linux安装阿里DataX实现数据迁移
目录
下载datax工具包(如果下载慢,请尝试其他国内镜像站或其他网站下载相应资源)
解压工具包到当前目录里
接着进入conf配置目录并创建一个myjob.json(临时测试json),myjob.json内容如下,用于模拟test库tab1表数据同步到test_copy库tab1表:
写好上述模拟配置文件后,从当前目录进入conf目录编辑然后执行数据同步,执行前两个库表数据如下编辑
注意事项:如果执行上述同步命令的时候,无法识别pathon命令,则需要在linux服务器安装并配置python,具体如何安装及配置,请自行百度
下载datax工具包(如果下载慢,请尝试其他国内镜像站或其他网站下载相应资源)
wget https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202308/datax.tar.gz
解压工具包到当前目录里
tar -zxvf ../datax.tar.gz -C .
解压后工具包名为datax,进入datax目录,文件结构如下
接着进入conf配置目录并创建一个myjob.json(临时测试json),myjob.json
内容如下,用于模拟test库tab1表数据同步到test_copy库tab1表:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"`id`",
"`name`",
"`create_time`"
],
"splitPk": "",
"connection": [
{
"table": [
"tab1"
],
"jdbcUrl": [
"jdbc:mysql://192.168.7.231:3306/test?useSSL=false&serverTimezone=Asia/Shanghai"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "root",
"column": [
"`id`",
"`name`",
"`create_time`"
],
"writeMode": "replace",
"preSql": ["TRUNCATE TABLE tab1"],
"connection": [
{
"table": [
"tab1"
],
"jdbcUrl": "jdbc:mysql://192.168.7.231:3306/test_copy?useSSL=false&serverTimezone=Asia/Shanghai"
}
]
}
}
}
]
}
}
特别参数说明
| channel | 控制同步速度,channel 表示并发通道数(即并行读写线程数量,根据系统资源来设定) |
| errorLimit>>record | 最大允许错误记录数(0表示不允许任何错误) |
| errorLimit>>percentage | 允许的错误比例上限(即总记录数的2%) |
| reader | 读(源库)插件配置 |
| column | 源库表的列字段数组 |
| splitPk | 分片键字段名,为空表示不分片 |
| writer | 写(目标库)插件配置 |
| writeMode | 写入模式:replace 表示使用 REPLACE INTO |
| preSql | 写入前执行的SQL语句 |
写好上述模拟配置文件后,从当前目录进入conf目录

然后执行数据同步,执行前两个库表数据如下
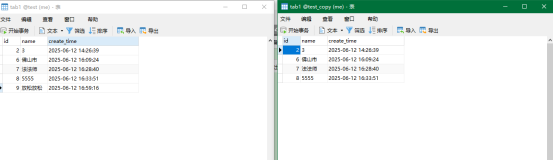
现在开始执行数据同步python datax.py ../conf/myjob.json
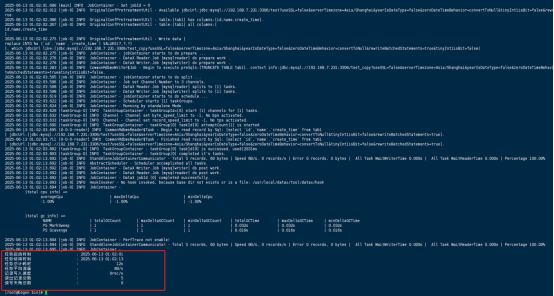
上图结果表示同步成功,然后查看同步后的两个库表的数据,发现已经一致了