【AI应用开发数据基建】从非结构化数据到结构化知识的通用转化流程
一、数据准备阶段
数据采集与输入
-
来源识别:确定数据来源(文档、视频、音频、图片、社交媒体等)
-
批量处理:设计可扩展的批量处理机制
在批量处理非结构化数据的第一步进行数据情况统计时,以下是需要注意的关键要点:
1. 基础量级统计
-
文件总量:确认待处理文件的总数量级(百/千/百万级)
-
存储规模:统计原始数据总占用空间(GB/TB/PB)
-
类型分布:按扩展名分类统计(PDF/视频/图像等各占比例)
2. 非结构化程度评估
-
内容可解析性:
-
文本类:可提取文字比例 vs 扫描图像比例
-
多媒体:是否有字幕/语音转文字可行性
-
-
结构特征:
-
是否存在目录/章节/时间戳等内在结构
-
元数据完整度(作者、创建时间等)
-
3. 资源需求预估
-
计算密集型:需要GPU加速处理的文件类型及量级
-
存储密集型:中间产物(如视频帧)的预估存储需求
-
时间成本:基于样本测试推算总处理耗时
数据预处理
-
文件解析:
-
文本类:PDF/Word解析、编码处理
-
多媒体:视频分帧/音频转文本
-
图像类:OCR识别、图像增强
-
-
内容提取:
-
去除无关内容(页眉页脚、广告等)
-
保留核心内容结构和元数据
-
预处理的时候还可以挑选10%-20%左右的典型数据来建立评估集,方便后续优化的时候进行测试。
二、内容理解阶段
混合内容PDF的智能处理流程
1. 内容类型识别分层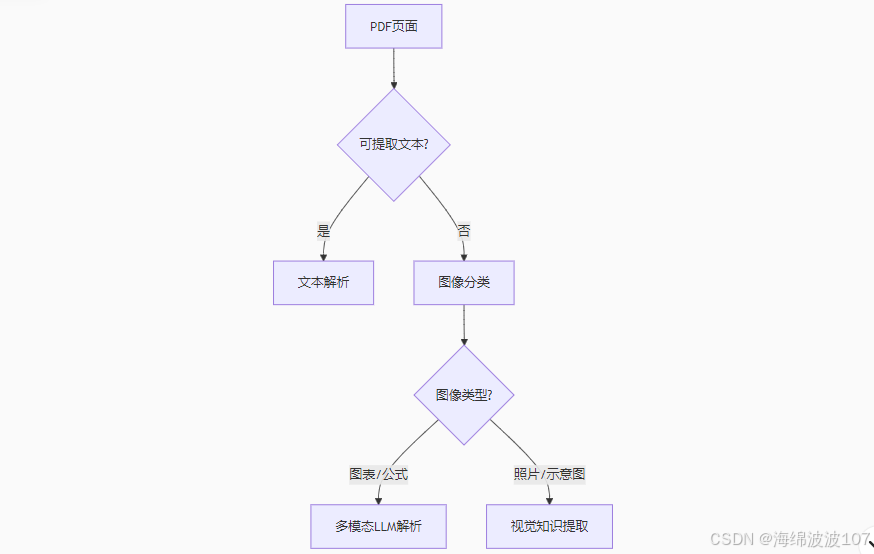
-
2. 多模态协同处理技术
-
文本层处理:
-
使用OCR引擎(Tesseract/Adobe PDF Extract、GOT-OCR、Paddle OCR、OlmOCR)
-
保留原始文本布局信息(段落/表格/标题)
-
-
视觉层处理:
-
科学图表:
-
使用GPT-4V/Claude-3 Opus解析:
prompt = "将此学术图表转化为:1) 图表类型说明 2) 横纵坐标含义 3) 关键数据趋势描述" -
-
装置示意图:
-
采用LLaVA-1.6等视觉模型:
prompt = "描述此机械装置的:1) 核心组件 2) 工作原理 3) 物质流动方向" -
-
数学公式:
-
MathPix API + LaTeX解析
-
-
-
这种处理方式相比传统OCR能多提取30-50%的隐含知识,特别适合学术文献、技术手册等专业文档的深度数字化。实际实施时需要根据领域特点调整多模态prompt的设计。
三、结构化存储与应用阶段
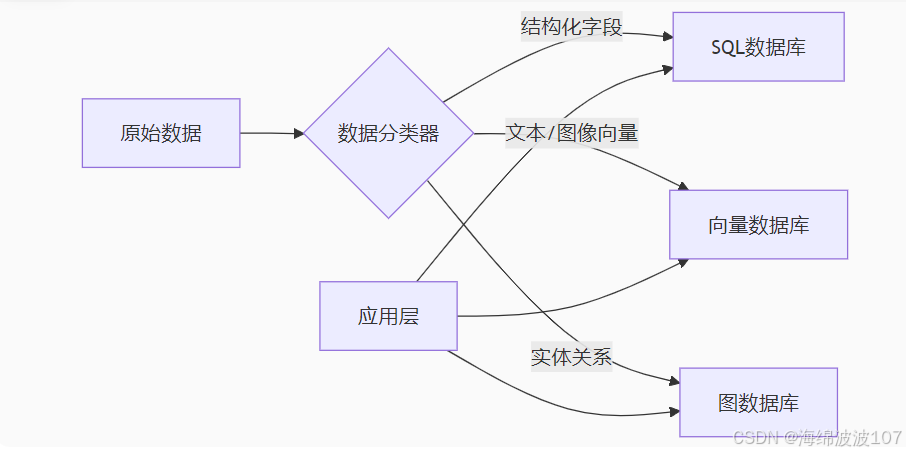
混合存储架构:
┌─────────────────┐
│ 结构化数据库 │←──SQL/NoSQL
├─────────────────┤
│ 向量数据库 │←──FAISS/Milvus
├─────────────────┤
│ 图数据库 │←──Neo4j/JanusGraph
└─────────────────┘采用混合存储方案(如结合结构化数据库、向量数据库和图数据库)是为了应对非结构化数据转化后知识的多维特性和不同使用场景的需求。
1. 数据类型与访问模式的多样性
| 数据类型 | 典型特征 | 最优存储方案 | 应用场景示例 |
|---|---|---|---|
| 元数据 | 结构化字段(作者、日期等) | 关系型数据库(MySQL/PostgreSQL) | 精确查询、统计分析 |
| 内容向量 | 高维嵌入向量(768-1536维) | 向量数据库(FAISS/Milvus) | 语义搜索、相似推荐 |
| 关系网络 | 实体-关系-实体三元组 | 图数据库(Neo4j/JanusGraph) | 关联推理、路径分析 |
案例:
一篇学术论文转化后:
-
SQL库存储
{标题,作者,发表年份} -
向量库存储
摘要文本嵌入向量 -
图库存储
作者-研究领域-方法论关系网
2. 性能与效率的平衡
-
结构化查询:
SELECT * FROM papers WHERE year > 2020 AND author = "李华"→ 关系型数据库比向量库快100倍
