DeepCritic: SFT+RL两阶段训练突破LLM自我监督!显著提升大模型的自我批判能力!!
摘要:随着大型语言模型(LLMs)的迅速发展,对其输出进行准确反馈和可扩展监督成为一个迫切且关键的问题。利用LLMs作为批评模型以实现自动化监督是一个有前景的解决方案。在本研究中,我们专注于研究并提升LLMs在数学批评方面的能力。当前的LLM批评模型在每个步骤上提供的批评过于肤浅和表面化,导致判断准确度低,且难以提供足够的反馈来帮助LLM生成器纠正错误。为解决这一问题,我们提出了一个新颖且有效的两阶段框架,用于开发能够针对数学解决方案的每个推理步骤进行深思熟虑的批评的LLM批评模型。在第一阶段,我们利用Qwen2.5-72B-Instruct生成4500条长篇批评作为监督微调的种子数据。每条种子批评包含对每个推理步骤的深思熟虑的分步批评,包括多角度验证以及对初始批评的深入批评。然后,我们使用强化学习对微调后的模型进行训练,使用PRM800K中现有的人工标注数据或通过基于蒙特卡洛抽样的正确性估计获得的自动标注数据,以进一步激励其批评能力。我们基于Qwen2.5-7B-Instruct开发的批评模型不仅在各种错误识别基准测试中显著优于现有的LLM批评模型(包括相同大小的DeepSeek-R1-distill模型和GPT-4o),而且通过更详细的反馈更有效地帮助LLM生成器完善错误步骤。
本文目录
一、背景动机
二、实现方法
3.1 监督式微调(阶段一)
3.2 强化学习(阶段二)
四、实验结论
4.1 性能提升
4.2 测试时扩展性
4.3 弱监督潜力
五、总结
一、背景动机
论文题目:DeepCritic: Deliberate Critique with Large Language Models
论文地址:https://arxiv.org/pdf/2505.00662
当前使用LLM critics 可以生成对 LLM 生成内容的批判,识别其中的缺陷和错误,帮助 LLM 生成器改进输出,从而实现自动监督和持续改进。然而,现有的 LLM critics 在复杂领域(如数学推理任务)中表现出的批判能力有限,其生成的批判往往过于肤浅,缺乏批判性思维,无法提供准确可靠的反馈。例如,它们通常只是重复原始推理步骤的内容,而不是对其进行深入的批判性分析,导致批判结果不准确且缺乏指导性。
该文章提出了一个名为 DeepCritic 的新型两阶段框架,用于开发能够对数学解题过程的每个推理步骤进行深入批判的 LLM critics。实验结果表明,基于 Qwen2.5-7B-Instruct 开发的 DeepCritic 模型在多个错误识别基准测试中显著优于现有的 LLM critics(包括同尺寸的 DeepSeek-R1-distill 模型和 GPT-4o),并且能够通过更详细的反馈更有效地帮助 LLM 生成器修正错误步骤。

二、实现方法
