NLP学习路线图(二十八):BERT及其变体
一、基石:Transformer架构解析
在Transformer之前,处理序列数据(尤其是文本)的主流模型是循环神经网络(RNN)及其变体LSTM、GRU。尽管这些模型能够处理序列依赖性,但存在两个根本性瓶颈:
-
顺序计算限制并行化: RNN必须逐时间步处理序列,无法充分利用现代GPU/TPU强大的并行计算能力,训练速度慢。
-
长距离依赖问题: 尽管LSTM/GRU通过门控机制缓解了梯度消失/爆炸问题,但在处理非常长的序列时,模型捕捉远距离词之间关系的能力仍然显著下降。
2017年,Google在论文《Attention is All You Need》中提出的Transformer架构,彻底摒弃了循环结构,完全依赖注意力机制(Attention Mechanism)来建立输入和输出中所有元素(词)之间的全局依赖关系。
Transformer的核心组件
-
自注意力机制(Self-Attention)
-
核心思想: 对于序列中的每一个元素(词),计算它与序列中所有其他元素(包括自身)的关联程度(权重)。这种关联度决定了在编码或解码当前元素时,应该“关注”序列中其他元素的多少信息。
-
计算过程 (简化):
-
将每个词的嵌入向量
X分别乘以三个不同的权重矩阵W_Q,W_K,W_V,得到该词的 Query向量 (Q), Key向量 (K), Value向量 (V)。 -
计算注意力分数:对于目标词
i的Q_i和序列中所有词j的K_j计算点积Score_ij = Q_i · K_j^T(衡量i与j的关联度)。 -
缩放:将
Score_ij除以√(d_k)(d_k是 Key 向量的维度),防止点积结果过大导致梯度不稳定。 -
归一化:对缩放后的
Score_ij应用 Softmax 函数,得到归一化的注意力权重α_ij(所有j对应的α_ij和为 1)。 -
加权求和:用
α_ij对各个词j的V_j向量进行加权求和,得到目标词i的输出向量Z_i = Σ(α_ij * V_j)。
-
-
意义:
Z_i融合了序列中所有词的信息,但其权重α_ij由i与j的关联度动态决定。模型可以同时关注序列中所有位置的信息,完美解决了长距离依赖问题,且计算高度并行化。
-
-
多头注意力(Multi-Head Attention)
-
将
Q,K,V通过不同的线性投影切分成h个头(例如 8 个头)。在每个头上独立地进行自注意力计算。然后将h个头的结果拼接起来,再通过一个线性层映射回原始维度。 -
优势: 允许模型在不同子空间(representation subspaces)中学习不同的关系模式(例如,一个头关注语法依赖,另一个头关注指代关系),极大地增强了模型的表征能力。
-
-
位置编码(Positional Encoding)
-
由于 Transformer 本身没有循环或卷积结构,它无法感知序列中词的位置顺序。需要显式地将位置信息注入到输入中。
-
