Shuffle流程
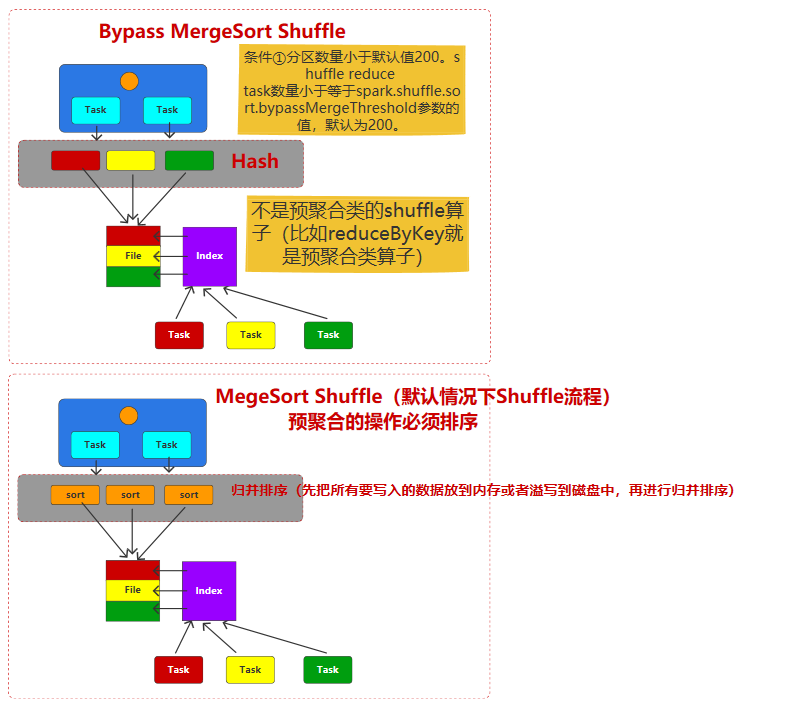
正常情况下都是走MegeSortShuffle流程,特别是预聚合类shuffle算子(比如reduceByKey),但是数据量多的情况下,整个排序过程较慢,导致整个shuffle过程较慢,并且因为底层用的是归并排序,中间会产生多个文件
如果满足①分区数量小于等于spark.shuffle.sort.bypassMergeThreshold(默认值200)②不是预聚合类shuffle算子(比如groupByKey),会采用ByPass MegeSortShuffle(不经过排序的Shuffle),底层不用经过排序,用Hash对Task生成的文件进行初步分区,后面再写入到一个data文件和index文件中,效率明显提高.