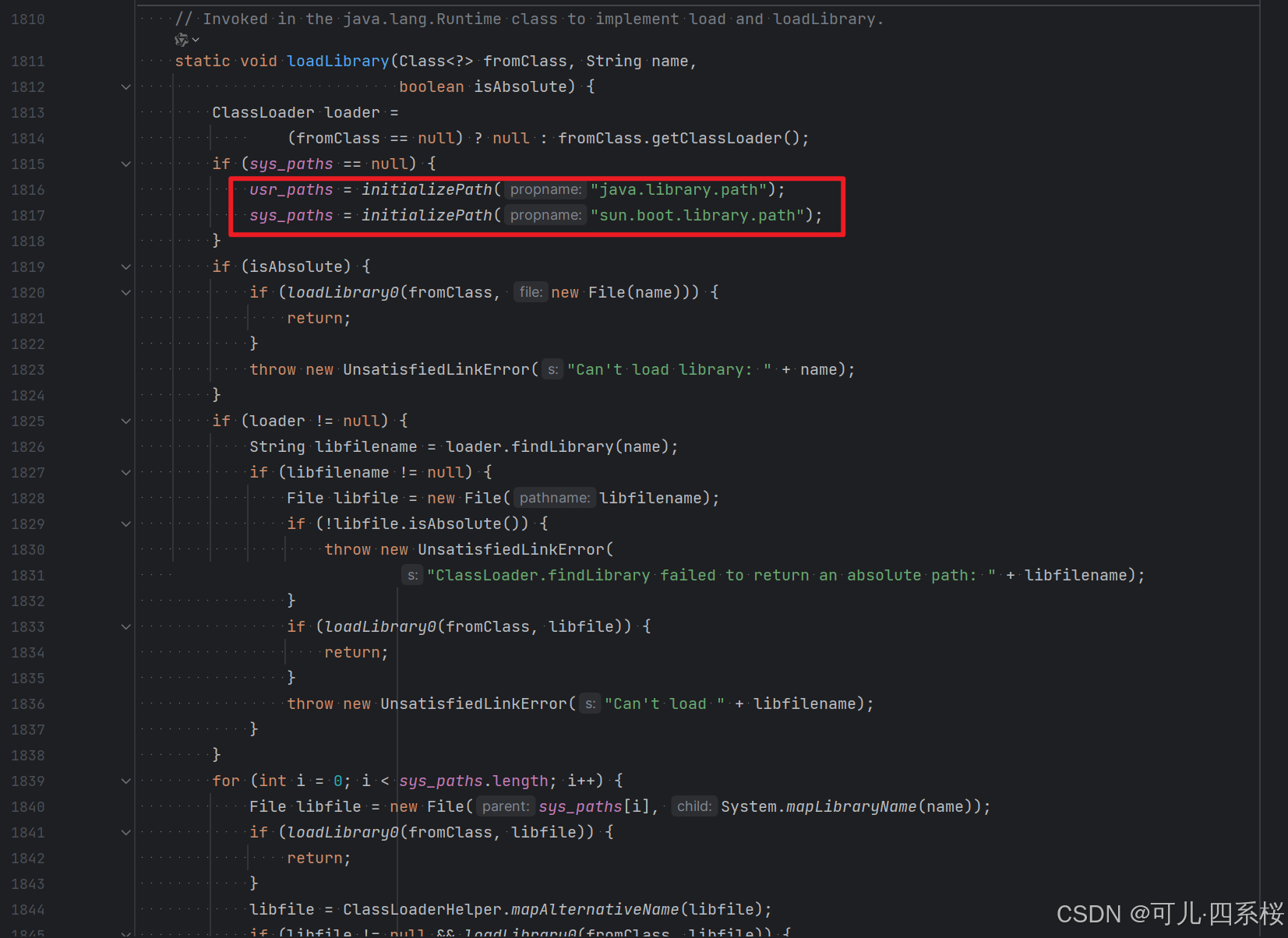
2. 点击 ClassLoader.java:1863
从该图可以看出,他读取 java.library.path 和 sun.boot.library.path 这两个路径。所以说 -Djava.library.path 可以替换为 -Dsun.boot.library.path。
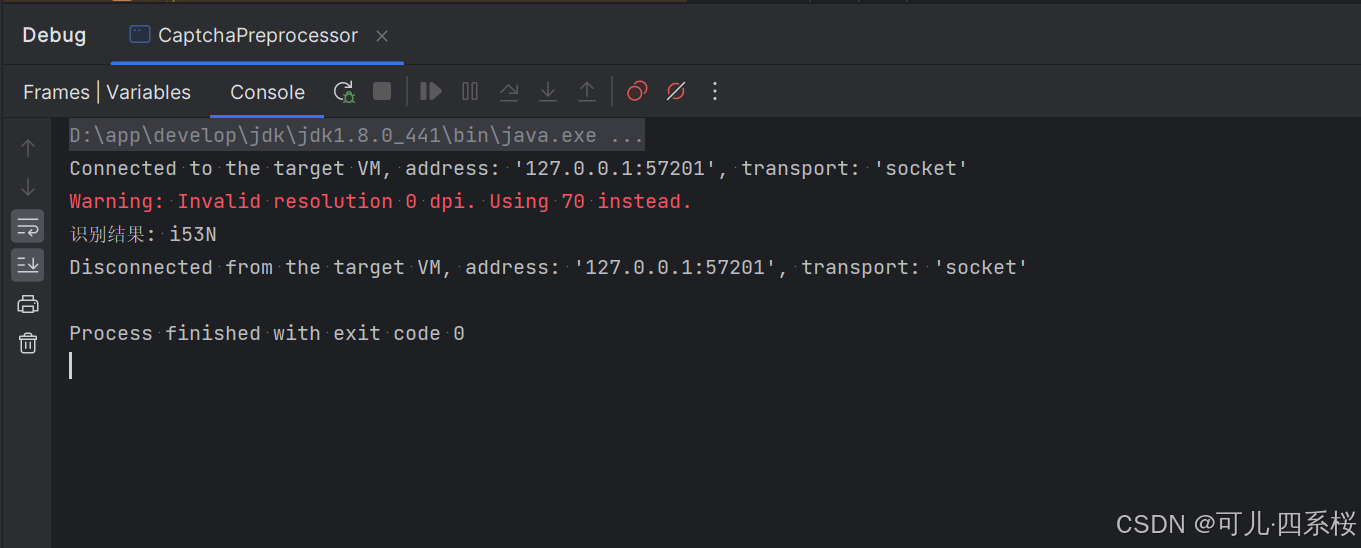
4. 执行测试
以下面这个图片为例:
![]()
原图片经过去噪、二值化等操作处理后:
![]()
识别结果为: