实验科学中策略的长期效应评估学习笔记
文章目录
- 1 实验科学的长短期效应产生原因
- 2 温中卉的总结
- 2.1 内生性问题:CCD(Cookie-Cookie-Day)实验解决用户学习效应
- 2.2 个性化推荐方法:优化CCD实验
- 2.3 短期代理指标方法
- 2.4 代理指数预测方法
- 2.5 分期预测方法
- 2.6 观察数据方法
- 2.7 人群偏差调整方法
- 3 自己的整理
- 3.1 反转实验法
- 3.2 常规方法
- 3.3 Netflix的代理指标实践案例
- 3.4 生存分析与分期预测
- 3.5 强化学习估计长期价值
- 4 长期异质性效应
1 实验科学的长短期效应产生原因
实验长短期效应产生的原因大体分为两类:
- 一类是外生性原因,例如,市场达到供需均衡状态是需要一定时间的;或者是策略受到时间影响,如季节变化、周中周末等;还可能受到突发事件的影响。
- 另一类是内生性原因,例如,
- 用户学习效应(积极的结果会强化导致该结果的行为,比如说用户体验会逐渐变好强化)、
- 新奇效应(策略效果会因新鲜感的降低而减弱)
- 首要效应(用户会因适应策略而导致策略效果增加);
- 还包括推荐系统个性化推荐(推荐系统是个性化的,推荐会因用户过去的行为不同而推荐不同的内容,久而久之会产生差异);
- 可能没有一个逐渐改变的过程,只是因为实验时长有限,不能观察到中长期北极星指标的变化,如 30 天留存的变化;
- 以及 A/B 实验的用户圈定存在人群偏差,如活跃用户比不活跃用户更有可能被纳入实验的现象,从而导致估计的效果存在偏差。
2 温中卉的总结
来自社群温中卉 腾讯 数据科学家 的总结:【关于A/B 实验中策略长期效果评估方案的研究】
关联论文:
Estimating Effects of Long-Term Treatments

2.1 内生性问题:CCD(Cookie-Cookie-Day)实验解决用户学习效应
用户学习效应是指积极的效应会被强化,而消极的结果会逐渐衰减。
CCD(Cookie-Cookie-Day)实验,就像测试新菜谱:让一些人天天吃,一些人偶尔吃,看看吃久了会不会腻
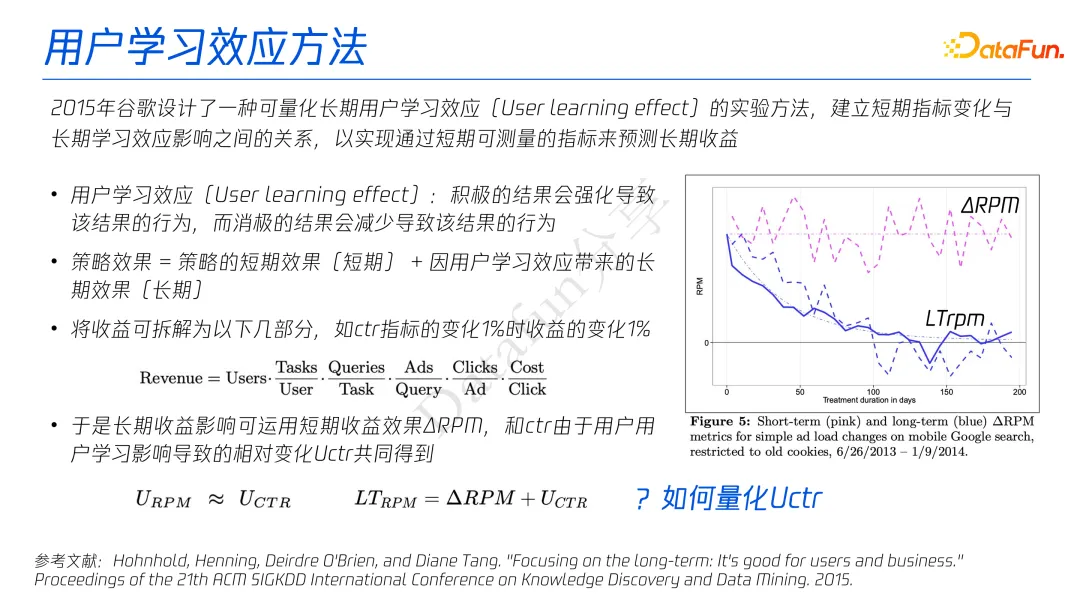
谷歌在 2015 年设计了一种可量化长期用户学习效应(User learning effect)的实验方法,建立短期指标变化与长期学习效应影响之间的关系,以实现通过短期可测量的指标来预测长期收益。
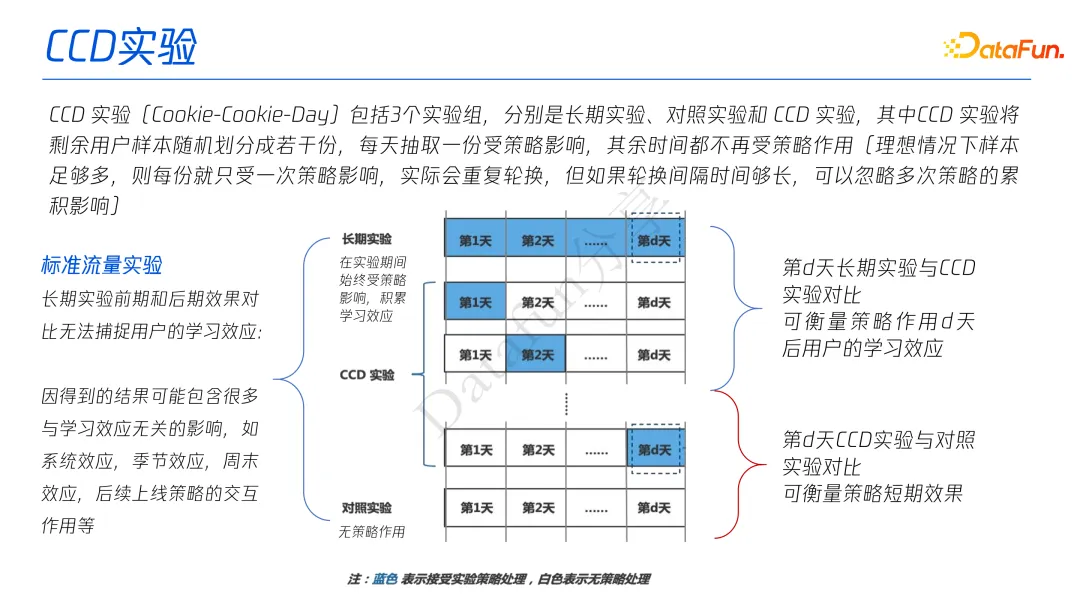
具体做法是设计一个 CCD(Cookie-Cookie-Day)实验,该实验共包含 3 个实验组,分别为长期实验组、对照实验组和 CCD 实验组:
- 长期组,在实验期间始终受策略影响,积累学习效应
- 对照组,没有策略作用
- CCD 实验组,将该组用户随机划分成若干份,每天抽取一份使其当天受到策略影响而其余时间不受策略影响。
传统的标准流量实验,只是有长期实验和对照实验,通过对比长期实验前期和后期效果其实无法捕捉用户的学习效应,因为得到的结果可能包含很多与学习效应无关的影响,如系统效应,季节效应,周末效应,后续上线策略的交互作用等。
因此需要多一个 CCD 实验,在第 d 天短期接受策略的组,通过比较第 d 天 CCD 组和长期组,可以“抹去”策略带来的短期效果,于是两组的差异则来自于长期效果,从而达到评估长期效果的目的。
该方法仍存在一些局限性:
