ALOHA ACT算法与源码笔记
算法
一文通透动作分块算法ACT:斯坦福ALOHA团队推出的动作序列预测算法(Action Chunking with Transformers)
比较简单,算法题目里就写了:Action Chunking with Transformers,比较有特色的地方就是Action Chunking,核心就是不浪费之前做过的推理预测,统统拿过来加权一下,得到最终的答案。

源码
逐行解读ALOHA ACT的实现:机器人动作分块算法ACT的代码剖析、训练部署(含真机上的智能分拣复现)
代码写得很优雅,读起来很流畅
1.1.1 模仿学习及其挑战:Action Chunking with Transformers(ACT)
预测动作中的小误差会引起状态的大差异,加剧模仿学习的“复合误差”问题。为了解决这个问题,他们从动作分块(action chunking)中获得灵感,这是心理学中的一个概念,描述了如何将一系列动作组合在一起作为一个块,最终作为一个单元执行
他们使用Transformers实现动作分块策略,并将其训练为条件VAE (CVAE),以捕获人类数据中的可变性。他们将该方法命名为Action Chunking with Transformers(ACT),并发现它在一系列模拟和现实世界的精细操作任务上显著优于以前的模仿学习算法
2.2.2 第二步 推断z,以获得CVAE解码器输入中的风格变量z
一文通透动作分块算法ACT:斯坦福ALOHA团队推出的动作序列预测算法(Action Chunking with Transformers)的这句话啥意思?
最后
只取第一个输出,它对应于**[CLS]标记**,并使用另一个线性网络来预测z分布的均值和方差,将其参数化为对角高斯分布
且使用重新参数化获得z的样本,这是一种允许在采样过程中反向传播的标准方法,以便编码器和解码器可以联合优化[33]
看detr_vae.py的代码就知道了:
在DETRVAE的if is_training头上有个注释:Obtain latent z from action sequence,
意思是风格变量z就是latent_input
[CLS]标记:encoder_output = encoder_output[0] # take cls output only
均值:mu = latent_info[:, :self.latent_dim]
方差:logvar = latent_info[:, self.latent_dim:]
使用重新参数化获得z的样本:latent_sample = reparametrize(mu, logvar)
最后:latent_input = self.latent_out_proj(latent_sample)
2.3 优势特征:ACT与其他模仿学习方法的比较
一方面,transformer解码器的“query”是第一层固定的正弦位置嵌入,即如上图右下角所示的position embeddings(fixed),其维度为k ×512
二方面,transformer解码器的交叉注意力(cross-attention)层中的“keys”和“values”来自上述transformer编码器的输出
eval_bc(评估一个行为克隆(behavior cloning)模型)和train_bc(训练行为克隆BC模型)的区别
我看到train_bc里头有个eval的,但这个eval应该和eval_bc不一样,虽然两者都要用到policy.eval()
注:policy里头就会调用
model, optimizer = build_ACT_model_and_optimizer(args_override)
self.model = model
1.8.3.2 根据观察结果查询策略、获取动作
这里的train_bc的policy调用参数是(qpos_data, image_data, action_data, is_pad)
eval_bc的policy调用参数是(qpos, curr_image)
根据参数来判断是训练还是推理
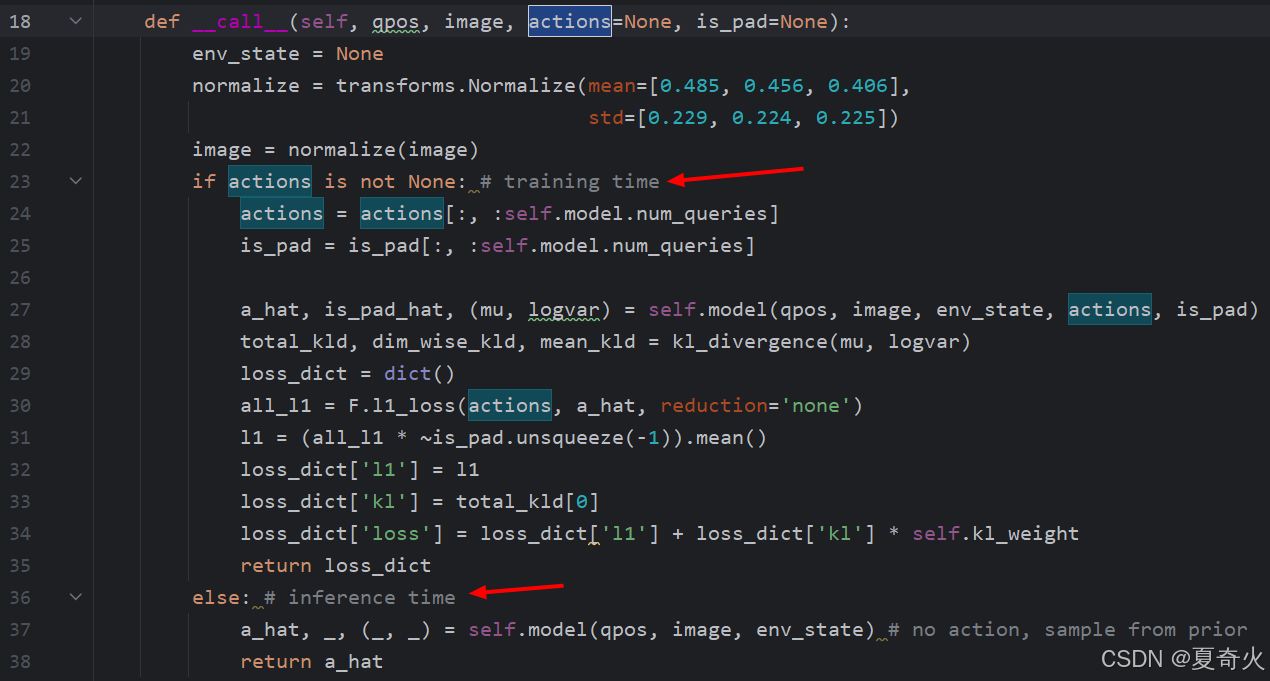
在训练模式下,会计算出一系列的损失并返回一个包含这些损失的字典
在推理模式下,会从模型中获取预测的动作并返回
aloha act代码里头的qpos和action有什么区别?
