自动化监控方案设计:从 Prometheus 到 APM 工具的集成实践
关键词:自动化监控方案,Prometheus 监控,APM 工具集成,数据库性能基线,告警阈值配置,数据库监控,可观测性,Grafana,Alertmanager,Exporters,分布式追踪,日志管理,SRE
在复杂的现代分布式系统中,服务的健康状况、性能瓶颈以及潜在故障,如同冰山下的暗流,若无有效工具洞察,随时可能给业务带来致命打击。构建一套完善的自动化监控方案,不仅是应对突发事件的“灭火器”,更是保障系统稳定运行、优化资源配置、提升用户体验的“指南针”。
本文将探讨如何设计一套集成的自动化监控方案,以Prometheus作为核心指标采集与存储引擎,结合其强大的告警能力,并进一步与APM(应用性能管理)工具融合,实现从基础设施到应用代码层面的全面可观测性,特别是针对数据库性能的基线建立与告警阈值配置,为SRE和运维团队提供深度洞察。
1. 自动化监控体系的构建基石:可观测性金字塔
一个成熟的监控体系通常涵盖以下三个核心支柱,构成可观测性金字塔:
- 指标(Metrics):系统在特定时间点的数值度量,如CPU使用率、QPS、错误率、延迟等。Prometheus在此层扮演核心角色。
- 日志(Logs):离散的、描述系统事件的文本记录,用于排查具体问题。ELK Stack (Elasticsearch, Logstash, Kibana) 或 Loki 是常见方案。
- 追踪(Traces):记录请求在分布式系统中完整生命周期的调用链,用于分析服务间依赖和性能瓶颈。Jaeger、Zipkin、SkyWalking 属于此类。
本文将侧重于Metrics层,并探讨其与Traces/Logs层的集成。
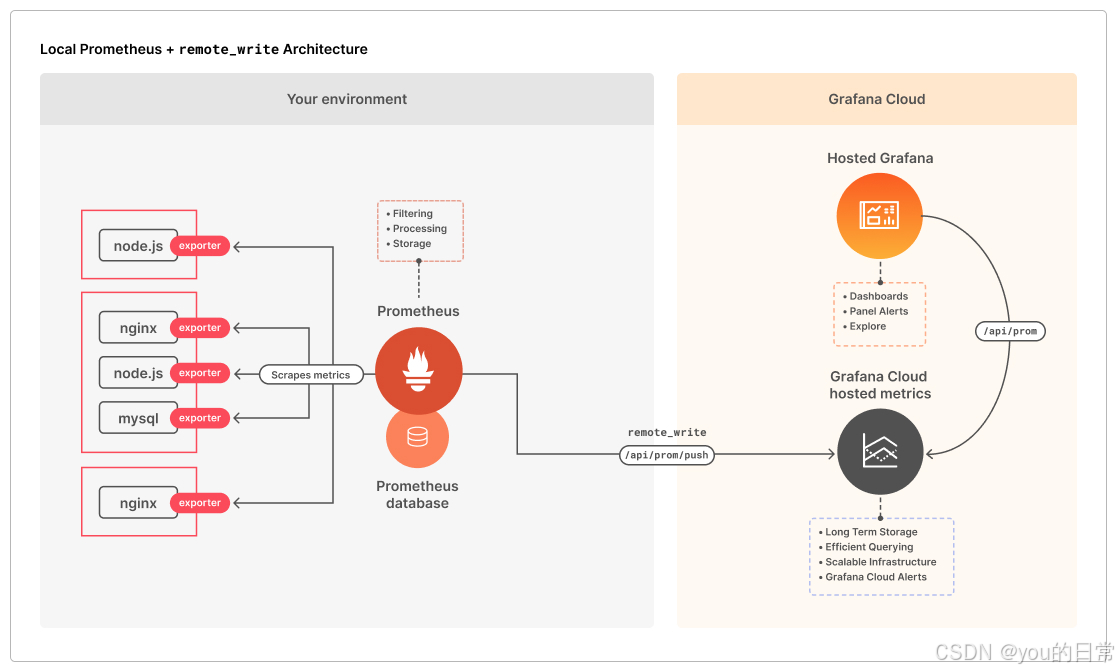
2. Prometheus:Metrics 收集与存储核心
Prometheus 是一款强大的开源监控系统,以其灵活的维度数据模型、Pull-based(拉取式)采集模式、PromQL查询语言和内置告警功能,成为云原生时代的监控标准。
