【C++】25. 哈希表封装unordered_map和unordered_set
上一章节我们分别用开放定址法和链地址法来实现哈希表,这一章节我们来对链地址法的哈希表封装,模拟STL库的思路来实现我们自己的unordered_map和unordered_set
1. 源码及框架分析
SGI-STL30版本源代码中确实未包含unordered_map和unordered_set这两个容器实现。这是因为SGI-STL30版本是基于C++98标准的STL实现,而unordered_map和unordered_set是在C++11标准中才正式加入STL的标准容器。
背景说明:
- SGI-STL30发布于2000年左右,是HP/SGI版本的STL实现
- C++11标准于2011年发布,才引入了基于哈希表的unordered系列容器
替代方案: 虽然缺少标准unordered容器,但SGI-STL30实现了自己的哈希表容器:
- hash_map:哈希表实现的映射容器
- hash_set:哈希表实现的集合容器
这些容器在当时属于非标准扩展(non-standard extensions),其特点是:
- 不在C++标准规定必须实现的容器范围内
- 各编译器厂商实现可能存在差异
- 接口设计与标准容器略有不同
源代码位置: 这些哈希表相关实现分布在以下文件中:
- hash_map:容器外部接口
- hash_set:容器外部接口
- stl_hash_map:内部实现
- stl_hash_set:内部实现
- stl_hashtable.h:核心哈希表数据结构实现
实现特点:
- 使用开链法解决哈希冲突
- 默认哈希函数针对基本数据类型
- 需要用户自定义哈希函数时需继承std::hash
- 装载因子默认阈值为1.0
示例代码:
#include <hash_map> // 非标准头文件
__gnu_cxx::hash_map<int, string> my_map; // 使用非标准命名空间
注意事项:
- 这些容器在移植到其他平台时可能存在兼容性问题
- C++11后建议改用标准的unordered系列容器
- 接口与标准容器有细微差别,需注意文档说明
hash_map和hash_set的核心实现框架结构如下:
// stl_hash_set
template <class Value, class HashFcn = hash<Value>,class EqualKey = equal_to<Value>,class Alloc = alloc>
class hash_set
{
private:typedef hashtable<Value, Value, HashFcn, identity<Value>,EqualKey, Alloc> ht;ht rep;
public:typedef typename ht::key_type key_type;typedef typename ht::value_type value_type;typedef typename ht::hasher hasher;typedef typename ht::key_equal key_equal;typedef typename ht::const_iterator iterator;typedef typename ht::const_iterator const_iterator;hasher hash_funct() const { return rep.hash_funct(); }key_equal key_eq() const { return rep.key_eq(); }
};
// stl_hash_map
template <class Key, class T, class HashFcn = hash<Key>,class EqualKey = equal_to<Key>,class Alloc = alloc>
class hash_map
{
private:typedef hashtable<pair<const Key, T>, Key, HashFcn,select1st<pair<const Key, T> >, EqualKey, Alloc> ht;ht rep;
public:typedef typename ht::key_type key_type;typedef T data_type;typedef T mapped_type;typedef typename ht::value_type value_type;typedef typename ht::hasher hasher;typedef typename ht::key_equal key_equal;typedef typename ht::iterator iterator;typedef typename ht::const_iterator const_iterator;
};
// stl_hashtable.h
template <class Value, class Key, class HashFcn,class ExtractKey, class EqualKey,class Alloc>
class hashtable {
public:typedef Key key_type;typedef Value value_type;typedef HashFcn hasher;typedef EqualKey key_equal;
private:hasher hash;key_equal equals;ExtractKey get_key;typedef __hashtable_node<Value> node;vector<node*, Alloc> buckets;size_type num_elements;
public:typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey,Alloc> iterator;pair<iterator, bool> insert_unique(const value_type& obj);const_iterator find(const key_type& key) const;
};
template <class Value>
struct __hashtable_node
{__hashtable_node* next;Value val;
};1.1 核心数据结构:hashtable
-
模板参数:
-
Value:节点存储的数据类型 -
Key:键的类型 -
HashFcn:哈希函数类型(默认hash<Key>) -
ExtractKey:从Value中提取键的函子 -
EqualKey:键比较函子(默认equal_to<Key>) -
Alloc:分配器类型(默认alloc)
-
-
关键成员:
-
hash:哈希函数对象 -
equals:键比较函数对象 -
get_key:键提取函数对象(类型为ExtractKey) -
buckets:桶数组(vector<node*, Alloc>) -
num_elements:元素总数
-
-
节点结构:
template <class Value> struct __hashtable_node {__hashtable_node* next; // 单向链表指针Value val; // 存储的数据 }; -
功能接口:
-
insert_unique():插入唯一键值对 -
find():查找键对应的元素
-
1.2 容器适配器
(1) hash_set
-
设计特点:
-
键与值类型相同(
key_type == value_type) -
使用
identity<Value>提取键(直接返回元素本身) -
迭代器均为常量(
const_iterator),禁止修改元素(避免破坏哈希结构)
-
-
模板参数:
template <class Value, class HashFcn = hash<Value>,class EqualKey = equal_to<Value>, class Alloc = alloc> -
底层实现:
typedef hashtable<Value, Value, HashFcn, identity<Value>, EqualKey, Alloc> ht; ht rep; // 核心哈希表实例
(2) hash_map
-
设计特点:
-
存储键值对
pair<const Key, T> -
使用
select1st提取键(返回pair.first) -
迭代器可修改值(
mapped_type),但键为const
-
-
模板参数:
template <class Key, class T, class HashFcn = hash<Key>,class EqualKey = equal_to<Key>, class Alloc = alloc> -
底层实现:
typedef hashtable<pair<const Key, T>, Key, HashFcn, select1st<pair<const Key, T>>, EqualKey, Alloc> ht; ht rep; // 核心哈希表实例 -
特殊类型定义:
-
mapped_type:值类型T -
data_type:值类型别名(与mapped_type相同)
-
1.3 核心设计思想
-
开链法解决冲突:
-
buckets数组 + 单向链表(__hashtable_node) -
桶数组存储链表头指针
-
-
策略泛化:
-
哈希函数:通过
HashFcn自定义 -
键提取:通过
ExtractKey适配不同容器-
hash_set→identity(值即键) -
hash_map→select1st(从pair提取键)
-
-
键比较:通过
EqualKey自定义相等逻辑
-
-
迭代器设计:
-
__hashtable_iterator实现跨桶遍历 -
hash_set仅提供常量迭代器(安全考虑) -
hash_map提供非常量迭代器(允许修改值)
-
-
内存管理:
-
使用
Alloc分配器管理节点和桶数组 -
节点单独分配(
__hashtable_node)
-
1.4 关键差异总结
| 特性 | hash_set | hash_map |
|---|---|---|
| 元素类型 | Value | pair<const Key, T> |
| 键提取方式 | identity<Value> | select1st<pair<...>> |
| 迭代器权限 | 仅 const_iterator | 支持 iterator 和 const_iterator |
| 修改元素 | ❌ 禁止 | ✅ 可修改值(不可修改键) |
总结
-
hashtable是通用底层实现,通过策略模板参数适配不同容器。 -
hash_set/hash_map是轻量适配器,主要封装键提取逻辑和迭代器类型。 -
该设计体现了泛型编程思想:将算法(哈希)、数据提取(
ExtractKey)、比较(EqualKey)等策略参数化。 -
与现代 C++ 的
unordered_set/unordered_map设计理念一致,但接口和实现细节有所不同。
通过深入分析STL源码可以发现,在底层实现结构上,hash_map和hash_set与标准map和set的设计理念完全类似,都是基于相同的hashtable模板实现的。具体实现细节如下:
-
复用机制:
- hash_set直接复用hashtable的key-only结构
- hash_map复用hashtable的key-value结构
-
参数传递方式:
容器类型 传递给hashtable的参数类型 hash_set Key, const Key(两个相同key) hash_map Key, std::pair<const Key, Value> -
源码中的命名问题:
- 在STL实现中存在明显的命名风格混乱现象
- hash_set的模板参数使用"Value"命名
- hash_map却使用"Key"和"T"命名
- 这与标准map/set的命名风格不一致(map使用key_type/value_type)
-
代码示例对比:
// 标准库中的不规范命名 template<class Value, ...> class hash_set; template<class Key, class T, ...> class hash_map;// 合理的命名应该为 template<class Key, ...> class hash_set; template<class Key, class Value, ...> class hash_map;
基于上述分析,我们将按照更规范的命名风格来重新实现这些容器:
- 采用一致的key/value命名规则
- 保持与STL标准容器相同的命名习惯
- 确保模板参数命名具有明确的语义
这样既能保证代码的可读性,又能与STL的其他容器保持风格一致。在实际开发中,即使是经验丰富的开发者也会出现代码风格不一致的情况,但保持良好的代码规范对于维护和协作至关重要。
2. 模拟实现unordered_map和unordered_set
2.1 实现出复用哈希表的框架,并支持insert
• 参考源码框架,让unordered_map和unordered_set复用之前实现的哈希表。
• 在参数设计上,我们采用K表示key,V表示value,哈希表中的数据类型则使用T。
• 相比map和set,unordered_map和unordered_set的模拟实现类结构稍复杂,但整体框架和思路是相似的。由于HashTable采用泛型设计,无法直接判断T是K还是pair<K,V>,因此在insert操作中需要以下处理:
- 将K对象转换为整形进行取模运算
- 比较K对象是否相等(而非比较整个pair对象)