常用方法:使用正弦和余弦函数生成与位置相关的固定向量,加到词的嵌入向量上。这些编码能让模型学习到相对位置和绝对位置的信息。
-
-
前馈神经网络(Feed-Forward Network, FFN)
-
对自注意力层的输出进行进一步的非线性变换。通常包含两个线性层和一个激活函数(如 ReLU 或 GELU):
FFN(x) = max(0, xW1 + b1)W2 + b2。 -
作用:增加模型的非线性能力和表征空间。
-
-
层归一化(Layer Normalization)和残差连接(Residual Connection)
-
残差连接: 将子层(如自注意力层、FFN层)的输入直接加到其输出上:
Output = Sublayer(x) + x。有效缓解了深层网络训练中的梯度消失问题,使训练更稳定。 -
层归一化: 对残差连接后的结果进行归一化(通常对每个样本的特征维度进行归一化),加速训练收敛。
-
Transformer架构图景
-
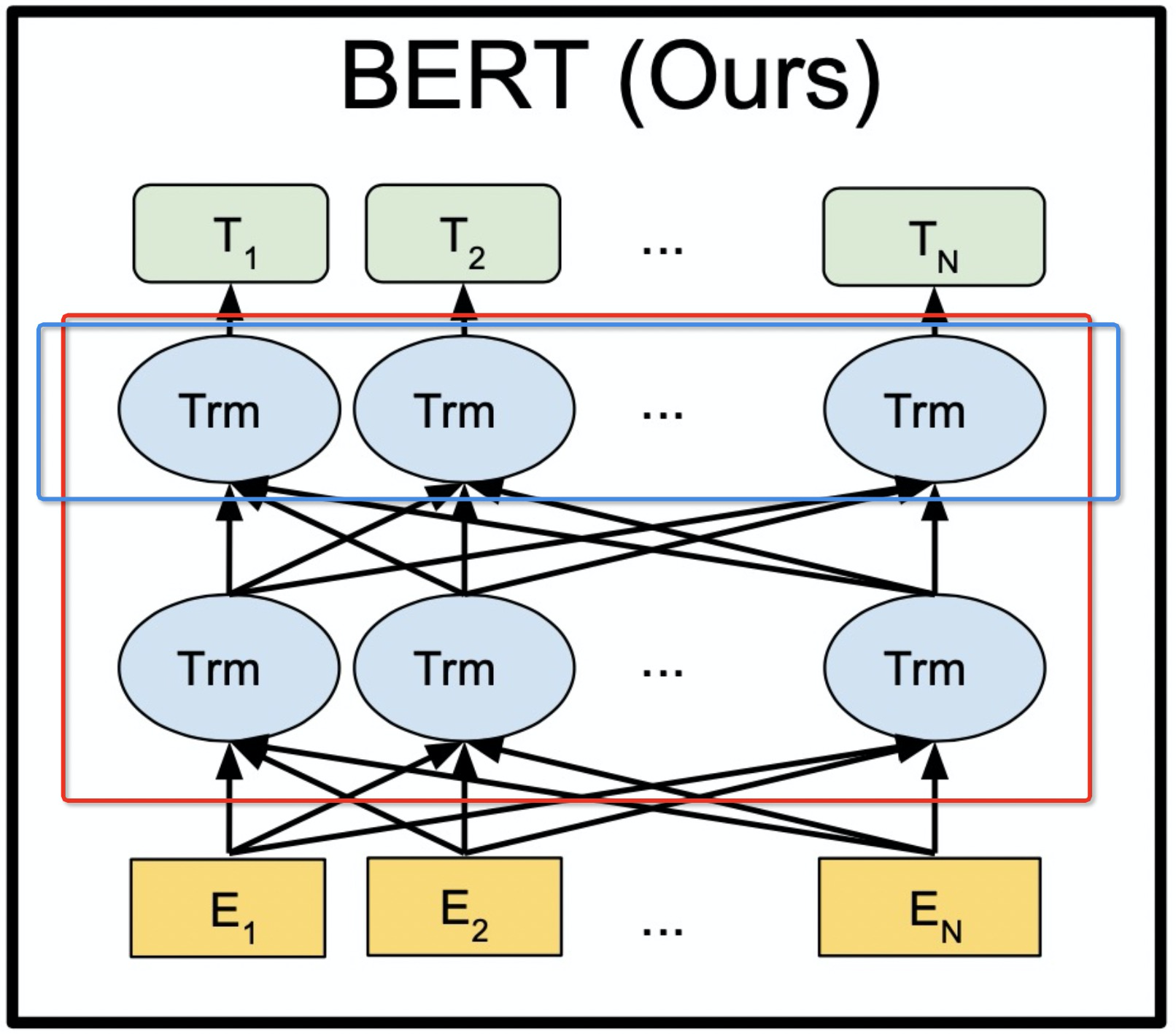
编码器(Encoder): 由
N个(如 6 或 12)相同的层堆叠而成。每层包含一个多头自注意力子层和一个FFN子层,每个子层前后都有残差连接和层归一化。编码器的作用是将输入序列(源语言句子)编码成一个蕴含丰富上下文信息的向量序列。 -
解码器(Decoder): 同样由
N个相同的层堆叠。除了包含带掩码的多头自注意力子层(防止解码时看到未来信息)和FFN子层外,每层还插入一个多头编码器-解码器注意力子层(接收编码器输出)。解码器根据编码器输出和已生成的目标序列部分,自回归地预测下一个词。
二、革命:BERT横空出世
虽然Transformer在机器翻译等序列到序列任务上取得了巨大成功,但如何将其强大的表征能力迁移到更广泛的NLP任务(如文本分类、问答、命名实体识别等)上,仍需有效的方法。
2018年底,Google AI团队推出的BERT(Bidirectional Encoder Representations from Transformers),标志着NLP进入“预训练+微调”的新范式时代。
BERT的核心思想
-
使用Transformer编码器: BERT仅使用了Transformer的编码器部分。这意味着它专注于学习输入文本本身的深度双向表示。
-
深度双向上下文建模: 这是BERT区别于之前模型(如ELMo、GPT)的关键。之前的模型要么是单向的(如从左到右的GPT),要么是浅层双向拼接(如ELMo)。BERT利用Transformer的自注意力机制,在预训练过程中,允许每个词同时关注其左侧和右侧的所有上下文信息,从而学习到真正意义上的深层双向语境表示。
-
预训练(Pre-training) + 微调(Fine-tuning)范式:
-
预训练: 在海量无标注文本语料库(如BooksCorpus, Wikipedia)上,通过设计自监督学习任务,训练一个通用的语言理解模型。BERT在这个阶段学习到了丰富的语言知识和世界知识。
