Java多线程从入门到精通
一、基础概念
1.1 进程与线程
进程是指运行中的程序。 比如我们使用浏览器,需要启动这个程序,操作系统会给这个程序分配一定的资源(占用内存资源)。
线程是CPU调度的基本单位,每个线程执行的都是某一个进程的代码的某个片段。
1.2 多线程
多线程是指:单个进程中同时运行多个线程。
多线程的不低是为了提高CPU的利用率。
可以通过避免一些网络IO或者磁盘IO等需要等待的操作,让CPU去调度其他线程。
多线程的局限
- 如果线程数量特别多,CPU在切换线程上下文时,会额外造成很大的消耗。
- 任务的拆分需要依赖业务场景,有一些异构化的任务,很难对任务拆分,还有很多业务并不是多线程处理更好。
- 线程安全问题:虽然多线程带来了一定的性能提升,但是再做一些操作时,多线程如果操作临界资源,可能会发生一些数据不一致的安全问题,甚至涉及到锁操作时,会造成死锁问题。
1.3 串行、并行、并发
串行就是一个一个排队,第一个做完,第二个才能上。
并行就是同时处理。(一起上!!!)
多线程中的并发概念(CPU调度线程的概念)。CPU在极短的时间内,反复切换执行不同的线程,看似好像是并行,但是只是CPU高速的切换。
并行囊括并发。
并行就是多核CPU同时调度多个线程,是真正的多个线程同时执行。
单核CPU无法实现并行效果,单核CPU是并发。
二、线程的创建
2.1 继承Thread类 重写run方法
启动线程是调用start方法,这样会创建一个新的线程,并执行线程的任务。
如果直接调用run方法,这样会让当前线程执行run方法中的业务逻辑。
public class MiTest {public static void main(String[] args) {MyJob t1 = new MyJob();t1.start();for (int i = 0; i < 100; i++) {System.out.println("main:" + i);}}}
class MyJob extends Thread{@Overridepublic void run() {for (int i = 0; i < 100; i++) {System.out.println("MyJob:" + i);}}
}2.2 实现Runnable接口 重写run方法
public class MiTest {public static void main(String[] args) {MyRunnable myRunnable = new MyRunnable();Thread t1 = new Thread(myRunnable);t1.start();for (int i = 0; i < 1000; i++) {System.out.println("main:" + i);}}}class MyRunnable implements Runnable{@Overridepublic void run() {for (int i = 0; i < 1000; i++) {System.out.println("MyRunnable:" + i);}}
}匿名内部类方式:
Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {for (int i = 0; i < 1000; i++) {System.out.println("匿名内部类:" + i);}}
});lambda方式:
Thread t2 = new Thread(() -> {for (int i = 0; i < 100; i++) {System.out.println("lambda:" + i);}
});2.3 实现Callable 重写call方法,配合FutureTask
Callable一般用于有返回结果的非阻塞的执行方法。
public class MiTest {public static void main(String[] args) throws ExecutionException, InterruptedException {//1. 创建MyCallableMyCallable myCallable = new MyCallable();//2. 创建FutureTask,传入CallableFutureTask futureTask = new FutureTask(myCallable);//3. 创建Thread线程Thread t1 = new Thread(futureTask);//4. 启动线程t1.start();//5. 做一些操作//6. 要结果Object count = futureTask.get();System.out.println("总和为:" + count);}
}class MyCallable implements Callable{@Overridepublic Object call() throws Exception {int count = 0;for (int i = 0; i < 100; i++) {count += i;}return count;}
}三、线程的使用
3.1 线程的状态
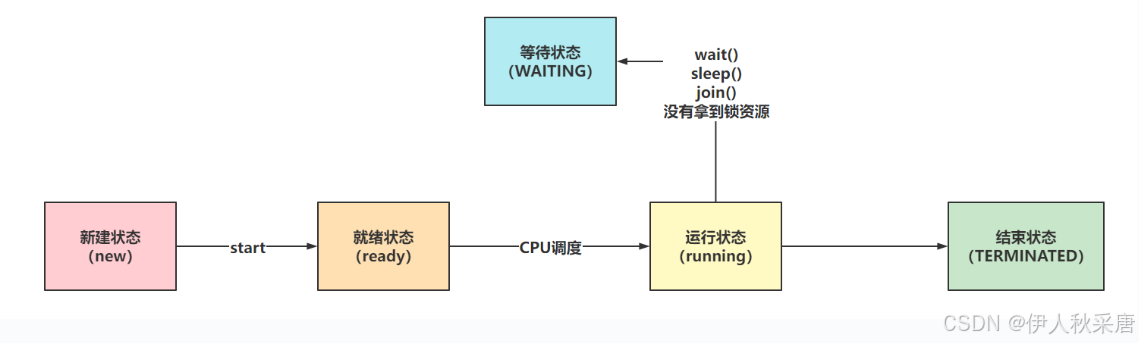
NEW:Thread对象被创建出来了,但是还没有执行start方法。
RUNNABLE:Thread对象调用了start方法,就为RUNNABLE状态(CPU调度/没有调度)
WAITING:可以理解为是阻塞、等待状态,因为处在这三种状态下,CPU不会调度当前线程
WAITING:调用wait方法就会处于WAITING状态,需要被手动唤醒
TERMINATED:run方法执行完毕,线程生命周期到头了
3.2 线程的常用方法
3.2.1 获取当前线程
Thread的静态方法获取当前线程对象:
public static void main(String[] args) throws ExecutionException, InterruptedException {// 获取当前线程的方法Thread main = Thread.currentThread();System.out.println(main);// "Thread[" + getName() + "," + getPriority() + "," + group.getName() + "]";// Thread[main,5,main]
