Python实现prophet 理论及参数优化
文章目录
- Prophet理论及模型参数介绍
- Python代码完整实现
- prophet 添加外部数据进行模型优化
之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观的理解要优化哪些参数,模型自带的可调参数比公式里的还要多一些。
Prophet理论及模型参数介绍
优秀文章参考过讲透一个强大算法模型,Prophet!!
想要还了解理论的,可以参考之前写的文章Python实现Prophet时序预测模型
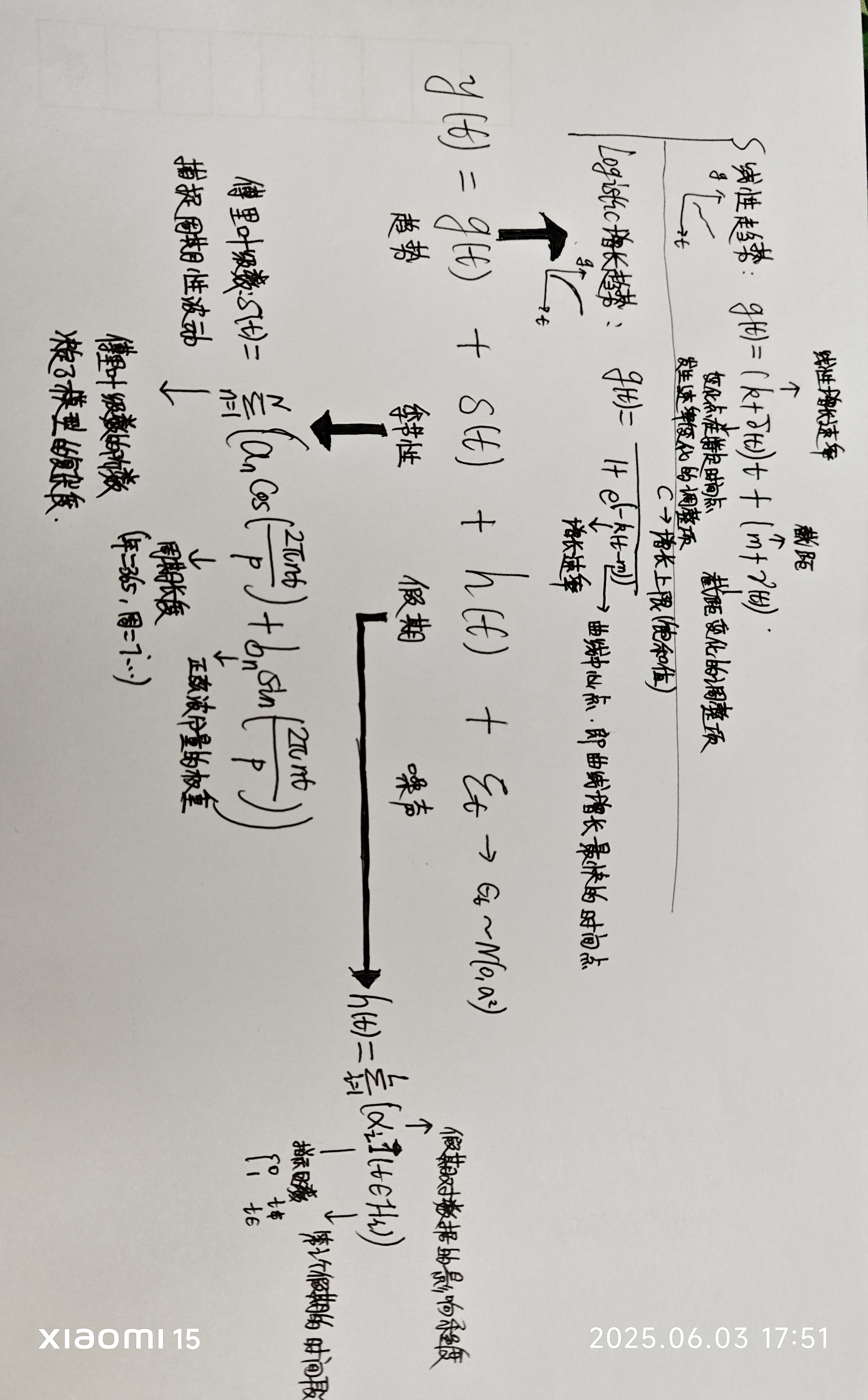
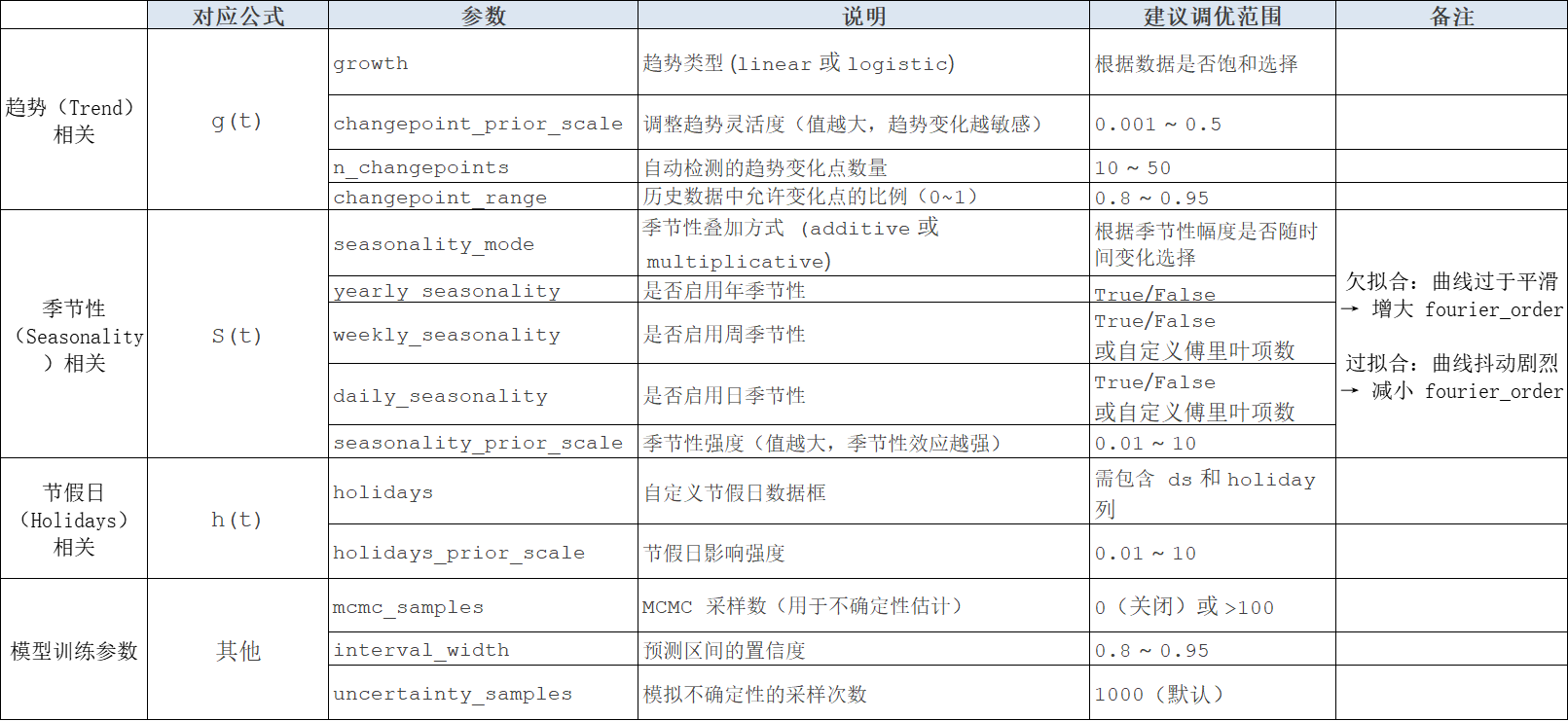
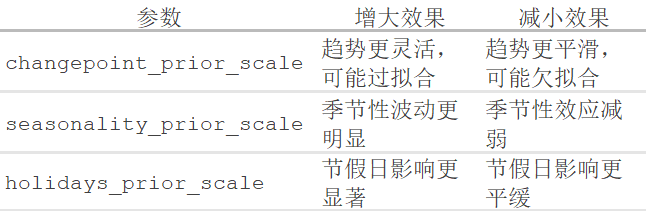
接下来,直接结合理论公式和代码里的参数进行介绍,看完下面我自己整理的图,你会理解以下问题:
- 为什么季节性的参数会选择优化傅里叶级数?
