问题复盘-当前日志组损坏问题
复盘描述
填写复盘相关的基础信息。
| 复盘主题 | Current日志组损坏场景下的几种恢复方法 |
| IP地址 | 192.168.56.111 测试环境 |
| 操作系统 | Centos7 |
| 数据库 | Oracle 11.2.0.4 单实例 |
| 问题来源 | 测试环境 |
问题场景
详细描述问题发生的前置场景
前置环境:
在一个Oracle单实例环境中,配置了有4组日志组,每组日志组有两个成员
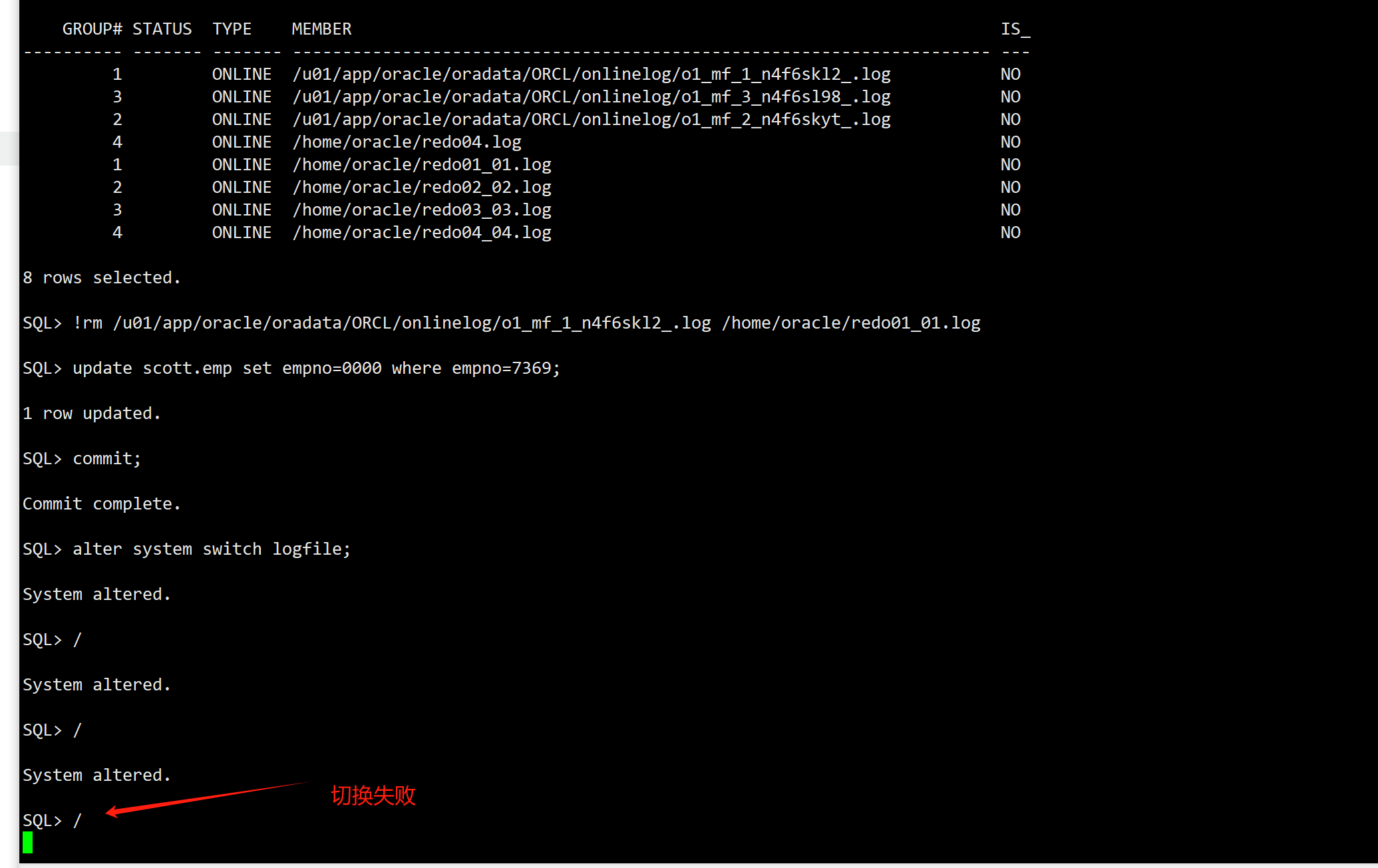
SQL> select * from v$log;GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME
---------- ---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- --------- ------------ ---------1 1 5 52428800 512 2 NO CURRENT 4701500 09-JUN-25 2.8147E+142 1 2 52428800 512 2 NO INACTIVE 4701491 09-JUN-25 4701494 09-JUN-253 1 3 52428800 512 2 NO INACTIVE 4701494 09-JUN-25 4701497 09-JUN-254 1 4 52428800 512 2 NO INACTIVE 4701497 09-JUN-25 4701500 09-JUN-25SQL> col member for a70
SQL> select * from v$logfile;GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ---------------------------------------------------------------------- ---1 ONLINE /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log NO3 ONLINE /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_3_n4f6sl98_.log NO2 ONLINE /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_2_n4f6skyt_.log NO4 ONLINE /home/oracle/redo04.log NO1 ONLINE /home/oracle/redo01_01.log NO2 ONLINE /home/oracle/redo02_02.log NO3 ONLINE /home/oracle/redo03_03.log NO4 ONLINE /home/oracle/redo04_04.log NO8 rows selected.
