DAY 23 pipeline管道
@浙大疏锦行![]() https://blog.csdn.net/weixin_45655710 知识回顾:
https://blog.csdn.net/weixin_45655710 知识回顾:
- 转化器和估计器的概念
- 管道工程
- ColumnTransformer和Pipeline类
作业:整理下全部逻辑的先后顺序,看看能不能制作出适合所有机器学习的通用pipeline
以心脏病数据集为例
没有pipline的代码
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings# 忽略警告信息,使输出更整洁
warnings.filterwarnings("ignore")# 设置中文字体,确保图表中的中文能够正常显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # SimHei是Windows下常用的黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示图表中的负号data = pd.read_csv('heart.csv')# --- 步骤 2: 数据探索与预处理 ---
# 心脏病数据集的特征通常是数值型的,或者已经是编码好的类别型数值。
# 我们将检查是否有明显的字符串类型需要编码,并处理缺失值。# 2.1 检查是否有字符串类型的特征需要处理
# (根据常见的心脏病数据集,大部分特征应该是数值型)
object_columns = data.select_dtypes(include=['object']).columns
if not object_columns.empty:print(f"发现字符串类型的列: {object_columns.tolist()}")print("请根据具体列的含义决定如何编码(例如标签编码或独热编码)。")# 示例:如果需要,可以在此处添加对特定对象列的编码逻辑# 例如: data['某个对象列'] = data['某个对象列'].astype('category').cat.codes
else:print("✅ 数据集中没有发现需要特殊编码的字符串类型列。")# 2.2 检查并处理缺失值
# 对于心脏病数据集,通常用中位数或均值填充数值型特征的缺失值
print("\n检查各列的缺失值数量:")
print(data.isnull().sum())# 筛选出数值类型的列(包括整数和浮点数)
numerical_features = data.select_dtypes(include=[np.number]).columns.tolist()if data.isnull().sum().sum() > 0: # 如果存在任何缺失值print("\n正在使用中位数填充数值型特征的缺失值...")for feature in numerical_features:if data[feature].isnull().any(): # 如果该列存在缺失值median_value = data[feature].median() # 计算中位数data[feature].fillna(median_value, inplace=True) # 用中位数填充from sklearn.model_selection import train_test_split
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集from sklearn.ensemble import RandomForestClassifier #随机森林分类器from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))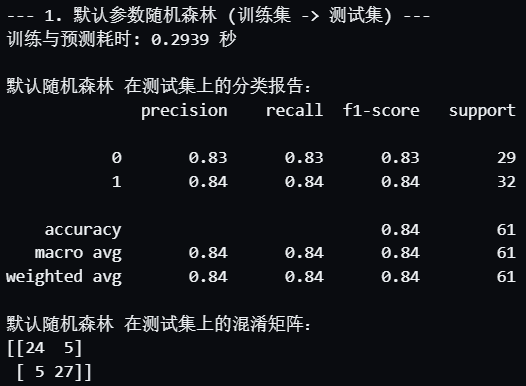
pipeline的代码教学
导入库和数据加载
# 导入基础库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time # 导入 time 库
import warnings# 忽略警告
warnings.filterwarnings("ignore")# 设置中文字体和负号正常显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 导入 Pipeline 和相关预处理工具
from sklearn.pipeline import Pipeline # 用于创建机器学习工作流
from sklearn.compose import ColumnTransformer # 用于将不同的预处理应用于不同的列
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler # 用于数据预处理(有序编码、独热编码、标准化)
from sklearn.impute import SimpleImputer # 用于处理缺失值# 导入机器学习模型和评估工具
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import classification_report, confusion_matrix # 用于评估分类器性能
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集# --- 加载原始数据 ---