- 不同自动检测的趋势变化点数量会影响什么?
- 趋势类型决定了模型的什么部分?
- 节假日影响强度是什么意思?
- … …

Python代码完整实现
import pandas as pd
import numpy as np
from prophet import Prophet
from sklearn.model_selection import ParameterGrid
from prophet.diagnostics import cross_validation, performance_metrics
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error,mean_squared_error
from prophet.plot import plot_cross_validation_metric, plot_components
import matplotlib.pyplot as plt
from datetime import timedelta
import logging
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 配置日志
logging.getLogger('prophet').setLevel(logging.WARNING)
logging.getLogger('cmdstanpy').setLevel(logging.WARNING)
from sklearn.model_selection import ParameterGrid
class normal_Prophet:def __init__(self):self.model = Noneself.freq = '15T' # 15分钟频率def preprocess_data(self, df):df = df.sort_values(by=['xxxx','xxx','xx'])cols = df.columns.tolist()cols[10:-1]=[f'point_{i}' for i in range(1, 97)] df.columns = colsreturn df def data_row_column(self,cus_df): #将数据1*96转换成96*1cus_df = self.preprocess_data(cus_df)hourly_loads = cus_df.drop(['xxxx','xxx','xx','年月'], axis=1)df = hourly_loads[(hourly_loads.cust_id ==20250610)]# 列名格式为 'point_1', 'point_2', ..., 'point_96'load_columns = df.filter(regex="point_").columns# 将96点数据转换为长格式hourly_loads = df.melt(id_vars=["xxxxxxxxxx"],value_vars=load_columns,var_name="point",value_name="load")# 计算时间戳(每15分钟一个点)hourly_loads["point_idx"] = hourly_loads["point"].str.extract("(\d+)").astype(int)hourly_loads["hour"] = (hourly_loads["point_idx"] - 1) // 4 # 计算小时(0-23)hourly_loads["minute"] = ((hourly_loads["point_idx"] - 1) % 4) * 15 # 计算分钟(0, 15, 30, 45)hourly_loads["timestamp"] = hourly_loads["amt_ym"] + pd.to_timedelta(hourly_loads["hour"], unit="h") + pd.to_timedelta(hourly_loads["minute"], unit="m")# 按时间戳排序hourly_loads = hourly_loads.sort_values("timestamp")ts_df = hourly_loads[["timestamp", "load"]].set_index("timestamp")return ts_dfdef z_score_data(self,ts_df):ts_df = self. data_row_column(ts_df)# print("时间范围:", ts_df.index.min(), "到", ts_df.index.max())# print("实际数据点数:", len(ts_df))# print("缺失的日期示例:", ts_df.asfreq('15T').index.difference(ts_df.index)[:5]) # 检查是否有缺失full_index = pd.date_range(start=ts_df.index.min(),end=ts_df.index.max(),freq='15T' )ts_df = ts_df.reindex(full_index).interpolate()ts_df = ts_df.reset_index()ts_df.columns = ['ds','y']"""'''窗口1(时间点0-95):计算 mean(y0:y95) 和 std(y0:y95),用于时间点95的Z-score。窗口2(时间点1-96):计算 mean(y1:y96) 和 std(y1:y96),用于时间点96的Z-score。窗口3(时间点2-97):计算 mean(y2:y97) 和 std(y2:y97),用于时间点97的Z-score。滑动窗口:代码中的 rolling() 是滑动(不重复)的,每个点基于最近的96个点计算统计量。异常值检测:只有完整的窗口(第96个点开始)会触发Z-score计算,前95个点被跳过。适用场景:适合高频数据中连续检测异常值,避免分块导致的边界不连续问题。'''"""window_size = 96 # 24小时窗口(96个15分钟间隔)if len(ts_df) > window_size:rolling_mean = ts_df['y'].rolling(window=window_size).mean()rolling_std = ts_df['y'].rolling(window=window_size).std()ts_df['z_score'] = (ts_df['y'] - rolling_mean) / rolling_stdts_df['y'] = np.where(np.abs(ts_df['z_score']) > 4, np.nan, ts_df['y'])return ts_df.dropna()def add_custom_seasonalities(self, model):"""添加高频数据特有的季节性"""# 周周期model.add_seasonality(name='weekly',period=7,fourier_order = params['weekly_fourier_order'],prior_scale = params['seasonality_weekly_prior_scale'])# 小时周期(覆盖默认的小时季节性) model.add_seasonality(name='hourly',period=24, # 24小时fourier_order = params['hourly_fourier_order'], # 捕捉小时级别模式prior_scale = params['seasonality_hourly_prior_scale'])# model.add_seasonality(# name='daily_15min',# period=1, # 1天周期# fourier_order=12, # 高频数据需要更高阶数# prior_scale=0.5,# mode='additive'# )# 可添加业务特定的周期(如半小时、45分钟等)# model.add_seasonality(# name='year',# period=24*365, # 0.5小时# fourier_order=2,# prior_scale=0.1# )return modeldef param_grid(self):# 参数网格param_grid = { 