Python_day51
作业:
day43的时候我们安排大家对自己找的数据集用简单cnn训练,现在可以尝试下借助这几天的知识来实现精度的进一步提高
关于 Dataset
从谷歌图片中抓取了 1000 多张猫和狗的图片。问题陈述是构建一个模型,该模型可以尽可能准确地在图像中的猫和狗之间进行分类。
图像大小范围从大约 100x100 像素到 2000x1000 像素。
图像格式为 jpeg。
已删除重复项。
猫狗图像分类
https://i-blog.csdnimg.cn/direct/e9afa2653aa74ecf9042321652063514.png

import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader# 设备设置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# CBAM 模块
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)self.relu1 = nn.ReLU()self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))out = avg_out + max_outreturn self.sigmoid(out)class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv1(x)return self.sigmoid(x)# 基础 CNN 模型含 CBAM
class CNNWithCBAM(nn.Module):def __init__(self):super(CNNWithCBAM, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(64)self.ca1 = ChannelAttention(64)self.sa1 = SpatialAttention()self.relu = nn.ReLU(inplace=True)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(128)self.ca2 = ChannelAttention(128)self.sa2 = SpatialAttention()self.fc1 = nn.Linear(128 * 8 * 8, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.relu(self.bn1(self.conv1(x)))x = self.ca1(x) * xx = self.sa1(x) * xx = self.pool(x)x = self.relu(self.bn2(self.conv2(x)))x = self.ca2(x) * xx = self.sa2(x) * xx = self.pool(x)x = x.view(-1, 128 * 8 * 8)x = self.relu(self.fc1(x))x = self.fc2(x)return x# 数据预处理
transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加载 CIFAR - 10 数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=32, shuffle=True)testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = DataLoader(testset, batch_size=32, shuffle=False)# 初始化模型、损失函数和优化器
model = CNNWithCBAM().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练函数
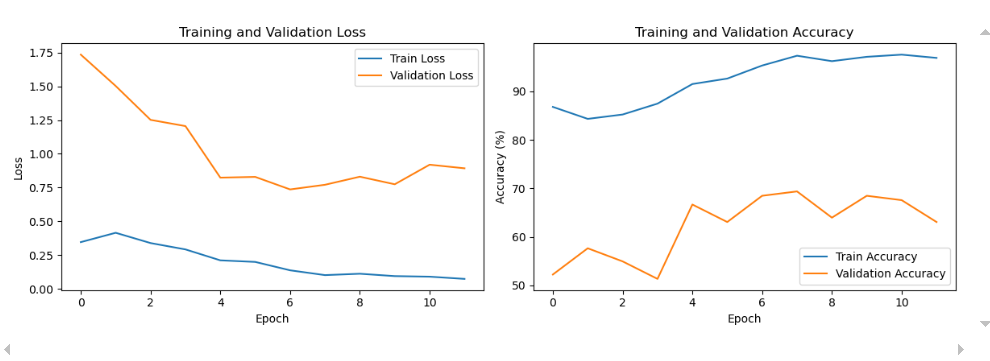
def train(model, trainloader, criterion, optimizer, device, epochs):model.train()for epoch in range(epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}')# 评估函数
def evaluate(model, testloader, device):model.eval()correct = 0total = 0with torch.no_grad():for data in testloader:images, labels = data[0].to(device), data[1].to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the network on the 10000 test images: {100 * correct / total} %')# 开始训练和评估
train(model, trainloader, criterion, optimizer, device, epochs=10)
evaluate(model, testloader, device)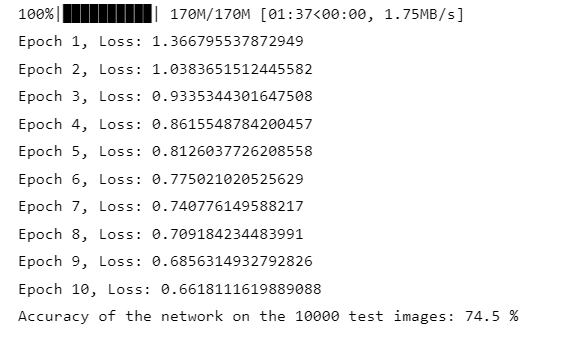
@浙大疏锦行