- 第一,基于 cookie 的方式并不稳定,或者存在一些用户行为的改变,可能会导致对长期学习效应的低估;
- 第二,在进行指数拟合时,学习速率并不一定是固定的;
- 第三,策略的其他短期指标仍存在探索空间;
- 第四,该方法本身的开发和探索成本较高。
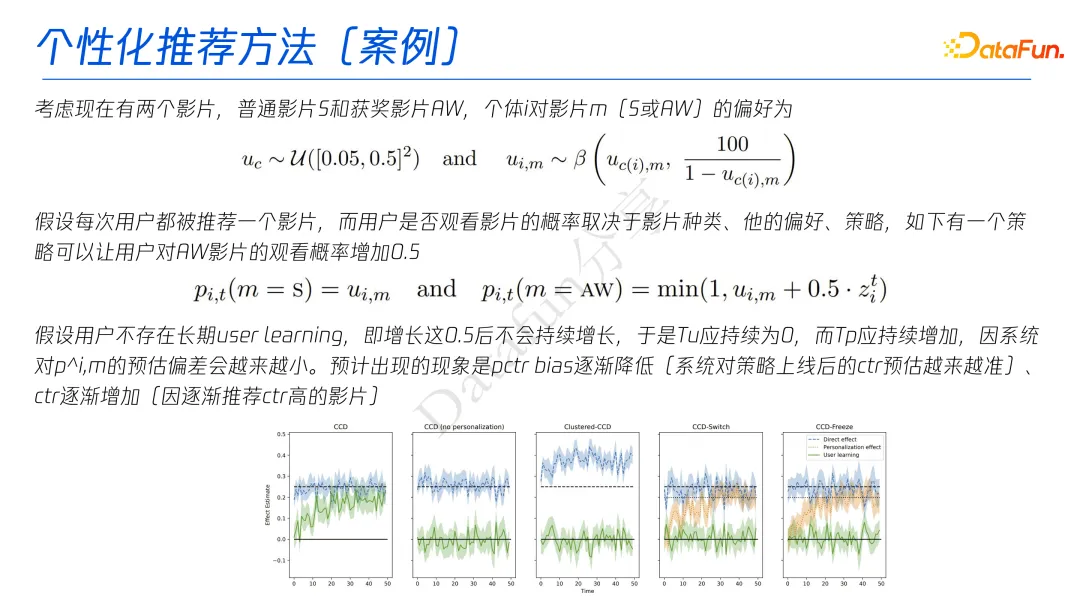
2.2 个性化推荐方法:优化CCD实验
策略的总体效应是由短期效应、用户学习效应和个性化推荐效应三方面共同决定的。

谷歌共提出了三种 CCD 改造方法,本次分享以 CCD-Switch 方法为例进行阐述。
相比于 CCD 实验,CCD-Switch 方法增加了一个实验组,该实验组接受长期策略的影响,但被系统推荐时,该组用户接收到的广告会被替换成对照组中“相似用户”接收到的广告,保证该组用户的推荐不受其历史行为的影响。
在此设定下,就可以通过对比四个实验组的结果来得到总体效应的三个部分,从而推断出策略的长期效应。
2.3 短期代理指标方法
找一个容易测量的短期数据(比如点击率)来代替难测量的长期数据(比如3个月后的留存率)。
先通过历史数据验证这个短期指标是否靠谱(比如点击率高时,留存率通常也高),然后在实验中只关注这个短期指标。就像用“体温”来猜“是否发烧”,省时省力。
代理指标的选择步骤共分为如下三步:
- 第一步,根据业务逻辑选择大量代理指标,这个候选代理指标需要满足以下条件:与北极星指标有高相关性;是可能被实验策略撼动的指标;适用于实验策略覆盖的业务场景;
- 第二步,通过模型和相关度分析,圈出若干个跟北极星指标关联度高的候选代理指标,进一步精简候选代理指标;
- 第三步,通过实验回测的方式,找出最敏感的代理指标,如长期指标显著的实验中,代理指标显著比例最高的代理指标。