}3.2.2 线程的名字
public static void main(String[] args) throws ExecutionException, InterruptedException {Thread t1 = new Thread(() -> {System.out.println(Thread.currentThread().getName());});t1.setName("模块-功能-计数器");t1.start();
}3.2.3 线程的优先级
低到高:1-10
public static void main(String[] args) throws ExecutionException, InterruptedException {Thread t1 = new Thread(() -> {for (int i = 0; i < 1000; i++) {System.out.println("t1:" + i);}});Thread t2 = new Thread(() -> {for (int i = 0; i < 1000; i++) {System.out.println("t2:" + i);}});t1.setPriority(1);t2.setPriority(10);t2.start();t1.start();
}3.2.4 线程的让步
可以通过Thread的静态方法yield,让当前线程从运行状态转变为就绪状态。
public static void main(String[] args) throws ExecutionException, InterruptedException {Thread t1 = new Thread(() -> {for (int i = 0; i < 100; i++) {if(i == 50){Thread.yield();}System.out.println("t1:" + i);}});Thread t2 = new Thread(() -> {for (int i = 0; i < 100; i++) {System.out.println("t2:" + i);}});t2.start();t1.start();
}3.2.5 线程的休眠
Thread的静态方法,让线程从运行状态转变为等待状态
sleep有两个方法重载:
- 第一个就是native修饰的,让线程转为等待状态的效果
public static native void sleep(long millis) throws InterruptedException;- 第二个是可以传入毫秒和一个纳秒的方法(如果纳秒值大于等于0.5毫秒,就给休眠的毫秒值+1。如果传入的毫秒值是0,纳秒值不为0,就休眠1毫秒)
public static void sleep(long millis, int nanos)throws InterruptedException {if (millis < 0) {throw new IllegalArgumentException("timeout value is negative");}if (nanos < 0 || nanos > 999999) {throw new IllegalArgumentException("nanosecond timeout value out of range");}if (nanos >= 500000 || (nanos != 0 && millis == 0)) {millis++;}sleep(millis);}public static void main(String[] args) throws InterruptedException {System.out.println(System.currentTimeMillis());Thread.sleep(1000);System.out.println(System.currentTimeMillis());
}3.2.6 线程的强占
某一个线程下去调用Thread的非静态方法join方法。
如果在main线程中调用了t1.join(),那么main线程会进入到等待状态,需要等待t1线程全部执行完毕,在恢复到就绪状态等待CPU调度。
如果在main线程中调用了t1.join(2000),那么main线程会进入到等待状态,需要等待t1执行2s后,在恢复到就绪状态等待CPU调度。如果在等待期间,t1已经结束了,那么main线程自动变为就绪状态等待CPU调度。
public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {for (int i = 0; i < 10; i++) {System.out.println("t1:" + i);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();for (int i = 0; i < 10; i++) {System.out.println("main:" + i);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}if (i == 1){try {t1.join(2000);} catch (InterruptedException e) {e.printStackTrace();}}}
}3.2.7 线程的等待和唤醒
获取synchronized锁资源的线程通过wait方法进去到锁的等待池,并且会释放锁资源。
可以让获取synchronized锁资源的线程,通过notify或者notifyAll方法,将等待池中的线程唤醒,添加到锁池中。
notify随机的唤醒等待池中的一个线程到锁池。
notifyAll将等待池中的全部线程都唤醒,并且添加到锁池。
在调用wait方法和notify以及norifyAll方法时,必须在synchronized修饰的代码块或者方法内部才可以,因为要操作基于某个对象的锁的信息维护。
public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {sync();},"t1");Thread t2 = new Thread(() -> {sync();},"t2");t1.start();t2.start();Thread.sleep(12000);synchronized (MiTest.class) {MiTest.class.notifyAll();}
}public static synchronized void sync() {try {for (int i = 0; i < 10; i++) {if(i == 5) {MiTest.class.wait();}Thread.sleep(1000);System.out.println(Thread.currentThread().getName());}} catch (InterruptedException e) {e.printStackTrace();}
}四、锁
4.1锁的分类
1 可重入锁、不可重入锁
Java中提供的synchronized,ReentrantLock,ReentrantReadWriteLock都是可重入锁。
重入:当前线程获取到A锁,在获取之后尝试再次获取A锁是可以直接拿到的。
不可重入:当前线程获取到A锁,在获取之后尝试再次获取A锁,无法获取到的,因为A锁被当前线程占用着,需要等待自己释放锁再获取锁。
2 乐观锁、悲观锁
Java中提供的synchronized,ReentrantLock,ReentrantReadWriteLock都是悲观锁。
Java中提供的CAS操作,就是乐观锁的一种实现。
悲观锁:获取不到锁资源时,会将当前线程挂起(进入BLOCKED、WAITING),线程挂起会涉及到用户态和内核的太的切换,而这种切换是比较消耗资源的。
- 用户态:JVM可以自行执行的指令,不需要借助操作系统执行。
- 内核态:JVM不可以自行执行,需要操作系统才可以执行。
乐观锁:获取不到锁资源,可以再次让CPU调度,重新尝试获取锁资源。
Atomic原子性类中,就是基于CAS乐观锁实现的。
3 公平锁、非公平锁
Java中提供的synchronized只能是非公平锁。
Java中提供的ReentrantLock,ReentrantReadWriteLock可以实现公平锁和非公平锁
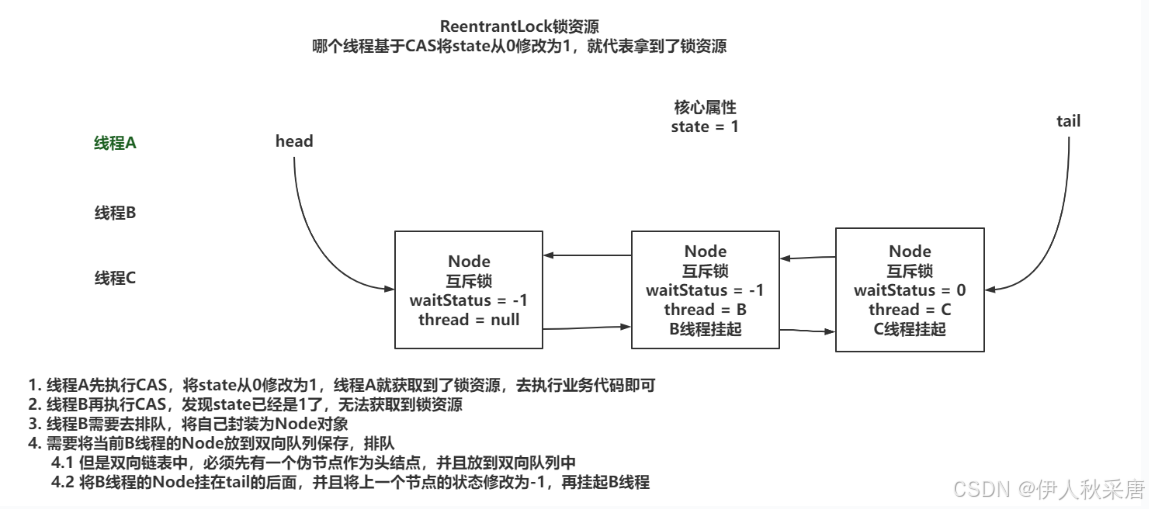
公平锁:线程A获取到了锁资源,线程B没有拿到,线程B去排队,线程C来了,锁被A持有,同时线程B在排队。直接排到B的后面,等待B拿到锁资源或者是B取消后,才可以尝试去竞争锁资源。
非公平锁:线程A获取到了锁资源,线程B没有拿到,线程B去排队,线程C来了,先尝试竞争一波
- 拿到锁资源:开心,插队成功。
- 没有拿到锁资源:依然要排到B的后面,等待B拿到锁资源或者是B取消后,才可以尝试去竞争锁资源。
4 互斥锁、共享锁
Java中提供的synchronized、ReentrantLock是互斥锁。
Java中提供的ReentrantReadWriteLock,有互斥锁也有共享锁。
互斥锁:同一时间点,只会有一个线程持有者当前互斥锁。
共享锁:同一时间点,当前共享锁可以被多个线程同时持有。
4.2synchronized
synchronized的锁是基于对象实现的,使用一般就是同步方法和同步代码块。
synchronized的优化:
锁消除:在synchronized修饰的代码中,如果不存在操作临界资源的情况,会触发锁消除,你即便写了synchronized,他也不会触发。
锁膨胀:如果在一个循环中,频繁的获取和释放做资源,这样带来的消耗很大,锁膨胀就是将锁的范围扩大,避免频繁的竞争和获取锁资源带来不必要的消耗。
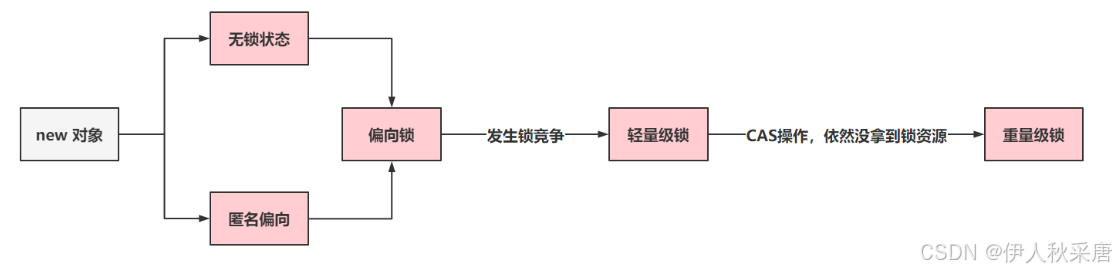
锁升级:ReentrantLock的实现,是先基于乐观锁的CAS尝试获取锁资源,如果拿不到锁资源,才会挂起线程。
- 无锁、匿名偏向:当前对象没有作为锁存在。
- 偏向锁:如果当前锁资源,只有一个线程在频繁的获取和释放,那么这个线程过来,只需要判断,当前指向的线程是否是当前线程 。
- 如果是,直接拿着锁资源走。
- 如果当前线程不是,基于CAS的方式,尝试将偏向锁指向当前线程。如果获取不到,触发锁升级,升级为轻量级锁。(偏向锁状态出现了锁竞争的情况)
- 轻量级锁:会采用自旋锁的方式去频繁的以CAS的形式获取锁资源(采用的是自适应自旋锁)
- 如果成功获取到,拿着锁资源走
- 如果自旋了一定次数,没拿到锁资源,锁升级。
- 重量级锁:就是最传统的synchronized方式,拿不到锁资源,就挂起当前线程。(用户态&内核态)
偏向锁在升级为轻量级锁时,会涉及到偏向锁撤销,需要等到一个安全点(STW),才可以做偏向锁撤销,在明知道有并发情况,就可以选择不开启偏向锁,或者是设置偏向锁延迟开启。
因为JVM在启动时,需要加载大量的.class文件到内存中,这个操作会涉及到synchronized的使用,为了避免出现偏向锁撤销操作,JVM启动初期,有一个延迟4s开启偏向锁的操作
如果正常开启偏向锁了,那么不会出现无锁状态,对象会直接变为匿名偏向。
4.3ReentrantLock
- ReentrantLock是个类,synchronized是关键字,当然都是在JVM层面实现互斥锁的方式
效率区别:
- 如果竞争比较激烈,推荐ReentrantLock去实现,不存在锁升级概念。而synchronized是存在锁升级概念的,如果升级到重量级锁,是不存在锁降级的。
底层实现区别:
- 实现原理是不一样,ReentrantLock基于AQS实现的,synchronized是基于ObjectMonitor
功能向的区别:
- ReentrantLock的功能比synchronized更全面。
- ReentrantLock支持公平锁和非公平锁
- ReentrantLock可以指定等待锁资源的时间。
非公平锁的流程
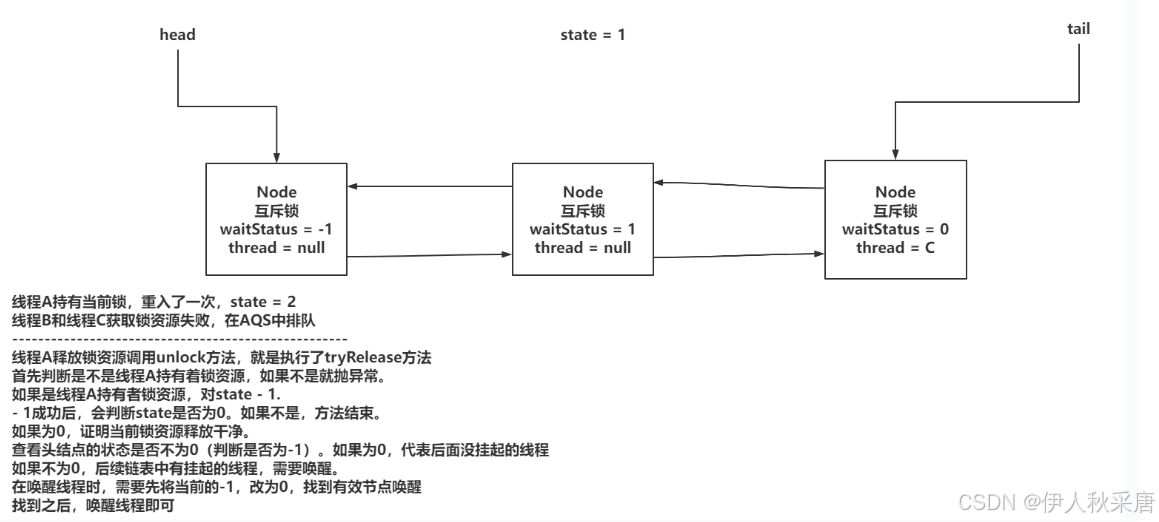
释放锁
五、阻塞队列
生产者 消费者彼此之间不会直接通讯的,而是通过一个容器(队列)进行通讯。
所以生产者生产完数据后扔到容器中,不通用等待消费者来处理。
消费者不需要去找生产者要数据,直接从容器中获取即可。
而这种容器最常用的结构就是队列。
5.1ArrayBlockingQueue
ArrayBlockingQueue在初始化的时候,必须指定当前队列的长度。
因为ArrayBlockingQueue是基于数组实现的队列结构,数组长度不可变,必须提前设置数组长度信息。
public static void main(String[] args) throws ExecutionException, InterruptedException, IOException {// 必须设置队列的长度ArrayBlockingQueue queue = new ArrayBlockingQueue(4);// 生产者扔数据queue.add("1");queue.offer("2");queue.offer("3",2,TimeUnit.SECONDS);queue.put("2");// 消费者取数据System.out.println(queue.remove());System.out.println(queue.poll());System.out.println(queue.poll(2,TimeUnit.SECONDS));System.out.println(queue. Take());
}生产者方法实现原理
add方法实现
add方法本身就是调用了offer方法,如果offer方法返回false,直接抛出异常
public boolean add(E e) {if (offer(e))return true;else// 抛出的异常throw new IllegalStateException("Queue full");
}offer方法实现
public boolean offer(E e) {// 要求存储的数据不允许为null,为null就抛出空指针checkNotNull(e);// 当前阻塞队列的lock锁final ReentrantLock lock = this.lock;// 为了保证线程安全,加锁lock.lock();try {// 如果队列中的元素已经存满了,if (count == items.length)// 返回falsereturn false;else {// 队列没满,执行enqueue将元素添加到队列中enqueue(e);// 返回truereturn true;}} finally {// 操作完释放锁lock.unlock();}
}//==========================================================
private void enqueue(E x) {// 拿到数组的引用final Object[] items = this.items;// 将元素放到指定位置items[putIndex] = x;// 对inputIndex进行++操作,并且判断是否已经等于数组长度,需要归位if (++putIndex == items.length)// 将索引设置为0putIndex = 0;// 元素添加成功,进行++操作。count++;// 将一个Condition中阻塞的线程唤醒。notEmpty.signal();
}offer(time,unit)方法
生产者在添加数据时,如果队列已经满了,阻塞一会。
- 阻塞到消费者消费了消息,然后唤醒当前阻塞线程
- 阻塞到了time时间,再次判断是否可以添加,不能,不添加。
// 如果线程在挂起的时候,如果对当前阻塞线程的中断标记位进行设置,此时会抛出异常直接结束
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {// 非空检验checkNotNull(e);// 将时间单位转换为纳秒long nanos = unit.toNanos(timeout);// 加锁final ReentrantLock lock = this.lock;// 允许线程中断并排除异常的加锁方式lock.lockInterruptibly();try {// 为什么是while(虚假唤醒)// 如果元素个数和数组长度一致,队列慢了while (count == items.length) {// 判断等待的时间是否还充裕if (nanos <= 0)// 不充裕,直接添加失败return false;// 挂起等待,会同时释放锁资源(对标sync的wait方法)// awaitNanos会挂起线程,并且返回剩余的阻塞时间// 恢复执行时,需要重新获取锁资源nanos = notFull.awaitNanos(nanos);}// 说明队列有空间了,enqueue将数据扔到阻塞队列中enqueue(e);return true;} finally {// 释放锁资源lock.unlock();}
}put方法
如果队列是满的, 就一直挂起,直到被唤醒,或者被中断。
public void put(E e) throws InterruptedException {checkNotNull(e);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length)// await方法一直阻塞,直到被唤醒或者中断标记位notFull.await();enqueue(e);} finally {lock.unlock();}
}消费者方法实现原理
remove方法
// remove方法就是调用了poll
public E remove() {E x = poll();// 如果有数据,直接返回if (x != null)return x;// 没数据抛出异常elsethrow new NoSuchElementException();
}poll方法
// 拉取数据