-
微调: 将预训练好的BERT模型,针对特定的下游NLP任务(如情感分析、问答),在相对较小的标注数据集上进行额外的少量训练。通常只需要在BERT的输出层之上添加一个简单的任务相关层(如一个分类层),然后微调所有参数或部分参数。
-
BERT的预训练任务
BERT设计了两个巧妙的预训练任务,迫使模型学习深层次的语义和句法关系:
-
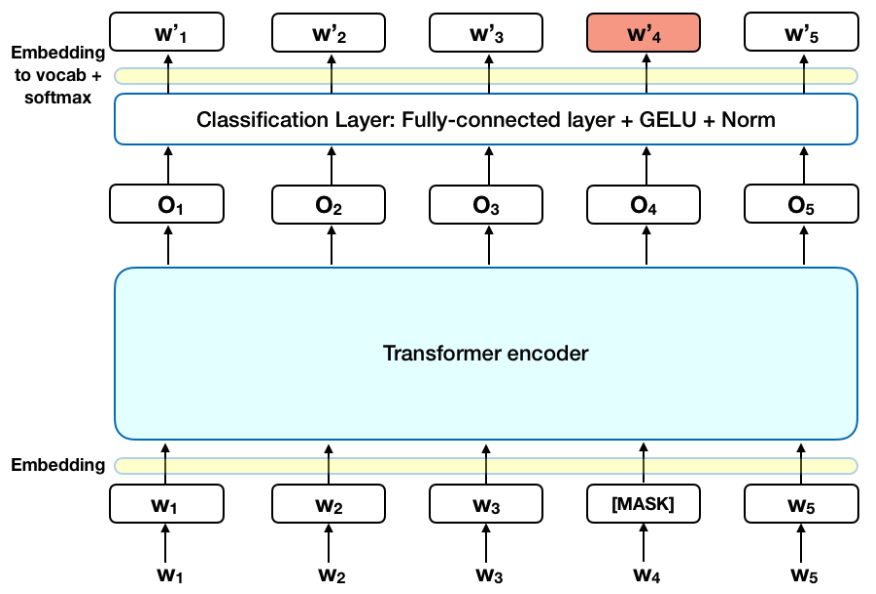
掩码语言模型(Masked Language Model, MLM)
-
在输入序列中,随机“掩码”(遮盖)掉一定比例(如15%)的词。
-
这些被掩码的词,80%被替换为一个特殊的
[MASK]token,10%被随机替换为其他词,10%保持不变。 -
模型的任务是预测这些被掩码位置上的原始词是什么。
-
核心作用: 迫使模型理解双向上下文信息,才能准确预测被掩盖的词。随机替换和不替换的设置增加了模型的鲁棒性。
-
-
下一句预测(Next Sentence Prediction, NSP)
-
模型接收两个句子
A和B作为输入。 -
50%的情况下,
B是A在原始文档中的下一个句子(正例IsNext)。 -
50%的情况下,
B是从语料库中随机抽取的句子(负例NotNext)。 -
模型的任务是预测
B是否是A的下一句。 -
核心作用: 学习句子间的关系,这对于理解问答(QA)、自然语言推理(NLI)等需要推理多个句子之间关系的任务至关重要。
-
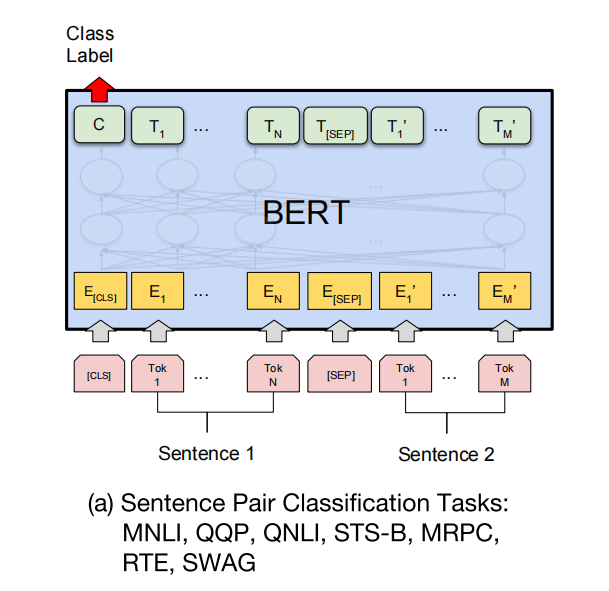
BERT的输入表示
BERT的输入表示融合了三种嵌入信息:
-
Token Embeddings: 词(或子词,WordPiece)的嵌入向量。
-
Segment Embeddings: 用于区分输入中的不同句子(例如,对于句子对任务,句子A为0,句子B为1)。
-
Position Embeddings: Transformer的位置编码,表示词在序列中的位置。
输入以一个特殊的[CLS]token开头(其最终输出常用于分类任务),句子之间用[SEP]token分隔。
BERT的威力与影响
-
刷新记录: BERT在发布时,在11项NLP基准任务上取得了当时最优(state-of-the-art)的成绩,包括GLUE(通用语言理解评估)、SQuAD(问答)、SWAG(常识推理)等。
-
范式革命: “预训练+微调”成为NLP领域的新标准流程。开发者不再需要为每个特定任务从头设计复杂的网络结构,只需下载预训练好的BERT模型,进行少量微调即可获得优异性能。
-
普及应用: BERT及其变体被广泛应用于搜索引擎、聊天机器人、情感分析、机器翻译、文本摘要、信息抽取、内容推荐等众多场景。
三、进化:BERT的变体家族
BERT的巨大成功激发了研究者们对其进行改进和扩展的热情,催生了一个庞大的BERT变体家族。这些变体主要从以下几个方向进行优化:
1. 模型效率优化(更小、更快)
