操作系统期末版
文章目录
- 概论
- 处理机管理
- 进程
- 线程
- 处理机调度
- 生产者消费者问题
- 死锁简介
- 死锁的四个必要条件
- 解决死锁的方法
- 存储管理
- 链接的三种方式
- 静态链接
- 装入时动态链接
- 运行时链接
- 装入内存的三种方式
- 绝对装入
- 可重定位装入
- 动态运行时装入
- 覆盖
- 交换
- 存储管理方式
- 连续分配
- **分段存储管理方式**
- **分页存储管理方式**
- 快表
- 虚拟存储器
- **(1) 虚拟地址空间**
- **(2) 地址映射**
- **(3) 页面交换(Paging/Swapping)**
- **(4) 按需分页(Demand Paging)**
- 置换算法
- **(1) 先进先出(FIFO, First-In-First-Out)**
- **(2) 最近最少使用(LRU, Least Recently Used)**
- **(3) 最优置换算法(OPT, Optimal Page Replacement)**
- **(4) 时钟算法(Clock Algorithm,或Second-Chance Algorithm)**
- **(5) 最近最常使用(LFU, Least Frequently Used)**
- **3. 算法对比总结**
- 抖动
- **5. 如何解决抖动?**
- 文件管理
- 目录
- 软链接实现文件共享
- 软链接的优点
- 软链接的缺点
- 设备管理
- 输入输出系统
- **1. I/O系统的功能**
- **2. I/O系统的模型**
- **3. I/O系统的接口**
- 设备控制器
- 三种控制方式
- **1. 什么是中断?**
- **2. 什么是中断处理程序?**
- **3. 中断和中断处理程序的工作流程**
- **1. 什么是用户层的 I/O 软件?**
- **2. 主要功能**
- **3. 工作原理**
- **1. 什么是假脱机系统?**
- **2. 假脱机系统的原理**
- 缓冲区管理
- **通俗介绍缓冲区管理**
- **1. 什么是缓冲区管理?**
- **2. 缓冲区管理的原理**
- **3. 主要功能**
- **4. 常见缓冲区管理技术**
- **5. 优点**
- **6. 缺点**
- 磁盘存储器管理
- 外存组织方式
- 连续分配
- 链接分配
- 索引分配
- 存储空间的管理
- 1. 空闲表法
- 2. 空闲链表法
- 3. 位图法(Bitmap)
- 4. 成组链接法
- 提高磁盘I/O速度的途径
- 1. 硬件升级
- 2. 软件优化
- 3. 文件系统选择
- 4. 操作习惯
- 多处理机操作系统
概论
操作系统:本质上是一个一直运行的软件,管理硬件,软件,内存,用户交互等计算机资源
操作系统的特征:
- 并发:两个或多个活动在同一时间中进行
- 共享:计算机系统中的资源被多个进程所共用
- 异步:进程以不可预知的速度向前推进。
- 虚拟:把一个物理上的实体抽象为逻辑上的对应物
操作系统的功能:
- 处理机管理:包括进程同步,进程通信,死锁处理,处理机调度等
- 存储器管理:包括内存分配,地址映射,内存保护与共享,内存扩充等
- 文件管理:包括文件存储空间的管理,目录管理,文件读写管理和保护等
- 设备管理:包括缓冲管理,设备分配,设备处理和虚拟设备等
原语:处在操作系统最底层的程序,运行具有原子性,不可中断,运行时间都比较短,且调用频繁。
内中断:通过指令自愿中断或被软硬件强迫中断
外中断:中断请求来自外部,如人工干预,外设请求等
系统调用:系统给程序员提供的唯一接口,使其可以使用内核层的特权指令
处理机管理
进程
进程(Process)是操作系统中正在运行的程序的实例,是资源分配和调度的基本单位。每个进程拥有独立的内存空间、程序代码、数据以及运行状态(如寄存器、堆栈等)。进程通过进程控制块(PCB)管理,包括进程状态、优先级、资源占用等信息。简单来说,进程是程序执行的动态过程,彼此之间相对隔离。
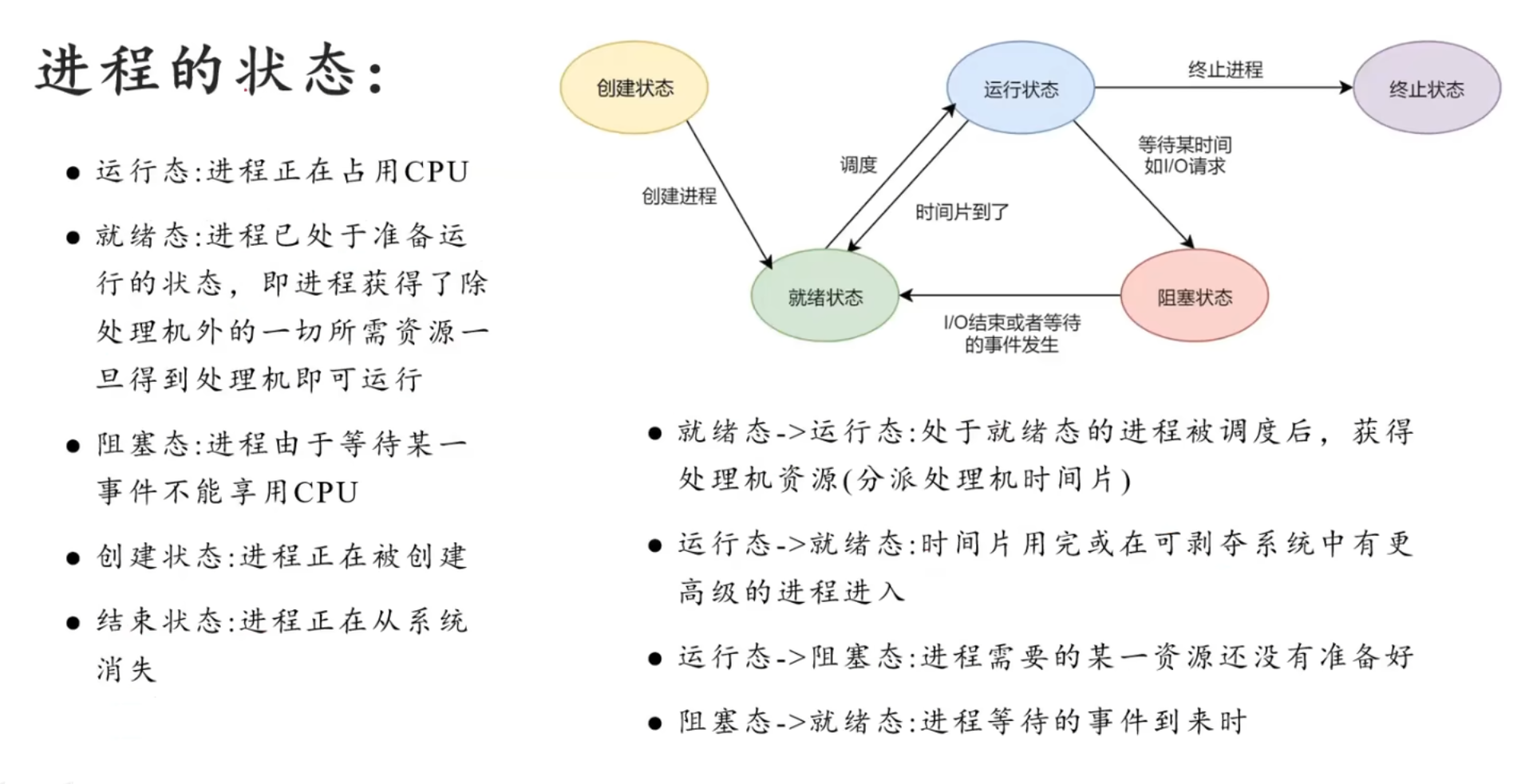
进程和程序的关系:进程是动态的程序执行,程序是静态的代码的集合,进程是暂时的,程序是永久的。进程的组成包括程序,数据块和进程控制块。
线程
线程(Thread)是进程中的一个执行单元,是CPU调度的最小单位。一个进程可以包含多个线程,这些线程共享进程的资源(如内存、文件句柄等),但每个线程有自己的栈、寄存器和程序计数器。线程的运行相对轻量,适合处理并发任务。
处理机调度

非剥夺:必须等其他东西运行完才可以调度
调度算法:
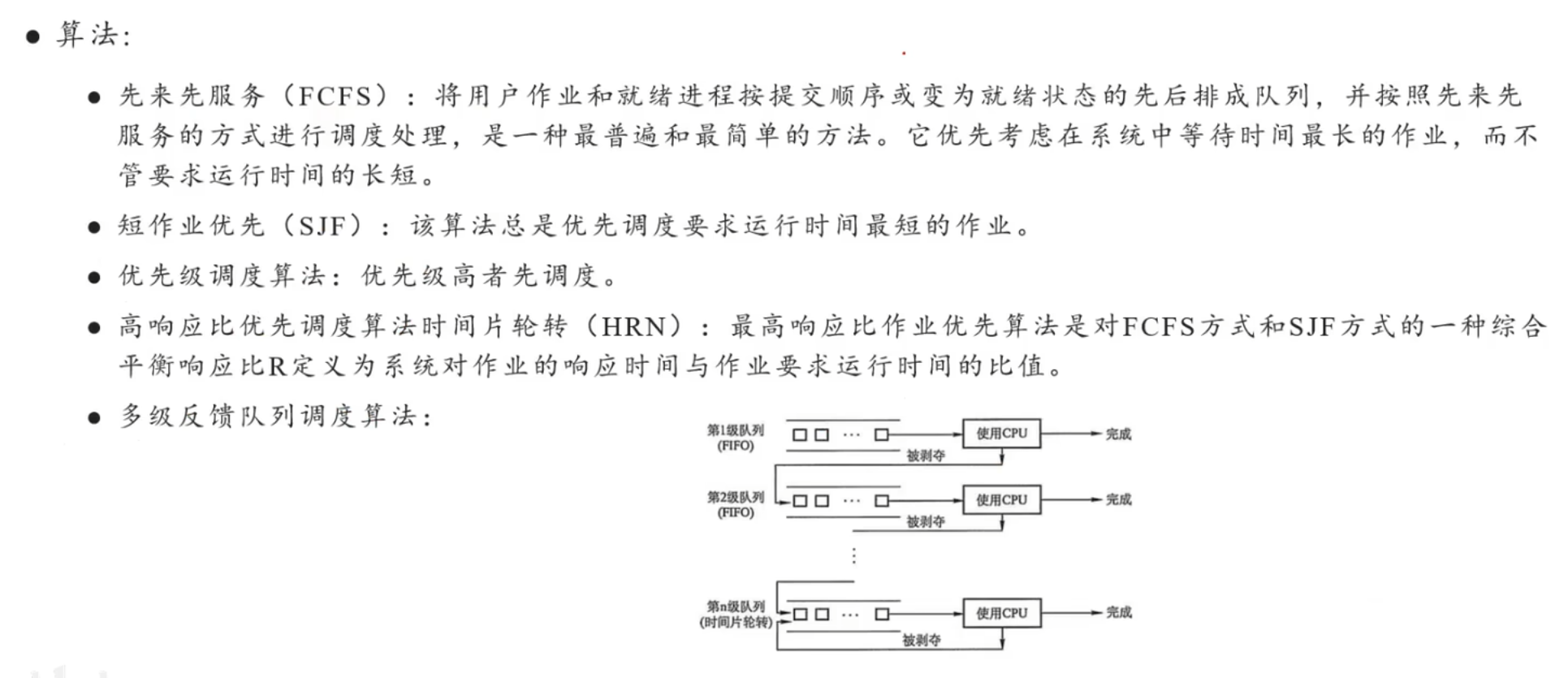
