大模型原理、架构与落地
近年来,大模型(Large Language Models,LLMs)在人工智能领域迅猛发展,从GPT-3到GPT-4、Claude、Gemini、文心一言、GLM等模型相继发布,大模型已逐渐走出实验室,迈向产业落地。本文将从技术原理、模型架构、训练技巧、推理优化到实际应用进行系统剖析,帮助读者深入掌握大模型相关知识,全面提升AI实战能力。
目录
第一部分:大模型的技术演进与架构原理
1.1 语言模型的发展历程
1.2 Transformer架构详解
1.2.1 自注意力机制(Self-Attention)
1.2.2 多头注意力(Multi-Head Attention)
1.2.3 残差连接与层归一化
1.2.4 位置编码
1.3 预训练-微调范式
第二部分:大模型训练的工程实践
2.1 数据构建与预处理
2.1.1 数据来源与清洗策略
2.1.2 分词与Tokenization策略
2.2 模型训练关键技术
2.2.1 混合精度训练(Mixed Precision)
2.2.2 梯度裁剪与累积
2.2.3 学习率调度与Warmup
2.3 分布式训练策略与框架
2.3.1 ZeRO优化器(DeepSpeed)
2.3.2 框架对比分析
第三部分:大模型推理优化与部署实践
3.1 推理性能瓶颈与优化策略
3.1.1 KV缓存优化与动态Batch合并
3.1.2 Prompt合并与请求复用
3.2 模型压缩技术详解
3.2.1 量化(Quantization)
3.2.2 蒸馏(Knowledge Distillation)
3.2.3 参数高效微调(LoRA/QLoRA)
3.3 高性能推理引擎与部署实践
3.3.1 常用推理引擎
3.3.2 云端部署方案
第四部分:实际应用与案例分析
4.1 多模态模型与RAG增强能力
4.1.1 多模态模型结构设计
4.1.2 检索增强生成(RAG)
4.2 行业落地场景分析
4.2.1 智能客服与对话系统
4.2.2 编程辅助与代码生成
4.2.3 医疗、法律等专业领域
4.3 开源大模型与微调实践
4.3.1 代表性模型
4.3.2 微调流程示意
第一部分:大模型的技术演进与架构原理
1.1 语言模型的发展历程
语言模型最早起源于统计建模,如n-gram模型,通过计算词语联合概率对文本建模。然而这类模型对上下文建模能力有限,随着神经网络的兴起,出现了RNN、LSTM等循环神经网络,它们可以处理序列依赖关系,但难以捕捉长距离信息。
以LSTM为例,其核心结构包含输入门、遗忘门、输出门,能够保留部分历史信息。然而在面对长文本输入时,依旧存在梯度消失、训练不稳定的问题。
import torch
import torch.nn as nn# 简单的LSTM模块定义
lstm = nn.LSTM(input_size=100, hidden_size=128, num_layers=2, batch_first=True)
input_seq = torch.randn(32, 50, 100) # batch_size=32, seq_len=50, feature_dim=100
output, (hn, cn) = lstm(input_seq)Transformer模型的提出彻底变革了语言模型的架构,使得序列间的依赖可以通过注意力机制并行建模,带来性能与扩展性的质变。
1.2 Transformer架构详解
Transformer由以下几部分组成:
1.2.1 自注意力机制(Self-Attention)
自注意力机制使模型能在处理每个token时考虑序列中所有位置的信息。其计算核心如下:
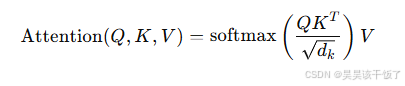
其中,$Q, K, V$ 分别是查询、键、值矩阵,$d_k$ 是向量维度。
import torch
import torch.nn.functional as Fdef scaled_dot_product_attention(Q, K, V):d_k = Q.size(-1)scores = torch.matmul(Q, K.transpose(-2, -1)) / d_k**0.5weights = F.softmax(scores, dim=-1)return torch.matmul(weights, V)1.2.2 多头注意力(Multi-Head Attention)
多头注意力机制将注意力层复制多个分支,使模型能从不同子空间并行学习不同的注意力分布。
# Multi-head 架构(简化表示)
class MultiHeadAttention(nn.Module):def __init__(self, heads, d_model):super().__init__()self.heads = headsself.d_k = d_model // headsself.qkv_linear = nn.Linear(d_model, d_model * 3)self.out_linear = nn.Linear(d_model, d_model)def forward(self, x):qkv = self.qkv_linear(x) # [batch, seq, 3*d_model]# 拆分为多个头并执行注意力机制...return self.out_linear(output)1.2.3 残差连接与层归一化
Transformer 使用残差连接与 LayerNorm 来维持梯度流动,提高训练稳定性。
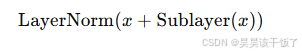