-
DistilBERT:
-
核心: 知识蒸馏(Knowledge Distillation)。
-
方法: 训练一个小型学生模型(DistilBERT)去模仿大型教师模型(BERT-base)的输出(预测概率分布)。同时结合MLM损失。
-
效果: 模型体积减小40%,推理速度提升60%,性能保留教师模型97%的能力。非常适合资源受限场景。
-
-
TinyBERT:
-
核心: 分阶段知识蒸馏。
-
方法: 不仅在模型预测输出层进行蒸馏,还在中间隐藏层(Transformer层的输出、注意力矩阵)进行蒸馏,使学生模型更全面地学习教师模型的行为。
-
效果: 相比DistilBERT,在同等大小下性能更好。
-
-
MobileBERT:
-
核心: 专为移动设备优化。
-
方法:
-
使用瓶颈(bottleneck)结构和自注意力与前馈层之间的平衡设计减小模型尺寸。
-
通过逐层知识迁移(从大型教师模型到小型学生模型)和特征映射损失进行训练。
-
-
效果: 在移动端实现实时推理。
-
-
ALBERT (A Lite BERT):
-
核心: 通过参数共享和分解显著减小模型参数量。
-
方法:
-
跨层参数共享: 所有Transformer层的参数共享同一组权重(例如,注意力参数共享、FFN参数共享或全部共享)。极大减少参数量。
-
嵌入参数分解: 将大的词嵌入矩阵分解为两个小矩阵(例如,将
VxH分解为VxE和ExH,其中E << H)。显著减少词嵌入参数。 -
句子顺序预测(SOP)任务: 替代NSP任务。预测两个连续片段是否被交换了顺序,比NSP更能学习连贯性。
-
-
效果: 模型参数量大幅减少(例如 ALBERT-base 只有 12M 参数,而 BERT-base 有 110M),训练速度更快,内存占用更低,并在某些任务上性能超过BERT。
-
2. 模型性能优化(更强、更准)
-
RoBERTa (Robustly Optimized BERT Approach):
-
核心: 重新审视BERT的训练策略,进行更充分的训练和更优的超参数设置。
-
主要改进:
-
更大的批次(Batch Size)和更多的训练数据: 使用更大的批次(如 8K)和远超原始BERT的数据量(如 160GB)。
-
更长的训练时间: 训练更多步数(epochs)。
-
移除NSP任务: 发现NSP任务效果有限甚至有时有害,只保留MLM任务。
-
动态掩码(Dynamic Masking): 在训练过程中动态生成掩码模式,而不是在数据预处理时固定。相当于为相同数据提供了更多的掩码视图。
-
更长的序列: 支持训练更长的序列。
-
-
效果: 显著提升了BERT在多项基准任务上的性能,成为后续研究的重要基线。
-
-
ERNIE (Enhanced Representation through kNowledge IntEgration):
-
核心: 融入外部知识(尤其是中文)。
-
方法:
-
