一种TFTransforme扩散模型时间序列预测模型, pytorch架构
代码介绍
TFTransforme扩散模型时间序列预测模型
python代码 pytorch架构
时间融合变换器(TFT),这是一种热门新颖的基于注意力的架构,结合了高性能的多层次预测和对时间动态的可解释洞察。为了学习不同尺度的时间关系,TFT使用递归层进行局部处理,并使用可解释的自注意力层来处理长期依赖。
功能如下:
1.多变量输入,单变量输出
2.多时间步预测,单时间步预测
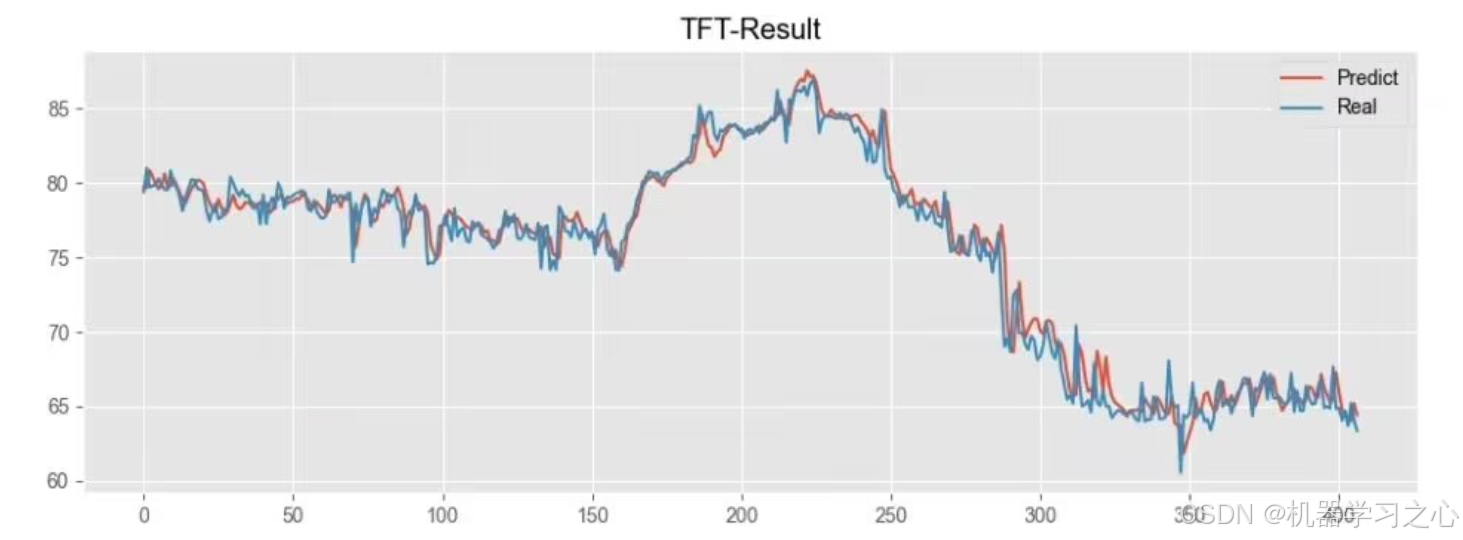
3.R方,MAE,MSE MAPE对比图,误差
4.将结果保存下来供后续处理
5.代码自带数据,一键运行,csv,xlsx文件读取数据,也可以替换自己数据集很简单。
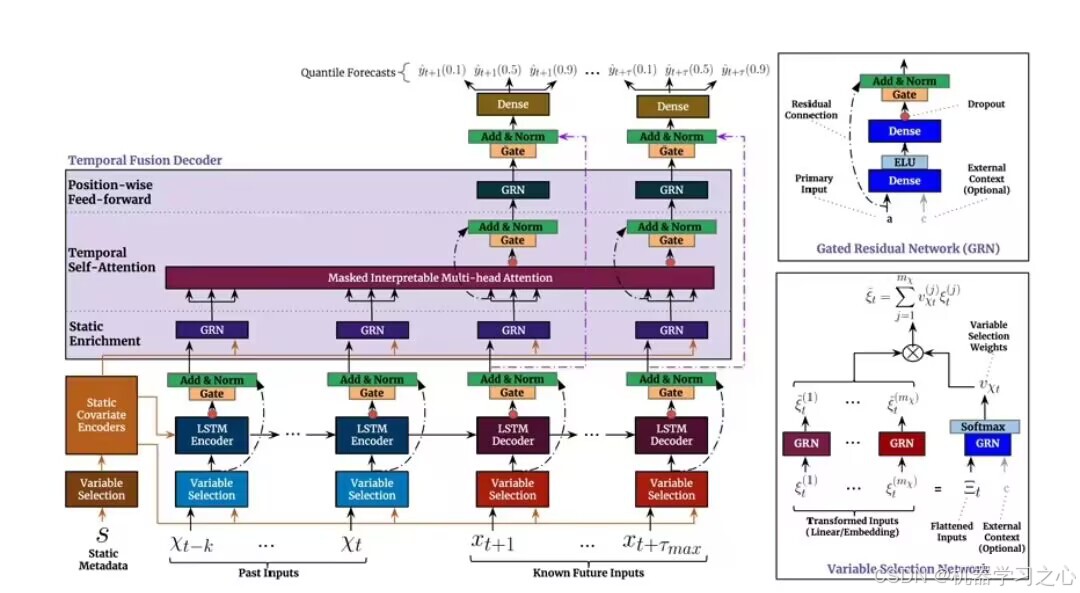
TFT的核心架构与设计原理
TFT是一种结合注意力机制与递归网络的混合架构,旨在解决多水平时间序列预测中的复杂依赖关系、混合数据类型处理及模型可解释性问题。其核心组件如下:
1. 递归层(LSTM)的局部处理机制
- 作用:捕获短期依赖与局部时间模式(如近期波动、事件响应)。
- 实现方式:
- 使用多层LSTM处理时间序列输入,其中:
- 编码器:处理历史数据(动态未知变量)。
- 解码器:结合已知未来输入(动态已知变量)生成预测。
- 门控机制:通过输入门、遗忘门、输出门控制信息流动,增强对重要特征的记忆能力:
c t = f t ⊙ c t − 1 + i t ⊙ g t , h t = o t ⊙ tanh ( c t ) c_t = f_t \odot c_{t-1} + i_t \odot g_t, \quad h_t = o_t \odot \tanh(c_t) ct=ft⊙ct−1+it⊙gt,ht=ot⊙tanh(ct)
其中 f t , i t , o t f_t, i_t, o_t ft,it,ot 分别为遗忘门、输入门、输出门的激活值, g t g_t gt 为候选状态。 - 参数优化:支持GPU加速(如cuDNN实现),使用
tanh激活与sigmoid递归激活。
- 门控机制:通过输入门、遗忘门、输出门控制信息流动,增强对重要特征的记忆能力:
2. 可解释自注意力层的长期依赖建模
- 设计目标:解决Transformer在时间序列中的信息泄露问题,提升可解释性。
- 关键技术:
- 掩码自注意力(Masked Self-Attention):
防止未来信息影响当前预测,仅允许历史时间步参与权重计算:
Attention ( Q , K , V ) = Softmax ( Q K T d k + M ) V \text{Attention}(Q,K,V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=Softmax(dkQKT+M)V
