[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?

论文网址:pdf
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
1. 心得
2. 论文逐段精读
2.1. Abstract
2.2. Introduction
2.3. Background and Motivation
2.3.1. Motivation
2.4. CLIP-ViL
2.4.1. Visual Question Aswering
2.4.2. Image Captioning
2.5. Vision-and-Language Pre-training
2.5.1. CLIP-VIL_p
2.5.2. Experiments
2.6. Analysis
2.7. Conclusions
1. 心得
(1)?非常简单的一篇文章,感觉在测试CLIP?
2. 论文逐段精读
2.1. Abstract
①Model pre-trained on large number of data brings better performance
②Scenarios suitable for CLIP: plug and fine-tune, or combining with V&L
2.2. Introduction
①Bottleneck of vision-and-language (V&L) tasks: visual representation and scarce labled data
②Most V&L tasks require complex reasoning, which can not use visual model directly
③They define two scenarios:
| CLIP_ViL | CLIP in direct task-specific fine-tuning |
| CLIP_ViL_p | integrate CLIP with V&L pre-training on image-text pairs and transfer to downstream tasks |
④Tasks: Visual Question Answering, Image Captioning, and Vision-and-Language Navigation
2.3. Background and Motivation
①Training stage:
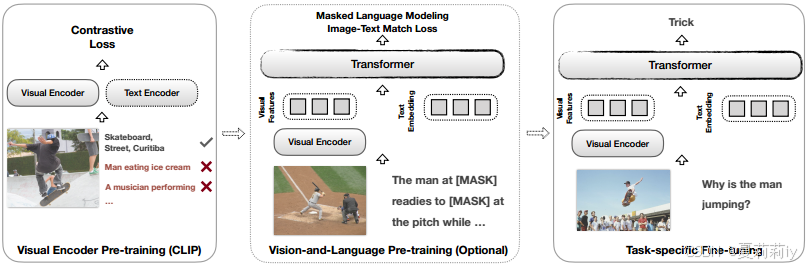
visual encoder pretrianing, alignment (opt), downstream task
②Different types of model:
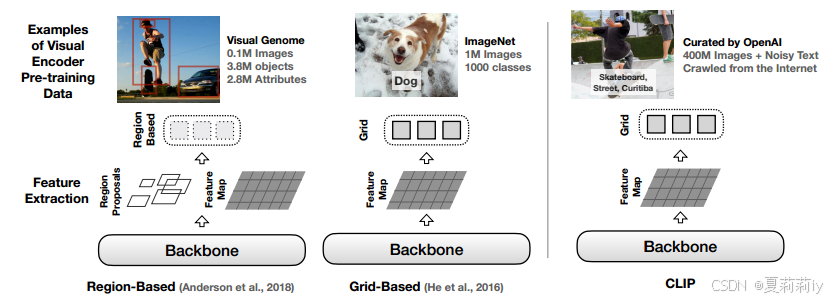
region based, network based, and CLIP (contrastive)
2.3.1. Motivation
①就是说直接把CLIP用在不同复杂视觉任务上性能一般般所以要小改一下
2.4. CLIP-ViL
2.4.1. Visual Question Aswering
①Performance of models on VQA v2.0 dataset:
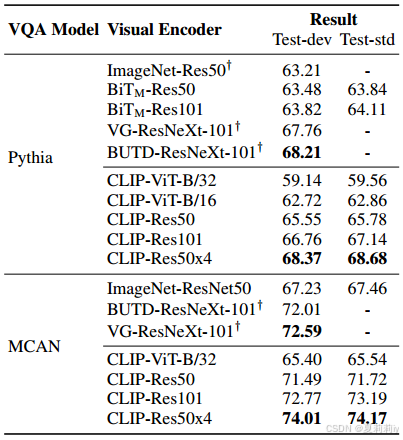
2.4.2. Image Captioning
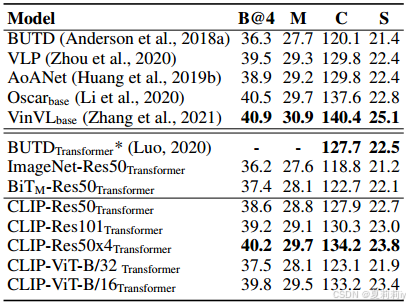
①Image captioning comparison table on COCO dataset:
2.4.3. Vision-and-Language Navigation
①The model performance on Room-to-Room (R2R) dataset:
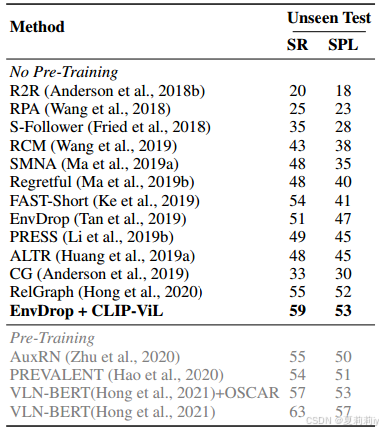
②Changing ResNet to CLIP, the performance table:
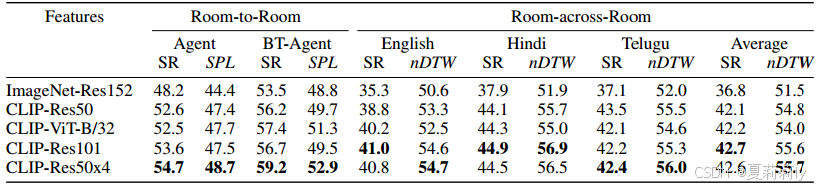
2.5. Vision-and-Language Pre-training
2.5.1. CLIP-VIL_p
①For text segment , tokenize it into subwords
and further embedded as the sum of its token, position and segment embeddings
②Image is is embedded as
③Concatenate them two as
④Reconstruct sentence with 15% mask ratio, match text and image with the 50% correct sentence ratio, then execute visual question answering
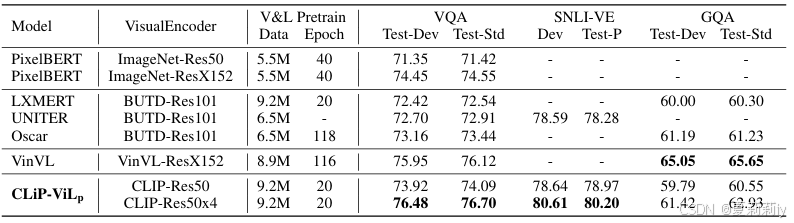
2.5.2. Experiments
①Two variants of CLIP as visual encoder: CLIP-Res50andCLIP Res50x4
②Datasets: MSCOCOCaptions, VisualGenomeCaptions, VQA,GQA, and VG-QA for pre-training
③Patch number for each image: 100
④Epoch of pretraining: 20
⑤Fine tune pretrained model on evaluation stage
⑥Dataset of tasks: VQAv2.0, visual entailment SNLI-VE, and GQA
⑦Results:
2.6. Analysis
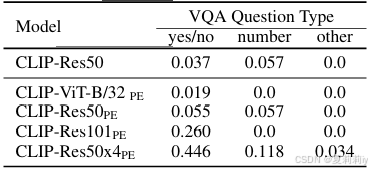
①Zero-shot performance of CLIP on VQA v2.0 mini-eval:
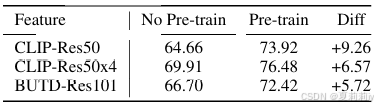
②Influence of V&L pre-training:
③Visualization of feature positioning of different models:

2.7. Conclusions
~