public E poll() {// 加锁操作final ReentrantLock lock = this.lock;lock.lock();try {// 如果没有数据,直接返回null,如果有数据,执行dequeue,取出数据并返回return (count == 0) ? null : dequeue();} finally {lock.unlock();}
}//==========================================================
// 取出数据
private E dequeue() {// 将成员变量引用到局部变量final Object[] items = this.items;// 直接获取指定索引位置的数据E x = (E) items[takeIndex];// 将数组上指定索引位置设置为nullitems[takeIndex] = null;// 设置下次取数据时的索引位置if (++takeIndex == items.length)takeIndex = 0;// 对count进行--操作count--;// 迭代器内容,先跳过if (itrs != null)itrs.elementDequeued();// signal方法,会唤醒当前Condition中排队的一个Node。// signalAll方法,会将Condition中所有的Node,全都唤醒notFull.signal();// 返回数据。return x;
}poll(time, unit)方法
public E poll(long timeout, TimeUnit unit) throws InterruptedException {// 转换时间单位long nanos = unit.toNanos(timeout);// 竞争锁final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {// 如果没有数据while (count == 0) {if (nanos <= 0)// 没数据,也无法阻塞了,返回nullreturn null;// 没数据,挂起消费者线程nanos = notEmpty.awaitNanos(nanos);}// 取数据return dequeue();} finally {lock.unlock();}
}take()方法
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {// 虚假唤醒while (count == 0)notEmpty.await();return dequeue();} finally {lock.unlock();}
}六、线程池
6.1构建线程池
6.1.1newFixedThreadPool
这个线程池的线程数是固定的,在创建时指定。构建方法:
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}构建好当前线程池后,线程个数已经固定好(线程是懒加载,在构建之初,线程并没有构建出来,而是随着人任务的提交才会将线程在线程池中国构建出来)。如果线程没构建,线程会待着任务执行被创建和执行。如果线程都已经构建好了,此时任务会被放到LinkedBlockingQueue无界队列中存放,等待线程从LinkedBlockingQueue中去take出任务,然后执行。
6.1.2newSingleThreadExecutor
单例线程池,线程池中只有一个工作线程在处理任务,业务涉及到顺序消费可以使用:
// 当前这里就是构建单例线程池的方式
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService// 在内部依然是构建了ThreadPoolExecutor,设置的线程个数为1// 当任务投递过来后,第一个任务会被工作线程处理,后续的任务会被扔到阻塞队列中// 投递到阻塞队列中任务的顺序,就是工作线程处理的顺序// 当前这种线程池可以用作顺序处理的一些业务中(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}static class FinalizableDelegatedExecutorService extends DelegatedExecutorService {// 线程池的使用没有区别,跟正常的ThreadPoolExecutor没区别FinalizableDelegatedExecutorService(ExecutorService executor) {super(executor);}// finalize是当前对象被GC干掉之前要执行的方法// 当前FinalizableDelegatedExecutorService的目的是为了在当前线程池被GC回收之前// 可以执行shutdown,shutdown方法是将当前线程池停止,并且干掉工作线程// 但是不能基于这种方式保证线程池一定会执行shutdown// finalize在执行时,是守护线程,这种线程无法保证一定可以执行完毕。// 在使用线程池时,如果线程池是基于一个业务构建的,在使用完毕之后,一定要手动执行shutdown,// 否则会造成JVM中一堆线程protected void finalize() {super.shutdown();}
}6.1.3newCachedThreadPool
构建方式:
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}当第一次提交任务到线程池时,会直接构建一个工作线程。
这个工作线程带执行完人后,60秒没有任务可以执行后,会结束。
如果在等待60秒期间有任务进来,他会再次拿到这个任务去执行。
如果后续提升任务时,没有线程是空闲的,那么就构建工作线程去执行。
最大的一个特点,任务只要提交到当前的newCachedThreadPool中,就必然有工作线程可以处理。
6.1.4newScheduleThreadPool
是一个定时任务的线程,可以以一个周期去执行一个任务,或者延迟多久执行一个任务一次。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {return new ScheduledThreadPoolExecutor(corePoolSize);