• 为此,我们在unordered_map和unordered_set层面分别实现MapKeyOfT和SetKeyOfT仿函数,并将其传递给HashTable的KeyOfT。HashTable通过KeyOfT仿函数从T类型对象中提取K对象,用于转换为整形取模和比较相等性。具体实现细节请参考以下代码。
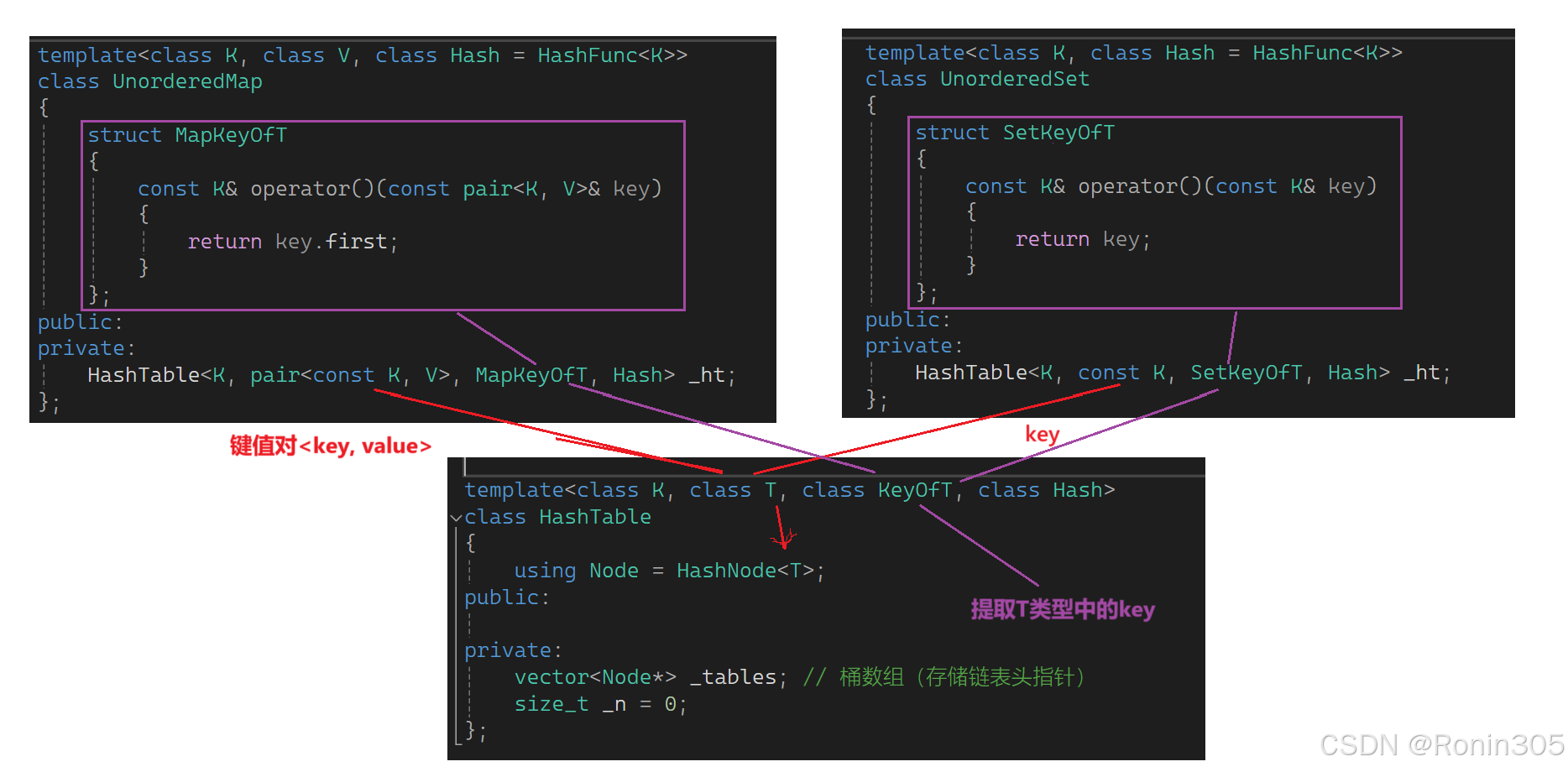
HashTable.h源代码
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& s){// BKDRsize_t hash = 0;for (auto ch : s){hash += ch;hash *= 131;}return hash;}
};inline unsigned long __stl_next_prime(unsigned long n)
{// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}template<class T>
struct HashNode
{HashNode(const T& data):_data(data),_next(nullptr){}T _data;HashNode<T>* _next;
};template<class K, class T, class KeyOfT, class Hash>
class HashTable
{using Node = HashNode<T>;
public:HashTable():_tables(__stl_next_prime(0))//:_tables(11){}HashTable(const HashTable& ht):_tables(ht._tables.size()), _n(ht._n){for (size_t i = 0; i < ht._tables.size(); i++){Node* cur = ht._tables[i];Node* tail = nullptr; // 方便尾插while (cur){Node* newnode = new Node(cur->_data);// 处理头节点if (_tables[i] == nullptr){_tables[i] = tail = newnode;}else{// 尾插tail->_next = newnode;tail = tail->_next;}cur = cur->_next;}}}// 现代写法HashTable& operator=(HashTable ht){_tables.swap(ht._tables);swap(_n, ht._n);return *this;}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const T& data){KeyOfT kot;// 存在就插入失败if (Find(kot(data))) return false;Hash hash;// 负载因子等于1时扩容if (_n == _tables.size()){vector<Node*> newtables(__stl_next_prime(_tables.size()) + 1);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = hash(kot(cur->_data)) % newtables.size();cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}size_t hashi = hash(kot(data)) % _tables.size();// 头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){KeyOfT kot;Hash hash;size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){KeyOfT kot;Hash hash;size_t hashi = hash(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){if (prev == nullptr){// 头节点_tables[hashi] = cur->_next;}else{// 中间节点prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}
private:vector<Node*> _tables; // 桶数组(存储链表头指针)size_t _n = 0;
};
UnorderedSet.h
namespace RO
{template<class K, class Hash = HashFunc<K>>class UnorderedSet{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:bool insert(const K& key){return _ht.Insert(key);}private:HashTable<K, const K, SetKeyOfT, Hash> _ht;};
}UnorderedMap.h
namespace RO
{template<class K, class V, class Hash = HashFunc<K>>class UnorderedMap{struct MapKeyOfT{const K& operator()(const pair<K, V>& key){return key.first;}};public:bool insert(const pair<K, V>& kv){return _ht.Insert(kv);}private:HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};
}2.2 迭代器实现支持
核心迭代器实现源码:
template <class Value, class Key, class HashFcn,class ExtractKey, class EqualKey, class Alloc>struct __hashtable_iterator {typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>hashtable;typedef __hashtable_iterator<Value, Key, HashFcn,ExtractKey, EqualKey, Alloc>iterator;typedef __hashtable_const_iterator<Value, Key, HashFcn,ExtractKey, EqualKey, Alloc>const_iterator;typedef __hashtable_node<Value> node;typedef forward_iterator_tag iterator_category;typedef Value value_type;node* cur;hashtable* ht;__hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab) {}__hashtable_iterator() {}reference operator*() const { return cur->val; }
#ifndef __SGI_STL_NO_ARROW_OPERATORpointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */iterator& operator++();iterator operator++(int);bool operator==(const iterator& it) const { return cur == it.cur; }bool operator!=(const iterator& it) const { return cur != it.cur; }};template <class V, class K, class HF, class ExK, class EqK, class A>__hashtable_iterator<V, K, HF, ExK, EqK, A>&__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++(){const node* old = cur;cur = cur->next;if (!cur) {size_type bucket = ht->bkt_num(old->val);while (!cur && ++bucket < ht->buckets.size())cur = ht->buckets[bucket];}return *this;}I. 迭代器基本设计
template <class Value, class Key, class HashFcn,class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {// 类型定义typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> hashtable;typedef __hashtable_node<Value> node;typedef forward_iterator_tag iterator_category; // 前向迭代器typedef Value value_type; // 迭代器值类型// 成员变量node* cur; // 当前节点指针hashtable* ht; // 关联的哈希表
};-
前向迭代器:使用
forward_iterator_tag标记,只支持单向遍历(++操作) -
双成员结构:
-
cur:指向当前链表节点 -
ht:指向所属哈希表(关键!用于跨桶遍历)
-
II. 迭代器操作实现
(1) 解引用操作
reference operator*() const { return cur->val; }
pointer operator->() const { return &(operator*()); }-
直接返回节点存储的值
val -
符合STL迭代器解引用规范
(2) 相等性比较
bool operator==(const iterator& it) const { return cur == it.cur; }
bool operator!=(const iterator& it) const { return cur != it.cur; }-
仅比较节点指针
cur(隐含要求比较的迭代器需属于同一哈希表)
III. 核心:迭代器自增操作(跨桶遍历)
iterator& operator++() {const node* old = cur;cur = cur->next; // 尝试移动到同桶的下一个节点// 当前桶遍历完毕,需要跨桶if (!cur) {size_type bucket = ht->bkt_num(old->val); // 计算旧节点所在桶索引// 向后搜索非空桶while (!cur && ++bucket < ht->buckets.size())cur = ht->buckets[bucket]; // 指向新桶的头节点}return *this;
}跨桶遍历算法:
-
先尝试在同桶链表移动(
cur = cur->next) -
若当前桶结束(
cur == nullptr):-
调用
ht->bkt_num(old->val)计算原节点所在桶索引 -
从下一个桶开始线性搜索(
++bucket) -
找到第一个非空桶(
buckets[bucket] != nullptr) -
将
cur指向新桶的头节点
-
IV. 关键设计特点
-
前向迭代器语义:
-
只支持
operator++(不提供--操作) -
符合哈希表无序容器的遍历特性
-
-
与哈希表的强耦合:
-
持有
hashtable*指针,用于访问桶数组 -
依赖
bkt_num()计算桶索引(需哈希表实现)
-
-
高效的跨桶遍历:
-
平均时间复杂度:O(1)(当负载因子合理时)
-
最坏情况:O(n)(所有元素集中在一个桶)
-
-
迭代器有效性:
-
依赖哈希表的稳定性(插入操作可能导致桶数组扩容,使迭代器失效)
-
V. 类型系统设计
typedef __hashtable_iterator<...> iterator;
typedef __hashtable_const_iterator<...> const_iterator;-
区分普通迭代器和常量迭代器
-
hash_set使用const_iterator禁止修改元素 -
hash_map使用普通迭代器允许修改mapped_type
VI. 与哈希表的关系
// 在 hashtable 中的迭代器定义
typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> iterator;-
哈希表通过此迭代器类型暴露遍历接口
-
begin()/end()实现需要扫描桶数组找到第一个/最后一个节点
总结
这个迭代器设计体现了 SGI STL 的经典模式:
-
节点遍历:通过链表指针
cur->next实现桶内遍历 -
桶间跳跃:利用哈希表的桶数组信息实现跨桶
-
前向迭代:符合哈希表无序容器的特性要求
-
类型安全:通过模板参数保持与容器类型一致
iterator实现思路分析
• 实现框架与list的iterator类似:通过封装节点指针类型,并重载运算符来模拟指针访问行为。需注意哈希表迭代器为单向迭代器。
• 核心难点在于operator++的实现:
- 若当前桶仍有节点,则指针指向下一节点
- 若当前桶已遍历完毕,则需定位下一个非空桶