高响应比:1+已等待时间/完成所需时间(兼顾了先来先服务和短作业优先算法)
多级队列:不同优先级分别设置队列
时间片轮转:每个进程给一定时间,时间用完就换人,最公平的算法
计算题相关概念:
- 周转时间=完成时间-到达时间
- 带权周转时间=周转时间/运行时间
- 等待时间=周转时间-运行时间
具体的计算,首先根据使用的算法安排进程执行顺序,其次分析每个进程的到达时间和实际完成时间
临界区的作用和相关机制

临界区的访问原则:
- 空闲让进
- 忙则等待
- 有限等待
- 让权等待
实现机制:
采用信号量,利用PV操作实现互斥
生产者消费者问题
数据定义
int n //有n个缓冲区,每个缓冲区可放一个数据项
semaphone mutex=1 //信号量mutex,初始化为1
semaphone empty=n //空的缓冲区数量为n
semaphone full=0 //满的缓冲区数量为0
生产者
producer(){while(1){生产一个产品;P(empty); //消耗一个空的缓冲区P(mutex); //确认有空间可以放才访问缓冲区把产品放入缓冲区PV(mutex);V(full); //增加一个产品}
}
消费者
consumer(){while(1){P(full); //如果有产品,就消费一个产品P(mutex); //去缓冲区拿从缓冲区取出一个产品V(mutex);V(empty);使用一个产品
}
}
死锁简介
死锁(Deadlock)是指多个进程(或线程)因竞争共享资源而相互等待,导致所有进程都无法继续执行的一种状态。每个进程都在等待其他进程释放资源,形成一个循环等待的僵局。
例如,进程A持有资源1并等待资源2,而进程B持有资源2并等待资源1,两者都无法前进。
死锁的四个必要条件
死锁发生需要同时满足以下四个条件,缺一不可:
- 互斥条件(Mutual Exclusion):
- 资源只能被一个进程独占,其他进程必须等待。
- 例如,打印机一次只能被一个进程使用。
- 占有并等待条件(Hold and Wait):
- 进程持有至少一个资源,同时等待其他进程持有的资源。
- 例如,进程A持有资源1并请求资源2。
- 不可抢占条件(No Preemption):
- 资源不能被强制抢占,只能由持有进程主动释放。
- 例如,进程A持有的资源1无法被其他进程强行夺取。
- 循环等待条件(Circular Wait):
- 进程间形成一个循环等待链,每个进程都在等待下一个进程持有的资源。
- 例如,A等B的资源,B等C的资源,C等A的资源。
解决死锁的方法
通过破坏上述四个条件之一,可以预防或解决死锁。以下是常见方法:
- 破坏互斥条件:
- 尽可能使资源可共享,减少独占性。
- 例如,使用读写锁允许多个进程同时读取数据。
- 局限性:某些资源(如打印机)天生需要独占,难以实现。
- 破坏占有并等待条件:
- 要求进程在开始执行前一次性申请所有需要的资源,若资源不足则不分配,进程等待。
- 例如,进程启动前声明需要资源1和资源2,系统确保两者都可用才分配。
- 实现方式:资源分配前检查,或采用“全或无”策略。
- 缺点:可能降低资源利用率,进程可能长时间等待。
- 破坏不可抢占条件:
- 允许系统抢占资源,强制将资源从一个进程转移到另一个进程。
- 例如,若进程A等待资源2超时,可释放其持有的资源1,供其他进程使用。
- 实现方式:设置超时机制或优先级调度。
- 缺点:抢占可能导致额外开销或数据不一致,需回滚操作。
- 破坏循环等待条件:
- 对资源编号,定进程必须按顺序请求资源(如先请求编号小的资源)。
- 例如,资源1编号为1,资源2编号为2,所有进程必须先请求1再请求2。
- 实现方式:资源分配图检测或严格的资源请求顺序。
- 优点:简单有效,易于实现。
- 缺点:可能限制灵活性,增加编程复杂性。
存储管理
从源程序到内存程序的三个步骤:编译,链接,和装入
编译:将高级语言翻译为机器语言
链接:链接器(linker)把多个目标文件(.o 文件)以及需要的库文件(比如标准库)“拼装”在一起,生成一个完整的可执行文件(比如 .exe 文件)。
- 链接具体干什么事:
- 符号解析:比如代码中用到printf,找到它在标准库中的具体位置
- 地址重定位:给每个函数和变量分配一个确定的内存地址,确保程序运行时能找到他们
装入:将可执行文件从硬盘搬到内存里
- 装入具体干什么事:
- 加载器:将可执行文件读入内存
- 分配内存空间
- 做一些动态链接
链接的三种方式
静态链接
是什么?
静态链接是在编译阶段就把所有需要的代码(包括目标文件和库文件)全部“打包”进最终的可执行文件,就像把所有食材和调料都提前混在一起,做成一个完整的“预制菜”。
怎么做?