存在一些明显的局限性。
- 首先,单一的代理指标可能不足以表征长期效应;
- 其次,可能存在代理指标明显提升但长期效果不显著的问题;
- 第三,代理指标的筛选只考虑了相关性而未检验因果性。
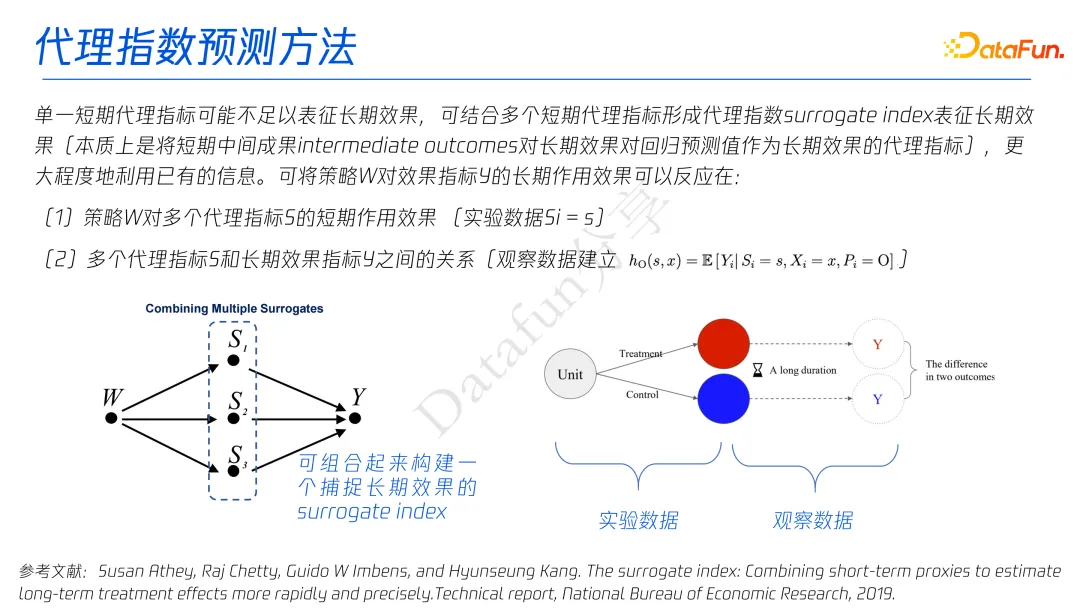
2.4 代理指数预测方法
通俗解释:因为单一短期指标可能不准,这个方法用多个短期指标(比如点击率+浏览时长+点赞数)组合起来,通过数学模型预测长期效果。
就像用“身高、体重、年龄”一起预测健康风险,比只看一个指标更可靠。
在使用该方法时,需要注意满足如下三个假设:
- Unconfoundedness,即没有混杂因素同时影响 W 和 Y,S;
- Surrogacy,即代理变量充分表征 W 对 Y 的影响,在代理变量给定时,W 和 Y 独立。此处可尽可能引入合适的代理变量,以捕捉 W 对 Y 的作用路径;
- Comparability,即在代理变量给定时,实验数据和观察性数据结果指标 Y 分布相同。因代理指标 S 和 Y 之间的关系是根据历史数据获得,所以要用此来预测实验中 T 对 Y 的长期效果,需保证此假设成立,这样回归模型才具有泛化性。
2.5 分期预测方法
把长期时间切成小段(比如每周一段),用每一段的短期数据(如用户行为)预测下一段的变化,一步步累积到长期效果。
就像爬楼梯:先预测第一阶的高度,再预测第二阶,最后算出整个楼梯多高。
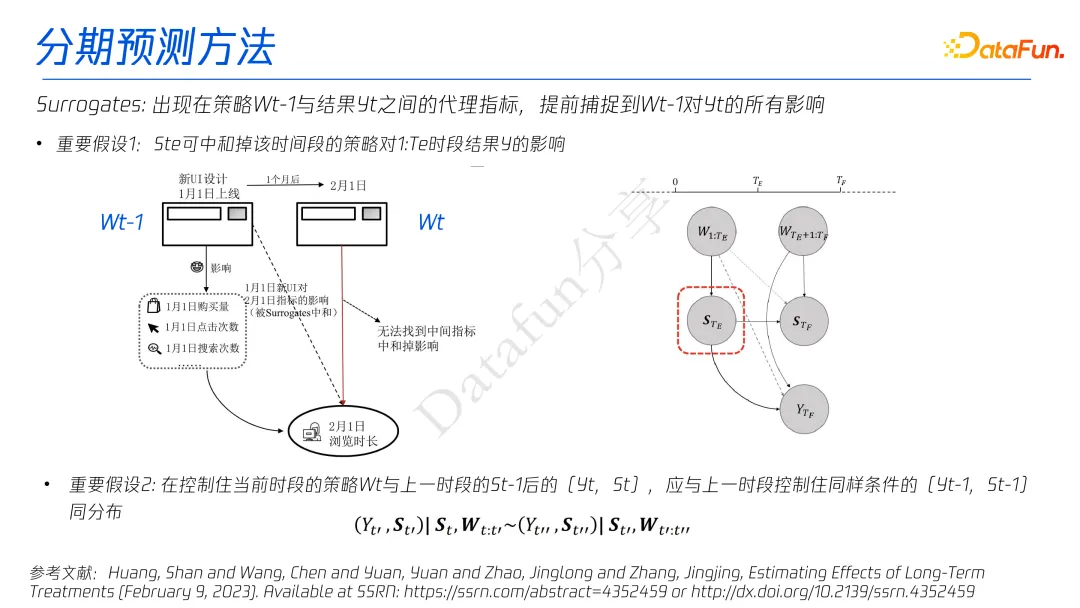
为了实现这一目标,需要满足两个重要假设。
- 假设效果指标受到用户特征、当期的策略和过往的策略的共同影响,因此引入代理指标表征过往策略对效果指标的全部影响,
- 假设每一期的影响效果都是同分布的。