https://metaso.cn/s/IOAGn1O
那mu, logvar是啥
https://metaso.cn/s/IOAGn1O
在变分自编码器(VAE)中,mu 和 logvar 是两个关键参数,它们分别代表潜在变量的均值和对数方差,用于生成潜在空间的样本。
这段代码是 变分自编码器(VAE) 中的 重参数化技巧(Reparameterization Trick) 的实现,其作用是 从潜在变量的分布中采样,同时保证 梯度可以连续传播,从而实现端到端的训练。
def reparametrize(mu, logvar):std = logvar.div(2).exp()eps = Variable(std.data.new(std.size()).normal_())return mu + std * eps
编码器和编码器的输入与输出
backbone + encoder 等等输入到 self.transformer,其实self.transformer就是decoder部分
核心代码是detr_vae.py的class DETRVAE(nn.Module):的def forward的if is_training:部分
前提:detr_vae.py的class DETRVAE(nn.Module):的def forward的参数:qpos, image, env_state, actions, is_pad,都来自于imitate_episodes.py的def forward_pass(data, policy)的data
编码器的输入与输出
编码器的核心调用语句:self.encoder(encoder_input, pos=pos_embed, src_key_padding_mask=is_pad)
参数的来源:
# project action sequence to embedding dim, and concat with a CLS token
action_embed = self.encoder_action_proj(actions) # (bs, seq, hidden_dim)
qpos_embed = self.encoder_joint_proj(qpos) # (bs, hidden_dim) # qpos来自于forward_pass(data, policy):的image_data, qpos_data, action_data, is_pad = data
qpos_embed = torch.unsqueeze(qpos_embed, axis=1) # (bs, 1, hidden_dim)
cls_embed = self.cls_embed.weight # (1, hidden_dim)
cls_embed = torch.unsqueeze(cls_embed, axis=0).repeat(bs, 1, 1) # (bs, 1, hidden_dim)
encoder_input = torch.cat([cls_embed, qpos_embed, action_embed], axis=1) # (bs, seq+1, hidden_dim)
encoder_input = encoder_input.permute(1, 0, 2) # (seq+1, bs, hidden_dim)
# do not mask cls token 输出形状为(bs, 2)的二维张量,里面元素全部填充为False
cls_joint_is_pad = torch.full((bs, 2), False).to(qpos.device) # False: not a padding
is_pad = torch.cat([cls_joint_is_pad, is_pad], axis=1) # (bs, seq+1)
# obtain position embedding
pos_embed = self.pos_table.clone().detach()
pos_embed = pos_embed.permute(1, 0, 2) # (seq+1, 1, hidden_dim)
# query model
encoder_output = self.encoder(encoder_input, pos=pos_embed, src_key_padding_mask=is_pad)
encoder_output = encoder_output[0] # take cls output only
编码器的输入与输出
编码器的的核心调用语句为
hs = self.transformer(src, None, self.query_embed.weight, pos, latent_input, proprio_input, self.additional_pos_embed.weight)[0]
其中:
- src
all_cam_features = []
for cam_id, cam_name in enumerate(self.camera_names):features, pos = self.backbones[0](image[:, cam_id]) # HARDCODEDfeatures = features[0] # take the last layer featurepos = pos[0]all_cam_features.append(self.input_proj(features))all_cam_pos.append(pos)
# fold camera dimension into width dimension
src = torch.cat(all_cam_features, axis=3)
- pos
for cam_id, cam_name in enumerate(self.camera_names):features, pos = self.backbones[0](image[:, cam_id]) # HARDCODEDfeatures = features[0] # take the last layer featurepos = pos[0]all_cam_features.append(self.input_proj(features))all_cam_pos.append(pos)
pos = torch.cat(all_cam_pos, axis=3)
- latent_input 【Obtain latent z from action sequence】里的latent z
self.latent_dim = 32
latent_info = self.latent_proj(encoder_output) # 来自于编码器的输出
mu = latent_info[:, :self.latent_dim] # 潜在变量的均值
logvar = latent_info[:, self.latent_dim:] # 潜在变量的对数方差
latent_sample = reparametrize(mu, logvar)
latent_input = self.latent_out_proj(latent_sample)
- proprio_input = self.input_proj_robot_state(qpos) # qpos来自于forward_pass(data, policy):的image_data, qpos_data, action_data, is_pad = data
为什么env_max_reward 设成0 ?
可能真机不需要看模拟出来的精度?
# load environment
if real_robot:from aloha_scripts.robot_utils import move_grippers # requires alohafrom aloha_scripts.real_env import make_real_env # requires alohaenv = make_real_env(init_node=True)env_max_reward = 0 # 为什么设成0 ?
success_rate = np.mean(np.array(highest_rewards) == env_max_reward)
avg_return = np.mean(episode_returns)
summary_str = f'\nSuccess rate: {success_rate}\nAverage return: {avg_return}\n\n'
for r in range(env_max_reward+1):more_or_equal_r = (np.array(highest_rewards) >= r).sum()more_or_equal_r_rate = more_or_equal_r / num_rolloutssummary_str += f'Reward >= {r}: {more_or_equal_r}/{num_rollouts} = {more_or_equal_r_rate*100}%\n'print(summary_str)