- 链接器把你的程序目标文件(.o)和静态库(.a 或 .lib,比如 C 的标准库)合并。
- 所有函数和变量的地址都在链接时确定,生成的可执行文件包含了运行所需的所有代码。
- 可执行文件体积较大,但运行时不需要额外的库文件。
特点:
- 优点:独立性强,运行时不需要依赖外部库,适合在没有库的环境下运行。
- 缺点:文件体积大;如果库更新了,程序需要重新编译链接。
- 例子:一个 C 程序用静态链接把 libc.a 里的 printf 打包进 program.exe,运行时直接用,不需要外部文件。
装入时动态链接
是什么?
需要时才装入,边装入边动态链接。
怎么做?
- 链接器在生成可执行文件时,只记录需要的动态库(.so 或 .dll)的信息和函数的“占位符”(符号表)。
- 程序运行时,操作系统动态加载这些库(比如 Windows 的 .dll 文件或 Linux 的 .so 文件)到内存。
- 动态库的地址在运行时由加载器解析。
特点:
- 优点:可执行文件体积小;多个程序可共享同一份库,节省内存;库更新后无需重新编译程序。
- 缺点:运行时需要确保动态库存在,否则会报错(比如“缺少 xxx.dll”)。
- 例子:你的程序用 printf,链接器只记录 libc.so 的位置,运行时操作系统会加载 libc.so 里的 printf。
运行时链接
是什么?
运行时链接是程序在运行中主动加载某些库或模块。
怎么做?
- 程序通过特定的 API(如 Windows 的 LoadLibrary 或 Linux 的 dlopen)在运行时手动加载动态库。
- 程序可以根据需要动态决定加载哪些库,甚至卸载不需要的库。
- 常用于插件系统或动态扩展功能。
特点:
- 优点:灵活性极高,程序可以根据运行环境选择加载哪些模块。
- 缺点:程序员需要手动管理库的加载和卸载,代码复杂,容易出错。
- 例子:一个游戏程序运行时加载某个图形插件的 .dll 文件,以支持特定的显卡功能。
装入内存的三种方式
绝对装入
是什么?
绝对装入是直接把程序加载到内存中固定的、预先指定的地址,就像把菜直接装到固定的盘子里,位置完全确定。
怎么做?
- 可执行文件中已经包含了固定的内存地址(在编译和链接时就确定)。
- 加载器直接把程序加载到这些预定地址,基本不做修改。
- 常用于早期的简单系统或嵌入式设备。
特点:
- 优点:简单直接,加载速度快。
- 缺点:缺乏灵活性,内存地址固定,不能适应多程序运行或动态内存分配。
- 例子:嵌入式系统中,程序被加载到固定的 ROM 地址(如 0x1000),每次运行都在这个位置。
可重定位装入
是什么?
可重定位装入是在加载时临时决定程序在内存中的地址,就像把菜装到餐桌上随便哪个盘子,位置可以调整。
怎么做?
- 可执行文件中地址是相对的(比如“相对程序起点偏移 100 字节”)。
- 加载器在加载时根据内存的实际可用位置,重新计算并分配绝对地址(重定位)。
- 加载后,程序的地址是固定的,不能再次移动。
特点:
- 优点:比绝对装入灵活,适应多程序环境。
- 缺点:程序加载后地址固定,不能动态调整,内存碎片可能较多。
- 例子:早期操作系统(如 DOS)加载程序时,根据可用内存分配一个起始地址,然后调整所有地址。
动态运行时装入
是什么?
动态运行时装入允许程序在运行时动态调整内存地址,就像吃饭时可以随时换盘子或挪桌子,位置完全灵活。
怎么做?
- 程序使用虚拟地址,通过操作系统的内存管理单元(MMU)映射到实际物理地址。
- 加载器加载程序时,只分配虚拟地址空间,实际物理地址由操作系统动态管理。
- 支持程序在运行中被移动(如分页或分段机制),常用于现代操作系统。
特点:
- 优点:高度灵活,支持多任务、虚拟内存,内存利用率高。
- 缺点:实现复杂,依赖操作系统的内存管理机制,加载和运行开销稍大。
- 例子:现代操作系统(如 Windows、Linux)加载程序时,使用虚拟内存,程序感觉自己在独占内存,实际地址由操作系统动态分配。
覆盖
覆盖技术的基本思想:将程序分为多个段,常用的段常驻内存,不常用的段在需要时调入内存。
特点:打破了必须将一个进程的全部信息装入主存后才能运行的限制,解决了程序大小超过物理内存总和的问题
交换
基本思想:内存空间紧张时,将某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存
存储管理方式
连续分配
- 定义: 将用户程序分配到一个连续的内存区域中,程序的所有部分存储在连续的内存地址空间。
- 特点:
- 简单直接: 分配和释放内存操作简单,适合小型系统或简单任务。
- 内存利用率低: 容易产生外部碎片(内存中分散的小块空闲区域无法被有效利用)。
- 分配方式:
- 单一连续分配: 整个内存分配给一个程序,适用于单用户、单任务系统(如早期嵌入式系统)。
- 固定分区分配: 内存预先分成固定大小的区域,每个程序分配到一个分区,可能产生内部碎片(分区内未使用的空间)。
- 动态分区分配: 根据程序大小动态分配连续内存区域,分配灵活,但仍会产生外部碎片。
- 优点: 实现简单,访问速度快(因为地址连续)。
- 缺点: 内存碎片问题严重,扩展性差,适合小型或单一任务系统。
分段存储管理方式
- 定义: 将程序按逻辑功能(如代码段、数据段、栈段)划分为多个段,每段分配到内存中,段内地址连续,段间可以不连续。
- 特点:
- 逻辑划分: 按程序的逻辑结构(如函数、数组)划分段,段长可变,程序员可感知段的划分。
- 地址映射: 逻辑地址由段号+段内偏移组成,通过段表(记录每段的起始地址和长度)映射到物理地址。
- 内存分配: 动态分配,每段可以独立分配到非连续的内存区域。
- 碎片问题: 可能产生外部碎片,但比连续分配少,因为段可以分散存储。
- 优点:
- 逻辑结构清晰,便于程序模块化管理。
- 支持动态增长(如栈段、数据段可扩展)。
- 便于共享和保护(不同段可设置不同权限)。
- 缺点:
- 外部碎片仍存在。
- 段表管理增加系统开销。
- 地址转换稍复杂。
分页存储管理方式
- 定义: 将内存和程序分成固定大小的页面(page),程序的逻辑地址空间分页后映射到物理内存的页面框架(frame)中。
- 特点:
- 固定大小划分: 内存和程序都分成等大的页面(通常为4KB或8KB),页面大小由硬件决定。
- 地址映射: 逻辑地址由页面号+页内偏移组成,通过页表(记录页面与物理框架的映射)转换为物理地址。
- 内存分配: 页面可以分散存储在内存的任意框架中,消除了外部碎片。
- 碎片问题: 仅存在内部碎片(页面未用满的部分),通常较小。
- 优点:
- 消除了外部碎片,内存利用率高。
- 便于内存分配和回收,管理简单。
- 支持虚拟内存(通过页面置换实现)。
- 缺点:
- 页表可能占用较多内存(特别是大型程序)。
- 地址转换需要硬件支持(如MMU),增加开销。
- 不如分段直观,逻辑结构不明显。
页表的作用:实现页号到物理地址的映射
快表
快表(Translation Lookaside Buffer,TLB)是一种硬件缓存,用于加速分页存储管理中逻辑地址到物理地址的转换过程。它存储最近使用过的页面号与物理框架号的映射,是一种高速的关联存储器,通常集成在CPU的内存管理单元(MMU)中。