所做操作:
删除数据库当前正在使用的current日志组的所有成员
SQL> !rm /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log /home/oracle/redo01_01.log
问题表现:
1、数据库实例并没有立即崩溃,尝试手动发起一个事务并提交,数据库依旧没有崩溃。
SQL> !rm /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log /home/oracle/redo01_01.logSQL> update scott.emp set empno=0000 where empno=7369;1 row updated.SQL> commit;Commit complete.
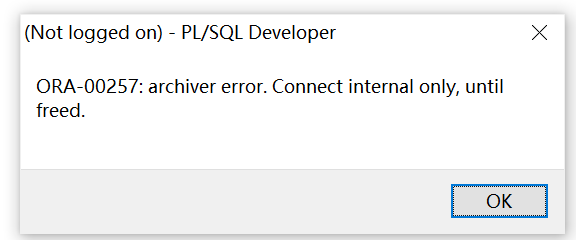
2、连续切换归档至下一次使用已经删除成员的日志组做当前日志组,会话卡住数据库没有崩溃,但是检查点和clear损坏日志组操作都会卡住并失败,此时任何远程登陆会话都报错归档错误而无法连接。
问题解析
对上诉问题进行逐一拆解并分析根因
问题一:
原因在于操作系统上做了删除文件操作,但是实例层面使用了文件缓存(内存),所以依旧可以正常commit事务。
[root@centos7 yum.repos.d]# lsof |grep -E "delete|FD"
COMMAND PID TID USER FD TYPE DEVICE SIZE/OFF NODE NAME
oracle 9170 oracle 258u REG 253,0 52429312 947873 /home/oracle/redo01_01.log (deleted)
oracle 9170 oracle 259u REG 253,0 52429312 16885099 /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log (deleted)
问题二:
原因在于切换后已经损坏的日志组成员在内存缓存失效,再次使用该日志组的时候,会重新读写磁盘文件,由于文件被删除了就会一直报校验失败,由于先前切换操作导致缓存释放,无法与磁盘文件进行sync,实例也不会有对应的信息做检查点以及归档操作,同样的clear操作也是执行不了(需要检查点先完成)。