- 为方便桶定位,迭代器结构中除节点指针外还应保存哈希表指针,通过计算当前桶位置并顺序查找后续桶来实现
• 迭代器接口设计:
- begin()返回首个非空桶的首节点构造的迭代器
- end()可用空指针表示
• 容器适配:
- unordered_set迭代器禁止修改:将模板参数设为HashTable<K, const K, SetKeyOfT, Hash> _ht
- unordered_map仅允许修改value:使用HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht
迭代器结构
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct HashTableIterator
{using Node = HashNode<T>;using HT = HashTable<K, T, KeyOfT, Hash>;using Self = HashTableIterator<K, T, Ref, Ptr, KeyOfT, Hash>;Node* _node;const HT* _ht; // 为满足const迭代器的不可修改的特性,这里也得加上constHashTableIterator(Node* node, const HT* ht):_node(node),_ht(ht){}
};1. 模板参数设计
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>-
K:键类型(Key type)
-
T:节点存储的数据类型(Value type)
-
Ref:解引用返回的引用类型(
T&或const T&) -
Ptr:箭头操作符返回的指针类型(
T*或const T*) -
KeyOfT:从
T中提取键的函子(类似STL的ExtractKey) -
Hash:哈希函数类型
这种设计通过 Ref 和 Ptr 区分了普通迭代器和常量迭代器,无需单独实现const版本。
2. 类型别名
using Node = HashNode<T>;
using HT = HashTable<K, T, KeyOfT, Hash>;
using Self = HashTableIterator<...>;-
Node:哈希节点类型(应包含
T数据和next指针) -
HT:关联的哈希表类型(关键!用于跨桶遍历)
-
Self:迭代器自身类型(简化代码)
3. 成员变量
Node* _node; // 当前节点指针
const HT* _ht; // 所属哈希表指针(常量!)-
_node:指向当前链表节点 -
_ht:常量指针指向所属哈希表-
使用
const HT*是关键设计! -
确保迭代器不会意外修改哈希表结构(如桶数组)
-
满足常量迭代器的语义要求(即使通过const迭代器访问,也不能修改容器结构)
-
4. 构造函数
HashTableIterator(Node* node, const HT* ht):_node(node), _ht(ht)
{}-
同时需要节点和哈希表指针初始化
5. 设计亮点分析
(1) 常量正确性
const HT* _ht; // 常量指针!-
这是你实现最精妙的部分
-
通过
const HT*保证:-
常量迭代器不会修改哈希表结构(如桶数组)
-
普通迭代器仍可通过
_node修改元素值(若Ref= T&)
-
-
完美区分两种迭代器行为:
// 普通迭代器 using iterator = HashTableIterator<K, T, T&, T*, KeyOfT, Hash>;// 常量迭代器 using const_iterator = HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash>;
(2) 迭代器行为控制
-
通过模板参数控制迭代器类型:
-
若
Ref = const T&且Ptr = const T*:常量迭代器-
不允许修改元素值
-
不允许修改哈希表结构(由
const HT*保证)
-
-
若
Ref = T&且Ptr = T*:普通迭代器-
允许修改元素值(若
T允许) -
仍禁止修改哈希表结构
-
-
6. 对比SGI STL实现
| 特性 | 你的实现 | SGI STL实现 |
|---|---|---|
| 常量控制 | 模板参数+const HT* | 单独__hashtable_const_iterator |
| 迭代器类型区分 | 通过Ref/Ptr模板参数 | 单独类实现 |
| 哈希表指针 | 显式const修饰 | 无const修饰 |
| 代码复用 | 单模板处理两种迭代器 | 两个独立类 |
解引用操作符:
对迭代器解引用,我们直接返回对应哈希表节点数据的引用
Ref operator*()
{return _node->_data;
}箭头操作符:
使用->操作符时,直接返回对应哈希表节点数据的地址
Ptr operator->()
{return &_node->_data;
}比较操作符:
在进行迭代器遍历时,需要比较迭代器,只需要比较两个节点是否为同一个节点
bool operator!=(const Self& tmp)
{return _node != tmp._node;
}bool operator==(const Self& tmp)
{return _node == tmp._node;
}自增操作符:
前置++:
大致步骤如下:
- 若当前桶仍有节点,则指针指向下一节点
- 若当前桶已遍历完毕,则需定位下一个非空桶
Self& operator++()
{// 处理空表情况,防止除0错误if (_ht->_tables.empty()){_node = nullptr;return *this;}if (_node->_next){// 当前桶还有数据_node = _node->_next;}else // 跨桶查找{// 计算当前桶的索引KeyOfT kot;Hash hash;size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();// 向后查找非空桶while (++hashi < _ht->_tables.size()){_node = _ht->_tables[hashi];if (_node) break;}// 所有桶都走完了,end()为空标识符的_nodeif (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;
}(1) 处理空表情况
// 空表检查
if (_ht->_tables.empty()) {_node = nullptr;return *this;
}-
防止
% _ht->_tables.size()除零错误
(2) 正确的桶索引计算
size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();-
为什么必须重新计算?