这使得每一层都可以在保留原始信息的同时,加入新的特征变换。
1.2.4 位置编码
Transformer本身不具备序列顺序建模能力,因此引入位置编码:
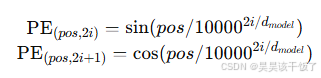
def positional_encoding(seq_len, d_model):import numpy as npPE = torch.zeros(seq_len, d_model)position = torch.arange(0, seq_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))PE[:, 0::2] = torch.sin(position * div_term)PE[:, 1::2] = torch.cos(position * div_term)return PE1.3 预训练-微调范式
大模型的训练普遍采用“预训练+微调”的范式,先使用海量通用语料预训练模型,再将其迁移到具体任务上微调。
以GPT为例,其预训练任务为自回归语言建模(Causal Language Modeling):
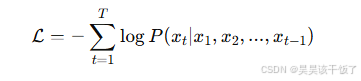
在微调阶段,只需用少量标注数据继续训练模型即可适配具体任务,如摘要生成、问答系统、代码补全等。
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
inputs = tokenizer("今天天气不错,", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))第二部分:大模型训练的工程实践
2.1 数据构建与预处理
大模型的性能离不开高质量的大规模语料。训练前的数据准备工作包括文本收集、去重、分词、过滤敏感信息、数据增强等多个步骤。这些环节对模型训练稳定性、泛化能力乃至伦理安全影响极大。
2.1.1 数据来源与清洗策略
典型的数据源包括维基百科、Common Crawl、Reddit、知乎问答、代码仓库(如GitHub)等。数据预处理一般包含如下步骤:
-
数据去重:基于哈希(如SimHash)或相似度检测(如Jaccard)去除重复段落。
-
语言识别与筛选:保留目标语言样本,可用
langdetect、fasttext库。 -
敏感词与垃圾文本过滤:正则表达式结合黑名单策略。
-
格式规范化:统一标点、空格、编码格式等,提升模型收敛速度。
from langdetect import detect
import redef clean_text(text):if detect(text) != 'zh':return Nonetext = re.sub(r"\s+", " ", text)text = re.sub(r"[^一-龥a-zA-Z0-9,.!?]", "", text)return text.strip()2.1.2 分词与Tokenization策略
Transformer架构需将文本转为token输入,分词器的设计直接影响模型输入长度、训练速度与语义切分。
目前主流子词分词算法:
-
BPE(Byte Pair Encoding):合并频繁出现的子串,提高语义一致性。
-
WordPiece:用于BERT,关注词干与词缀结构。
-
SentencePiece:基于Unigram模型的无空格训练方式,适合中日韩语言。
from transformers import AutoTokenizer# 使用BPE分词器
tokenizer = AutoTokenizer.from_pretrained("gpt2")
text = "大模型时代已经到来。"
tokens = tokenizer.tokenize(text)
print(tokens)2.2 模型训练关键技术
2.2.1 混合精度训练(Mixed Precision)
使用FP16(半精度)训练可降低显存占用并提高训练速度,但需注意数值稳定性。PyTorch支持自动混合精度训练(AMP):
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():output = model(input)loss = criterion(output, target)scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()2.2.2 梯度裁剪与累积
大模型常出现梯度爆炸问题,可使用torch.nn.utils.clip_grad_norm_()裁剪梯度,保持稳定训练。此外,显存不足时可采用梯度累积技术:
# 简单的梯度累积伪代码
for i, batch in enumerate(dataloader):output = model(batch)loss = compute_loss(output)loss = loss / accumulation_stepsloss.backward()if (i + 1) % accumulation_steps == 0:optimizer.step()optimizer.zero_grad()2.2.3 学习率调度与Warmup
Warmup + Cosine Annealing 是当前广泛使用的策略,训练前期缓慢增大学习率以避免不稳定,随后缓慢降低。
from transformers import get_cosine_schedule_with_warmup