# 我们加载原始数据,不对其进行任何手动预处理
data = pd.read_csv('heart.csv')print("原始数据加载完成,形状为:", data.shape)
print(data.head()) # 可以打印前几行看看原始数据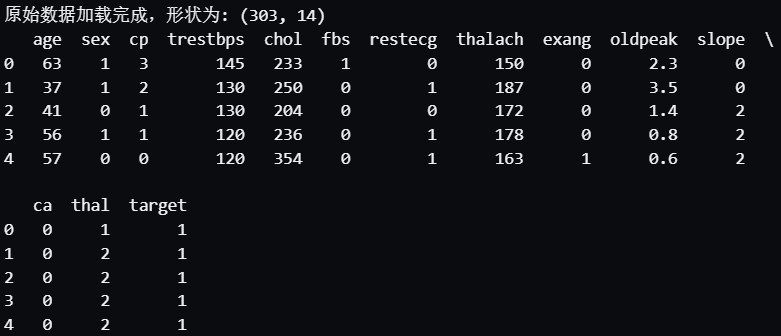
分离特征和标签,划分数据集
# --- 分离特征和标签 (使用原始数据) ---
y = data['target'] # 标签
X = data.drop(['target'], axis=1) # 特征 (axis=1 表示按列删除)print("\n特征和标签分离完成。")
print("特征 X 的形状:", X.shape)
print("标签 y 的形状:", y.shape)# --- 划分训练集和测试集 (在任何预处理之前划分) ---
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集print("\n数据集划分完成 (预处理之前)。")
print("X_train 形状:", X_train.shape)
print("X_test 形状:", X_test.shape)
print("y_train 形状:", y_train.shape)
print("y_test 形状:", y_test.shape) 
代码汇总
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time # 导入 time 库
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 防止负号显示问题# 导入 Pipeline 和相关预处理工具
from sklearn.pipeline import Pipeline # 用于创建机器学习工作流
from sklearn.compose import ColumnTransformer # 用于将不同的预处理应用于不同的列,之前是对datafame的某一列手动处理,如果在pipeline中直接用standardScaler等函数就会对所有列处理,所以要用到这个工具
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler # 用于数据预处理
from sklearn.impute import SimpleImputer # 用于处理缺失值# 机器学习相关库
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split # 只导入 train_test_split# --- 加载原始数据 ---
data = pd.read_csv('heart.csv')# --- 分离特征和标签 (使用原始数据) ---
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签# --- 划分训练集和测试集 (在任何预处理之前划分) ---
# X_train 和 X_test 现在是原始数据中划分出来的部分,不包含你之前的任何手动预处理结果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# --- 定义不同列的类型和它们对应的预处理步骤 (这些将被放入 Pipeline 的 ColumnTransformer 中) ---
# 这些定义是基于原始数据 X 的列类型来确定的# 识别原始的 object 列 (对应你原代码中的 discrete_features 在预处理前)
object_cols = X.select_dtypes(include=['object']).columns.tolist()# --- 2. 定义不同类型的特征列 ---
# 根据心脏病数据集的常见定义来划分特征# 数值型连续特征
# 这些特征的值是连续的,可以进行比较和度量
continuous_features = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']# 类别型特征 (虽然它们是数字,但代表类别,没有大小顺序关系)
# 我们将对这些特征进行独热编码
nominal_features = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal']# --- 3. 构建特征处理的 Pipelines ---
# 在这个心脏病数据集中,我们主要有两类特征:连续型和类别型。# 构建处理连续特征的 Pipeline:
# 步骤1: 用中位数填充可能存在的缺失值 (更稳健的选择)
# 步骤2: 标准化数据,使其均值为0,方差为1
continuous_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())
])# 构建处理类别特征的 Pipeline:
# 步骤1: 用众数填充可能存在的缺失值
# 步骤2: 进行独热编码,将每个类别转换为一个新列
nominal_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])# --- 4. 使用 ColumnTransformer 组合所有处理步骤 ---