SQL> select * from v$logfile;GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ---------------------------------------------------------------------- ---1 ONLINE /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log NO3 ONLINE /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_3_n4f6sl98_.log NO2 ONLINE /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_2_n4f6skyt_.log NO4 ONLINE /home/oracle/redo04.log NO1 ONLINE /home/oracle/redo01_01.log NO2 ONLINE /home/oracle/redo02_02.log NO3 ONLINE /home/oracle/redo03_03.log NO4 ONLINE /home/oracle/redo04_04.log NO8 rows selected.SQL> !ls /home/oracle/redo01_01.log
ls: cannot access /home/oracle/redo01_01.log: No such file or directorySQL> !ls /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log
ls: cannot access /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log: No such file or directory
问题解决
针对性的解决问题思路和方案
通用方法:
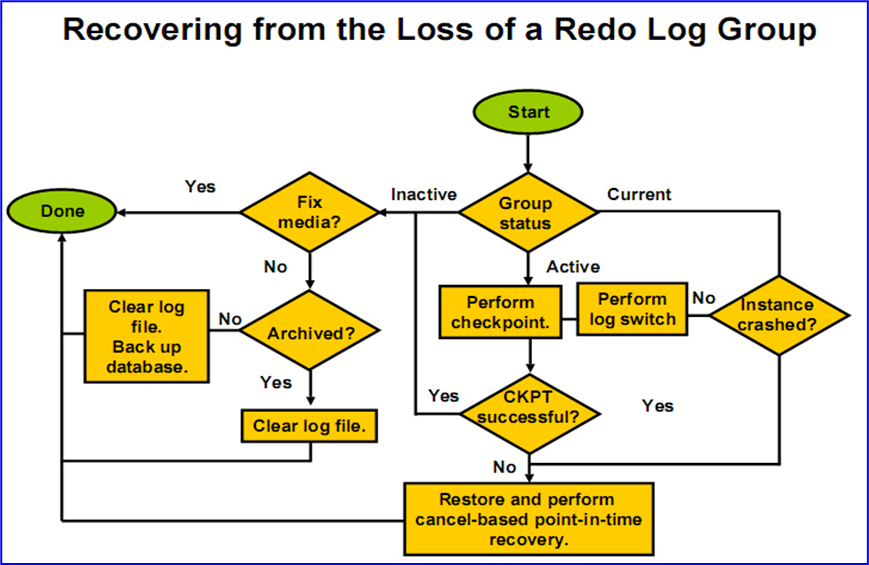
对于日志组损坏,不同状态有不同的解决方案,有下面这样一个流程图可供参考:
问题一:
- 数据恢复:如果需要恢复这些文件,可以通过 lsof 找到文件的进程ID,然后使用 cp 或 dd 命令从
/proc/<pid>/fd/<fd>复制文件内容。
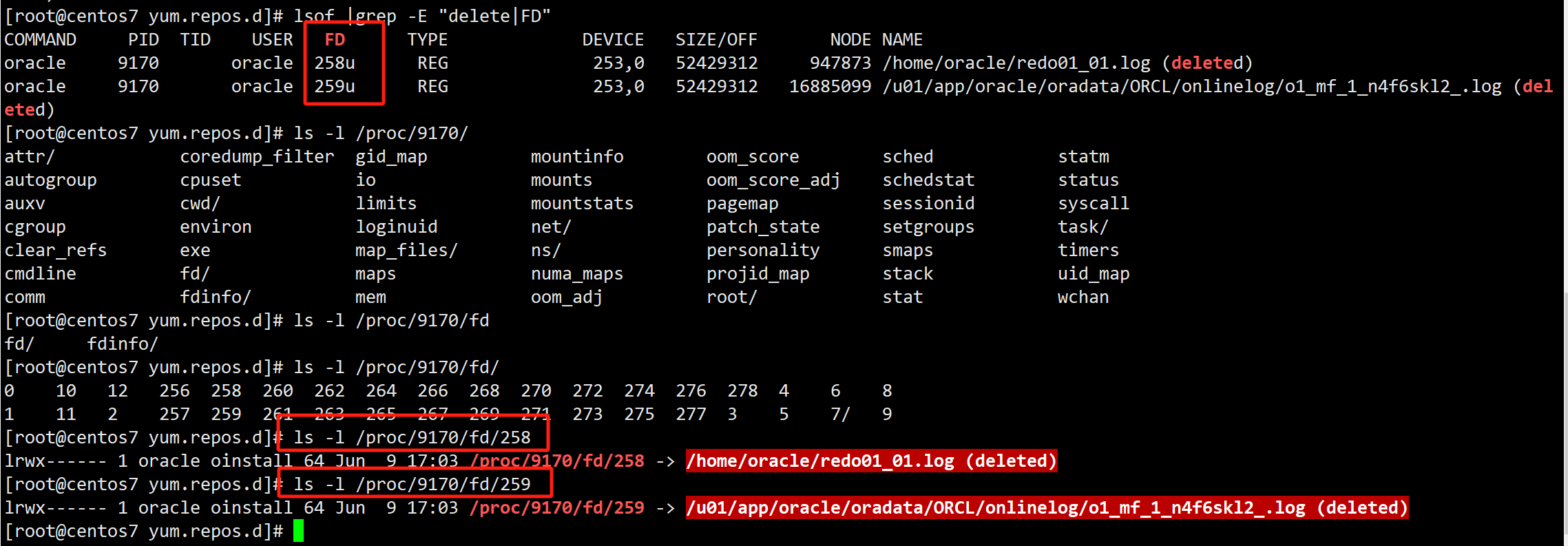
操作如下:
