RunnablePassthrough介绍和透传参数实战
导读:在构建复杂的LangChain应用时,你是否遇到过需要在处理链中既保留原始输入又动态扩展上下文的场景?RunnablePassthrough正是为解决这类数据流处理问题而设计的核心组件。
本文通过深入剖析RunnablePassthrough的工作机制和实际应用,为开发者提供了一套完整的数据透传解决方案。文章不仅详细介绍了该组件的核心概念和基础用法,更重要的是通过一个完整的RAG(检索增强生成)系统实战案例,展示了如何在实际项目中优雅地处理并行数据流。
特别值得关注的是文章中的
.assign()方法应用技巧——它能够在不破坏原始数据结构的前提下,动态添加新的上下文字段。这种设计模式在处理复杂业务逻辑时显得尤为重要。案例中展示的向量检索与用户问题并行处理的实现方式,为构建高效AI应用提供了实用的架构参考。
简介
本文将深入介绍LangChain中的RunnablePassthrough组件,并通过实战案例演示如何使用透传参数功能。
RunnablePassthrough核心概念
功能定义
RunnablePassthrough是LangChain中的一个重要组件,其核心功能包括:
- 在处理链中直接传递输入数据,不进行任何修改
- 通过
.assign()方法扩展上下文字段,动态添加新的数据字段
应用场景
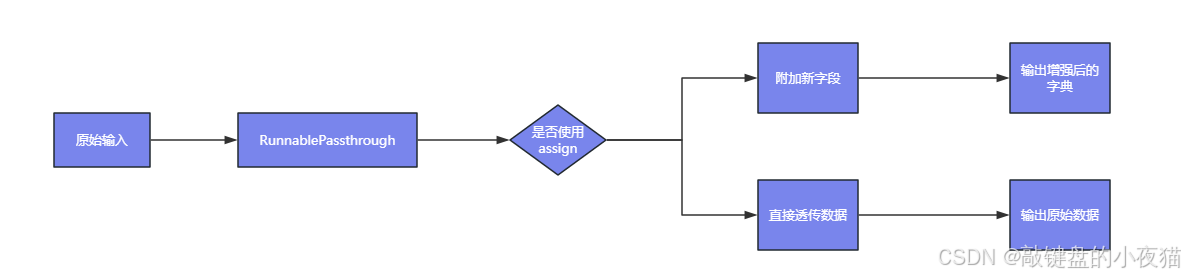
RunnablePassthrough主要适用于以下场景:
- 数据保留:保留原始输入数据供后续步骤使用
- 上下文扩展:动态添加新字段到上下文中,例如结合检索结果与用户问题
基础用法示例
直接传递输入
from langchain_core.runnables import RunnablePassthrough# 直接传递输入数据
chain = RunnablePassthrough() | model
output = chain.invoke("Hello")扩展字段实战案例
案例一:使用assign()添加字段
from langchain_core.runnables import RunnablePassthrough# 使用assign()方法添加新字段
# 该方法接收关键字参数,其值是一个处理函数
# 函数定义了如何处理输入数据以生成新字段
# lambda函数接收输入x,返回x["num"] * 2的结果
# 创建新字段'processed',值为输入字段'num'的两倍
chain = RunnablePassthrough.assign(processed=lambda x: x["num"] * 2)# 调用chain对象的invoke方法,传入包含'num'字段的字典
# 执行lambda函数,在输入字典基础上添加'processed'字段
# 输出处理后的完整字典
output = chain.invoke({"num": 3}) # 输出:{'num': 3, 'processed': 6}
print(output)案例二:构建上下文处理链
# 构建包含原始问题和处理上下文的链(伪代码示例)
chain = (RunnablePassthrough.assign(context=lambda x: retrieve_documents(x["question"]))| prompt| llm
)input_data = {"question": "LangChain是什么?"}
response = chain.invoke(input_data)透传参数LLM实战案例
工作流程说明
本案例展示了一个完整的RAG(检索增强生成)系统的实现流程:
- 并行处理:用户输入的问题同时传递给retriever和RunnablePassthrough()
- 检索执行:retriever完成检索后,自动将结果赋值给context字段
- 数据整合:检索结果context和用户输入question一并传递给提示模板
- 生成答案:模型根据检索到的上下文生成最终答案
完整代码实现
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.documents import Document
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI# 初始化嵌入模型
embeddings = DashScopeEmbeddings(model="text-embedding-v2", # 第二代通用嵌入模型max_retries=3,dashscope_api_key="sk-xxxxxxxxxxxxxxxxxxx"
)# 创建文档数据
document_1 = Document(page_content="MMR搜索和LangChain整合Milvus实战",metadata={"source": "humaonan.blog.csdn.net/article/details/148318637"},
)document_2 = Document(page_content="Milvus向量Search查询综合案例实战(下)",metadata={"source": "humaonan.blog.csdn.net/article/details/148292710"},
)documents = [document_1, document_2]# 构建向量存储
vector_store = Milvus.from_documents(documents=documents,embedding=embeddings,collection_name="runnable_test",connection_args={"uri": "http://192.168.19.152:19530"}
)# 创建检索器(默认使用similarity_search)
retriever = vector_store.as_retriever(search_kwargs={"k": 2})# 定义提示模板
prompt = ChatPromptTemplate.from_template("基于上下文回答:{context}\n问题:{question}")# 初始化语言模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxx",temperature=0.7
)# 构建处理链
chain = {"context": retriever, # 检索相关文档"question": RunnablePassthrough() # 直接传递用户问题
} | prompt | model# 执行查询
result = chain.invoke("如何实现向量搜索?")
print(result)总结
RunnablePassthrough作为LangChain生态系统中的基础组件,为数据流处理提供了灵活的解决方案。通过本文的实战案例,我们可以看到:
- 简洁性:RunnablePassthrough提供了简洁的API来处理数据传递和扩展
- 灵活性:支持多种数据处理模式,适应不同的业务场景
- 实用性:在RAG系统中发挥重要作用,实现了高效的上下文管理
掌握RunnablePassthrough的使用方法,将有助于构建更加高效和灵活的AI应用系统。