-
语义搜索:
db.similarity_search("量子计算的最新进展", k=5)→ 向量数据库比SQL快1000倍(对于近似最近邻搜索)
-
关联推理:
MATCH (a:Author)-[r:COLLABORATED_WITH]->(b) WHERE a.name = "王强" RETURN b→ 图数据库比关系库快100倍(对于深度遍历)
典型需要深度遍历的问题场景:
社交网络分析
-
场景:查找某人的N度人脉(例如"朋友的朋友的朋友")。
-
深度遍历:
-
关系库需要多次JOIN(性能随深度指数下降),而图库(如Neo4j)直接沿边遍历,复杂度仅为O(深度)。
-
欺诈检测与反洗钱
-
场景:识别复杂资金环或网状交易路径(例如5层转账链路)。
-
深度遍历:
-
关系库需递归CTE或多表连接,图库通过
(A)-[转账]->(B)-[转账]->(C)...直接追踪路径。
-
知识图谱与推理
-
场景:医学知识库中查找"药物A→副作用B→禁忌症C→替代药物D"的关联链。
-
深度遍历:
-
图库通过属性图快速跳转,关系库需多次自连接或中间表查询。
-
推荐系统
-
场景:基于协同过滤的"用户喜欢A→A相似物品B→喜欢B的用户也喜欢C"的推荐。
-
深度遍历:
-
图库直接遍历用户-物品-用户网络,关系库需多次聚合和JOIN。
-
供应链与物流路径优化
-
场景:查找供应商的N级上游依赖(例如"零件厂商→组件厂商→整车厂商")。
-
深度遍历:
-
图库支持可变长度路径查询(如Neo4j的
[:SUPPLIES*1..5]),关系库需动态生成SQL。
-
3. 知识完整性的需求
混合存储确保三种知识表达不丢失:
-
表层知识(What)→ 结构化数据库
"这篇论文发表于Nature 2023年" -
语义知识(Meaning)→ 向量数据库
"该研究证明了室温超导的可能性" -
关联知识(Why/How)→ 图数据库
"该方法借鉴了2015年张团队的实验设计"
混合架构实施建议
四、质量保障机制
语义理解环节的优化策略
1. 提示词工程黄金法则
需要掌握一些提示词的技巧,来提高信息提取的效果
-
结构化提取模板:
prompt = """请严格按以下结构提取信息: {"核心实体": [{"名称": "","类型": "人物/地点/技术","属性": {"key1":"value1", "key2":"value2"}}],"关键关系": [{"主体": "实体1","客体": "实体2","关系类型": "影响/依赖/包含","证据文本": "原文引用"}],"时间线索": [{"事件": "","时间点": "","置信度": "高/中/低"}] }"""
2. 动态提示调整
-
上下文感知提示:
if "学术论文" in document_metadata:prompt += "\n请特别关注METHODOLOGY部分的实验参数" elif "技术专利" in document_metadata:prompt += "\n重点提取权利要求书中的技术特征"
LLM API选型矩阵
| 模型特性 | Gemini-1.5-Pro | GPT-4-Turbo | Claude-3-Opus | 适用场景建议 |
|---|---|---|---|---|
| 上下文窗口 | 1M tokens | 128K | 200K | 长文献/视频转录 |
| 结构化输出能力 | ★★★★☆ | ★★★★☆ | ★★★★★ | 复杂JSON生成 |
| 多模态支持 | ★★★★★ | ★★★☆☆ | ★★★★☆ | 图文混合解析 |
| 中文处理 | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | 中文技术文档 |
| 价格($/1M输入) | $7.00 | $10.00 | $15.00 | 成本敏感型项目 |
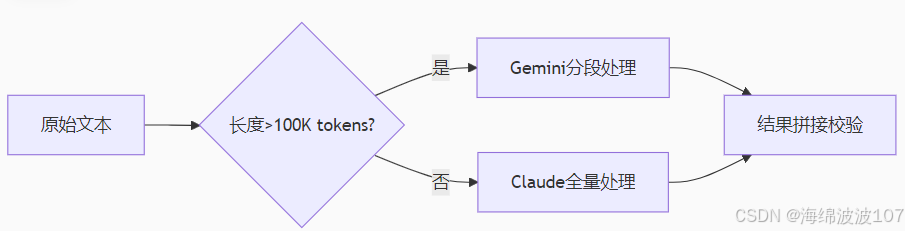
实践建议:
-
长文本处理流水线:
例1:非结构化文档(PDF/视频)转化为结构化知识库