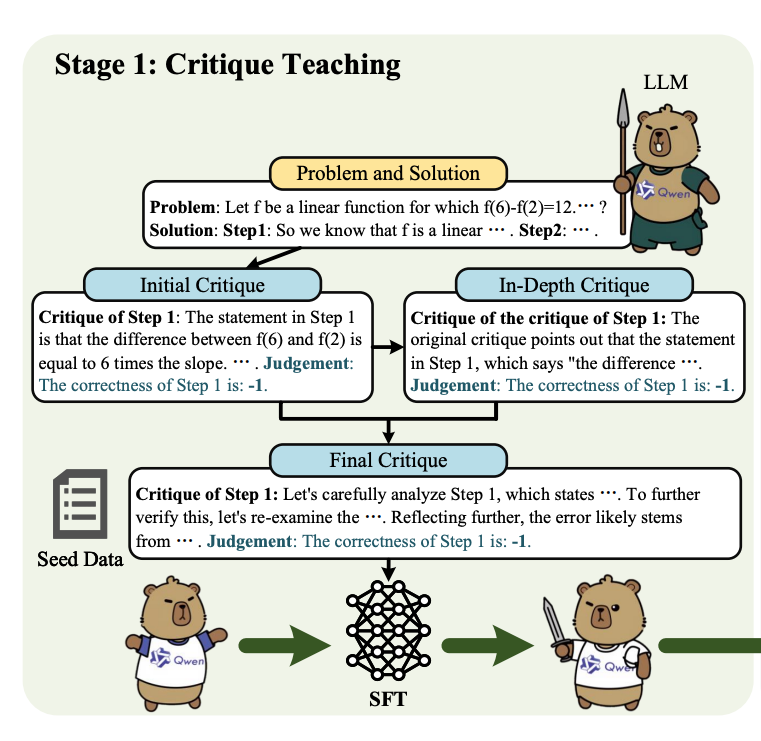
3.1 监督式微调(阶段一)
- 初始批判生成:从 PRM800K 数据集中采样一小部分标注数据作为种子任务输入,利用 Qwen2.5-72B-Instruct 为每个推理步骤生成初始批判。
-
对于每个步骤,模型生成一个批判和一个判断结果,表示该步骤的正确性。
-
生成过程是独立的,即每次只针对一个步骤进行批判,而不是直接生成整个解决方案的批判。
-
生成的初始批判通常较为简略,主要跟随原始推理步骤的逻辑进行验证。
-
- 深入批判生成:基于初始批判,进一步生成深入批判,从不同角度验证推理步骤的正确性,或对初始批判本身进行批判性分析。
-
基于问题 P、解决方案 S 和初始批判,再次利用 Qwen2.5-72B-Instruct 模型生成深入批判和判断结果。
-
深入批判的目标是从不同角度验证推理步骤的正确性,或对初始批判本身进行批判性分析,以发现初始批判中的潜在错误。
-
- 最终批判合成:将初始批判和深入批判合并为一个长篇批判,形成完整的解决方案批判。
-
利用 Qwen2.5-72B-Instruct 模型,将初始批判和深入批判合并为一个最终批判 cfinali。
-
合并过程中,模型会添加一些过渡性的、反思性的语句,使批判内容更加连贯和深入。
-
最终批判不仅包含对每个步骤的详细分析,还可能包含对初始批判的修正和补充。
-