高速缓存:TLB是小型、快速的硬件缓存,访问速度远高于主存中的页表(通常只需1-2个时钟周期)。
工作原理:
- 当CPU需要转换逻辑地址时,先查询TLB。
- 如果TLB中包含该页面号(称为TLB命中),直接获取物理框架号,结合页内地址计算物理地址。
- 如果TLB未命中(Miss),则访问主存中的页表,获取映射后更新TLB。
提高地址转换效率:TLB大幅减少访问主存页表的次数,降低地址转换的延迟(主存访问可能需要几十到几百个时钟周期)。
支持虚拟内存:通过快速映射逻辑地址到物理地址,TLB支持现代操作系统的虚拟内存机制。
优化性能:由于程序的局部性原理(时间局部性和空间局部性),TLB命中率通常较高(90%以上),显著提升系统性能。
查询主存的次数:若快表命中,则一次访问主存。若没命中,则再去查询页表,页表在主存里,所以需要两次访问主存
多级页表的意义:节省空间,只为实际使用的空间分配页表条目,适合稀疏空间

多级页表把页面号分成几部分,逐级索引,只为实际使用的页面分配页表条目。以下以二级页表为例:
- 逻辑地址分解:
- 32位地址分为:10位一级索引 + 10位二级索引 + 12位页内偏移。
- 一级页表有2^10(1024)个条目,每个条目指向一个二级页表。
- 每个二级页表也有1024个条目,记录页面到物理框架的映射。
- 每个页表占4KB(1024 × 4字节)。
- 节省内存的关键:
- 如果进程只用到一小部分地址空间(比如1MB,256个页面),只需要分配1个二级页表(4KB)+一级页表的部分条目(4KB)。
- 总共占用约8KB内存,远小于单级页表的4MB。
- 对于没用到的地址空间,根本不分配二级页表,节省大量空间。
虚拟存储器
定义:虚拟存储器是操作系统提供的一种抽象机制,为每个进程提供一个独立的、看起来连续且巨大的虚拟地址空间(Virtual Address Space),而实际数据可能存储在物理内存(RAM)或外存(硬盘/SSD)中。
虚拟存储器通过将程序的逻辑地址(虚拟地址)映射到物理地址(主存或外存),结合分页或分段机制,实现了内存的高效管理。其核心原理包括:
(1) 虚拟地址空间
- 每个进程都有自己的虚拟地址空间,地址范围由系统架构决定:
- 32位系统:最大4GB(2^32字节)。
- 64位系统:理论上2^64字节(实际受限,如Linux通常用48位,256TB)。
- 虚拟地址空间是连续的,程序用虚拟地址访问数据,感觉自己独占内存,不受其他进程影响。
- 结构:
- 分为代码段、数据段、堆、栈等区域。
- 很多地址可能未分配实际内存(稀疏使用)。
(2) 地址映射
-
虚拟地址通过
页表
映射到物理地址:
- 虚拟地址分为页面号(Page Number)和页内偏移(Page Offset)。
- 页表记录页面号到物理框架号(Frame Number)的映射。
- 如果页面不在主存(RAM),操作系统从外存加载。
-
快表(TLB):硬件缓存,加速虚拟地址到物理地址的转换。
-
多级页表:节省内存,分层管理页表(如二级、四级页表)。
(3) 页面交换(Paging/Swapping)
- 物理内存(RAM)容量有限,无法容纳所有进程的页面。
- 当物理内存不足时,操作系统将不常用的页面(Page)暂时移到外存的交换分区(Swap Space),腾出空间加载新页面。
- 如果程序访问的页面不在主存(页面错误,Page Fault),操作系统从外存加载页面到主存,更新页表。
(4) 按需分页(Demand Paging)
- 程序启动时,不加载全部页面,只加载当前需要的页面(按需分配)。
- 当程序访问未加载的页面时,触发页面错误,操作系统动态加载页面。
- 这种机制减少内存占用,提高启动速度。
缺页率计算:
访问页面成功(在内存)的次数为S,访问页面失败(不在内存)的次数为F,总访问次数为A=S+F,缺页率为 f= F/A
缺页处理时间的计算:

置换算法
(1) 先进先出(FIFO, First-In-First-Out)
- 原理:
- 按照页面进入主存的顺序选择换出页面:最早进入主存的页面最先被换出。
- 操作系统维护一个队列,记录页面进入主存的顺序。
- 实现:
- 维护一个FIFO队列,记录页面进入顺序。
- 新页面加载时,最老的页面(队列头部)被换出,队列尾部加入新页面。
- 优点:
- 实现简单,只需维护一个队列。
- 不需要复杂的状态跟踪。
- 缺点:
- 不考虑页面的使用频率,可能换出经常使用的页面。
- 可能导致Belady异常:增加框架数反而可能增加页面错误(因为不考虑页面访问模式)。
- 适用场景:简单系统,页面访问模式不规律时。
(2) 最近最少使用(LRU, Least Recently Used)
- 原理:
- 选择最近最少使用的页面换出,假设最近未使用的页面未来也不太可能被使用(基于局部性原理)。
- 操作系统跟踪每个页面的最近访问时间。
- 实现:
- 维护一个页面访问的栈或时间戳,最近访问的页面放在栈顶或更新时间戳。
- 换出时选择栈底或最旧时间戳的页面。
- 例子:
- 主存3个框架,页面访问序列:1, 2, 3, 4, 1, 5。
- 加载过程:
- 加载1:框架=[1]
- 加载2:框架=[1, 2]
- 加载3:框架=[1, 2, 3]
- 加载4:框架满,移除3(最近最少使用),框架=[1, 2, 4]
- 访问1:框架=[1, 2, 4](1已存在,更新访问时间)
- 加载5:框架满,移除2(最近最少使用),框架=[1, 4, 5]
- 页面错误:4次(加载1、2、3、4、5时)。
- 优点:
- 利用程序的局部性原理(时间局部性),减少页面错误。
- 性能接近最优算法(OPT),适合大多数实际场景。
- 缺点:
- 实现复杂,需要跟踪每次页面访问的时间或顺序。
- 维护栈或时间戳增加开销(硬件支持如计数器可缓解)。
- 适用场景:现代操作系统(如Linux、Windows)常用,适合有局部性访问模式的程序。
(3) 最优置换算法(OPT, Optimal Page Replacement)
- 原理:
- 选择未来最长时间不会被使用的页面换出,理论上能最小化页面错误。
- 需要预知未来的页面访问序列(实际不可行,仅用于理论分析)。
- 实现:
- 假设知道完整的页面访问序列,换出下次访问最远的页面。
- 例子:
- 主存3个框架,页面访问序列:1, 2, 3, 4, 1, 5。
- 加载过程:
- 加载1:框架=[1]
- 加载2:框架=[1, 2]
- 加载3:框架=[1, 2, 3]
- 加载4:框架满,移除3(未来最晚使用,序列末尾无3),框架=[1, 2, 4]
- 访问1:框架=[1, 2, 4](1已存在)
- 加载5:框架满,移除2(未来最晚使用),框架=[1, 4, 5]
- 页面错误:4次(理论最优)。
- 优点:
- 理论上页面错误最少,是性能基准。
- 缺点:
- 无法实现,因为需要预测未来页面访问序列。
- 仅用于理论分析或模拟,比较其他算法的性能。
- 适用场景:学术研究或测试其他算法的效率。
(4) 时钟算法(Clock Algorithm,或Second-Chance Algorithm)
- 原理:
- 是LRU的简化版本,使用一个循环队列和“引用位”(Reference Bit)记录页面是否被访问。