将一些PDF格式的讲座PPT、MP4格式视频文件等学习资料,结构化提取其中的信息处理到数据库、向量库、Neo4j,涉及了多模态非结构化数据处理
1. PDF处理流程
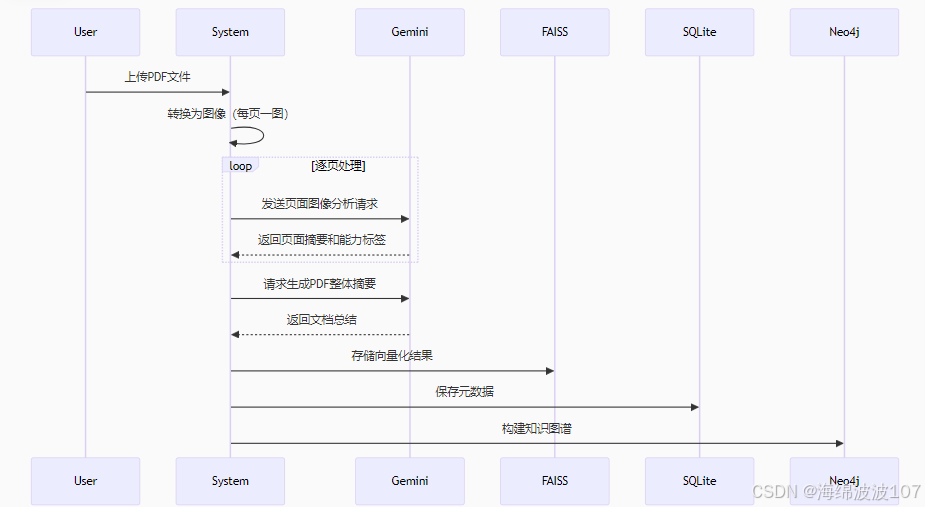
2. 视频处理流程
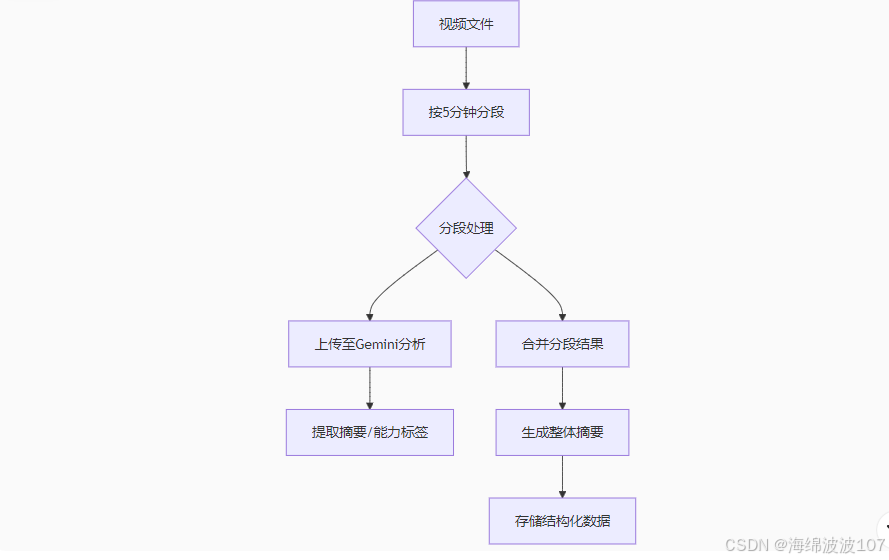
关键技术创新点
-
多模态内容理解:
-
同时处理文本和视觉内容
-
使用Gemini模型解析:
response = gemini_model.generate_content([{"text": "分析此图表..."}, {"image": base64_data} ])
-
-
混合知识表示:
-
结构化元数据(SQLite)
-
语义向量(FAISS)
-
关系网络(Neo4j)
# Neo4j关系创建示例 session.run("""MERGE (r:Resource {name: $name})MERGE (c:Capability {name: $cap})MERGE (r)-[:HAS_CAPABILITY]->(c) """, name=doc_name, cap=capability) -
-
动态质量控制系统:
-
页面级分析校验
-
文档级摘要验证
-
跨模态一致性检查
-
def _analyze_text_and_match_capabilities(text):# 强制使用预定义标签capabilities = load_predefined_tags()... -
工程实践亮点
-
文件处理优化:
-
PDF分页处理避免内存溢出
images = convert_from_path(pdf_path, dpi=200) # 控制分辨率-
视频分段处理
ffmpeg -ss {start} -i input.mp4 -t {duration} -c copy chunk.mp4 -
-
异常处理机制:
try:video_file = genai.upload_file(chunk_path)while video_file.state == "PROCESSING":time.sleep(5) except Exception as e:logger.error(f"分段处理失败: {e}") finally:os.unlink(chunk_path) # 清理临时文件 -
性能监控:
start_time = time.time() # 处理过程... print(f"处理耗时: {time.time()-start_time:.2f}秒")
源代码:
import os
import json
import numpy as np
import faiss
from PIL import Image
from pdf2image import convert_from_path
import torch
import torchvision.transforms as transforms
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection, AutoTokenizer, AutoModel
from typing import List, Dict, Tuple
from langchain_anthropic import ChatAnthropic
from langchain.prompts import PromptTemplate
from openai import OpenAI
import google.generativeai as genai # 导入Google的SDK
import sqlite3
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
import time
import base64
from io import BytesIO
import tempfile
import subprocess
