【第四十八周】HippoRAG 2 复现与分析(二):索引阶段代码分析
目录
- 摘要
- Abstract
- 代码结构
- 主函数
- 索引方法
- 嵌入向量生成
- 存储段落嵌入
- 开放信息提取
- 总结
摘要
本周工作主要围绕HippoRAG项目的代码结构和核心功能展开。该项目构建了一个清晰的模块化架构,包含嵌入模型、评估指标、信息抽取、大语言模型推理和提示管理等核心组件。重点分析了主函数逻辑和索引构建流程,其中HippoRAG类作为系统核心,通过index方法实现文档处理全流程:包括段落嵌入存储、开放信息抽取(使用多线程并行处理NER和三元组抽取)、实体/事实编码以及知识图谱构建。项目采用NV-Embed-v2等先进模型进行向量编码,并通过EmbeddingStore类高效管理嵌入向量,形成了一个完整的检索-问答系统框架。代码结构设计合理,各模块职责明确,便于学习和扩展。
Abstract
This week’s work primarily focused on the code structure and core functionalities of the HippoRAG project. The project features a well-organized modular architecture, encompassing key components such as embedding models, evaluation metrics, information extraction, large language model inference, and prompt management. A detailed analysis was conducted on the main function logic and the index-building process. The HippoRAG class serves as the system’s core, with its index method handling the entire document processing pipeline: storing passage embeddings, performing OpenIE (leveraging multi-threaded parallel processing for NER and triple extraction), encoding entities/facts, and constructing a knowledge graph. The project employs advanced models like NV-Embed-v2 for vector encoding and efficiently manages embeddings via the EmbeddingStore class, forming a comprehensive retrieval-question answering framework. The codebase is thoughtfully designed, with clearly defined responsibilities for each module, making it both easy to learn and extend.
代码结构
📦 .
│-- 📂 src/hipporag
│ ├── 📂 embedding_model # 所有嵌入模型的实现
│ │ ├── __init__.py # 获取特定嵌入模型类的函数
│ │ ├── base.py # 基类 `BaseEmbeddingModel` 和配置类 `EmbeddingConfig`
│ │ ├── NVEmbedV2.py # NV-Embed-v2 模型的实现
│ │ ├── ...
│ ├── 📂 evaluation # 所有评估指标的实现
│ │ ├── __init__.py
│ │ ├── base.py # 基类 `BaseMetric`
│ │ ├── qa_eval.py # 问答任务的评估指标
│ │ ├── retrieval_eval.py # 检索任务的评估指标
│ ├── 📂 information_extraction # 所有信息抽取模型的实现
│ │ ├── __init__.py
│ │ ├── openie_openai_gpt.py # 使用 OpenAI GPT 的 OpenIE 模型
│ │ ├── openie_vllm_offline.py # 使用通过 vLLM 部署的离线大语言模型进行 OpenIE 的模型
│ ├── 📂 llm # 大语言模型推理相关类
│ │ ├── __init__.py # 获取函数
│ │ ├── base.py # LLM 推理的配置类和基类
│ │ ├── openai_gpt.py # 使用 OpenAI GPT 进行推理的类
│ │ ├── vllm_llama.py # 使用本地 vLLM 服务器进行推理的类
│ │ ├── vllm_offline.py # 直接使用 vLLM API 进行推理的类
│ ├── 📂 prompts # 提示模板及提示模板管理器类
│ │ ├── 📂 dspy_prompts # 用于过滤的提示
│ │ │ ├── ...
│ │ ├── 📂 templates # 模板管理器加载的所有提示模板
│ │ │ ├── README.md # 提示模板管理器及其文件用法说明文档
│ │ │ ├── __init__.py
│ │ │ ├── triple_extraction.py
│ │ │ ├── ...