'seasonality_prior_scale':[0.01,1], #整体季节参数'weekly_fourier_order': [3, 7], #周周期-傅里叶级数'seasonality_weekly_prior_scale': [0.1], #周周期-季节强度'hourly_fourier_order': [3,5], #日周期-傅里叶级数'seasonality_hourly_prior_scale': [0.01,0.2], #日周期-季节强度'n_changepoints': [5,10], # 趋势相关-自动检测的趋势变化点数量'changepoint_prior_scale': [0.1,0.2], # 趋势相关-调整趋势灵活度'holidays_prior_scale':[0.01] #节假日相关-节假日影响强度}return param_griddef fit(self, params,df, holidays_df=None,fut_num = 16 ):"""训练模型"""df_processed = self.z_score_data(df)self.model = Prophet(n_changepoints = params['n_changepoints'],seasonality_prior_scale= params['seasonality_prior_scale'],changepoint_prior_scale= params['changepoint_prior_scale'],holidays_prior_scale = params['holidays_prior_scale'])# 添加自定义季节性self.model = self.add_custom_seasonalities(self.model)# 添加节假日效应if holidays_df is not None:holidays_df['ds'] = pd.to_datetime(holidays_df['ds'])self.model.add_country_holidays(country_name='CN')self.model.holidays = holidays_dfself.model.fit(df_processed[:-fut_num] )df_cv = cross_validation(self.model,initial='180 days',period='90 days',horizon='10 days')df_p = performance_metrics(df_cv, rolling_window=1)return self.model,df_p['rmse'].mean()def predict(self, periods=16, freq=None, include_history=True):"""生成预测"""if not self.model:raise ValueError("请先训练模型")freq = freq or self.freqfuture = self.model.make_future_dataframe(periods=periods,freq=freq,include_history=include_history)forecast = self.model.predict(future)return forecastdef plot_components(self, forecast):"""可视化组件"""fig = self.model.plot_components(forecast)for ax in fig.axes:ax.xaxis.set_major_locator(plt.MaxNLocator(5))return figdef result_data(self,df,forecast,fut_num = 16):da = self.z_score_data(df)result = forecast.iloc[-1*fut_num:][['ds','yhat']]rmse = np.sqrt(mean_squared_error(da[['y']][-1*fut_num:], result[['yhat']][-1*fut_num:]))mse = mean_squared_error(da[['y']][-1*fut_num:], result[['yhat']][-1*fut_num:])true_result = da[['ds','y']].iloc[-1*fut_num:]true_result[[ 'yhat', 'yhat_lower', 'yhat_upper']] = forecast[['yhat', 'yhat_lower', 'yhat_upper']].iloc[-1*fut_num:].valuestrue_result['timestamp'] = true_result['ds'].dt.time.apply(lambda x: x.strftime('%H:%M')) ymd = true_result.ds.values[0].astype('datetime64[D]') true_result['误差'] = np.abs(true_result['y'] -true_result['yhat'] )true_result['误差百分比'] = true_result['误差'] /true_result['y']*100print('预测结果\n',true_result)print(f'\n \n预测与真实值之间的RMSE :{rmse}')# #结果可视化plt.figure(figsize=(12,6))plt.scatter(true_result['timestamp'],true_result['y'],ls=':',c='red',lw=1)plt.fill_between(true_result['timestamp'],true_result['yhat_lower'],true_result['yhat_upper'],alpha = 0.15)plt.plot(true_result['timestamp'],true_result['yhat'],c='blue')plt.xlabel('未来4小时时刻点', size= 15)plt.ylabel('实际出力值', size= 15)plt.title('Prophet实际出力预测结果', size= 18)plt.legend(['出力真实值','预测值上下限','出力预测值'])plt.show()return true_resultif __name__ == '__main__':# 数据导入RAWcus_df = pd.read_excel("D:\\data.xlsx",engine='openpyxl') cus_df = RAWcus_df.copy()cus_df['年月'] = cus_df['xxx'].dt.strftime('%Y-%m')##开始模型训练normal_Prophet = normal_Prophet()holidays = pd.DataFrame({'ds': pd.to_datetime(['2023-01-01', '2023-01-22', '2023-04-05']),'holiday': ['元旦', '春节', '清明节'],'lower_window': -1,'upper_window': 1})# 4. 参数训练param_grid = normal_Prophet.param_grid()best_score = float('inf')best_params = {}best_params_list = []params_list = []rmse_list = []for params in ParameterGrid(param_grid):print('当前训练参数',params)params_list.append(params)model,current_rmse = normal_Prophet.fit(params,cus_df, holidays_df=holidays)rmse_list.append(current_rmse)if current_rmse < best_score:best_score = current_rmsebest_params = paramsbest_params_list.append(best_params)print(f"New best rmse: {best_score:.4f}, Params: {best_params}")print('所有参数训练列表',params_list)print(f"Optimized Parameters: {best_params}")# 导出参数训练过程params_jilu = pd.concat([pd.DataFrame(params_list),pd.DataFrame(rmse_list)],axis=1)params_jilu.rename(columns={0:'rmse'})print(params_jilu.head(3))# 5.