持续掩码策略: 不仅掩码单个词,还掩码命名实体(人名、地名、机构名)或短语(如“北京奥运会”),迫使模型学习更高级别的语义单元知识。
-
知识图谱融合(后期版本): 将结构化知识图谱信息融入预训练过程。
-
-
效果: 在中文任务上表现尤为突出,对实体和短语的理解更深入。
-
-
SpanBERT:
-
核心: 更好地建模文本片段(Span)。
-
方法:
-
随机连续掩码(Random Contiguous Span Masking): 不再随机掩码单个token,而是随机掩码连续的片段(span)。
-
片段边界目标(Span Boundary Objective, SBO): 利用片段边界处未被掩码的token来预测片段内被掩码token的原始内容。强化模型利用边界信息的能力。
-
-
效果: 在需要理解片段的任务(如抽取式问答、指代消解)上表现优于BERT。
-
3. 领域适配优化(更专)
-
BioBERT:
-
方法: 在通用语料(如Wikipedia, BooksCorpus)上预训练的BERT基础上,继续在生物医学领域的大规模文本(如PubMed摘要、全文)上进行领域适应预训练(Domain-Adaptive Pre-training)。
-
效果: 在生物医学文本挖掘任务(如命名实体识别、关系抽取)上性能显著优于通用BERT。
-
-
SciBERT:
-
方法: 类似于BioBERT,但针对更广泛的科学领域(包括计算机科学、生物医学等)进行预训练。其预训练语料来自科学出版物。
-
效果: 在各类科学文献处理任务上表现出色。
-
-
ClinicalBERT:
-
方法: 在临床电子健康记录(EHR)文本上进行领域适应预训练。
-
效果: 适用于医疗问答、临床实体识别、入院预测等医疗NLP任务。
-
4. 架构与任务创新
-
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately):
-
核心: 用更高效的替换token检测(Replaced Token Detection, RTD)任务替代MLM。
-
方法:
-
使用一个较小的生成器网络(通常是小型MLM)来随机替换输入序列中的某些token(类似于BERT的掩码,但替换成生成器预测的词)。
-
训练一个较大的判别器网络(ELECTRA主模型)来判别序列中的每个token是原始的还是被生成器替换的。
-
-
优势:
-
效率高: 判别任务学习每个token,比MLM只学习15%的token效率更高,样本利用率高。
-
性能强: 在相同计算开销下,性能通常优于BERT/RoBERTa。
-
-
-
DeBERTa (Decoding-enhanced BERT with Disentangled Attention):
-
核心: 改进注意力机制。
-
方法:
-
解耦注意力(Disentangled Attention): 将每个词的表示分解为内容向量和位置向量。计算注意力分数时,不仅考虑词内容之间的交互,还显式地考虑词内容与位置、位置与位置之间的交互。