- 页面按循环顺序排列,换出时检查引用位:
- 如果引用位为1(最近访问过),置0并跳到下一个页面。
- 如果引用位为0(未被访问),换出该页面。
- 通俗比喻:
- 像书桌上有个圆形转盘,书放一圈。每本书有张“最近翻过”标签(引用位)。要拿走一本书时,转盘转一圈,遇到标签为“翻过”的书,撕掉标签给个“第二次机会”,继续转;遇到没标签的书就拿走。
- 实现:
- 维护一个循环队列,页面有引用位(硬件支持)。
- 指针循环检查页面,换出引用位为0的页面。
- 例子:
- 主存3个框架,页面访问序列:1, 2, 3, 4, 1, 5。
- 加载过程(假设初始引用位为0,访问后置1):
- 加载1:框架=[1],引用位=[1]
- 加载2:框架=[1, 2],引用位=[1, 1]
- 加载3:框架=[1, 2, 3],引用位=[1, 1, 1]
- 加载4:框架满,指针检查:
- 1的引用位=1,置0,跳过。
- 2的引用位=1,置0,跳过。
- 3的引用位=1,置0,跳过。
- 再次循环,1的引用位=0,移除1,加载4:框架=[4, 2, 3],引用位=[1, 0, 0]
- 访问1:移除2(引用位=0),加载1:框架=[4, 1, 3],引用位=[1, 1, 0]
- 加载5:移除3(引用位=0),加载5:框架=[4, 1, 5],引用位=[1, 1, 1]
- 页面错误:5次。
- 优点:
- 比LRU简单,硬件支持引用位,减少跟踪开销。
- 利用局部性原理,性能接近LRU。
- 缺点:
- 可能多次扫描队列,效率低于LRU。
- 引用位过于简单,可能不够精准。
- 适用场景:Linux等系统常用,作为LRU的近似实现。
(5) 最近最常使用(LFU, Least Frequently Used)
- 原理:
- 选择使用频率最低的页面换出,假设使用次数少的页面未来也不太需要。
- 操作系统维护每个页面的访问计数。
- 实现:
- 每个页面有计数器,访问一次加1。
- 换出时选择计数最低的页面(若计数相同,可能结合FIFO或LRU)。
- 例子:
- 主存3个框架,页面访问序列:1, 2, 3, 4, 1, 5。
- 加载过程(计数初始为0):
- 加载1:框架=[1],计数=[1]
- 加载2:框架=[1, 2],计数=[1, 1]
- 加载3:框架=[1, 2, 3],计数=[1, 1, 1]
- 加载4:框架满,移除3(计数最低=1),框架=[1, 2, 4],计数=[1, 1, 1]
- 访问1:框架=[1, 2, 4],计数=[2, 1, 1]
- 加载5:移除2(计数最低=1),框架=[1, 4, 5],计数=[2, 1, 1]
- 页面错误:4次。
- 优点:
- 适合某些特定访问模式(如某些页面长期高频使用)。
- 缺点:
- 实现复杂,需维护计数器。
- 新加载的页面计数低,可能被快速换出,即使未来会频繁使用。
- 计数可能长期累积,难以反映近期访问趋势。
- 适用场景:缓存系统或特定高频访问场景。
3. 算法对比总结
| 算法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| FIFO | 最早进入的页面先换出 | 简单,易实现 | 不考虑使用频率,可能换出重要页面 | 简单系统,访问模式不规律 |
| LRU | 最近最少使用的页面换出 | 利用局部性,性能接近最优 | 实现复杂,需跟踪访问历史 | 通用操作系统,局部性强场景 |
| OPT | 最晚使用的页面换出 | 理论最优,页面错误最少 | 需预知未来,无法实现 | 理论分析,算法性能比较 |
| Clock | 循环检查引用位,给第二次机会 | 简单,接近LRU,硬件支持 | 扫描效率较低,精度有限 | Linux等实际系统,LRU近似 |
| LFU | 使用频率最低的页面换出 | 适合高频访问模式 | 实现复杂,计数不适应变化 | 缓存系统,特定访问模式 |
抖动
一个页面的进程块经常被换进换出
5. 如何解决抖动?
- 增加物理内存:
- 加装RAM,增加可用框架,减少页面换入换出。
- 比喻:把书桌换成大桌子,能放更多书,少搬来搬去。
- 降低多道程序度:
- 减少同时运行的进程数,确保每个进程有足够的内存框架。
- 操作系统可暂停某些进程,优先保证活跃进程的页面在内存中。
- 优化页面置换算法:
- 使用LRU或Clock算法,优先保留常用页面,减少不必要的页面错误。
- 工作集模型:
- 操作系统监控每个进程的“工作集”(最近常用的页面集合),确保分配足够的框架容纳工作集。
- 例如,保证进程的常用页面留在内存,减少换出。
- 程序优化:
- 程序员优化代码,增强局部性(如集中访问数据),减少页面错误。
- 调整交换分区:
- 确保外存(如SSD)速度快,减少页面错误时的I/O延迟。
文件管理
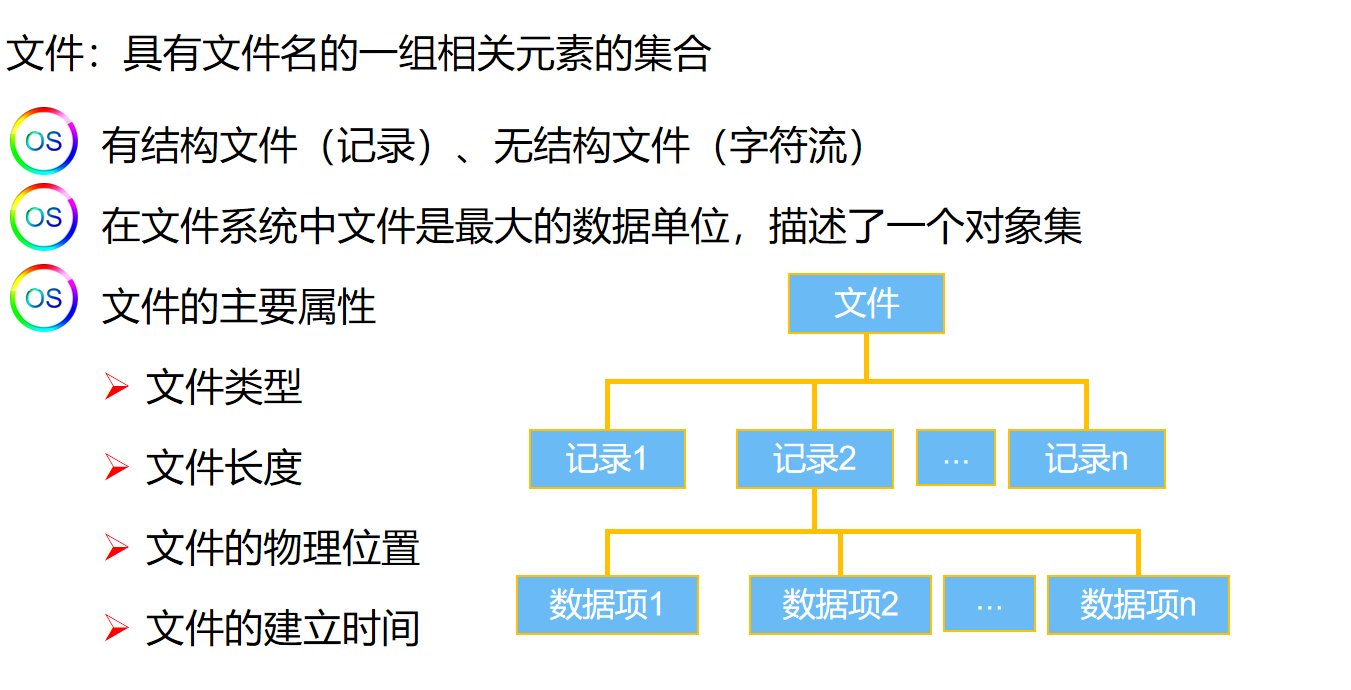
可分为有结构文件(记录式文件)和无结构文件(流式文件,指源程序,可执行文件,库函数等)
有结构文件按文件的记录方式分类
- 顺序文件
- 索引文件
- 索引顺序文件
| 特性 | 顺序文件 | 索引文件 | 索引顺序文件 |
|---|---|---|---|
| 存储方式 | 记录按顺序排列,无索引 | 记录随机存,有索引表 | 记录按顺序存,有分块索引 |
| 访问方式 | 只能顺序访问 | 随机访问(通过索引) | 顺序+随机访问(索引+小范围顺序) |
| 查找效率 | 慢(全文件扫描) | 快(直接定位) | 中等(索引定位+局部扫描) |
| 空间占用 | 小(无索引) | 大(索引表占空间) | 中等(索引比索引文件少) |
| 插入/删除 | 简单(追加)或复杂(需重排) | 复杂(需更新索引) | 较复杂(需维护顺序和索引) |
| 适用场景 | 批量处理、日志记录 | 快速查询、数据库 | 批量+随机查询、银行系统 |
目录
操作系统中的文件管理靠目录来实现以下功能:
- 组织文件:把文件分门别类,比如把照片放“图片”文件夹,工作文档放“工作”文件夹。
- 快速查找:通过目录路径(像C:\Users\YourName\Documents),可以快速找到文件。
- 权限管理:目录可以设置访问权限,比如“只读”或“仅管理员可改”。
- 结构化存储:支持层级结构,方便管理大量文件。
在操作系统中,目录有几种常见类型:
- 根目录(Root Directory)
- 整个文件系统的起点,所有文件和目录都从这里开始。
- 例子:Windows里是C:\,Linux里是/。
- 比喻:像树的根,所有的枝干(子目录)都从这长出来。
- 子目录(Subdirectory)
- 根目录下的目录,可以嵌套多层。
- 例子:C:\Users\YourName\Documents里的Documents是子目录。
- 比喻:像书架上的小抽屉,层层分类。
- 当前目录(Working Directory)
- 你当前操作的目录,比如在命令行里运行命令时,系统默认从当前目录找文件。
- 例子:Linux里用pwd命令查看当前目录。
- 比喻:像你现在站的房间,找东西默认先从这找。
- 父目录(Parent Directory)
- 当前目录的上级目录。