-
节点在哈希表中的位置可能因扩容而改变
-
直接存储桶索引可能失效
-
-
优势:
-
保证在任何情况下都能正确定位起始桶
-
避免存储额外状态(节省内存)
-
(3) 高效的跨桶搜索
-
线性探测:
while (++hashi < ...)简单高效 -
短路优化:
if (_node) break;找到即停 -
适应动态桶数组:使用
_ht->_tables.size()实时大小
(4) 精确的边界处理
if (hashi == _ht->_tables.size()) {_node = nullptr;
}-
明确处理遍历结束的情况
-
将迭代器设为
nullptr符合 STL 规范 -
确保
it == end()判断有效
后置++:
Self operator++(int)
{Self tmp = *this;++(*this);// 复用前置++return tmp;
}这里其实还有2个小问题
问题1:访问私有成员
在 operator++ 实现中,迭代器直接访问了 HashTable 的私有成员:
// 在迭代器中访问哈希表的私有成员
_node = _ht->_tables[hashi]; // 访问 _tables
size_t size = _ht->_tables.size(); // 访问 _tables.size()-
_tables通常是HashTable的私有成员(如vector<Node*> _tables;) -
非友元类/函数无法访问其他类的私有成员
但是迭代器需要访问哈希表内部状态
| 访问需求 | 成员类型 | 必需性 |
|---|---|---|
桶数组 (_tables) | 私有 | ✅ 核心访问(跨桶遍历) |
桶数组大小 (size()) | 私有 | ✅ 计算桶索引边界 |
解决方案:友元声明
在 HashTable 类中添加:
template <class K, class T, class KeyOfT, class Hash>
class HashTable {// 声明所有迭代器变体为友元template <class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct HashTableIterator;// 或者更精确的声明(推荐)friend struct HashTableIterator<K, T, T&, T*, KeyOfT, Hash>; // 普通迭代器friend struct HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash>; // const迭代器
private:vector<Node*> _tables; // 私有桶数组size_t _n = 0;
};为什么需要精确的模板参数?
迭代器模板:
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct HashTableIterator { ... };-
每个模板实例都是独立类型:
-
HashTableIterator<K,T,T&,T*,...>≠HashTableIterator<K,T,const T&,const T*,...>
-
-
必须为每个需要访问的迭代器变体单独声明友元
-
通用模板友元(
template <class...> friend struct ...)可能过度暴露
问题2: 循环依赖问题
-
迭代器需要
HashTable:迭代器类中使用了HashTable类型别名 (using HT = HashTable<...>;) -
HashTable需要迭代器:HashTable类中声明迭代器为友元 -
这种相互引用形成了编译器的循环依赖问题
解决方案:前置声明
在迭代器类定义之前添加:
// HashTable的前置声明
template <class K, class T, class KeyOfT, class Hash>
class HashTable;为什么需要前置声明?
编译顺序要求
-
编译器需要知道
HashTable是一个有效类型名 -
在迭代器中使用
const HT* _ht时:-
HT是HashTable<...>的别名 -
但此时
HashTable尚未完整定义
-
-
前置声明告诉编译器:
"
HashTable是一个有效的类模板,稍后会有完整定义"
迭代器接口实现
typedef typename HashTableIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;
typedef typename HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash> ConstIterator;Iterator Begin()
{// 处理空表的情况if (_n == 0) return End();// 找到第一个非空桶for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){//return Iterator(_tables[i], this);return { _tables[i], this }; // 隐式类型转换}}return End();
}Iterator End()
{//return Iterator(nullptr, this);return { nullptr, this }; // 隐式类型转换
}ConstIterator Begin() const
{// 处理空表的情况if (_n == 0) return End();// 找到第一个非空桶for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return { _tables[i], this }; // 隐式类型转换}}return End();
}ConstIterator End() const
{return { nullptr, this }; // 隐式类型转换
}1. 迭代器类型别名
typedef typename HashTableIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;
typedef typename HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash> ConstIterator;-
目的:定义普通迭代器和常量迭代器的类型别名
-
模板参数解析:
-
K:键类型 -
T:节点存储的数据类型 -
Ref:T&(普通引用)或const T&(常量引用) -
Ptr:T*(普通指针)或const T*(常量指针) -
KeyOfT:键提取函子 -
Hash:哈希函数类型
-
-
typename关键字:指示HashTableIterator是一个类型(模板依赖名称)
2. 普通迭代器 Begin()
Iterator Begin()
{// 处理空表的情况if (_n == 0) return End(); // 元素数量为0时直接返回end()// 找到第一个非空桶for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]) // 发现非空桶{return { _tables[i], this }; // 构造迭代器}}return End(); // 理论上不会执行到这里
}逻辑解析:
-
空表检查:
-
_n == 0:检查元素数量(避免无效遍历) -
直接返回
End()迭代器(nullptr+this)
-
-
查找第一个有效节点:
-
线性扫描桶数组
_tables -
返回第一个非空桶的头节点迭代器
-
-
返回值优化:
-
使用统一初始化
{ _tables[i], this } -
等价于
Iterator(_tables[i], this) -
更简洁且避免拷贝
-
3. 普通迭代器 End()
Iterator End()
{return { nullptr, this }; // 统一的尾后迭代器
}核心设计:
-
返回特殊标记的迭代器:
-
_node = nullptr(表示无效节点) -
_ht = this(关联当前哈希表)
-
-
所有结束位置统一表示
4. 常量迭代器 Begin() const
ConstIterator Begin() const
{if (_n == 0) return End(); // 空表处理for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return { _tables[i], this }; // 返回const迭代器}}return End();
}关键区别:
-
const成员函数:可在常量对象上调用 -
返回
ConstIterator而非Iterator -
隐式构造常量迭代器:
{ _tables[i], this }→ConstIterator
5. 常量迭代器 End() const
ConstIterator End() const
{return { nullptr, this }; // 常量尾后迭代器
}设计特点:
-
与普通
End()对称 -
返回常量版本的尾后迭代器
2.3 map 支持 [] 操作符
修改 HashTable 的 insert 返回值
• 为了支持 unordered_map 的 [] 操作,需要对 insert 方法进行修改,使其返回值为:
pair<Iterator, bool> Insert(const T& data)其中:
Iterator指向被插入的元素(或已存在的元素)bool表示是否成功插入新元素(true 表示新插入,false 表示已存在)
• 实现 [] 操作符的关键在于 insert 方法的改造,具体实现可参考以下代码
pair<Iterator, bool> Insert(const T& data)