其中 M M M 为下三角掩码矩阵( M i j = − ∞ if i < j M_{ij}=-\infty \text{ if } i<j Mij=−∞ if i<j)。 - 可解释多头注意力(Interpretable Multi-Head Attention):
- 掩码自注意力(Masked Self-Attention):
- 各注意力头共享值矩阵 W V W_V WV,使注意力权重 A ‾ = 1 H ∑ h = 1 H A h \overline{A} = \frac{1}{H}\sum_{h=1}^H A_h A=H1∑h=1HAh 可解释为“不同时间模式的重要性”。
- 输出为加权平均值: Output = A ‾ V \text{Output} = \overline{A} V Output=AV,直接反映时间步间的依赖强度。
- 块状掩码(Blockwise Masking):
扩展至时空数据,以时间点为单位屏蔽未来信息(如预测 t i t_i ti 时屏蔽所有 t j > t i t_j>t_i tj>ti 的数据)。
- 块状掩码(Blockwise Masking):
3. 其他关键组件
- 变量选择网络(Variable Selection Networks, VSN):
动态评估特征重要性,通过门控残差网络(GRN)生成权重:
w = Softmax ( GRN ( x ) ) , x ~ = ∑ w i x i w = \text{Softmax}(\text{GRN}(x)), \quad \tilde{x} = \sum w_i x_i w=Softmax(GRN(x)),x~=∑wixi
区分静态/动态/历史/未来变量的贡献。 - 静态协变量编码器:
将静态特征(如门店ID)编码为上下文向量,初始化LSTM状态。 - 门控与残差连接:
抑制冗余模块,提升训练效率(如跳过无关的LSTM层)。 - 分位数预测输出:
同时输出多分位数(如P10、P50、P90),量化预测不确定性。
TFT与传统模型的对比优势
| 维度 | TFT | 传统模型(LSTM/Transformer) |
|---|---|---|
| 输入处理 | 动态区分静态/动态/历史/未来变量 | 未明确区分变量类型,混合处理 |
| 可解释性 | 提供特征权重+时间依赖可视化(VSN+注意力) | 黑盒模型,依赖事后解释工具 |
| 多尺度建模 | LSTM(局部)+ 注意力(全局)融合 | LSTM仅局部依赖,Transformer忽略短期模式 |
| 预测策略 | 直接多水平预测,避免误差累积 | 迭代预测易累积误差(如DeepAR) |