- 例子:在C:\Users\YourName\Documents中,YourName是Documents的父目录。
- 比喻:像抽屉外面的更大抽屉。
软链接实现文件共享
假设你把文件 A(目标文件)链接到文件 B(软链接),那么:
- B 是一个软链接,指向 A。
- 当你访问 B 时,系统会自动给你 A 的内容。
- A 是实际存储数据的文件,B 只是一个“快捷方式”。
软链接的优点
- 省空间:只存路径,占用极少空间。
- 灵活:可跨分区/磁盘,链接文件或目录。
- 便于共享:多人访问同一文件,更新同步。
- 支持目录:可共享整个文件夹。
- 易操作:创建/删除简单,不影响原文件。
软链接的缺点
- 易失效:原文件删/移,链接变“死链接”。
- 权限复杂:需匹配原文件权限,配置易错。
- 网络兼容差:某些协议(如Samba)支持不好。
- 安全风险:可能暴露敏感文件。
- 微小开销:解析链接略耗时。
总结:软链接省空间、灵活,适合共享和管理,但要注意失效、权限和安全问题。
设备管理
输入输出系统
1. I/O系统的功能
I/O系统的核心任务是协调CPU、内存与外部设备的数据交换,确保高效、可靠的通信。功能包括:
- 设备管理:识别和控制各种设备(如硬盘、打印机、鼠标)。
- 数据传输:在设备与内存间传递数据(如读取文件、发送网络数据)。
- 中断处理:响应设备的中断请求(如键盘按键、磁盘读写完成)。
- 缓冲管理:通过缓冲区平滑设备与CPU的速度差异(如缓存磁盘数据)。
- 错误处理:检测和处理设备错误(如磁盘读写失败)。
- 设备独立性:为应用程序提供统一接口,屏蔽设备细节(如用文件接口读写磁盘)。
通俗比喻:I/O系统像餐厅的服务员,负责把顾客(程序)的点菜需求(数据请求)传递给厨房(设备),并把做好的菜(数据)端回,保证沟通顺畅。
2. I/O系统的模型
I/O系统的操作模式决定了设备与系统交互的方式,常见模型包括:
- 轮询(Polling):
- CPU不断检查设备状态,确认是否准备好(如键盘是否有输入)。
- 比喻:服务员不停问厨房“菜好了没”,效率低,浪费CPU时间。
- 特点:简单,但CPU占用高,适合低速设备。
- 中断驱动(Interrupt-Driven):
- 设备完成任务后通过中断通知CPU,CPU暂停当前任务处理I/O。
- 比喻:厨房做好菜主动喊服务员,服务员只在需要时行动。
- 特点:效率高,CPU可做其他工作,主流模式。
- 直接内存访问(DMA):
- 专用DMA控制器直接在设备与内存间传输数据,CPU只发起和结束操作。
- 比喻:厨房直接把菜送到顾客桌上,服务员只需开头和结尾忙一下。
- 特点:适合大批量数据(如磁盘、网络),减少CPU负担。
3. I/O系统的接口
I/O接口是操作系统与设备交互的桥梁,提供标准化方式访问设备。常见接口包括:
- 字符设备接口:
- 用于无固定结构的数据流设备(如键盘、鼠标、串口)。
- 特点:按字符流读写,无缓冲或小缓冲,顺序访问。
- 例子:Linux的/dev/tty(终端设备)。
- 块设备接口:
- 用于固定大小数据块的设备(如硬盘、SSD)。
- 特点:支持随机读写,通常有缓冲区,数据按块(如4KB)传输。
- 例子:Linux的/dev/sda(磁盘分区)。
- 网络设备接口:
- 用于网络设备(如网卡),处理数据包传输。
- 特点:支持数据包协议(如TCP/IP),异步操作。
- 例子:Linux的socket接口。
- 文件系统接口:
- 提供高级抽象,程序通过文件操作(如read、write)访问设备。
- 特点:屏蔽设备细节,统一访问方式。
- 例子:用fopen读写文件,实际可能是磁盘或网络设备。
设备控制器
- 定义:设备控制器(Device Controller)是连接I/O设备与计算机主板(CPU和内存)的硬件中介,负责管理设备操作、数据传输和通信。
- 功能:
- 设备控制:发送命令给设备(如“读取磁盘块”)。
- 数据转换:将设备数据格式转为CPU可识别的格式,或反之(如模拟信号转数字信号)。
- 缓冲管理:通过内置缓冲区暂存数据,平衡设备与CPU速度差异。
- 中断处理:设备完成任务后,通过中断通知CPU(如“数据已读取”)。
- 状态管理:跟踪设备状态(如忙碌、空闲、错误)。
- 组成:
- 寄存器:存储命令、状态、数据(如数据寄存器、控制寄存器)。
- 接口电路:连接设备和主板总线。
- 逻辑电路:处理设备特定的协议和操作。
- 通俗比喻:设备控制器像餐厅的服务员,接收顾客(I/O设备)的点菜需求,告诉厨房(CPU/内存)做什么菜,并把菜端回顾客,处理沟通和协调。
三种控制方式
| 控制方式 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 轮询 | CPU主动查设备状态 | 简单,易实现 | CPU占用高,效率低 | 低速设备,简单系统 |
| 中断 | 设备通知CPU处理 | 高效,CPU可多任务 | 中断处理有开销 | 通用设备,现代系统 |
| DMA | 控制器直接传输数据 | 高效,CPU负担小 | 硬件复杂,成本高 | 高速设备,大数据传输 |
1. 什么是中断?
- 定义:中断是I/O设备或其他硬件(如定时器、键盘、磁盘)向CPU发送的信号,通知CPU有事件需要处理(如数据准备好、按键输入)。它打断CPU当前任务,让CPU优先响应。
- 类型:
- 硬件中断:由I/O设备触发(如磁盘完成读写、键盘按下)。
- 软件中断:由程序触发(如系统调用、异常,如除零错误)。
- 定时器中断:由时钟触发,用于任务调度。
- 特点:
- 异步:中断随时发生,CPU无法预测。
- 高效:无需CPU轮询设备,节省计算资源。
- 优先级:不同中断有优先级,重要中断先处理。
2. 什么是中断处理程序?
- 定义:中断处理程序(Interrupt Handler,或中断服务例程ISR)是操作系统中专门为处理特定中断而设计的程序代码,负责响应中断并完成相应任务。
- 功能:
- 保存现场:保存CPU当前状态(如寄存器),以便中断后恢复。
- 处理中断:执行设备要求的任务(如读取键盘输入、传输磁盘数据)。
- 恢复现场:恢复CPU状态,继续执行被打断的程序。
- 实现:
- 操作系统维护一个中断向量表(Interrupt Vector Table),存储每种中断对应的处理程序地址。
- 中断发生时,CPU根据中断号查找向量表,跳转到对应中断处理程序。
3. 中断和中断处理程序的工作流程
- 中断发生:
- 设备(如键盘)完成任务,发送中断信号给CPU。
- 例如,按下键“A”,键盘控制器发出中断。
- CPU响应:
- CPU暂停当前程序,保存上下文(寄存器状态)。
- 根据中断号查找中断向量表,跳转到对应的中断处理程序。
- 执行中断处理程序:
- 处理程序读取设备数据(如键值“A”),存到内存或通知程序。
- 更新设备状态(如清除中断标志)。
- 恢复执行:
- CPU恢复保存的上下文,继续运行原程序。
例子:
- 你按键盘“A”,键盘控制器发出中断。
- CPU暂停程序,调用键盘中断处理程序。
- 处理程序读取“A”并存到内存,通知操作系统。
- CPU恢复程序,程序继续处理输入。
1. 什么是用户层的 I/O 软件?