{KeyOfT kot;// 存在就插入失败Iterator ret = Find(kot(data));if (ret != End()) return { ret, false };Hash hash;// 负载因子等于1时扩容if (_n == _tables.size()){vector<Node*> newtables(__stl_next_prime(_tables.size()) + 1);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = hash(kot(cur->_data)) % newtables.size();cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}size_t hashi = hash(kot(data)) % _tables.size();// 头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return { Iterator(newnode, this), true };
}Iterator Find(const K& key)
{KeyOfT kot;Hash hash;size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return Iterator(cur, this);}cur = cur->_next;}return End();
}[] 运算符的实现原理
[] 运算符的行为是:
- 如果键存在,返回对应的值引用
- 如果键不存在,插入该键并返回新值的引用
V& operator[](const K& key)
{pair<iterator, bool> ret = insert({ key, V() });//ret.first:iterator,再通过->操作符返回键对应的值的引用return ret.first->second;
}2.4 UnorderedMap的完整实现
直接复用底层哈希表的接口
namespace RO
{template<class K, class V, class Hash = HashFunc<K>>class UnorderedMap{struct MapKeyOfT{const K& operator()(const pair<K, V>& key){return key.first;}};public:typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}V& operator[](const K& key){pair<iterator, bool> ret = insert({ key, V() });//ret.first:iterator,再通过->操作符返回键对应的值的引用return ret.first->second;}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}private:HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};}2.5 UnorderedSet的完整实现
namespace RO
{template<class K, class Hash = HashFunc<K>>class UnorderedSet{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;typedef typename HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}private:HashTable<K, const K, SetKeyOfT, Hash> _ht;};
}2.6 测试
测试UnorderedMap
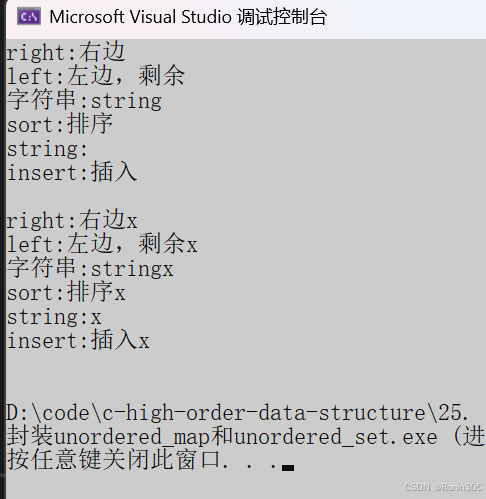
void test_map1()
{UnorderedMap<string, string> dict;dict.insert({ "sort", "排序" });dict.insert({ "字符串", "string" });dict.insert({ "sort", "排序" });dict.insert({ "left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余";dict["insert"] = "插入";dict["string"];for (auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}cout << endl;UnorderedMap<string, string>::iterator it = dict.begin();while (it != dict.end()){// 不能修改first,可以修改second//it->first += 'x';it->second += 'x';cout << it->first << ":" << it->second << endl;++it;}cout << endl;
}运行结果:
测试UnorderedSet
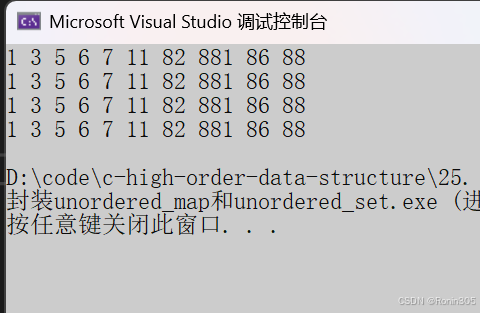
void print(const UnorderedSet<int>& s)
{UnorderedSet<int>::const_iterator it = s.begin();while (it != s.end()){//*it = 1;cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;
}void test_set1()
{int a[] = { 3,11,86,7,88,82,1,881,5,6,7,6 };UnorderedSet<int> s;for (auto e : a){s.insert(e);}UnorderedSet<int>::iterator it = s.begin();while (it != s.end()){//*it = 1;cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;print(s); // 测试const迭代器
}运行结果:
源代码
HashTable.h
#pragma once
#include <vector>
#include <string>
using namespace std;template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& s){// BKDRsize_t hash = 0;for (auto ch : s){hash += ch;hash *= 131;}return hash;}
};inline unsigned long __stl_next_prime(unsigned long n)
{// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}template<class T>
struct HashNode
{HashNode(const T& data):_data(data), _next(nullptr){}T _data;HashNode<T>* _next;
};// 前置声明
template<class K, class T, class KeyOfT, class Hash>
class HashTable;template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct HashTableIterator
{using Node = HashNode<T>;using HT = HashTable<K, T, KeyOfT, Hash>;using Self = HashTableIterator<K, T, Ref, Ptr, KeyOfT, Hash>;Node* _node;const HT* _ht; // 为满足const迭代器的不可修改的特性,这里也得加上constHashTableIterator(Node* node, const HT* ht):_node(node),_ht(ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& tmp){return _node != tmp._node;}bool operator==(const Self& tmp){return _node == tmp._node;}Self& operator++(){// 处理空表情况,防止除0错误if (_ht->_tables.empty()){_node = nullptr;return *this;}if (_node->_next){// 当前桶还有数据_node = _node->_next;}else // 跨桶查找{// 计算当前桶的索引KeyOfT kot;Hash hash;size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();// 向后查找非空桶while (++hashi < _ht->_tables.size()){_node = _ht->_tables[hashi];if (_node) break;}// 所有桶都走完了,end()为空标识符的_nodeif (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}Self operator++(int){Self tmp = *this;++(*this);// 复用前置++return tmp;}
};template<class K, class T, class KeyOfT, class Hash>
class HashTable