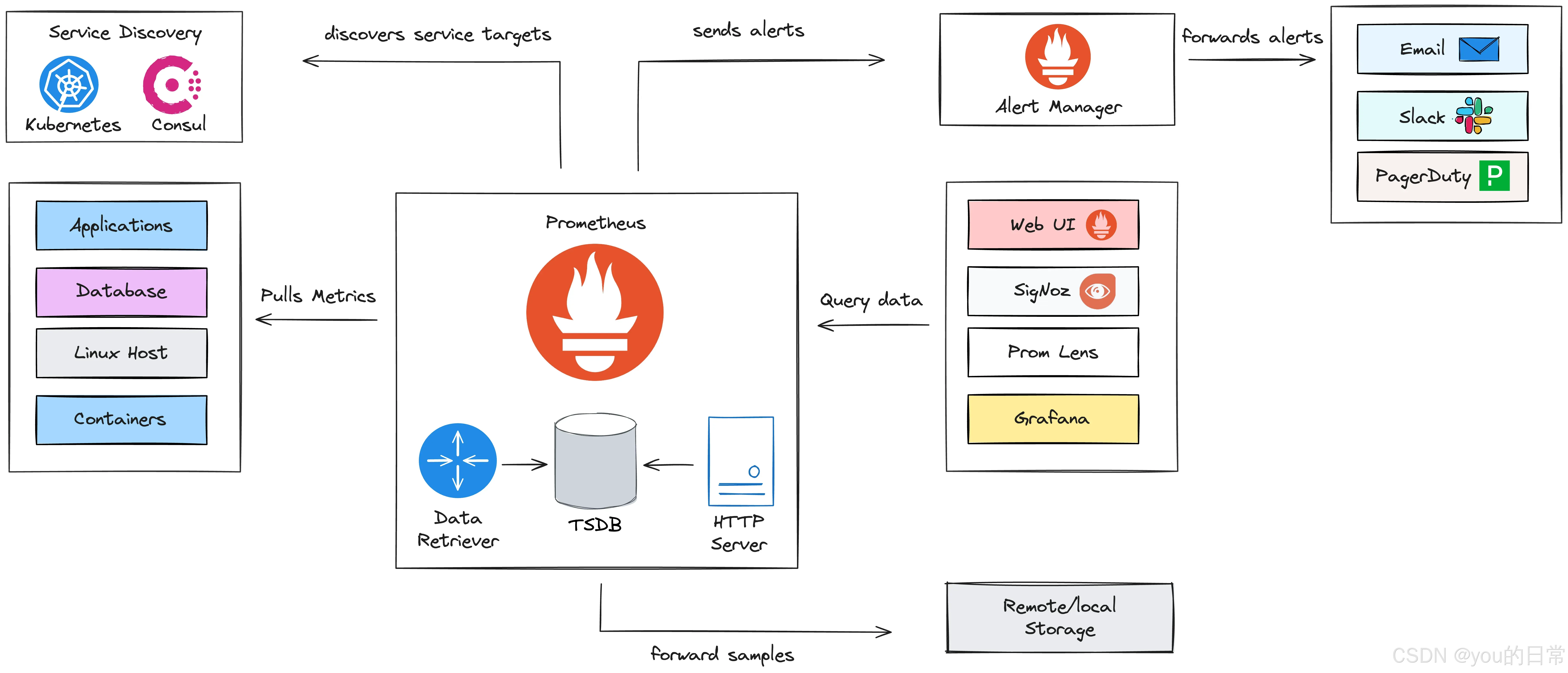
2.1 Prometheus 核心组件
- Prometheus Server:负责从配置的目标拉取指标,存储在本地的时间序列数据库中,并支持PromQL查询。
- Exporters:各种服务的轻量级中间件,将服务内部的指标转换为Prometheus可识别的格式。
- Alertmanager:处理Prometheus服务器发送的告警,进行分组、路由、去重、静默等操作,并发送到各种通知渠道(如邮件、Slack、Webhook)。
- Grafana:强大的可视化工具,能够从Prometheus查询数据并构建美观的仪表盘。
2.2 数据库 Exporters 介绍
数据库是应用的核心,其性能直接决定了整体系统的表现。针对主流数据库,Prometheus社区提供了成熟的Exporters:
- Node Exporter:用于采集服务器操作系统的通用指标,如CPU利用率、内存使用、磁盘I/O(IOPS、吞吐量、读写延迟)、网络流量等。
# 启动 Node Exporter (示例) ./node_exporter --web.listen-address=":9100" - MySQLd Exporter:针对MySQL数据库的专用Exporter,能采集QPS/TPS、连接数、Innodb Buffer Pool命中率、锁等待、慢查询计数等关键指标。
# 启动 MySQLd Exporter (示例) # 假设MySQL账号 'mysqld_exporter' 密码 'password' 拥有 SHOW DATABASES, REPLICATION CLIENT, PROCESS, RELOAD 等权限 ./mysqld_exporter --web.listen-address=":9104" \ --mysql.dsn="mysqld_exporter:password@(localhost:3306)/" - Postgres Exporter:针对PostgreSQL数据库的专用Exporter,提供数据库大小、连接数、WAL活动、缓存命中率等指标。