训练模型print("训练模型中...")model,bset_rmse = normal_Prophet.fit(best_params,cus_df, holidays_df=holidays)# 6. 生成预测(预测未来24小时)print("生成预测...")forecast = normal_Prophet.predict(periods=16) # 96个15分钟=24小时# 7. 对比结果true_result =normal_Prophet.result_data(cus_df,forecast)# 8. 可视化结果print("生成整体可视化...")fig1 = model.plot(forecast)fig2 = normal_Prophet.plot_components(forecast)plt.show()
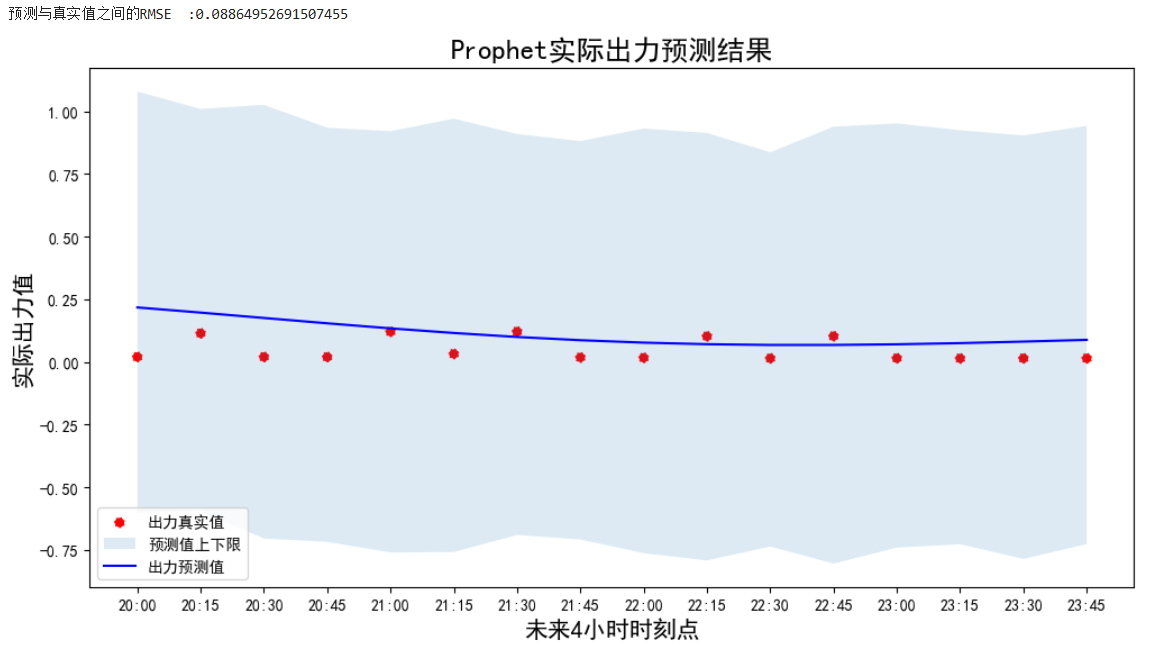
结果展示
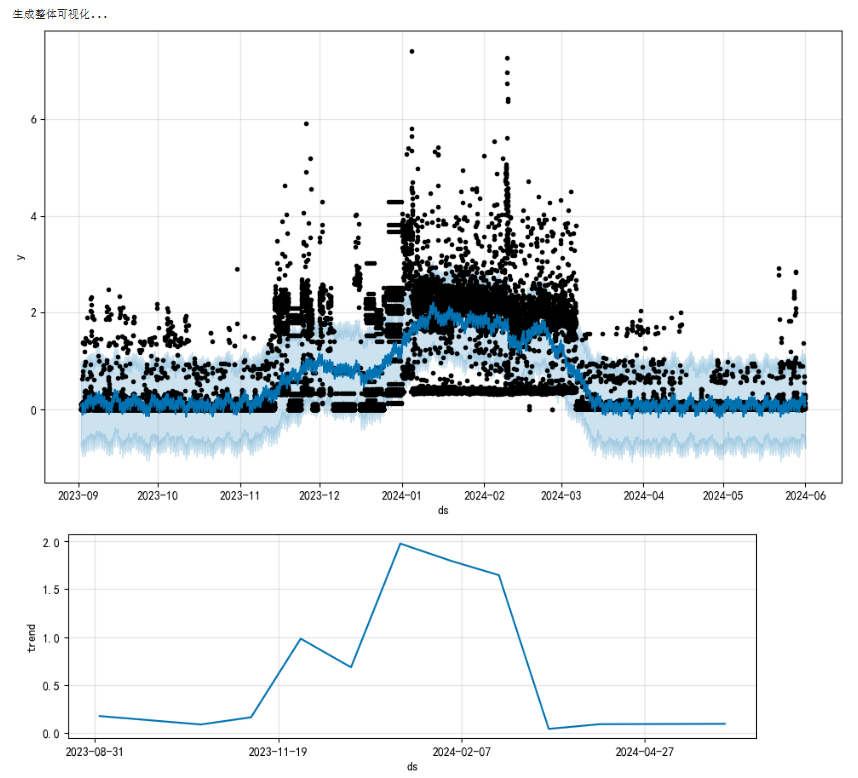
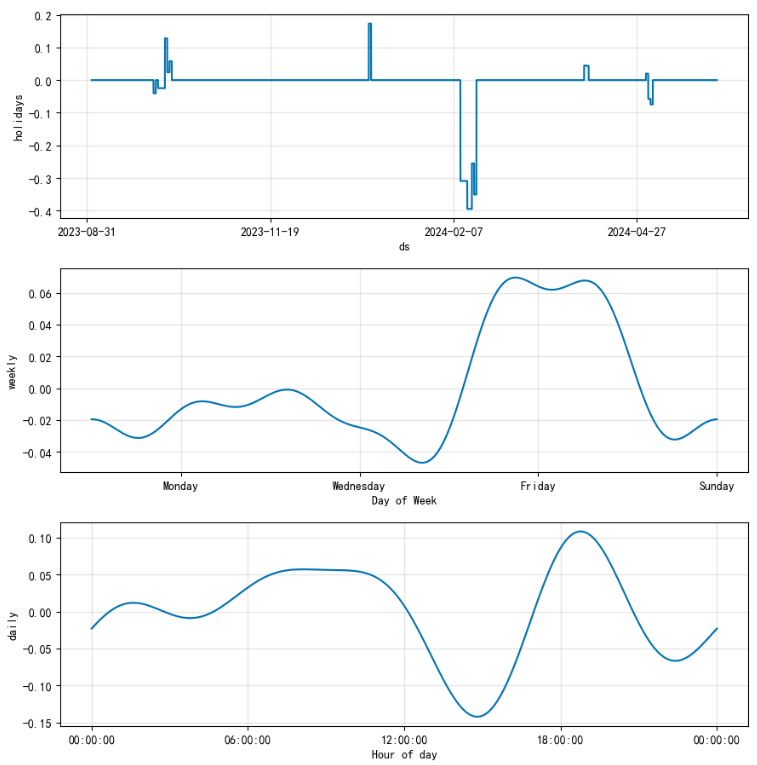
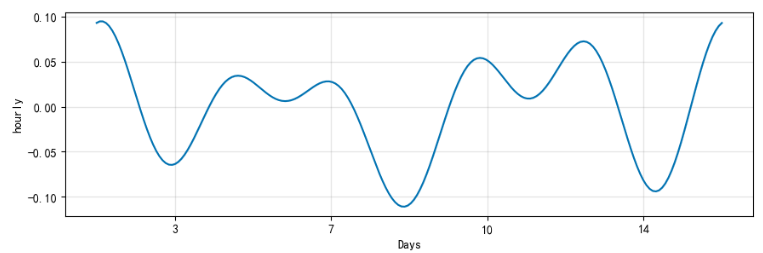
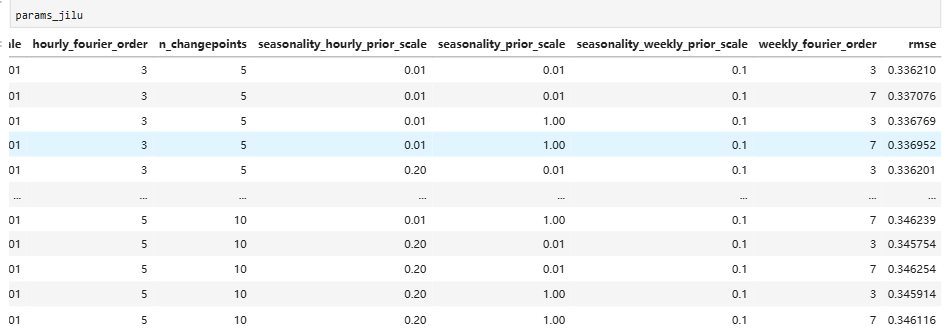

prophet 添加外部数据进行模型优化
大家都熟知prophet 的输入为两列[‘ds’,‘y’]数据,但是 Prophet 模型中整合其他外部数据(如促销活动、天气、经济指标等),可以使用 add_regressor() 方法添加额外的回归变量,从而使模型达到更好的效果。
model.add_regressor('XX', prior_scale=15, mode='additive') # 重要变量
model.add_regressor('ZZ', prior_scale=0.5, mode='additive')# 次要变量
# prior_scale: 控制正则化强度(默认0.5,值越大影响越大)
# mode: 可选 'additive'(默认)或 'multiplicative'model.fit(df)
future = model.make_future_dataframe(periods=30)
#未来外部变量的值需要事先确定在future 中
future = future.merge(pd.DataFrame({'ds': pd.date_range(start='2020-01-01', periods=395), # 合并未来30天的外部数据'XX': [1 if d.day == 15 else 0 for d in future['ds']], 'YY': np.sin(np.linspace(0, 10.5, 395)) * 10 + 25 }),on='ds',how='left'
)
forecast = model.predict(future)
评估回归器影响
# 查看回归器系数
print(model.params['beta'][:, 0]) # 第一个回归器的系数轨迹# 计算贡献度
regressor_effects = forecast[['ds', 'XX', 'ZZ']].copy()
regressor_effects['XX_effect'] = forecast['trend'] * model.params['beta'][0, 0]
regressor_effects['ZZ_effect'] = forecast['trend'] * model.params['beta'][0, 1]
正常的组件图 (plot_components) 将显示外部变量的影响,由于这里的数据不涉及外部变量,所以这里不和第一部分的参数优化融合在一起。