分期预测方法的局限性主要表现在个体预测难度大、时间预测较难、同分布假设较强等方面。
2.6 观察数据方法
直接分析实验数据随时间的变化趋势。如果发现效果先涨后跌(新奇效应)或慢慢上升(用户学习效应),就用这个规律外推长期效果。
比如新图标上线后点击率第一天暴涨但每天下降,就推测三个月后可能回归正常。这像看天气趋势图猜明天温度。

该方法能用于快速判断短期实验是否存在新奇效应或首要效应,若存在,一方面可以拉长实验周期持续观察,另一方面可以利用时间序列分析外推长期效应。该方法非常简单,没有实验开发的成本。
然而,该方法的主要局限性在于可能有其它外部因素使得预估有偏;并且对期望效果的线性表达式过于简单,可能不符合真实情况;另外,时间预测较难,可能受到周期性的影响。
2.7 人群偏差调整方法
实验中活跃用户太多会导致结果偏差(比如只测了“手机控”,忽略了普通用户)。这个方法用数学调整样本权重,让实验结果更接近真实用户群体。
就像投票时,给不同人群加权,避免“粉丝声音太大”影响结果。
发现重度用户偏差通常与实验的长度 k 成反比,借鉴 jackknife 的思想,构造出更为无偏的估计量。这个方法假设比较强,该文作者也在探索放开部分假设的方法。业界也针对这个问题有其他方法,如根据子群占比进行权重调整,使得实验周期内样本分布与总体分布一致。
3 自己的整理
主打找到简单的办法来解决问题
3.1 反转实验法
“反转实验”可以通俗地理解为:给已经体验过新策略的用户,再把新策略“撤回”或者“反转”掉,看看他们有什么反应。
它就像一个“后悔药”或者“回溯”的机制,目的是为了区分用户行为的变化究竟是因为尝鲜(短期效应),还是因为策略本身真的有价值(长期效应)。
为什么需要反转实验?