- 定义:用户层的 I/O 软件是运行在用户态的库或程序,封装了底层的 I/O 操作(如读写文件、网络通信),为应用程序提供简单、标准化的接口,开发者无需直接处理系统调用或设备细节。
2. 主要功能
- 简化 I/O 操作:
- 提供高级接口(如printf、fread),屏蔽底层系统调用的复杂性。
- 数据格式化:
- 处理数据的输入输出格式(如格式化字符串、文件解析)。
- 例如,printf将数字转为字符串显示。
- 缓冲管理:
- 在用户态提供缓冲区,减少系统调用次数,提高效率。
- 例如,fwrite先写到用户缓冲区,攒够数据再调用write。
- 错误处理:
- 捕获并处理 I/O 错误,向程序返回易懂的错误信息。
- 跨平台支持:
- 提供统一接口,屏蔽不同操作系统的差异(如Windows和Linux的I/O调用)。
3. 工作原理
-
分层交互:
- 应用程序:调用用户层 I/O 软件的函数(如fopen)。
- 用户层 I/O 软件:将高级请求转为系统调用(如open),管理缓冲和格式。
- 操作系统内核:通过系统调用访问与设备无关的 I/O 软件、驱动程序和设备。
-
流程示例:
-
程序调用
printf(“Hello”):
- 用户层标准 I/O 库(libc)将字符串格式化,存入缓冲区。
- 缓冲区满时,调用系统调用write输出到终端。
- 内核通过终端驱动程序将数据发送到显示器。
-
-
关键点:
- 用户层 I/O 软件不直接操作硬件,仅通过系统调用与内核交互。
- 运行在用户态,安全但性能略低于内核态。
1. 什么是假脱机系统?
- 定义:假脱机系统是一种I/O管理技术,通过在内存或磁盘上设置缓冲区(Spool),将慢速设备的I/O操作转为批量处理,让CPU和快速设备无需等待慢速设备,直接释放资源,提高效率。
- 通俗比喻:
- 像你在餐厅点餐(程序请求打印),不用等厨师慢慢做菜(打印机打印),服务员把你的订单记在笔记本(缓冲区)上,厨房稍后批量处理,你可以先去做别的事(CPU继续其他任务)。
2. 假脱机系统的原理
- 核心思想:
- 慢速设备(如打印机)处理速度远低于CPU和内存,程序直接与设备交互会导致CPU等待,浪费资源。
- 假脱机系统用缓冲区(通常在磁盘或内存)暂存I/O数据,程序快速将数据写入缓冲区后继续运行,设备稍后从缓冲区读取数据。
- 工作流程:
- 程序请求I/O:如打印文件,程序将数据写入缓冲区(Spool)。
- 缓冲区管理:假脱机系统在内存或磁盘暂存数据,组织成队列。
- 设备处理:设备(如打印机)从缓冲区读取数据,逐步完成任务。
- CPU解放:程序无需等待设备,直接继续执行其他任务。
缓冲区管理
通俗介绍缓冲区管理
缓冲区管理是操作系统中用于优化I/O操作的一项技术,通过在内存中设置缓冲区(Buffer)暂存数据,平衡CPU、内存与I/O设备(如磁盘、网卡)之间的速度差异,提高系统效率。以下用简洁、通俗的语言介绍缓冲区管理的定义、原理、功能和应用。
1. 什么是缓冲区管理?
- 定义:缓冲区管理是指操作系统利用内存中的一块区域(缓冲区)暂存I/O数据,协调快速的CPU/内存与慢速的I/O设备(如硬盘、打印机)之间的数据传输,减少等待时间和直接访问设备的次数。
- 通俗比喻:
- 像你在超市买东西(I/O操作),不直接把每件商品拿回家(设备处理),而是先放进购物车(缓冲区),攒够一堆再一次性结账(批量传输),省时省力。
2. 缓冲区管理的原理
- 核心问题:
- CPU和内存速度快(纳秒级),I/O设备慢(毫秒级,如磁盘读写)。
- 直接操作设备会导致CPU频繁等待,效率低。
- 解决方案:
- 在内存中开辟缓冲区,暂存待写入设备或从设备读取的数据。
- 程序快速与缓冲区交互,设备异步处理缓冲区数据,CPU无需等待。
- 工作流程:
- 写操作:程序将数据写入缓冲区,缓冲区满或触发条件时,数据批量传给设备。
- 读操作:设备数据先存入缓冲区,程序从缓冲区快速读取。
- 管理:操作系统维护缓冲区,决定何时清空或填充。
3. 主要功能
- 平滑速度差异:
- 缓冲区作为“中转站”,让快速CPU和慢速设备异步工作。
- 减少设备访问:
- 合并多次小数据操作,批量传输,降低设备操作频率。
- 例如,多次写文件先存缓冲区,一次性写入磁盘。
- 优化I/O性能:
- 提高数据吞吐量,减少CPU等待时间。
- 数据一致性:
- 确保缓冲区数据与设备数据同步(如强制刷新缓冲区)。
- 支持多种设备:
- 适用于磁盘、网络、打印机等,提供统一管理。
4. 常见缓冲区管理技术
- 单缓冲:
- 一个缓冲区,程序和设备轮流使用。
- 比喻:一个购物篮,装满才结账,简单但效率低。
- 双缓冲:
- 两个缓冲区,程序写一个,设备读另一个,交替使用。
- 比喻:两个购物篮,一个装货时另一个结账,流水线操作。
- 循环缓冲:
- 多个缓冲区组成环形队列,程序和设备按顺序填充/读取。
- 比喻:传送带上的多个篮子,连续装货和结账。
- 缓冲池:
- 一组动态分配的缓冲区,按需使用,灵活性高。
- 比喻:超市多个购物车,顾客随意挑,适应不同需求。
5. 优点
- 提高效率:
- 减少CPU等待和设备访问,提升系统吞吐量。
- 节省资源:
- 批量操作降低设备启动开销(如磁盘寻道)。
- 灵活性:
- 支持多种I/O场景(如文件读写、网络传输)。
- 用户体验:
- 程序感觉I/O更快(如写文件立即返回)。
6. 缺点
- 内存占用:
- 缓冲区消耗内存,需合理分配。
- 延迟:
- 数据暂存缓冲区可能引入微小延迟(如需等缓冲区满)。
- 一致性风:
- 断电或崩溃可能导致缓冲区数据丢失,需同步机制(如fsync)。
- 管理复杂性:
- 需维护缓冲区状态、同步和分配策略。
磁盘存储器管理
外存组织方式
连续分配
是什么?
连续分配就像给文件在磁盘上分配一段完整的、不被打断的“地盘”。当你保存一个文件时,操作系统会在磁盘上找一块足够大的连续空闲区域,把整个文件的数据一口气存进去,就像把一整本书直接放在书架上的一段空位里。
怎么工作的?
- 操作系统会记录文件的起始位置(比如“第100块”)和长度(比如“占50块”)。
- 读取文件时,系统直接从起始位置开始,按顺序读完整个连续区域。
- 比如,存一个视频文件,大小需要100个磁盘块,系统就找一块连续的100个空闲块,把视频数据依次写入。
优点
- 读取效率高:因为数据是连续的,读取时像顺着一条直路开车,很快,尤其是顺序读取(比如播放视频)。
- 简单直接:管理简单,只需记录起始位置和长度,系统开销小。
- 适合大文件:像电影、数据库文件这种大块数据,连续存储性能好。
缺点
- 容易产生碎片:文件删除后,磁盘上会留下“坑”(空闲块),像停车场里零散的空位。新文件可能找不到足够大的连续空间,就像大巴车找不到长停车位。
- 扩展困难:如果文件变大(比如追加内容),但旁边的块已经被占用,就得把整个文件搬到别处,费时费力。
- 空间浪费:如果分配的连续空间比文件实际需要的大(比如分配100块只用了90块),多余的空间就浪费了。
链接分配
是什么?
链接分配就像把文件切成小块,分散存放在磁盘的各个空闲块中,每块都带一个“指针”,指向上块和下块,像一串珍珠项链,珍珠(数据块)通过链条(指针)连起来。
怎么工作的?