from app.services.db_resource import ResourceServe
# from app.services.neo4j_crud import save_to_neo4j # 假设这是neo4j的接口函数
from app.utils.configs import (RESOURCE_VECTOR_DIR,LEARNING_RESOURCES_FOLDER,EMBEDDING_MODEL_PATH,LEVEL_TWO_JSON_PATH,OPENAI_API_KEY,OPENAI_API_BASE,LLF_KNOWLEDGE_BASES_FOLDER
)
from neo4j import GraphDatabase
import datetime
import ffmpeg
from app.utils.llm_utils import get_llm_response
os.environ['HF_DATASETS_OFFLINE'] = '1'
os.environ['TRANSFORMERS_OFFLINE'] = '1'
class ResourceVectorDB:def __init__(self, vector_dir, vector_dim=1792, google_api_key: str = None):self.db_path = vector_dirself.device = "cuda" # 假设你的HuggingFace Embeddings仍需要cudaself.vector_dim = vector_dimif google_api_key is None:raise ValueError("Google API Key must be provided.")genai.configure(api_key=google_api_key)# 初始化模型 (Embedding模型保持不变)self.embeddings = HuggingFaceEmbeddings(model_name="/data/hyq/huggingface/models--lier007--xiaobu-embedding-v2/snapshots/1912f2e59a5c2ef802a471d735a38702a5c9485e",model_kwargs={'device': self.device})os.makedirs(self.db_path, exist_ok=True)self.entire_path = os.path.join(vector_dir, "entire_doc")self.detail_path = os.path.join(vector_dir, "detail_doc")# entire_storeif os.path.exists(self.entire_path) and os.listdir(self.entire_path):try:self.entire_store = FAISS.load_local(self.entire_path,self.embeddings,allow_dangerous_deserialization=True)print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] FAISS向量库从 {self.entire_path} 加载成功。")except Exception as e:print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 从 {self.entire_path} 加载FAISS向量库失败: {e}. 创建新的库。")