}在原来的线程池基础上实现了定时任务的功能,原理是基于DelayQueue实现的延迟执行。周期性执行是任务执行完毕后,再次扔回到阻塞队列。
6.2ThreadPoolExecutor应用
ThreadPoolExecutor提供的七个核心参数:
public ThreadPoolExecutor(int corePoolSize, // 核心工作线程(当前任务执行结束后,不会被销毁)int maximumPoolSize, // 最大工作线程(代表当前线程池中,一共可以有多少个工作线程)long keepAliveTime, // 非核心工作线程在阻塞队列位置等待的时间TimeUnit unit, // 非核心工作线程在阻塞队列位置等待时间的单位BlockingQueue<Runnable> workQueue, // 任务在没有核心工作线程处理时,任务先扔到阻塞队列中ThreadFactory threadFactory, // 构建线程的线程工作,可以设置thread的一些信息RejectedExecutionHandler handler) { // 当线程池无法处理投递过来的任务时,执行当前的拒绝策略// 初始化线程池的操作
}拒绝策略:
AbortPolicy:当前拒绝策略会在无法处理任务时,直接抛出一个异常:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());
}//默认的拒绝策略
private static final RejectedExecutionHandler defaultHandler =new AbortPolicy();
CallerRunsPolicy:当前拒绝策略会在线程池无法处理任务时,将任务交给调用者处理
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}
}DiscardPolicy:当前拒绝策略会在线程池无法处理任务时,直接将任务丢弃掉
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}DiscardOldestPolicy:当前拒绝策略会在线程池无法处理任务时,将队列中最早的任务丢弃掉,将当前任务再次尝试交给线程池处理
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}
}自定义Policy:根据自己的业务,可以将任务扔到数据库,也可以做其他操作
private static class MyRejectedExecution implements RejectedExecutionHandler{@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {System.out.println("根据自己的业务情况,决定编写的代码!");}
}代码构建线程池,并处理有无返回结果的任务:
public static void main(String[] args) throws ExecutionException, InterruptedException {//1. 构建线程池ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2,5,10,TimeUnit.SECONDS,new ArrayBlockingQueue<>(5),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);thread.setName("test-ThreadPoolExecutor");return thread;}},new MyRejectedExecution());//2. 让线程池处理任务,没返回结果threadPool.execute(() -> {System.out.println("没有返回结果的任务");});//3. 让线程池处理有返回结果的任务Future<Object> future = threadPool.submit(new Callable<Object>() {@Overridepublic Object call() throws Exception {System.out.println("我有返回结果!");return "返回结果";}});Object result = future.get();System.out.println(result);//4. 如果是局部变量的线程池,记得用完要shutdownthreadPool.shutdown();
}private static class MyRejectedExecution implements RejectedExecutionHandler{@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {System.out.println("根据自己的业务情况,决定编写的代码!");}
}核心属性:
// 当前是线程池的核心属性
// 当前的ctl其实就是一个int类型的数值,内部是基于AtomicInteger套了一层,进行运算时,是原子性的。
// ctl表示着线程池中的2个核心状态:
// 线程池的状态:ctl的高3位,表示线程池状态
// 工作线程的数量:ctl的低29位,表示工作线程的个数
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));// Integer.SIZE:在获取Integer的bit位个数
// 声明了一个常量:COUNT_BITS = 29
private static final int COUNT_BITS = Integer.SIZE - 3;
00000000 00000000 00000000 00000001
00100000 00000000 00000000 00000000
00011111 11111111 11111111 11111111