- 监督微调:使用上述生成的批判数据对目标模型进行监督式微调,使模型能够进行多视角评估和自我反思。
3.2 强化学习(阶段二)
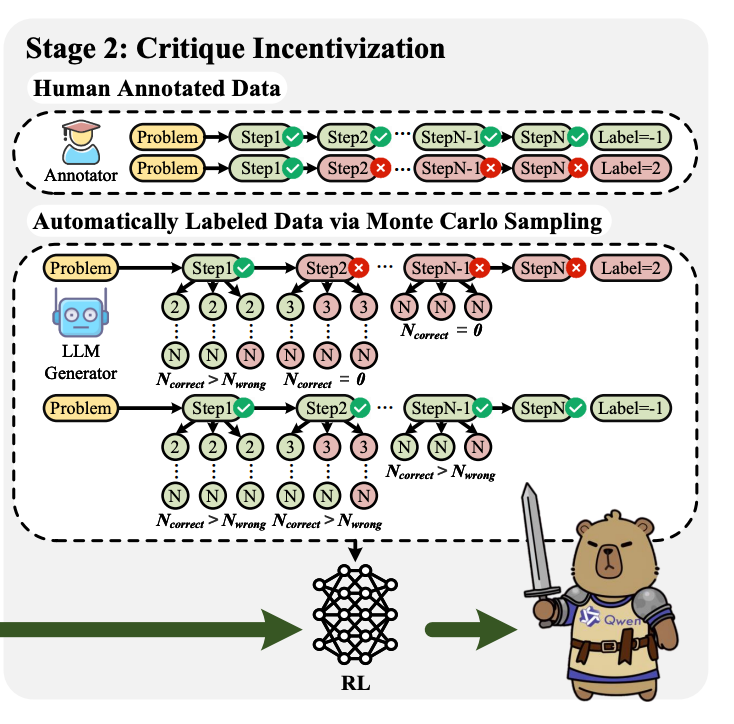
- 数据准备
-
人类标注数据:如果现成的人类标注数据可用(如 PRM800K),直接使用这些数据进行强化学习。
-
自动标注数据:如果没有人类标注数据,通过蒙特卡洛采样估计每个推理步骤的正确性,自动生成标注数据。
-
对于每个问题,生成多个逐步解决方案,并通过蒙特卡洛采样估计每个步骤的正确性。
-
如果某个步骤在大多数采样路径中都被认为是错误的,则将其标注为错误;否则标注为正确。
-
-
- 强化学习优化
-
奖励机制:如果模型的最终判断结果正确,则给予奖励 1.0;否则给予奖励 0.0。
-
训练目标:通过强化学习,进一步提升模型的批判能力,使其能够更准确地识别错误并提供详细反馈。
-
四、实验结论
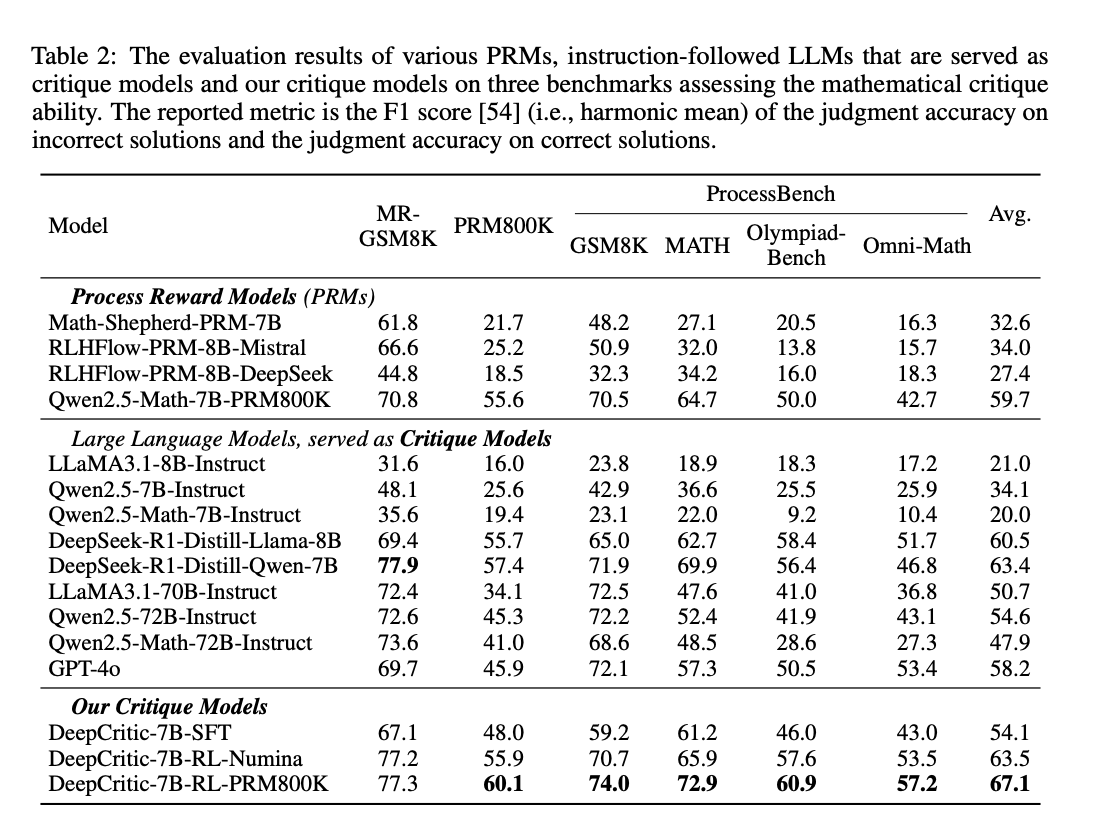
4.1 性能提升
DeepCritic 在多个错误识别基准测试中显著优于现有的 LLM critics 和过程奖励模型(PRMs),在 6 个测试集中有 5 个测试集的性能超过了 GPT-4o 和其他基线模型。如在 MR-GSM8K 数据集上,DeepCritic-7B-RL-PRM800K 的 F1 分数达到了 77.3%,显著高于其他基线模型,如 Qwen2.5-7B-Instruct(48.1%)和 GPT-4o(69.7%)。