self._create_empty_faiss_store()else:self._create_empty_faiss_store()# detail_storeif os.path.exists(self.detail_path) and os.listdir(self.detail_path):try:self.detail_store = FAISS.load_local(self.detail_path,self.embeddings,allow_dangerous_deserialization=True)print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] FAISS detail向量库从 {self.detail_path} 加载成功。")except Exception as e:print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 从 {self.detail_path} 加载FAISS detail向量库失败: {e}. 创建新的库。")self.detail_store = FAISS.from_texts(texts=["初始化向量库占位文本"],embedding=self.embeddings,metadatas=[{"id": "init_placeholder", "type": "init"}])self.detail_store.save_local(self.detail_path)else:self.detail_store = FAISS.from_texts(texts=["初始化向量库占位文本"],embedding=self.embeddings,metadatas=[{"id": "init_placeholder", "type": "init"}])self.detail_store.save_local(self.detail_path)# 初始化 Gemini 模型客户端self.gemini_model = genai.GenerativeModel('gemini-1.5-pro-latest') # 或 'gemini-1.5-pro'def _create_empty_faiss_store(self):print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 创建新的空FAISS向量库。")# FAISS.from_texts 需要至少一个文本,但我们可以用一个占位符,后续添加真实数据# 或者,如果你的FAISS版本支持,可以创建一个空的索引,但这通常更复杂# 一个简单的方法是初始化后立即保存一个空的(或带一个虚拟条目的)# 这里我们先不创建实际的FAISS对象,而是在第一次add_texts时创建它# 或者,像你原来那样,用一个初始化文本self.entire_store = FAISS.from_texts(texts=["初始化向量库占位文本"],embedding=self.embeddings,metadatas=[{"id": "init_placeholder", "type": "init"}])self.entire_store.save_local(self.entire_path)def extract_lecturer_from_filename(self, filename):"""使用LLM从文件名中提取讲师姓名"""prompt = f"""请从以下文件名中提取讲师姓名。如果找不到讲师姓名,请返回"未设置"。只需要返回讲师姓名,不要其他解释。文件名: {filename}"""try:# 直接获取响应文本lecturer = get_llm_response(prompt)# 如果响应为空或包含"未设置"相关文字,返回默认值if not lecturer or "未设置" in lecturer or "找不到" in lecturer:return "未设置"return lecturerexcept Exception as e:print(f"提取讲师姓名时出错: {str(e)}")return "未设置"def add_resource(self, file_path: str):"""根据文件类型自动分发处理"""ext = os.path.splitext(file_path)[-1].lower()if ext == ".pdf":