│ │ ├── __init__.py
│ │ ├── linking.py # 链接任务的指令
│ │ ├── prompt_template_manager.py # 提示模板管理器的实现
│ ├── 📂 utils # 整个项目中使用的工具函数(文件名表示其用途)
│ │ ├── config_utils.py # 所有模块共用的唯一配置及其设置在此指定
│ │ ├── ...
│ ├── __init__.py
│ ├── HippoRAG.py # 最高层的类,用于初始化检索、问答和评估
│ ├── embedding_store.py # 存储数据库,用于加载、管理和保存段落、实体和事实的嵌入向量
│ ├── rerank.py # 重排序和过滤方法
│-- 📂 examples
│ ├── ...
│ ├── ...
│-- 📜 README.md
│-- 📜 requirements.txt # 依赖列表
│-- 📜 .gitignore # Git 忽略文件列表
这个项目的代码结构非常清晰,很适合学习。
其中,HippoRAG.py 是项目中的最高层级模块,它定义了一个名为 HippoRAG 的类,该类的作用是作为整个系统的核心控制器或主接口(Main Controller / Entry Point),负责协调多个模块协同工作。
换句话说就是:
HippoRAG.py 是整个项目的“大脑”,它整合了嵌入模型、语言模型、提示工程、信息抽取和评估体系,提供了从查询、检索、回答到评估的一站式 RAG 系统接口。
主函数
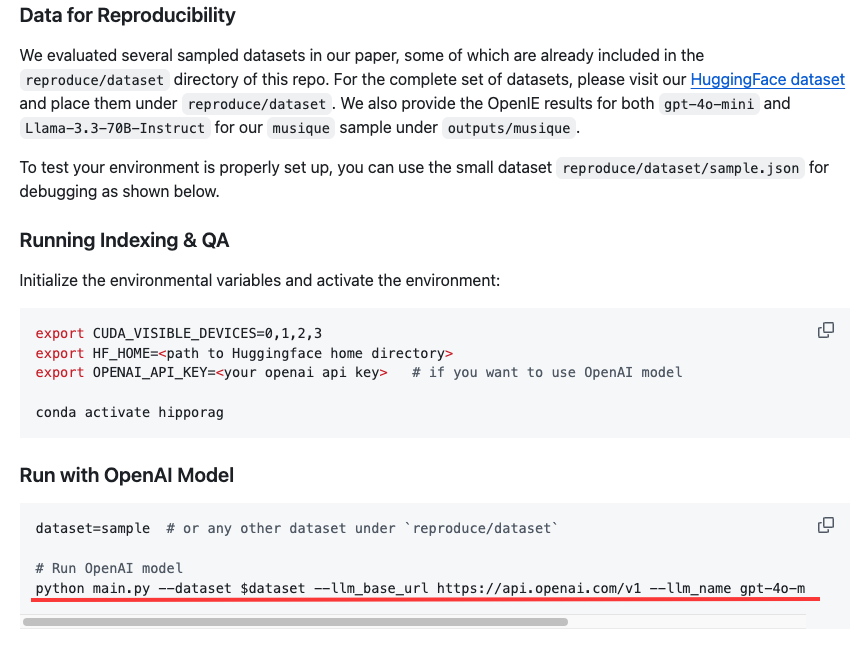
可以看到这个项目的主要运行逻辑是往main.py里传入对应的参数,我们再看一下主函数内部在实现什么操作。
# 设置CUDA设备排序方式为PCI总线ID
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
# 禁用tokenizers的并行处理以避免警告
os.environ["TOKENIZERS_PARALLELISM"] = "false"import loggingdef get_gold_docs(samples: List, dataset_name: str = None) -> List:"""获取支持文档(gold documents)"""gold_docs = []for sample in samples:# 处理hotpotqa和2wikimultihopqa数据集if 'supporting_facts' in sample: # hotpotqa, 2wikimultihopqa# 获取支持事实的标题集合gold_title = set([item[0] for item in sample['supporting_facts']])# 根据标题筛选出相关内容gold_title_and_content_list = [item for item in sample['context'] if item[0] in gold_title]# 针对hotpotqa数据集的特殊处理if dataset_name.startswith('hotpotqa'):gold_doc = [item[0] + '\n' + ''.join(item[1]) for item in gold_title_and_content_list]else:gold_doc = [item[0] + '\n' + ' '.join(item[1]) for item in gold_title_and_content_list]# 处理包含contexts字段的样本elif 'contexts' in sample:gold_doc = [item['title'] + '\n' + item['text'] for item in sample['contexts'] if item['is_supporting']]# 处理包含paragraphs字段的样本else:assert 'paragraphs' in sample, "`paragraphs` should be in sample, or consider the setting not to evaluate retrieval"gold_paragraphs = []for item in sample['paragraphs']:# 跳过非支持段落if 'is_supporting' in item and item['is_supporting'] is False:continuegold_paragraphs.append(item)gold_doc = [item['title'] + '\n' + (item['text'] if 'text' in item else item['paragraph_text']) for item in gold_paragraphs]# 去重后添加到结果列表gold_doc = list(set(gold_doc))gold_docs.append(gold_doc)return gold_docsdef get_gold_answers(samples):"""获取标准答案(gold answers)"""gold_answers = []for sample_idx in range(len(samples)):gold_ans = Nonesample = samples[sample_idx]# 根据不同字段获取答案if 'answer' in sample or 'gold_ans' in sample:gold_ans = sample['answer'] if 