- 文件被分成多个块,存到磁盘上任意空闲的位置。
- 每个块的末尾记录下一个块的地址,第一个块的地址由文件系统记录(比如在文件分配表中)。
- 读取文件时,系统从第一个块开始,顺着指针一个块一个块地找,直到读完。
- 比如,一个文件分成3块,分别存在磁盘的第10、50、30块,第10块指向第50块,第50块指向第30块。
优点
- 无外部碎片:因为可以利用磁盘上任意空闲块,不需要连续空间,像拼图一样把零散空位都用上。
- 扩展方便:文件变大时,只需找新的空闲块,加到链条末尾,不用搬动整个文件。
- 空间利用率高:不像连续分配需要整块空间,小块分配更灵活。
缺点
- 随机读取慢:如果想读文件中间某块,必须从头顺着指针找过去,像翻书得一页页翻,效率低。
- 指针开销:每个块都要存指针,占一点空间(不过通常很小)。
- 可靠性差:如果某个块的指针坏了(比如磁盘错误),后面的数据就找不到了,像项链断了一截,后面的珍珠全丢。
- 不适合大文件:链条太长,查找和管理会变得麻烦。
索引分配
是什么?
索引分配就像给文件建一个“目录索引”,文件数据分成块,分散存放在磁盘上,但所有块的地址都记录在一个单独的索引块(或索引表)中。想读文件,先查索引表,直接找到需要的块。
怎么工作的?
- 每个文件有一个索引块,里面存着文件所有数据块的地址,像书的目录列出每章的页码。
- 读取文件时,系统先访问索引块,找到目标数据块的地址,再直接读取。
- 比如,一个文件有3个数据块,分别在磁盘的第10、50、30块,索引块里记录“块1:10,块2:50,块3:30”。
- 如果文件很大,索引块可能指向其他索引块,形成多级索引(像目录里的子目录)。
优点
- 随机访问快:通过索引表能直接定位任何块,适合需要跳跃访问的场景(如数据库)。
- 无外部碎片:数据块可以分散存储,利用零散空间。
- 扩展灵活:文件变大时,只需在索引表加新块的地址(除非索引表本身满了)。
- 可靠性较高:即使某个数据块坏了,其他块还能通过索引找到。
缺点
- 索引表占空间:每个文件都需要额外的索引块,小文件可能浪费空间(比如1KB文件也要一个索引块)。
- 管理复杂:索引表需要维护,增加/删除块时要更新表,系统开销稍大。
- 索引表可能变大:大文件需要多级索引,访问时多几步(查索引的索引)。
- 随机写稍慢:更新文件时要同时改索引表,写操作比连续分配慢。
存储空间的管理
文件存储空间的基本分配单位是盘块
1. 空闲表法
是什么?
空闲表法就像给磁盘建一张“空闲空间登记表”。操作系统维护一个表格,记录磁盘上所有空闲的连续区域(称为空闲块段),每个条目包括起始块号和块数量。
怎么工作?
- 磁盘被分成固定大小的块(比如 4KB 一块)。
- 空闲表记录每段连续空闲块的信息,例如:
- 起始块号 100,长度 50(表示第 100 到 149 块空闲)。
- 起始块号 200,长度 30(表示第 200 到 229 块空闲)。
- 分配空间时:系统从表中找一段足够大的空闲区域,分配给文件,更新表(减去已用块)。
- 释放空间时:删除文件后,将释放的块加回表,可能合并相邻的空闲段。
2. 空闲链表法
是什么?
空闲链表法把磁盘上的空闲块像串珍珠一样,用链表串起来。每个空闲块记录下一个空闲块的地址,操作系统维护一个链表,跟踪所有空闲块。
怎么工作?
- 磁盘的每个空闲块存储一个指针,指向下一个空闲块。
- 操作系统记录链表的头(第一个空闲块)。
- 分配空间时:从链表头部取一块或多块,更新链表头(指向下一个空闲块)。
- 释放空间时:将删除文件的块加回链表,可能插到头部或尾部。
- 比如,空闲块是第 10、20、30 块,第 10 块指向第 20 块,第 20 块指向第 30 块。
3. 位图法(Bitmap)
是什么?
位图法用一个二进制位图(bitmap)记录磁盘块的使用情况。每个块对应一个位(bit):0 表示空闲,1 表示已占用。整个位图就像一张磁盘的“使用地图”。
怎么工作?
- 磁盘有 N 个块,位图就有 N 位,存在磁盘或内存中。
- 比如,磁盘有 8 块,位图可能是 00101100(第 3、5、6 块已用,第 1、2、4、7、8 块空闲)。
- 分配空间时:扫描位图,找连续或分散的 0(空闲块),分配后把对应位改成 1。
- 释放空间时:将删除文件的块对应位改回 0。
- 现代文件系统(如 ext4、NTFS)常优化位图,用分组或层级结构提高效率。
4. 成组链接法
是什么?
成组链接法是空闲链表法的改进,把空闲块分成组,每组由一个块(称为超级块或组块)记录一组空闲块的地址,超级块之间再用指针链接,像一个分级管理的链表。
怎么工作?
- 空闲块被分组,比如每 100 个空闲块为一组。
- 每个组的第一个块(超级块)记录本组空闲块的地址(比如第 10、20、30 块)和下一个组的地址。
- 操作系统维护第一个超级块的地址。
- 分配空间时:从第一个超级块取空闲块,用完后跳到下一个超级块。
- 释放空间时:将块加回某组,可能新建超级块。
- 比如,第一个超级块记录块 100-199,指向第二个超级块(记录块 300-399)
| 方法 | 外存组织方式支持 | 典型文件系统 | 特点 |
|---|---|---|---|
| 空闲表法 | 连续分配 | FAT、DVD | 适合连续存储,易碎片 |
| 空闲链表法 | 链接分配、索引分配 | FAT | 灵活,无碎片,查找慢 |
| 位图法 | 连续/链接/索引分配 | NTFS、ext4 | 高效,适合大磁盘 |
| 成组链接法 | 链接/索引分配 | ext2/ext3/ext4 | 高效管理大磁盘 |
提高磁盘I/O速度的途径
1. 硬件升级
- 用SSD:SSD比HDD快10倍,建议NVMe SSD(如三星970 EVO)。
- 更快接口:用NVMe(PCIe 4.0/5.0),速度可达7GB/s。
- 增加缓存:选带DRAM缓存的SSD,提升小文件读写。
- RAID阵列:RAID 0倍增速度,适合高性能需求(需备份)。
- 升级主板/CPU:支持PCIe 4.0的主板和现代CPU(如Ryzen 5000)提升NVMe性能。
2. 软件优化
- 优化文件系统:ext4、NTFS用索引分配,适合快速访问;启用TRIM支持SSD。
- 调整块大小:大文件用大块(如64KB),小文件用小块(如4KB)。
- 启用写缓存:操作系统缓冲写操作,需UPS防断电。
- 减少I/O负载:关闭不必要服务,定期清理临时文件。
- 异步I/O:程序用异步读写,减少等待。
3. 文件系统选择
- ext4:Linux默认,日志+Extent高效,适合SSD。
- NTFS:Windows用,支持大文件和权限。
- 避免FAT32:4GB文件限制,随机访问慢。
4. 操作习惯
- 定期整理碎片:HDD上用工具(如Windows磁盘整理)减少碎片。
- 分区对齐:SSD分区对齐4KB,提升性能。
- 避免满盘:保持20%空闲,防止速度下降。
- 监控I/O:用工具(如iostat、Resource Monitor)排查瓶颈。
多处理机操作系统
什么是紧密耦合多处理机系统?
紧密耦合多处理机系统是指多个 CPU 共享同一组资源(主要是内存和 I/O 设备),通过高速总线或交叉开关紧密连接,像一个大家庭住在一个大房子里,资源共用,互动频繁。
什么是松弛耦合多处理机系统?
松弛耦合多处理机系统是指多个 CPU 各有独立资源(内存、I/O),通过网络或低速互联 loosely 连接,像多个小家庭各有厨房,通过电话或快递联系。每个 CPU 像一个独立节点,协作较松散。
| 特性 | 紧密耦合多处理机系统 | 松弛耦合多处理机系统 |
|---|---|---|
| 内存结构 | 共享内存 | 分布式内存 |
| 通信方式 | 内存读写,延迟低 | 消息传递,延迟高 |
| 互联方式 | 总线/交叉开关 | 网络(如 InfiniBand) |
| 扩展性 | 中等(4-64核) | 高(数百/千核) |
| 同步开销 | 高(需锁/缓存一致性) | 低(独立操作) |
| 可靠性 | 较低(单点故障影响整体) | 较高(故障隔离) |
| 编程难度 | 较低(多线程) | 较高(分布式通信) |
| 典型应用 | 桌面/服务器(如 ext4/Linux) | 超级计算机/云计算(如 HDFS) |