Google机器学习实践指南(机器学习模型泛化能力)
🔥 Google机器学习(14)-机器学习模型泛化能力解析
Google机器学习(14)-机器学习模型泛化原理与优化(约10分钟)
一、泛化问题引入
▲ 模型表现对比:
假设森林中树木健康状况预测模型:
-
图1:初始模型表现
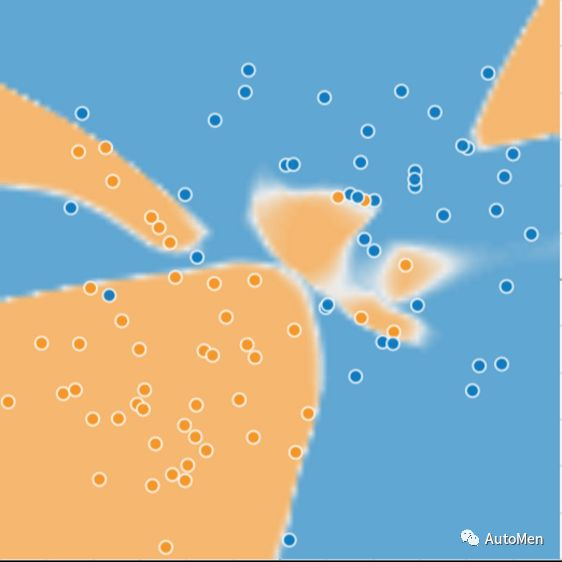
蓝点:生病树 | 橙点:健康树 | 模型边界:黑色曲线
-
图2:新增数据后的表现
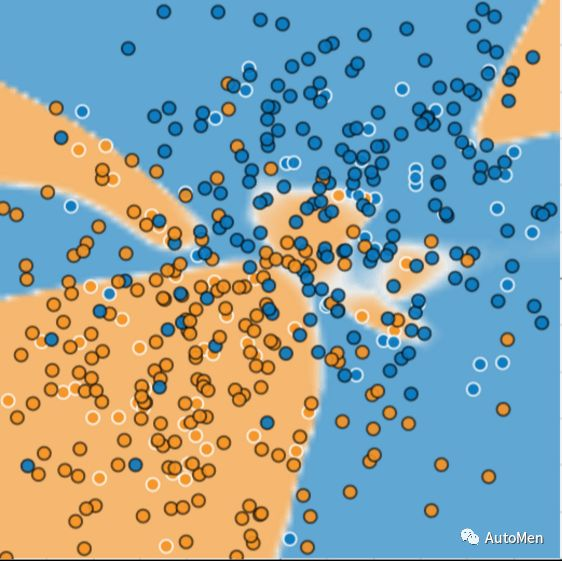
模型在新数据上表现糟糕,尽管训练损失很低
❓ 核心问题:
为什么低训练损失的模型在新数据上表现差?
二、泛化概念解析
泛化(Generalization)
机器学习模型的泛化能力指模型对未见过的数据的预测能力。即:
泛化能力 = 模型在新数据上的表现能力泛化误差 = E [ L ( f ( x ) , y ) ] ( L 为损失函数 ) 泛化能力 = 模型在新数据上的表现能力 泛化误差 = E[L(f(x), y)] (L为损失函数) 泛化能力=模型在新数据上的表现能力泛化误差=E[L(f(x),y)](L为损失函数)
泛化误差(Generalization Error)
所学习模型的期望风险,反映模型对未知数据预测的误差:
泛化误差 = E [ L ( f ( x ) , y ) ] ( L 为损失函数 ) 泛化误差 = E[L(f(x), y)] (L为损失函数) 泛化误差=E[L(f(x),y)](L为损失函数)
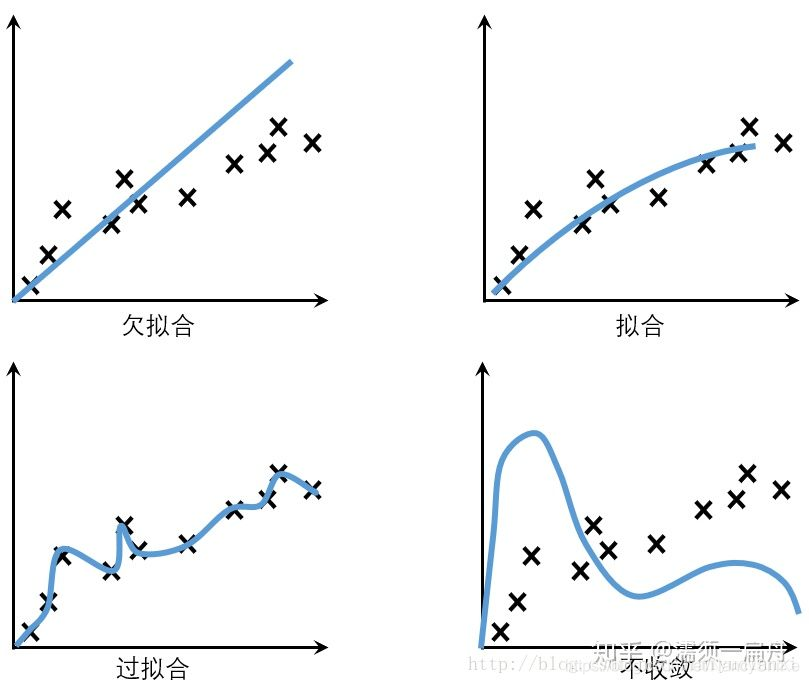
三、提高泛化能力的方法
1. 奥卡姆剃刀定律
“如无必要,勿增实体” - 优先选择更简单的模型
2. 关键策略
| 方法 | 原理 | 实现方式 |
|---|---|---|
| 增加数据量 | 减少样本偏差 | 数据增强/收集更多数据 |
| 降低模型复杂度 | 防止过拟合 | 减少网络层数/特征选择 |
| 正则化 | 约束参数空间 | L1/L2正则化/Dropout |
| 交叉验证 | 全面评估模型 | K折交叉验证 |
| 早停机制 | 防止过训练 | 监控验证集损失 |
四、数据集划分规范
标准数据划分
| 数据集 | 作用 | 比例 | 使用原则 |
|---|---|---|---|
| 训练集 | 模型参数学习 | 70-80% | 多次使用 |
| 验证集 | 超参数调整 | 10-15% | 有限使用 |
| 测试集 | 最终性能评估 | 10-15% | 仅使用一次 |
关键注意事项:
-
测试集必须与训练集互斥
-
避免反复使用相同测试集
-
测试集应足够大(>1000样本)
# 技术问答 #
Q:如何判断模型是否过拟合?
A:训练损失持续下降但验证损失开始上升时
Q:正则化参数如何选择?
A:通过验证集进行网格搜索(如λ∈[0.001,0.01,0.1,1])
Q:小数据集如何保证泛化能力?
A:采用K折交叉验证(K=5或10)
参考文献:
[1] 泛化能力深度解析
[2] Google机器学习-过拟合风险