'answer' in sample else sample['gold_ans']elif 'reference' in sample:gold_ans = sample['reference']elif 'obj' in sample:# 合并多个可能的答案来源gold_ans = set([sample['obj']] + [sample['possible_answers']] + [sample['o_wiki_title']] + [sample['o_aliases']])gold_ans = list(gold_ans)assert gold_ans is not None# 确保答案为列表形式if isinstance(gold_ans, str):gold_ans = [gold_ans]assert isinstance(gold_ans, list)gold_ans = set(gold_ans)# 添加答案别名if 'answer_aliases' in sample:gold_ans.update(sample['answer_aliases'])gold_answers.append(gold_ans)return gold_answersdef main():# 设置命令行参数解析器parser = argparse.ArgumentParser(description="HippoRAG retrieval and QA")parser.add_argument('--dataset', type=str, default='musique', help='数据集名称')parser.add_argument('--llm_base_url', type=str, default='https://api.openai.com/v1', help='LLM基础URL')parser.add_argument('--llm_name', type=str, default='gpt-4o-mini', help='LLM名称')parser.add_argument('--embedding_name', type=str, default='nvidia/NV-Embed-v2', help='嵌入模型名称')parser.add_argument('--force_index_from_scratch', type=str, default='false',help='如果设为True,将忽略所有现有存储文件和图表数据并从头开始重建')parser.add_argument('--force_openie_from_scratch', type=str, default='false', help='如果设为False,将尝试首先重用语料库的openie结果')parser.add_argument('--openie_mode', choices=['online', 'offline'], default='online',help="OpenIE模式,offline表示使用VLLM离线批量模式进行索引,online表示在线模式")parser.add_argument('--save_dir', type=str, default='outputs', help='保存目录')args = parser.parse_args()# 从参数中获取配置dataset_name = args.datasetsave_dir = args.save_dirllm_base_url = args.llm_base_urlllm_name = args.llm_name# 设置保存目录if save_dir == 'outputs':save_dir = save_dir + '/' + dataset_nameelse:save_dir = save_dir + '_' + dataset_name# 加载语料库corpus_path = f"reproduce/dataset/{dataset_name}_corpus.json"with open(corpus_path, "r") as f:corpus = json.load(f)# 格式化文档数据docs = [f"{doc['title']}\n{doc['text']}" for doc in corpus]# 转换布尔参数force_index_from_scratch = string_to_bool(args.force_index_from_scratch)force_openie_from_scratch = string_to_bool(args.force_openie_from_scratch)# 准备数据集和评估samples = json.load(open(f"reproduce/dataset/{dataset_name}.json", "r"))all_queries = [s['question'] for s in samples]# 获取标准答案和支持文档gold_answers = get_gold_answers(samples)try:gold_docs = get_gold_docs(samples, dataset_name)assert len(all_queries) == len(gold_docs) == len(gold_answers), "查询、支持文档和标准答案的长度应该相同"except:gold_docs = None# 配置基础参数config = BaseConfig(save_dir=save_dir,llm_base_url=llm_base_url,llm_name=llm_name,dataset=dataset_name,embedding_model_name=args.embedding_name,force_index_from_scratch=force_index_from_scratch, # 忽略之前存储的索引,设为False可使用之前存储的索引和嵌入force_openie_from_scratch=force_openie_from_scratch,rerank_dspy_file_path="src/hipporag/prompts/dspy_prompts/filter_llama3.3-70B-Instruct.json",retrieval_top_k=200,linking_top_k=5,max_qa_steps=3,qa_top_k=5,graph_type="facts_and_sim_passage_node_unidirectional",embedding_batch_size=8,max_new_tokens=None,corpus_len=len(corpus),openie_mode=args.openie_mode)# 设置日志级别logging.basicConfig(level=logging.INFO)# 初始化HippoRAGhipporag = HippoRAG(global_config=config)# 构建索引hipporag.index(docs)# 执行检索和问答hipporag.rag_qa(queries=all_queries, gold_docs=gold_docs, gold_answers=gold_answers)if __name__ == "__main__":main()
在这个主函数的代码中,绝大部分是在设置对应的参数和路径,最关键的部分是在构建索引和QA过程中,其中构建索引是通过hipporag.index(docs)来实现的,也就是通过HippoRAG中的index方法在实现本操作。
索引方法
HippoRAG中的各个属性和参数如下所示:
- 属性(Attributes):
global_config (BaseConfig):实例的全局配置设置。如果没有提供值,则使用一个 BaseConfig 的实例。
saving_dir (str):用于存储特定 HippoRAG 实例的目录。如果没有提供值,默认为 outputs。
llm_model (BaseLLM):根据全局配置设置使用的语言模型,用于处理任务。
openie (Union[OpenIE, VLLMOfflineOpenIE]):开放信息抽取模块,根据全局配置设置以在线或离线模式进行配置。
graph:由 initialize_graph 方法初始化的图结构实例。
embedding_model (BaseEmbeddingModel):与当前配置相关联的嵌入模型。
chunk_embedding_store (EmbeddingStore):用于管理段落(chunk)嵌入的嵌入存储器。
entity_embedding_store (EmbeddingStore):用于管理实体(entity)嵌入的嵌入存储器。
fact_embedding_store (EmbeddingStore):用于管理事实(fact)嵌入的嵌入存储器。
prompt_template_manager (PromptTemplateManager):用于管理提示模板和角色映射的管理器。
openie_results_path (str):基于全局配置中的数据集名称和 LLM 名称,存储开放信息抽取结果的文件路径。
rerank_filter (Optional[DSPyFilter]):当全局配置中指定了重排序文件路径时,负责执行信息重排序的过滤器。
ready_to_retrieve (bool):标志位,表示系统是否已准备好执行检索操作。
- 参数(Parameters):
global_config:全局配置对象。默认为 None,此时将初始化一个新的 BaseConfig 对象。
working_dir:用于存储工作文件的目录。默认为 None,此时将基于类名和时间戳构造一个默认目录。
llm_model_name:大语言模型名称,可以通过参数直接传入,也可以通过配置文件指定。
embedding_model_name:嵌入模型名称,可以通过参数直接传入,也可以通过配置文件指定。
llm_base_url:部署好的 LLM 模型的 URL 地址,可以通过参数直接传入,也可以通过配置文件指定。
HippoRAG类中的index方法会对文档执行 OpenIE 抽取知识图谱,并分别编码段落、实体和事实,用于后续检索。
def index(self, docs: List[str]):"""根据 HippoRAG 2 框架对给定文档进行索引。参数:docs : List[str]需要被索引的文档列表。"""