// CAPACITY就是当前工作线程能记录的工作线程的最大个数
private static final int CAPACITY = (1 << COUNT_BITS) - 1;// 线程池状态的表示
// 当前五个状态中,只有RUNNING状态代表线程池没问题,可以正常接收任务处理
// 111:代表RUNNING状态,RUNNING可以处理任务,并且处理阻塞队列中的任务。
private static final int RUNNING = -1 << COUNT_BITS;
// 000:代表SHUTDOWN状态,不会接收新任务,正在处理的任务正常进行,阻塞队列的任务也会做完。
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 001:代表STOP状态,不会接收新任务,正在处理任务的线程会被中断,阻塞队列的任务一个不管。
private static final int STOP = 1 << COUNT_BITS;
// 010:代表TIDYING状态,这个状态是否SHUTDOWN或者STOP转换过来的,代表当前线程池马上关闭,就是过渡状态。
private static final int TIDYING = 2 << COUNT_BITS;
// 011:代表TERMINATED状态,这个状态是TIDYING状态转换过来的,转换过来只需要执行一个terminated方法。
private static final int TERMINATED = 3 << COUNT_BITS;// 在使用下面这几个方法时,需要传递ctl进来// 基于&运算的特点,保证只会拿到ctl高三位的值。
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 基于&运算的特点,保证只会拿到ctl低29位的值。
private static int workerCountOf(int c) { return c & CAPACITY; }线程池状态和切换方式:
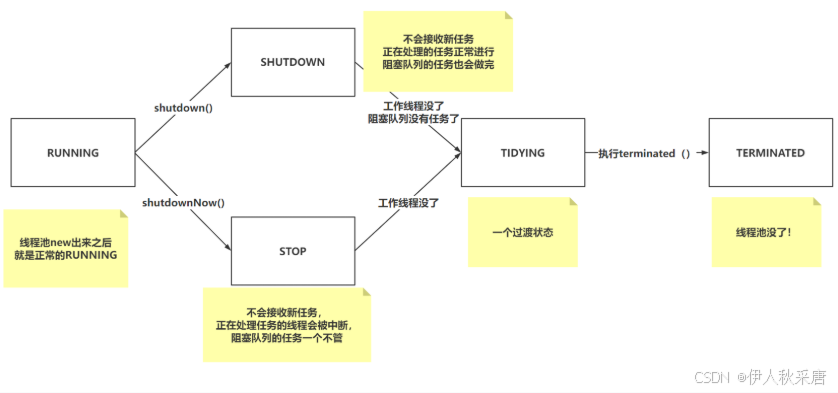
ThreadPoolExecutor的execute方法
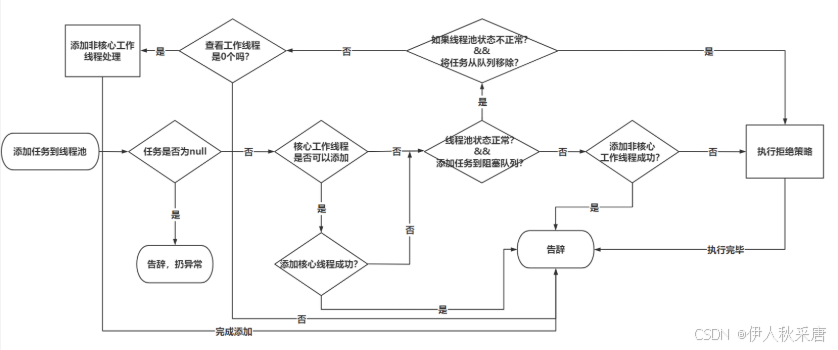
// 提交任务到线程池的核心方法
// command就是提交过来的任务
public void execute(Runnable command) {// 提交的任务不能为nullif (command == null)throw new NullPointerException();// 获取核心属性ctl,用于后面的判断int c = ctl.get();// 如果工作线程个数,小于核心线程数。// 满足要求,添加核心工作线程if (workerCountOf(c) < corePoolSize) {// addWorker(任务,是核心线程吗)// addWorker返回true:代表添加工作线程成功// addWorker返回false:代表添加工作线程失败// addWorker中会基于线程池状态,以及工作线程个数做判断,查看能否添加工作线程if (addWorker(command, true))// 工作线程构建出来了,任务也交给command去处理了。return;// 说明线程池状态或者是工作线程个数发生了变化,导致添加失败,重新获取一次ctlc = ctl.get();}// 添加核心工作线程失败,往这走// 判断线程池状态是否是RUNNING,如果是,正常基于阻塞队列的offer方法,将任务添加到阻塞队列if (isRunning(c) && workQueue.offer(command)) {// 如果任务添加到阻塞队列成功,走if内部// 如果任务在扔到阻塞队列之前,线程池状态突然改变了。// 重新获取ctlint recheck = ctl.get();// 如果线程池的状态不是RUNNING,将任务从阻塞队列移除,if (!isRunning(recheck) && remove(command))// 并且直接拒绝策略reject(command);// 在这,说明阻塞队列有我刚刚放进去的任务// 查看一下工作线程数是不是0个// 如果工作线程为0个,需要添加一个非核心工作线程去处理阻塞队列中的任务// 发生这种情况有两种:// 1. 构建线程池时,核心线程数是0个。// 2. 即便有核心线程,可以设置核心线程也允许超时,设置allowCoreThreadTimeOut为true,代表核心线程也可以超时else if (workerCountOf(recheck) == 0)// 为了避免阻塞队列中的任务饥饿,添加一个非核心工作线程去处理addWorker(null, false);}// 任务添加到阻塞队列失败// 构建一个非核心工作线程// 如果添加非核心工作线程成功,直接完事,告辞else if (!addWorker(command, false))// 添加失败,执行决绝策略reject(command);
}execute方法的流程图:
ThreadPoolExecutor的addWorker方法:
- 一、校验线程池的状态以及工作线程个数
- 二、添加工作线程并且启动工作线程
校验线程池的状态以及工作线程个数
// 添加工作线程之校验源码
private boolean addWorker(Runnable firstTask, boolean core) {// 外层for循环在校验线程池的状态// 内层for循环是在校验工作线程的个数// retry是给外层for循环添加一个标记,是为了方便在内层for循坏跳出外层for循环retry:for (;;) {// 获取ctlint c = ctl.get();// 拿到ctl的高3位的值int rs = runStateOf(c);