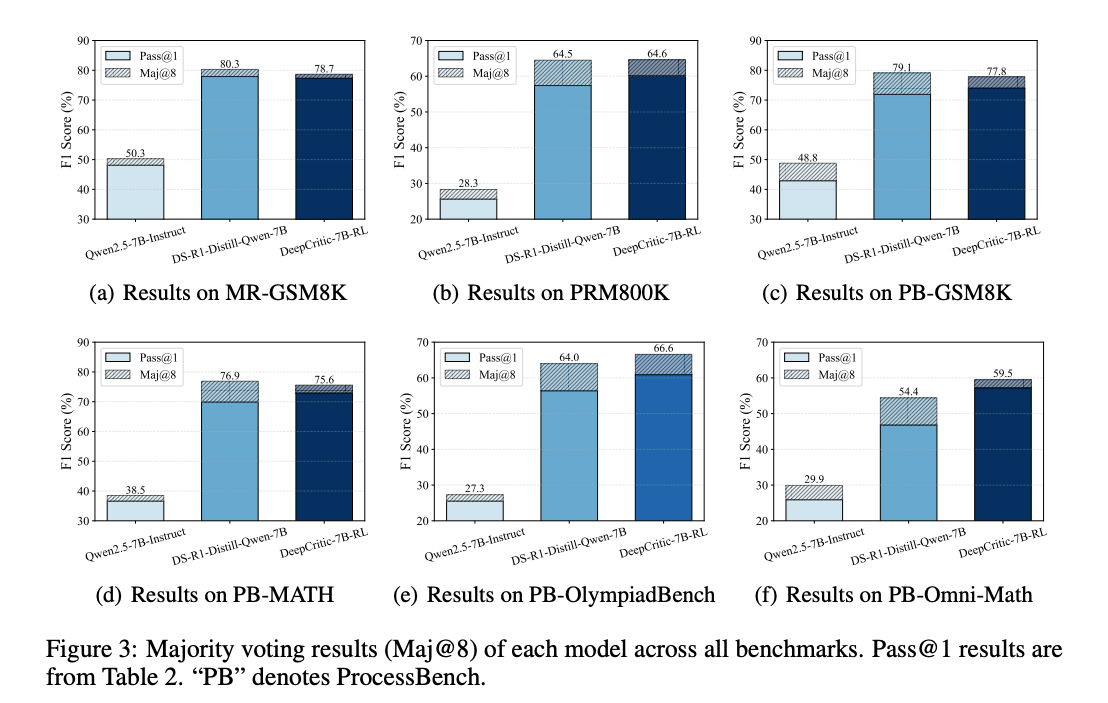
4.2 测试时扩展性
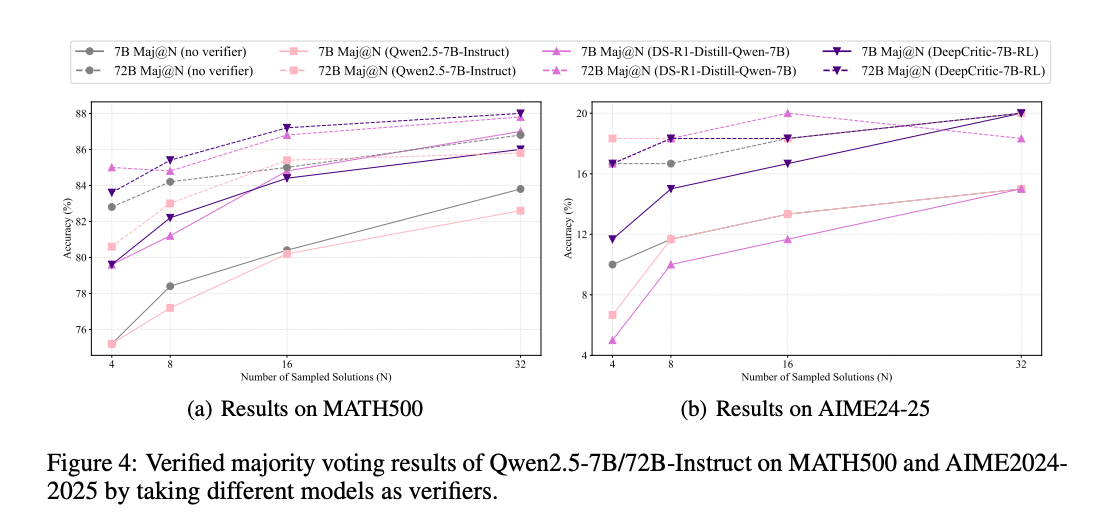
DeepCritic 在测试时表现出良好的扩展性。通过增加测试时的采样次数,批判模型的判断准确性一致提高,如使用 8 次采样的多数投票(Maj@8)将 DeepCritic-7B-RL-PRM800K 的 F1 分数从 77.3% 提升到 78.7%。
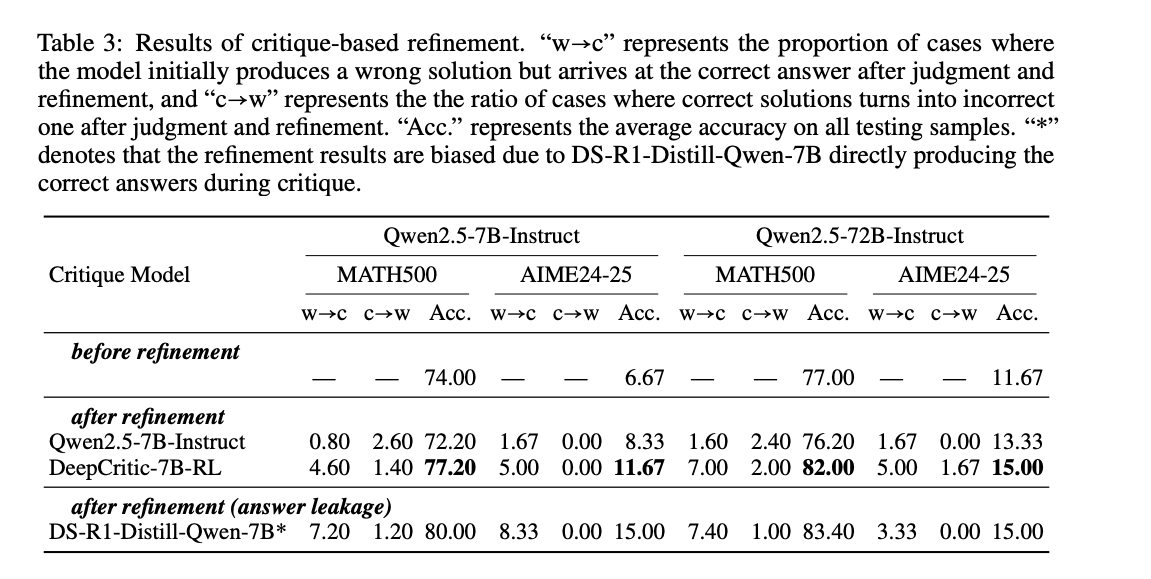
DeepCritic 通过提供详细反馈帮助 LLM 生成器修正错误,有效提升 LLM 生成器的性能,在 MATH500 数据集上,使用 DeepCritic 的反馈进行修正后,Qwen2.5-7B-Instruct 的准确率从 74.0% 提升到 77.2%
4.3 弱监督潜力
DeepCritic 展示了弱监督的潜力,在 MATH500 数据集上,DeepCritic-7B-RL 能够有效监督 Qwen2.5-72B-Instruct 的输出,帮助其修正错误,提升整体性能。
五、总结
文章提出了一种有效的两阶段训练范式,通过监督式微调和强化学习显著提升了 LLMs 的数学批判能力。DeepCritic 模型不仅在多个基准测试中表现出色,还展示了在测试时扩展和弱监督方面的潜力。