# 记录日志:开始索引文档logger.info(f"Indexing Documents")# 记录日志:开始执行 OpenIE(开放式信息抽取)logger.info(f"Performing OpenIE")# 如果配置为离线模式,则调用 pre_openie 方法预处理文档if self.global_config.openie_mode == 'offline':self.pre_openie(docs)# 将文档段落插入到 chunk_embedding_store 中(用于存储段落嵌入)self.chunk_embedding_store.insert_strings(docs)# 获取所有已有的 chunk_id 到对应文档内容的映射关系chunk_to_rows = self.chunk_embedding_store.get_all_id_to_rows()# 加载已有 OpenIE 结果,并获取需要重新处理的 chunk_idsall_openie_info, chunk_keys_to_process = self.load_existing_openie(chunk_to_rows.keys())# 构建新的 OpenIE 待处理数据:仅包含未处理过的 chunk 数据new_openie_rows = {k: chunk_to_rows[k] for k in chunk_keys_to_process}# 如果有待处理的新 chunk,则批量执行 OpenIE(NER + 三元组抽取)if len(chunk_keys_to_process) > 0:# 执行批量 OpenIE,返回 NER 实体和三元组结果new_ner_results_dict, new_triple_results_dict = self.openie.batch_openie(new_openie_rows)# 合并新抽取的结果到已有 OpenIE 信息中self.merge_openie_results(all_openie_info, new_openie_rows, new_ner_results_dict, new_triple_results_dict)# 如果配置要求保存 OpenIE 结果,则调用保存方法if self.global_config.save_openie: self.save_openie_results(all_openie_info)# 对 OpenIE 结果进行格式化处理,提取 NER 和 Triple 字典ner_results_dict, triple_results_dict = reformat_openie_results(all_openie_info)# 断言:确保 chunk 数量与 NER、Triple 结果数量一致,避免数据不匹配assert len(chunk_to_rows) == len(ner_results_dict) == len(triple_results_dict)# 准备数据结构:获取所有 chunk 的 IDchunk_ids = list(chunk_to_rows.keys())# 对每个 chunk 的三元组进行文本处理(如标准化、清洗等)chunk_triples = [[text_processing(t) for t in triple_results_dict[chunk_id].triples] for chunk_id in chunk_ids]# 提取所有实体节点以及每个 chunk 对应的实体集合entity_nodes, chunk_triple_entities = extract_entity_nodes(chunk_triples)# 将所有唯一实体插入到实体嵌入数据库中logger.info(f"Encoding Entities")self.entity_embedding_store.insert_strings(entity_nodes)# 将所有事实(facts)转换为字符串形式并插入到事实嵌入数据库中logger.info(f"Encoding Facts")self.fact_embedding_store.insert_strings([str(fact) for fact in facts])# 开始构建知识图谱logger.info(f"Constructing Graph")# 初始化一些图相关的统计字典和映射表self.node_to_node_stats = {}self.ent_node_to_chunk_ids = {}# 添加事实边到图中(连接实体与事实)self.add_fact_edges(chunk_ids, chunk_triples)# 添加段落边到图中(连接段落与实体/事实),返回新增的 chunk 数量num_new_chunks = self.add_passage_edges(chunk_ids, chunk_triple_entities)# 如果有新增 chunk,则继续添加同义词边并扩展图结构if num_new_chunks > 0:logger.info(f"Found {num_new_chunks} new chunks to save into graph.")self.add_synonymy_edges() # 添加同义词边self.augment_graph() # 增强图结构(如推理、补全等操作)self.save_igraph() # 保存最终构建的知识图谱
嵌入向量生成
对于使用NVEmbedV2模型而言,批量生成嵌入向量的代码如下所示:
def batch_encode(self, texts: List[str], **kwargs) -> None:"""批量编码文本为嵌入向量参数:texts: 要编码的文本列表(支持单个字符串自动转换)**kwargs: 额外的编码参数,会覆盖默认配置返回:numpy数组形式的嵌入向量结果"""# 处理单字符串输入情况:转换为单元素列表if isinstance(texts, str): texts = [texts]# 深拷贝默认编码参数以避免修改原配置params = deepcopy(self.embedding_config.encode_params)# 用kwargs参数更新默认配置if kwargs: params.update(kwargs)# 特殊处理instruction参数if "instruction" in kwargs:if kwargs["instruction"] != '': # 非空instruction处理# 格式化instruction模板params["instruction"] = f"Instruct: {kwargs['instruction']}\nQuery: "# 注:原代码有被注释掉的删除instruction操作# del params["instruction"]# 获取批处理大小(默认16)batch_size = params.pop("batch_size", 16)# 记录调试日志logger.debug(f"Calling {self.