基于KNN算法的入侵检测模型设计与实现【源码+文档】
基于KNN算法的入侵检测模型设计与实现
1、相关背景知识
1.1 KDD Cup 1999 数据集
KDD Cup 1999数据集是第3届知识发现与数据挖掘竞赛所使用的数据集。该数据 集来源于一个模拟的美国空军军事网络环境下的局域网流量数据,包含了多种网络攻击 与入侵行为。KDD Cup 1999通过记录上述局域网连续9周的原始TCP dump数据流量, 生成了大约700万条连接记录。每一条连接记录反映了某一时刻从源IP地址到目的 IP地址若干个数据包的传输情况。整个数据集分为训练数据集和测试数据集两部分。 训练数据集用于提取数据特征,生成数据挖掘模型;测试数据集用于验证模型的效率与 正确性。
KDD Cup 1999数据集对每一条连接记录都进行了分类(label).所有记录分为正常 (normal)与攻击(attack)两大类,其中攻击行为又可进一步分为以下4种类型:
(1)DOS:拒绝服务攻击,如SYN洪泛攻击。
(2)R2L:来自于远程主机的非法入侵,如猜测密码。
(3)U2R:非法获得本地主机的超级用户权限,如各种“缓冲区溢出”攻击。
(4)Probing:监视与探测,如端口打描。
除类别(label)以外,KDD Cup 1999数据集中的每一条连接记录还包含4J项属性。本 章共用到其中的18项属性(如表10 1所示)。其中,前3个属性为符号类型,其他属性为连 续类型。
表1-1 KDD Cup 1999数据记录的18项属性
| 名 称 | 类 型 | 说 明 |
| protocol type | symbolic | 协议类型 |
| Service | symbolic | 服务类型 |
| Flag | symbolic | 状态标志 |
| src_bytes | conti nuous | 源到目的字节数 |
| dst_bytes | continuous | 目的到源字节数 |
| num failed logins | continuous | 登录失败次数 |
| num_root | continuous | root用户权限存取次数 |
| Count | continuous | 两秒内连接相同主机的数 |
| srveount | continuous | 两秒内连接相同端口的数 |
| serror_rate | continuous | “REJ”错误的连接数比例 |
| same_srv_ratc | continuous | 连接到相同端口数的比例 |
| diff_srv_rate | continuous | 连接到不同端门数的比例 |
| dst_host_srv_count | continuous | 相同目的地相同端口连接数 |
| dst_host_same_srv_rat | continuous | 相同的地相同端口连接数比例 |
| dst host diff srv rate | continuous | 相同目的地不同端口连接数比例 |
| dst_host_sarne_src_port_rate | continuous | 相同目的地相同源端口连接比例 |
| dst_host srv diff host rate | continuous | 不同主机连接相同端打的比例 |
| dst host_srv_serror_rate | I continuous | 连接当前主机有so错误的比例 |
1.2 KDD Cup 1999 数据集
K最近邻(K-Nearest Neighbor,简称KNN)分类算法是数据挖掘分类技术中最简单常用的方法之一。所谓K最近邻,就是寻找K个最近的邻居的意思,每个样本都可以用它最接近的K个邻居来代表。