# ColumnTransformer 可以将不同的处理 Pipeline 应用到不同的列上
preprocessor = ColumnTransformer(transformers=[('num', continuous_transformer, continuous_features),('cat', nominal_transformer, nominal_features)],remainder='passthrough' # 保留未被指定的列(如果有的话),默认为'drop'
)# --- 5. 应用预处理器到数据上 ---
# 现在,你可以将这个 preprocessor 应用到你的特征数据X上
# 这通常在机器学习模型的 Pipeline 中完成,或者直接转换数据
# 例如:
# X_processed = preprocessor.fit_transform(X)
# print(f"\n预处理后的数据形状: {X_processed.shape}")
# print("这个 X_processed 就可以用于训练模型了。")# 为了演示,我们可以直接在X上应用它
X_processed = preprocessor.fit_transform(X)# --- 构建完整的 Pipeline ---
# 将预处理器和模型串联起来
# 使用你原代码中 RandomForestClassifier 的默认参数和 random_state,这里的参数用到了元组这个数据结构
pipeline = Pipeline(steps=[('preprocessor', preprocessor), # 第一步:应用所有的预处理 (ColumnTransformer)('classifier', RandomForestClassifier(random_state=42)) # 第二步:随机森林分类器
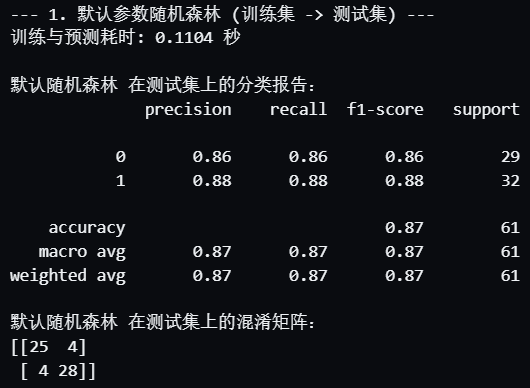
])# --- 1. 使用 Pipeline 在划分好的训练集和测试集上评估 ---print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
start_time = time.time() # 记录开始时间# 在原始的 X_train 上拟合整个Pipeline
# Pipeline会自动按顺序执行preprocessor的fit_transform(X_train),然后用处理后的数据拟合classifier
pipeline.fit(X_train, y_train)# 在原始的 X_test 上进行预测
# Pipeline会自动按顺序执行preprocessor的transform(X_test),然后用处理后的数据进行预测
pipeline_pred = pipeline.predict(X_test)end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒") # 使用你原代码的输出格式print("\n默认随机森林 在测试集上的分类报告:") # 使用你原代码的输出文本
print(classification_report(y_test, pipeline_pred))
print("默认随机森林 在测试集上的混淆矩阵:") # 使用你原代码的输出文本
print(confusion_matrix(y_test, pipeline_pred))
-
特征分类的改变:
- 没有有序分类特征:在标准的心脏病数据集中,像
cp(胸痛类型) 或thal(地中海贫血) 这类虽然是用数字表示,但数字本身没有大小顺序关系(例如,类型3不一定比类型2“好”或“差”)。因此,我们没有使用OrdinalEncoder。 - 连续特征与类别特征的重新定义:我们根据特征的医学含义,将
age,trestbps,chol等定义为连续特征,将sex,cp,fbs等定义为类别特征。这是处理此数据集的关键一步。
- 没有有序分类特征:在标准的心脏病数据集中,像
-
Pipeline 的简化:
- 由于只有两种特征类型(连续型和类别型),我们将原有的三个
transformer简化为两个:continuous_transformer和nominal_transformer。 nominal_transformer在此数据集中负责处理所有非连续的特征,对它们进行独热编码,因为这是处理无序类别特征最标准的方法。
- 由于只有两种特征类型(连续型和类别型),我们将原有的三个
-
核心工具
ColumnTransformer:- 代码的核心是使用
sklearn.compose.ColumnTransformer。这个工具非常强大,它可以接收一个列表,列表中每个元素都指定了 “要用哪个处理流程 (transformer) 来处理哪些列 (columns)”。 ('num', continuous_transformer, continuous_features): 表示对continuous_features列表中的列应用continuous_transformer。('cat', nominal_transformer, nominal_features): 表示对nominal_features列表中的列应用nominal_transformer。- 这样,一个
preprocessor对象就包含了对整个数据集所有特征的完整处理逻辑。
- 代码的核心是使用