__class__.__name__} with:\n{params}")# 根据文本数量选择处理方式if len(texts) <= batch_size:# 小批量直接处理params["prompts"] = texts results = self.embedding_model.encode(**params)else:# 大批量分批次处理pbar = tqdm(total=len(texts), desc="Batch Encoding") # 进度条results = []for i in range(0, len(texts), batch_size):# 分批次编码params["prompts"] = texts[i:i + batch_size]results.append(self.embedding_model.encode(**params))pbar.update(batch_size) # 更新进度pbar.close()# 合并批次结果results = torch.cat(results, dim=0)# 结果后处理if isinstance(results, torch.Tensor):# 转换Tensor到numpy数组results = results.cpu() # 确保在CPU上results = results.numpy()# 归一化处理(如果配置开启)if self.embedding_config.norm:results = (results.T / np.linalg.norm(results, axis=1)).Treturn results
存储段落嵌入
首先要将语料库中的段落形成嵌入向量并存储起来。
# 将文本段落后插入到 chunk_embedding_store 中(用于存储段落嵌入)self.chunk_embedding_store.insert_strings(docs)
而 chunk_embedding_store 又是通过EmbeddingStore这个类来初始化的。
self.chunk_embedding_store = EmbeddingStore(self.embedding_model,os.path.join(self.working_dir, "chunk_embeddings"),self.global_config.embedding_batch_size, 'chunk')
在这个类中,insert_strings主要是将文本转化为嵌入向量插入到存储中、
def insert_strings(self, texts: List[str]):"""插入文本到存储中参数:texts: 待插入的文本列表"""nodes_dict = {}# 为每个文本生成hash_idfor text in texts:nodes_dict[compute_mdhash_id(text, prefix=self.namespace + "-")] = {'content': text}all_hash_ids = list(nodes_dict.keys())if not all_hash_ids:return # 无内容可插入# 检查已存在的记录existing = self.hash_id_to_row.keys()missing_ids = [hash_id for hash_id in all_hash_ids if hash_id not in existing]logger.info(f"插入 {len(missing_ids)} 条新记录,{len(all_hash_ids) - len(missing_ids)} 条记录已存在")if not missing_ids:return {} # 所有记录已存在# 准备需要编码的文本texts_to_encode = [nodes_dict[hash_id]["content"] for hash_id in missing_ids]# 生成嵌入向量并更新存储missing_embeddings = self.embedding_model.batch_encode(texts_to_encode)self._upsert(missing_ids, texts_to_encode, missing_embeddings)
开放信息提取