KNN分类算法是最近邻算法,字面意思就是寻找最近邻居,由Cover和Hart在1968年提出,简单直观易于实现。KNN分类算法的核心思想是从训练样本中寻找所有训练样本X中与测试样本距离(欧氏距离)最近的前K个样本(作为相似度),再选择与待分类样本距离最小的K个样本作为X的K个最邻近,并检测这K个样本大部分属于哪一类样本,则认为这个测试样本类别属于这一类样本。假设现在需要判断下图中的圆形图案属于三角形还是正方形类别,采用KNN算法分析如下:
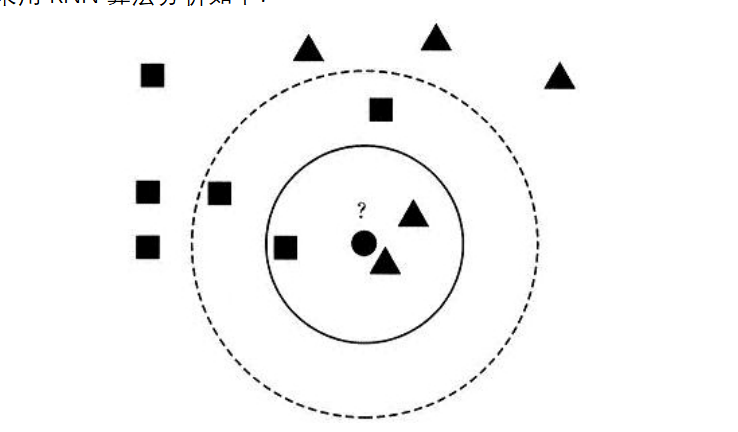
1.当K=3时,图中第一个圈包含了三个图形,其中三角形2个,正方形一个,该圆的则分类结果为三角形。
2.当K=5时,第二个圈中包含了5个图形,三角形2个,正方形3个,则以3:2的投票结果预测圆为正方形类标。总之,设置不同的K值,可能预测得到不同的结果。
KNN核心算法主要步骤包括五步:
加载数据集、划分数据集、KNN训练、评价算法、降维可视化
算法优化
为了入侵检测算法的优劣性,要对入侵检测算法KNN进行一个优化。
1、数值标准化
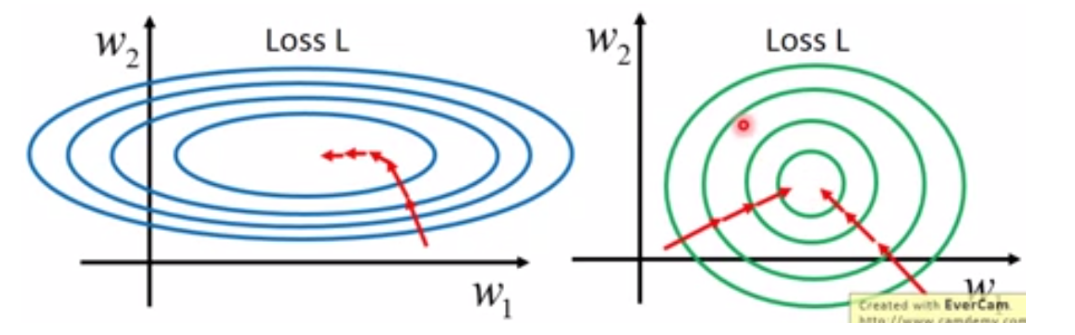
数据标准化主要是应对特征向量中数据很分散的情况,防止小数据被大数据(绝对值)吞并的情况。另外,数据标准化也有加速训练,防止梯度爆炸的作用。下面是两张截图图,左图表示未经过数据标准化处理的loss更新函数,右图表示经过数据标准化后的loss更新图。可见经过标准化后的数据更容易迭代到最优点,而且收敛更快。
在聚类\分类算法中,使用计算距离的方法对数据进行聚类\分类,而连接记录的固定特征属性中有两种类型的数值——离散型和连续型。对于连续型特征属性,各属性的度量方法不一样。一般而言,所用的度量单位越小,变量可能的值域就越大,这样对聚类结果的影响也越大,即在计算数据间距离时对聚类的影响越大,甚至会出现“大数”吃“小数”的现象。
因此为了避免对度量单位选择的依赖,消除由于属性度量的差异对聚类\分类产生的影响,需要对属性值进行标准化。对于离散型特征属性本文中并不作标准化处理,而是放在聚类算法中计算距离时处理。所以数据标准化是针对连续型特征属性的。
设训练数据集有n条网络连接记录,每个记录中有22个连续型属性向量记作 xij(1≤i≤n,11≤j≤41) 。对xij数据预处理分为两步:数值标准化和数值归一化。
Z-score标准化:
基于数据均值和方差的标准化化方法。标准化后的数据是均值为0,方差为1的正态分布。这种方法要求原始数据的分布可以近似为高斯分布,否则效果会很差。标准化公式如下: 其中,AVG为平均值,STAD为平均绝对偏差,如果AVG等于0,则X’=0;如果STD等于0,则X’=0。
其中,AVG为平均值,STAD为平均绝对偏差,如果AVG等于0,则X’=0;如果STD等于0,则X’=0。
2.数值归一化
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是常用的归一化方法:
min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 , 1]之间。转换函数如下:
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
3、最后要实现的功能有
- 针对上面标准化和归一化处理后的数据集,进行KNN算法分类
- 采用欧式距离计算,并绘制散点分布图(序列号、最小欧式距离、类标)
- ROC曲线评估