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=100000)2.3 分布式训练策略与框架
随着模型规模增长,单机训练难以满足计算与显存需求。需引入分布式训练策略:
-
数据并行(DP):复制模型至多GPU处理不同数据子集。
-
模型并行(MP):将模型不同层划分到不同GPU。
-
张量并行(TP):将矩阵乘法拆分后分布执行。
-
流水并行(PP):借助层间依赖推进训练流程,适合深层模型。
综合使用上述策略构成混合并行训练。
2.3.1 ZeRO优化器(DeepSpeed)
ZeRO(Zero Redundancy Optimizer)是Deepspeed提出的显存优化方法,其核心思想为:
-
ZeRO-1:优化器状态分片
-
ZeRO-2:优化器状态 + 梯度分片
-
ZeRO-3:模型参数、梯度与优化器状态全部分片
# DeepSpeed 配置文件样例(json)
"zero_optimization": {"stage": 2,"allgather_partitions": true,"overlap_comm": true,"reduce_bucket_size": 5e8
}2.3.2 框架对比分析
| 框架 | 优势 | 场景适配 |
|---|---|---|
| DeepSpeed | 高效显存利用、兼容性强 | 百亿级大模型训练 |
| Megatron-LM | NVIDIA官方,优化推理效率 | Transformer密集计算 |
| Colossal-AI | 支持张量/流水并行、调度器灵活 | 自定义并行训练架构 |
第三部分:大模型推理优化与部署实践
3.1 推理性能瓶颈与优化策略
训练完成的大模型若不能高效部署,其实际价值将大打折扣。推理阶段的典型瓶颈包括:
-
内存占用高,尤其是KV Cache存储每层历史状态
-
响应延迟大,影响用户体验
-
吞吐量不足,难以支撑大规模服务
3.1.1 KV缓存优化与动态Batch合并
推理阶段,每个Token的生成都需依赖历史token的KV缓存,存储消耗如下:
![]()
其中$L$为序列长度,$H$为头数,$D$为每头维度,$B$为Batch size。
可采用如下方法优化:
-
静态分配缓存结构,避免频繁重建
-
使用FlashAttention等优化内存访问
-
通过Token Streaming加快生成速度
# KV Cache 示例结构
class KVCache:def __init__(self, num_layers, batch_size, seq_len, hidden_dim):self.key_cache = torch.zeros(num_layers, batch_size, seq_len, hidden_dim)self.value_cache = torch.zeros_like(self.key_cache)3.1.2 Prompt合并与请求复用
针对高并发部署,可使用Prompt合并技术将多个请求在同一Batch中执行,提升GPU利用率。vLLM等推理引擎已内置该功能,极大提高吞吐性能。
3.2 模型压缩技术详解
3.2.1 量化(Quantization)
量化通过降低精度(如FP32→INT8)减少存储和计算开销。典型方案:
-
Post-Training Quantization(PTQ):无需再训练,部署简便
-
Quantization-Aware Training(QAT):训练中感知量化误差,精度更高
from neural_compressor import quantization
q_model = quantization.fit(model, conf=config, calib_dataloader=dataloader)3.2.2 蒸馏(Knowledge Distillation)
训练一个小模型模仿大模型输出,从而大幅减少参数量。如DistilGPT、TinyBERT即为成功案例。
# 蒸馏损失由真实标签与teacher输出共同组成
loss = alpha * CE(student(input), label) + beta * KL(student(input), teacher(input))3.2.3 参数高效微调(LoRA/QLoRA)
通过冻结大模型主体,仅微调小规模可学习矩阵,大幅降低训练和推理负担。
from peft import get_peft_model, LoraConfig
config = LoraConfig(r=8, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, config)3.3 高性能推理引擎与部署实践
3.3.1 常用推理引擎
| 引擎 | 特点 | 使用场景 |
|---|---|---|
| vLLM | 支持Prompt合并,KV cache优化 | 高并发文本生成 |
| ONNX | 跨平台兼容性强 | Web/API部署 |
| TensorRT | NVIDIA深度优化 | 实时推理、视频流应用 |
| llama.cpp | CPU部署支持,轻量 | 无GPU设备,嵌入式终端 |
3.3.2 云端部署方案
云平台支持快速部署模型,如:
-
HuggingFace Inference Endpoint
-
AWS SageMaker
-
阿里云PAI-EAS
推荐流程如下:
-
使用Transformers或vLLM部署模型推理服务
-
结合FastAPI或Triton构建RESTful API
-
利用Docker + Nginx完成负载均衡与容器化部署