//==========================线程池状态判断==================================================// 如果线程池状态是SHUTDOWN,并且此时阻塞队列有任务,工作线程个数为0,添加一个工作线程去处理阻塞队列的任务// 判断线程池的状态是否大于等于SHUTDOWN,如果满足,说明线程池不是RUNNINGif (rs >= SHUTDOWN &&// 如果这三个条件都满足,就代表是要添加非核心工作线程去处理阻塞队列任务// 如果三个条件有一个没满足,返回false,配合!,就代表不需要添加!(rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))// 不需要添加工作线程return false;for (;;) {
//==========================工作线程个数判断================================================== // 基于ctl拿到低29位的值,代表当前工作线程个数 int wc = workerCountOf(c);// 如果工作线程个数大于最大值了,不可以添加了,返回falseif (wc >= CAPACITY ||// 基于core来判断添加的是否是核心工作线程// 如果是核心:基于corePoolSize去判断// 如果是非核心:基于maximumPoolSize去判断wc >= (core ? corePoolSize : maximumPoolSize))// 代表不能添加,工作线程个数不满足要求return false;// 针对ctl进行 + 1,采用CAS的方式if (compareAndIncrementWorkerCount(c))// CAS成功后,直接退出外层循环,代表可以执行添加工作线程操作了。break retry;// 重新获取一次ctl的值c = ctl.get(); // 判断重新获取到的ctl中,表示的线程池状态跟之前的是否有区别// 如果状态不一样,说明有变化,重新的去判断线程池状态if (runStateOf(c) != rs)// 跳出一次外层for循环continue retry;}}// 省略添加工作线程以及启动的过程
}添加工作线程并且启动工作线程
private boolean addWorker(Runnable firstTask, boolean core) {// 省略校验部分的代码// 添加工作线程以及启动工作线程~~~// 声明了三个变量// 工作线程启动了没,默认falseboolean workerStarted = false;// 工作线程添加了没,默认falseboolean workerAdded = false;// 工作线程,默认为nullWorker w = null;try {// 构建工作线程,并且将任务传递进去w = new Worker(firstTask);// 获取了Worker中的Thread对象final Thread t = w.thread;// 判断Thread是否不为null,在new Worker时,内部会通过给予的ThreadFactory去构建Thread交给Worker// 一般如果为null,代表ThreadFactory有问题。if (t != null) {// 加锁,保证使用workers成员变量以及对largestPoolSize赋值时,保证线程安全final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 再次获取线程池状态。int rs = runStateOf(ctl.get());// 再次判断// 如果满足 rs < SHUTDOWN 说明线程池是RUNNING,状态正常,执行if代码块// 如果线程池状态为SHUTDOWN,并且firstTask为null,添加非核心工作处理阻塞队列任务if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {// 到这,可以添加工作线程。// 校验ThreadFactory构建线程后,不能自己启动线程,如果启动了,抛出异常if (t.isAlive()) throw new IllegalThreadStateException();// private final HashSet<Worker> workers = new HashSet<Worker>();// 将new好的Worker添加到HashSet中。workers.add(w);// 获取了HashSet的size,拿到工作线程个数int s = workers.size();// largestPoolSize在记录最大线程个数的记录// 如果当前工作线程个数,大于最大线程个数的记录,就赋值if (s > largestPoolSize)largestPoolSize = s;// 添加工作线程成功workerAdded = true;}} finally {mainLock.unlock();}// 如果工作线程添加成功,if (workerAdded) {// 直接启动Worker中的线程t.start();// 启动工作线程成功workerStarted = true;}}} finally {// 做补偿的操作,如果工作线程启动失败,将这个添加失败的工作线程处理掉if (!workerStarted)addWorkerFailed(w);}// 返回工作线程是否启动成功return workerStarted;
}
// 工作线程启动失败,需要不的步长操作
private void addWorkerFailed(Worker w) {// 因为操作了workers,需要加锁final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 如果w不为null,之前Worker已经new出来了。if (w != null)// 从HashSet中移除workers.remove(w);// 同时对ctl进行 - 1,代表去掉了一个工作线程个数decrementWorkerCount();// 因为工作线程启动失败,判断一下状态的问题,是不是可以走TIDYING状态最终到TERMINATED状态了。tryTerminate();} finally {// 释放锁mainLock.unlock();}
}