{// 过度暴露/*template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct HashTableIterator;*/// 更精确的友元声明(推荐)friend struct HashTableIterator<K, T, T&, T*, KeyOfT, Hash>; // 普通迭代器friend struct HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash>; // const迭代器using Node = HashNode<T>;
public:typedef typename HashTableIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;typedef typename HashTableIterator<K, T, const T&, const T*, KeyOfT, Hash> ConstIterator;Iterator Begin(){// 处理空表的情况if (_n == 0) return End();// 找到第一个非空桶for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){//return Iterator(_tables[i], this);return { _tables[i], this }; // 隐式类型转换}}return End();}Iterator End(){//return Iterator(nullptr, this);return { nullptr, this }; // 隐式类型转换}ConstIterator Begin() const{// 处理空表的情况if (_n == 0) return End();// 找到第一个非空桶for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return { _tables[i], this }; // 隐式类型转换}}return End();}ConstIterator End() const{return { nullptr, this }; // 隐式类型转换}HashTable():_tables(__stl_next_prime(0))//:_tables(11){}HashTable(const HashTable& ht):_tables(ht._tables.size()), _n(ht._n){for (size_t i = 0; i < ht._tables.size(); i++){Node* cur = ht._tables[i];Node* tail = nullptr; // 方便尾插while (cur){Node* newnode = new Node(cur->_data);// 处理头节点if (_tables[i] == nullptr){_tables[i] = tail = newnode;}else{// 尾插tail->_next = newnode;tail = tail->_next;}cur = cur->_next;}}}// 现代写法HashTable& operator=(HashTable ht){_tables.swap(ht._tables);swap(_n, ht._n);return *this;}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}pair<Iterator, bool> Insert(const T& data){KeyOfT kot;// 存在就插入失败Iterator ret = Find(kot(data));if (ret != End()) return { ret, false };Hash hash;// 负载因子等于1时扩容if (_n == _tables.size()){vector<Node*> newtables(__stl_next_prime(_tables.size()) + 1);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = hash(kot(cur->_data)) % newtables.size();cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}size_t hashi = hash(kot(data)) % _tables.size();// 头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return { Iterator(newnode, this), true };}Iterator Find(const K& key){KeyOfT kot;Hash hash;size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return Iterator(cur, this);}cur = cur->_next;}return End();}bool Erase(const K& key){KeyOfT kot;Hash hash;size_t hashi = hash(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){if (prev == nullptr){// 头节点_tables[hashi] = cur->_next;}else{// 中间节点prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}
private:vector<Node*> _tables; // 桶数组(存储链表头指针)size_t _n = 0;
};
UnorderedMap.h
#pragma once
#include "HashTable.h"namespace RO
{template<class K, class V, class Hash = HashFunc<K>>class UnorderedMap{struct MapKeyOfT{const K& operator()(const pair<K, V>& key){return key.first;}};public:typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}V& operator[](const K& key){pair<iterator, bool> ret = insert({ key, V() });//ret.first:iterator,再通过->操作符返回键对应的值的引用return ret.first->second;}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}private:HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};void test_map1(){UnorderedMap<string, string> dict;dict.insert({ "sort", "排序" });dict.insert({ "字符串", "string" });dict.insert({ "sort", "排序" });dict.insert({ "left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余";dict["insert"] = "插入";dict["string"];for (auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}cout << endl;UnorderedMap<string, string>::iterator it = dict.begin();while (it != dict.end()){// 不能修改first,可以修改second//it->first += 'x';it->second += 'x';cout << it->first << ":" << it->second << endl;++it;}cout << endl;}
}UnorderedSet,h
#pragma once
#include "HashTable.h"namespace RO
{template<class K, class Hash = HashFunc<K>>class UnorderedSet{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;typedef typename HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin() const{return _ht.Begin();}const_iterator end() const{return _ht.End();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}private:HashTable<K, const K, SetKeyOfT, Hash> _ht;};void print(const UnorderedSet<int>& s){UnorderedSet<int>::const_iterator it = s.begin();while (it != s.end()){//*it = 1;cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;}void test_set1(){int a[] = { 3,11,86,7,88,82,1,881,5,6,7,6 };UnorderedSet<int> s;for (auto e : a){s.insert(e);}UnorderedSet<int>::iterator it = s.begin();while (it != s.end()){//*it = 1;cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;print(s); // 测试const迭代器}
}