[root@centos7 yum.repos.d]# ls -l /proc/9170/fd/258
lrwx------ 1 oracle oinstall 64 Jun 9 17:03 /proc/9170/fd/258 -> /home/oracle/redo01_01.log (deleted)
[root@centos7 yum.repos.d]# ls -l /proc/9170/fd/259
lrwx------ 1 oracle oinstall 64 Jun 9 17:03 /proc/9170/fd/259 -> /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log (deleted)
[root@centos7 yum.repos.d]# cp /proc/9170/fd/258 /home/oracle/redo01_01.log
[root@centos7 yum.repos.d]# cp /proc/9170/fd/259 /u01/app/oracle/oradata/ORCL/onlinelog/o1_mf_1_n4f6skl2_.log问题二:
1)数据库没有崩溃
第一步,可以做一个完全检查点,将db buffer中的所有dirty buffer全部刷新到磁盘上。
SQL> alter system checkpoint;
第二步,尝试数据库在打开状态下进行不做归档的强制清除。
SQL> alter database clear unarchived logfile group n;
实测失败了
数据库此时为打开状态,这步若能成功,一定要做一个新的数据库全备,因为当前日志无法归档,归档日志sequence已无法保持连续性。全备的目的就是甩掉之前的归档日志。
2)数据库已经崩溃,只能做传统的基于日志的不完全恢复或使用闪回数据库。
SQL> recover database until cancel;
SQL> alter database open resetlogs;
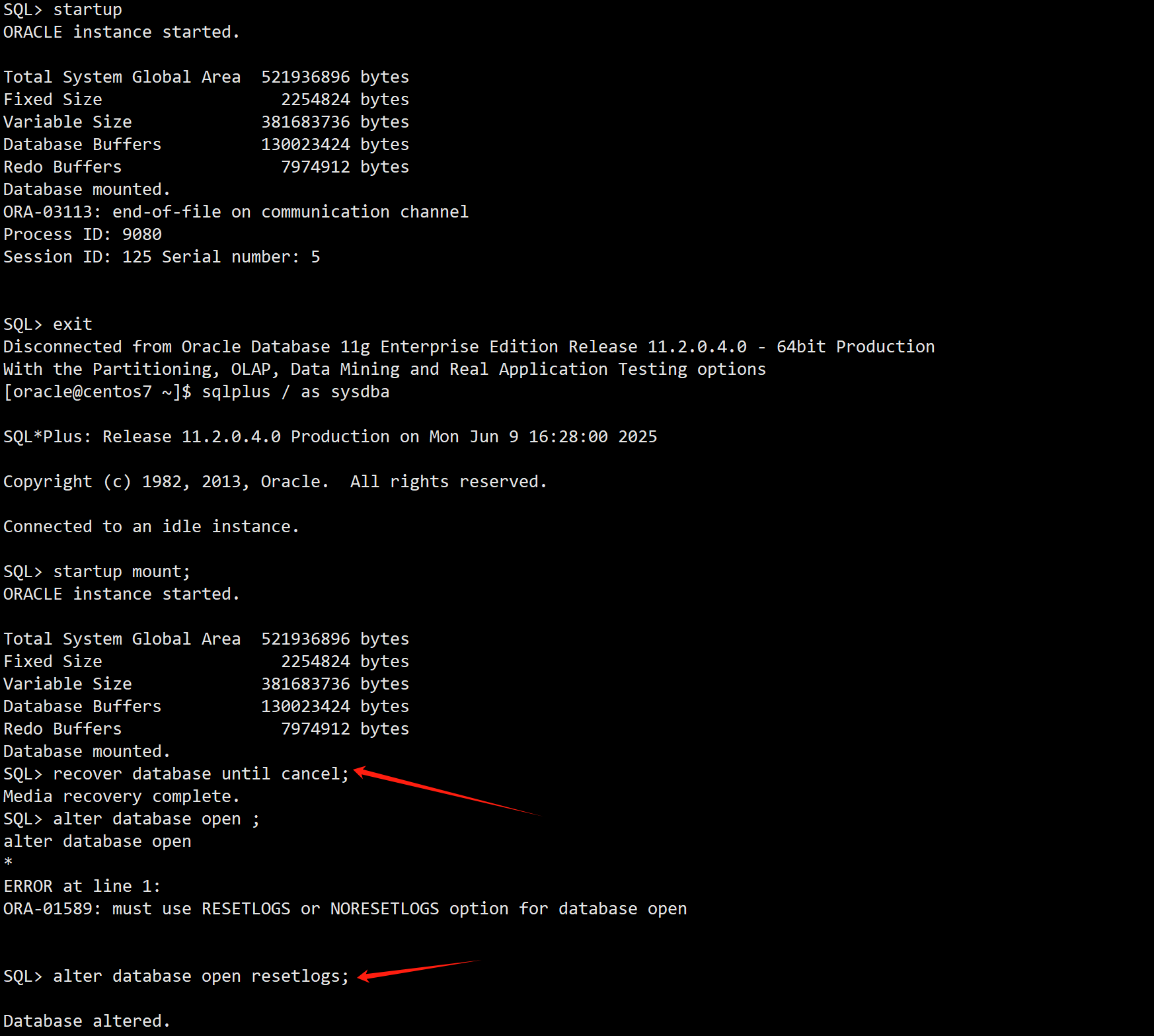
3)如果之前没有可用的备份,或问题严重到任何方法都不能resetlogs打开数据库,为了抢救数据,考虑最后一招使用Oracle的隐含参数:”_allow_resetlogs_corruption”=TRUE
Oracle不推荐使用这个隐含参数
该参数的含义是:允许数据库在不致性的情况下强制打开数据库。_
最终解决方案,还没有试过