# FastAPI部署示意
uvicorn app:server --host 0.0.0.0 --port 8080 --workers 4第四部分:实际应用与案例分析
4.1 多模态模型与RAG增强能力
近年来,大模型正从“单一文本输入”走向多模态处理,即支持图像、视频、语音等输入类型,提升模型泛化与交互能力。典型如GPT-4V、Gemini、文心多模态等,在文本生成任务中引入图像上下文,支持复杂的多模态问答、图文解读、OCR分析。
4.1.1 多模态模型结构设计
多模态大模型通常采用以下结构:
-
图像编码器(如CLIP或ViT)提取视觉特征
-
将图像向量投射至语言模型词向量空间
-
使用融合策略(early/late fusion)结合文本与图像输入
# 融合示例:将图像特征连接到语言模型输入序列前
image_feat = vision_encoder(image)
text_input_ids = tokenizer("请描述图像中的场景", return_tensors="pt")
input_embeds = torch.cat([image_feat, model.embeddings(text_input_ids)], dim=1)4.1.2 检索增强生成(RAG)
RAG(Retrieval-Augmented Generation)融合了信息检索与生成能力,使模型能基于外部知识库作答。
典型架构流程:
-
用户提问 → 文本编码
-
相似向量检索(FAISS/Milvus) → 找到候选文档
-
拼接文档到Prompt中,输入至大模型生成回答
# 向量检索伪代码
query_vector = embedding_model.encode(query)
docs = faiss_index.search(query_vector, top_k=5)
prompt = build_prompt_with_docs(docs, query)
response = llm.generate(prompt)RAG适用于FAQ问答、企业知识库查询、法规解读等领域,兼顾准确率与响应速度。
4.2 行业落地场景分析
4.2.1 智能客服与对话系统
大模型具备上下文理解、指令执行、情绪识别能力,是智能客服的核心引擎之一。结合多轮记忆与用户画像可构建“个性化虚拟助手”。
部署要点:
-
使用意图识别模块结合知识图谱提升响应准确率
-
多轮对话状态管理器实现上下文追踪
-
引入提示模板(Prompt Engineering)控制回答风格
prompt = f"你是银行的智能客服。客户问题:{query},请简洁专业地回答。"
response = llm.generate(prompt)4.2.2 编程辅助与代码生成
GitHub Copilot、CodeGeeX等是典型的大模型编程助手应用,可用于:
-
函数补全
-
代码注释与解释
-
多语言代码迁移
以Transformers为例构建代码补全器:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-2B")
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-2B")input_code = "def quicksort(arr):"
input_ids = tokenizer(input_code, return_tensors="pt").input_ids
output = model.generate(input_ids, max_new_tokens=64)
print(tokenizer.decode(output[0]))4.2.3 医疗、法律等专业领域
这些行业具备强专业性,通常采用“领域微调+外部知识增强”方式提升准确率。
应用示例:
-
法律助手:案件摘要生成、法律条文匹配
-
医疗问答:用药指南、病历摘要、辅助诊断
-
合规生成:结合企业制度文档生成审查报告
# 医疗问答示意
prompt = f"你是医学专家。请根据以下资料,回答用户问题:{question}\n资料:{medical_passage}"4.3 开源大模型与微调实践
4.3.1 代表性模型
| 模型 | 发布者 | 特色 | 开源支持 |
|---|---|---|---|
| ChatGLM | 智谱AI | 中英双语、结构紧凑 | ✅ |
| InternLM | 上海AI实验室 | 支持FP8推理,适合长文本处理 | ✅ |
| LLaMA/Mistral | Meta/社区 | 推理快、小模型效果优 | ✅ |
| Baichuan | 百川智能 | 商业可用,微调接口丰富 | ✅ |
4.3.2 微调流程示意
from transformers import TrainingArguments, Trainer
from datasets import load_dataset# 加载模型和数据
dataset = load_dataset("csv", data_files="data.csv")
training_args = TrainingArguments("./results", per_device_train_batch_size=4, num_train_epochs=3)
trainer = Trainer(model=model, args=training_args, train_dataset=dataset['train'])
trainer.train()此外,还可结合LoRA、QLoRA等技术进行高效参数微调,适用于资源受限场景。