| 不确定性量化 | 分位数输出,支持风险管理 | 多数模型仅输出点估计 |
| 性能表现 | 平均P50损失降低7%,P90降低9% | 基准模型(如MQRNN)表现次优 |
案例验证:在电力需求预测中,TFT通过注意力权重识别出“工作日早高峰”的长期依赖,而VSN显示温度变量权重高达0.8,解释预测峰值。
多尺度时间关系建模的实现
TFT通过分层机制融合不同时间尺度:
- 局部尺度(LSTM层):
- 处理高频波动(如过去10笔交易收益率)。
- 输出状态 h t local h_t^{\text{local}} htlocal 捕获短期模式(如突发流量峰值)。
- 全局尺度(注意力层):
- 建模长周期规律(如过去30天波动率)。
- 注意力权重 α t , i \alpha_{t,i} αt,i 揭示 t t t 时刻对历史 i i i 时刻的依赖强度(如季节性高峰)。
- 动态融合机制:
- 时序融合层(Temporal Fusion Layer)整合 h t local h_t^{\text{local}} htlocal 与注意力输出,公式:
y t = GRN ( Concat ( h t local , ∑ i α t , i V i ) ) y_t = \text{GRN}\left( \text{Concat}(h_t^{\text{local}}, \sum_i \alpha_{t,i} V_i) \right) yt=GRN(Concat(htlocal,i∑αt,iVi))
实现短期响应与长期趋势的协同。
- 时序融合层(Temporal Fusion Layer)整合 h t local h_t^{\text{local}} htlocal 与注意力输出,公式:
实证效果:在印尼股价预测中,TFT对“突发新闻”的短期波动(LSTM捕获)和“季度财报”的长期影响(注意力捕获)的融合误差比单一模型低12%。
应用场景
- 金融预测:
- 收益率曲线建模中,TFT通过分位数输出指导债券交易策略,年化收益提升15%。
- 能源需求预测:
- 英国电力公司OVO Energy应用TFT,电价预测误差降低9%,优化储能调度。
- 零售销售预测:
- 处理异构数据(促销活动+节假日静态变量),准确率超传统模型11%。
- 医疗监测:
- 结合患者静态特征(病史)与动态监测数据,预测疾病进展的RMSE降低18%。
总结:TFT的核心创新
- 架构融合:LSTM(局部) + 注意力(全局) + 门控(动态路由)。
- 可解释性:VSN(特征重要性) + 可解释注意力(时间依赖)。
- 概率预测:分位数输出支持不确定性量化。
- 工业级效率:模块化设计支持GPU并行,训练速度比DeepAR快3倍。