def batch_openie(self, chunks: Dict[str, ChunkInfo]) -> Tuple[Dict[str, NerRawOutput], Dict[str, TripleRawOutput]]:"""批量执行开放信息抽取(OpenIE),包括命名实体识别(NER)和三元组抽取,使用多线程并行处理。参数:chunks: 需要处理的文本块字典,键为哈希化的chunk_id,值为包含文本内容的ChunkInfo对象返回:包含两个字典的元组:- 第一个字典: chunk_id到NER结果的映射- 第二个字典: chunk_id到三元组抽取结果的映射"""# 从输入的chunks中提取出纯文本内容,建立chunk_id到文本的映射chunk_passages = {chunk_key: chunk["content"] for chunk_key, chunk in chunks.items()}# 初始化NER处理相关的统计变量ner_results_list = [] # 存储所有NER结果total_prompt_tokens = 0 # 累计使用的prompt tokens数total_completion_tokens = 0 # 累计生成的completion tokens数num_cache_hit = 0 # 缓存命中次数统计# 创建线程池并行处理NER任务with ThreadPoolExecutor() as executor:# 为每个chunk提交NER任务到线程池# 使用字典推导式创建future到chunk_id的映射ner_futures = {executor.submit(self.ner, chunk_key, passage): chunk_keyfor chunk_key, passage in chunk_passages.items()}# 使用tqdm创建进度条,跟踪NER任务完成情况pbar = tqdm(as_completed(ner_futures), total=len(ner_futures), desc="NER")for future in pbar:# 获取当前完成的NER任务结果result = future.result()ner_results_list.append(result)# 从结果元数据中提取统计信息并累加metadata = result.metadatatotal_prompt_tokens += metadata.get('prompt_tokens', 0)total_completion_tokens += metadata.get('completion_tokens', 0)if metadata.get('cache_hit'):num_cache_hit += 1# 更新进度条显示统计信息pbar.set_postfix({'total_prompt_tokens': total_prompt_tokens,'total_completion_tokens': total_completion_tokens,'num_cache_hit': num_cache_hit})# 初始化三元组抽取相关的统计变量triple_results_list = []total_prompt_tokens, total_completion_tokens, num_cache_hit = 0, 0, 0# 创建线程池并行处理三元组抽取任务with ThreadPoolExecutor() as executor:# 为每个NER结果提交三元组抽取任务# 使用NER结果中的chunk_id、对应文本和识别出的实体作为参数re_futures = {executor.submit(self.triple_extraction, ner_result.chunk_id,chunk_passages[ner_result.chunk_id],ner_result.unique_entities): ner_result.chunk_idfor ner_result in ner_results_list}# 使用tqdm创建进度条,跟踪三元组抽取任务完成情况pbar = tqdm(as_completed(re_futures), total=len(re_futures), desc="Extracting triples")for future in pbar:# 获取当前完成的三元组抽取结果result = future.result()triple_results_list.append(result)# 从结果元数据中提取统计信息并累加metadata = result.metadatatotal_prompt_tokens += metadata.get('prompt_tokens', 0)total_completion_tokens += metadata.get('completion_tokens', 0)if metadata.get('cache_hit'):num_cache_hit += 1# 更新进度条显示统计信息pbar.set_postfix({'total_prompt_tokens': total_prompt_tokens,'total_completion_tokens': total_completion_tokens,'num_cache_hit': num_cache_hit})# 将NER和三元组抽取结果列表转换为字典形式,以chunk_id为键ner_results_dict = {res.chunk_id: res for res in ner_results_list}triple_results_dict = {res.chunk_id: res for res in triple_results_list}# 返回两个结果字典return ner_results_dict, triple_results_dict
总结
本周深入研究了HippoRAG项目的整体架构和核心实现,重点分析了其模块化设计、索引构建流程和知识图谱生成机制。项目通过HippoRAG类整合嵌入模型、信息抽取和LLM推理,采用多线程并行处理实现高效的开放信息抽取,并利用NV-Embed-v2等先进模型进行向量编码,构建了一个完整的检索-问答系统框架。代码结构清晰规范,各模块职责明确,具有良好的可扩展性和学习价值,为后续的优化和应用奠定了坚实基础。