pandas随笔
主要操作两个对象:一维带标签数组 和 二维表格DataFrame
一维带标签数组Series
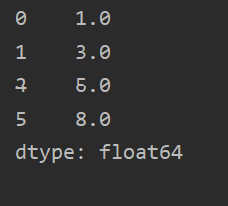
pd.Series([1, 3, 5, np.nan, 6, 8]) ,结果如下:
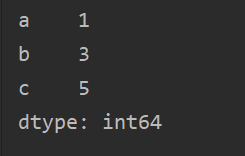
可指定索引,pd.Series([1, 3, 5], index=['a', 'b', 'c'])
二维表格DataFrame
创建时需要指定列名,如
字典创建
data = {'姓名': ['Alice', 'Bob', 'Charlie'],'年龄': [25, 30, 35],'评分': [85.5, 90.0, 88.5]
}
df = pd.DataFrame(data)
列表创建
列表不像字典,需额外指定列名
data = [['Alice', 25, 85.5],['Bob', 30, 90.0],['Charlie', 35, 88.5]
]
columns = ['姓名', '年龄', '评分']
df = pd.DataFrame(data, columns=columns,index=[索引内容])index:指定行索引,为一个列表类型,长度要匹配,可以省去。默认行索引为0,1,2......
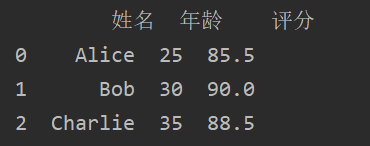
上面两种方式结果都如下
表格数据统计
head(n) 查看前n行数据
tail(n) 查看后n行数据
shape 查看行数、列数
cloumns 查看列名
describe() 统计摘要(计数、均值、标准差等)
info() 查看基本信息
corr() 列与列的相关系数
简单可视化实现(用到pyplot)
将表中的单独一行,或单独一列数据拿出来绘制图表
df[' 列名 '].plot() #找出某行数据,以行为x轴
df.loc[' 行索引 '].plot #找出某行数据,以列为x轴
最后plt.show()即可
表格数据筛选与过滤
索引查找
按列名索引 df [ '年龄' ]
按位置索引(整数) df.iloc [ '0' ] #第一行 df.iloc [ 1:3,0:2 ] #第2-3行,第1-2列(左闭右开)
按标签索引 df.loc [df['年龄'] > 30] # 筛选年龄>30的行
df.loc [ :, ['姓名', '评分']] # 选取指定列
按指定位置索引 df.loc ['行索引', ['A', 'B']] #指定行+列,若表数据未指定行索引, #默认按 0,1,2.....来
筛选查找
年龄>30且评分>88的
filtered = df[(df['年龄'] > 30) & (df['评分'] > 88)]
上面方法查找到的数据,定位到之后可直接进行赋值修改
唯一值与去重
unique_names = df['姓名'].unique() # 列中唯一值
df.drop_duplicates(subset=['姓名']) # 按列去重
sort_values(by= '评分' ,ascending=False) 按评分降序排列,为True时升序
数据清洗
查找无效值,并填充NaN
isnull() 显示无效值信息
fillna(value=0, inplace=True) 填充缺失值,inplace=False时默认填充NAN,也可以value='NaN'
删除缺失信息的行
dropna(subset=[ '评分' ])
依次检测subset中的列 ,将每列中有NaN值存在的所在行进行删除
一般要先进行数据清洗,将表中的空值和None值 转换为NaN,dropna只针对NaN值进行删除
drop(columns=['年龄差值'], inplace=True) 删除整列
df[ '年龄' ].astype( 'int' ) 转换为整数类型
df.[ '评分' ].round(1) 保留1位小数
df['年龄差值'] = df['年龄'] - df['年龄'].min() 新增列(基于现有列计算)
分组
groupby( '年龄' ) 按年龄进行分组
df.groupby('年龄')['评分'].mean() #在年龄这一组,计算评分的平均值groupby( '年龄' ).agg 按年龄这一组,进行多列分组聚合
df.groupby('年龄').agg({'评分': 'mean','姓名': 'count'
})表格关联合并
表单数据进行合并连接,这里使用内连接为例,数据库内连接、外连接不懂得可以去自行查阅
merge(df1, df2, on = 'ID' ,how = 'inner' )
df1 = pd.DataFrame({'ID': [1, 2, 3], '姓名': ['Alice', 'Bob', 'Charlie']})
df2 = pd.DataFrame({'ID': [2, 3, 4], '成绩': [90, 85, 95]})# 内连接(基于ID列)
merged = pd.merge(df1, df2, on='ID', how='inner')强拼接,按维度直接进行强拼接(比较生硬)
concat([ df1, df2 ], axis =0) 按行进行拼接,axis=1 为按列
导出/读入数据
- to_csv( '文件路径+名称 .csv', index = False )
- 保存为csv文件,index=False表示不保存行索引
- to_excel( '文件路径+名称 .xlsx' , sheet_name = '表名', index = False)
- sheet_name 设置表格的名称,默认为Sheet1,index 表示是否保存行索引
- read_csv( '文件路径+名称 .csv' )
- read_excel( '文件路径+名称 .xlsx' , sheet_name = '表名')
- sheet_name:指定为文件中的哪一个工作表