-
增强的掩码解码器(Enhanced Mask Decoder, EMD): 在输出层引入绝对位置信息,帮助模型更好地预测被掩码词。
-
-
效果: DeBERTa及其后续版本(如DeBERTa V3)在多个基准测试(如SuperGLUE)上达到或接近SOTA水平。
-
变体概览表
| 变体名称 | 主要优化方向 | 关键技术/特点 | 主要优势 |
|---|---|---|---|
| DistilBERT | 效率(尺寸/速度) | 知识蒸馏 | 小体积,快推理,保留大部分性能 |
| TinyBERT | 效率(尺寸/速度) | 分层知识蒸馏 (输出层+中间层) | 在极小型号上性能优异 |
| MobileBERT | 效率(移动端) | 瓶颈结构 + 知识迁移 | 移动设备实时推理 |
| ALBERT | 效率(参数量) | 跨层参数共享 + 嵌入分解 + SOP任务 | 参数极少,内存占用低,训练快 |
| RoBERTa | 性能 | 更大数据/批次/步数 + 动态掩码 + 去NSP | 显著提升多项任务性能 |
| ERNIE | 性能(知识融入) | 实体/短语级掩码 + 知识图谱(后期) | 中文任务强,理解实体/短语语义深 |
| SpanBERT | 性能(片段建模) | 连续片段掩码 + 片段边界目标 (SBO) | 片段相关任务(问答、指代)表现好 |
| BioBERT | 领域适配 | 生物医学领域数据继续预训练 | 生物医学NLP任务性能飞跃 |
| SciBERT | 领域适配 | 科学文献领域数据预训练 | 科学文本处理任务表现出色 |
| ELECTRA | 效率/性能/任务 | 替换token检测 (RTD) + 生成器-判别器架构 | 训练效率高,同计算资源下性能更优 |
| DeBERTa | 性能/架构 | 解耦注意力 (内容/位置) + 增强掩码解码器 (EMD) | 多项基准测试SOTA,理解更精细 |
四、总结与展望
Transformer架构通过自注意力机制彻底解决了序列建模的并行化和长距离依赖难题,为NLP的飞跃奠定了基础。BERT则利用Transformer编码器和创新的双向预训练任务(MLM + NSP),开创了“预训练+微调”的新范式,释放了大规模无标注文本的潜力,显著提升了各种NLP任务的上限。
BERT的变体家族则沿着多个维度持续进化:
-
效率维度: DistilBERT、TinyBERT、MobileBERT、ALBERT等致力于模型小型化、轻量化,加速推理,降低部署门槛。
-
性能维度: RoBERTa通过更激进的训练设置挖掘潜力,ERNIE融入知识,SpanBERT强化片段理解,ELECTRA革新预训练任务,DeBERTa改进注意力机制,不断推高模型能力的天花板。
-
领域维度: BioBERT、SciBERT、ClinicalBERT等通过领域适应预训练,将BERT的强大能力成功迁移到专业垂直领域。