- 新奇效应: 用户刚开始觉得新鲜,所以多点了几下,多用了几次。但新鲜感一过,他们就恢复了正常使用习惯。
- 用户学习效应: 用户需要时间来适应和学习新功能。可能一开始用户觉得不习惯,慢慢学会了才发现新功能的好处,或者一开始用户觉得很方便,但用久了发现它并没有那么好。
在文章【推荐系统的基本概念】也提到了可以再全新的推全层,保留一个小的反转桶,使用旧策略,来观察长期的策略效果
火山引擎已经上线了反转实验,来看看文档:https://www.volcengine.com/docs/6287/1113735
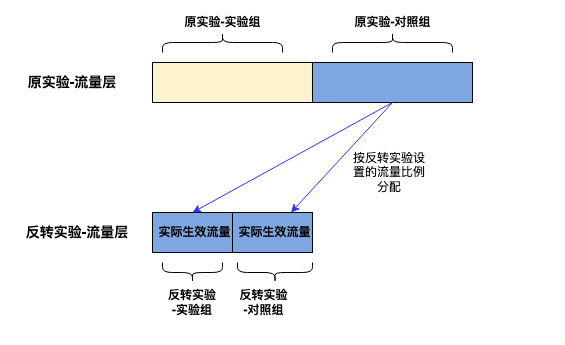
会对已结束的原实验的对照组流量再进行一次哈希,将此部分的流量均匀分布,然后按反转实验配置的流量比例分配给反转实验的实验组和对照组,作为实际生效流量,如图所示。
反转实验与传统AB的差异:
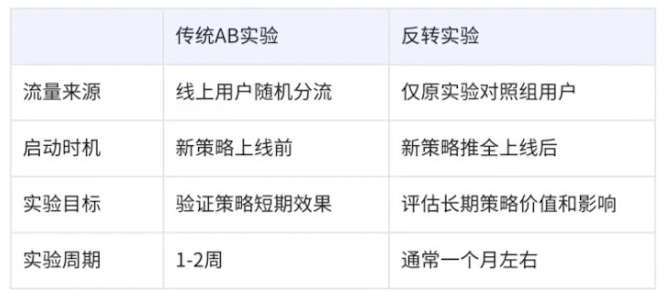
反转实验注意事项:
- 反转实验开启时机一般在策略上线后:一般情况下,原实验已被论证有正向价值结束后,为了论证长期价值往往才开启反转实验。但在工作中,有时候开反转是论证早已上线策略的价值。
- 选择原对照组用户:注意是在原对照组用户进行反转观测,切忌不可在原实验组选相同流量比对。原因是原实验组策略样本量比对照组要大的多,其算法等训练效果是不一样的,很有可能原实验组相同流量比在原对照组反转的实验组效果要更好。
- 反转实验周期一般不要过长:虽然是观测长期收益,但长期保留半年也不太合理(对照组用户长期无新功能更新),除非是特殊场景要准确预估长期收入。当确定有正向收益,尽快覆盖对照组用户,保障用户体验同时拿到更多收益。
3.2 常规方法
针对有一些策略已经在线好久时间了,基于时序的效果数据,可以简单使用常规的办法就可以完成长期效应测量
比如:差分法DID 、 合成控制法SCM、断点回归设计
不赘述
3.3 Netflix的代理指标实践案例
来自文章:Netflix 如何透過短期 A/B Testing 結果估計長期成效
其实与【2.3】一样,只不过当时讲座没细说,笔者刚好找到了就展开一下
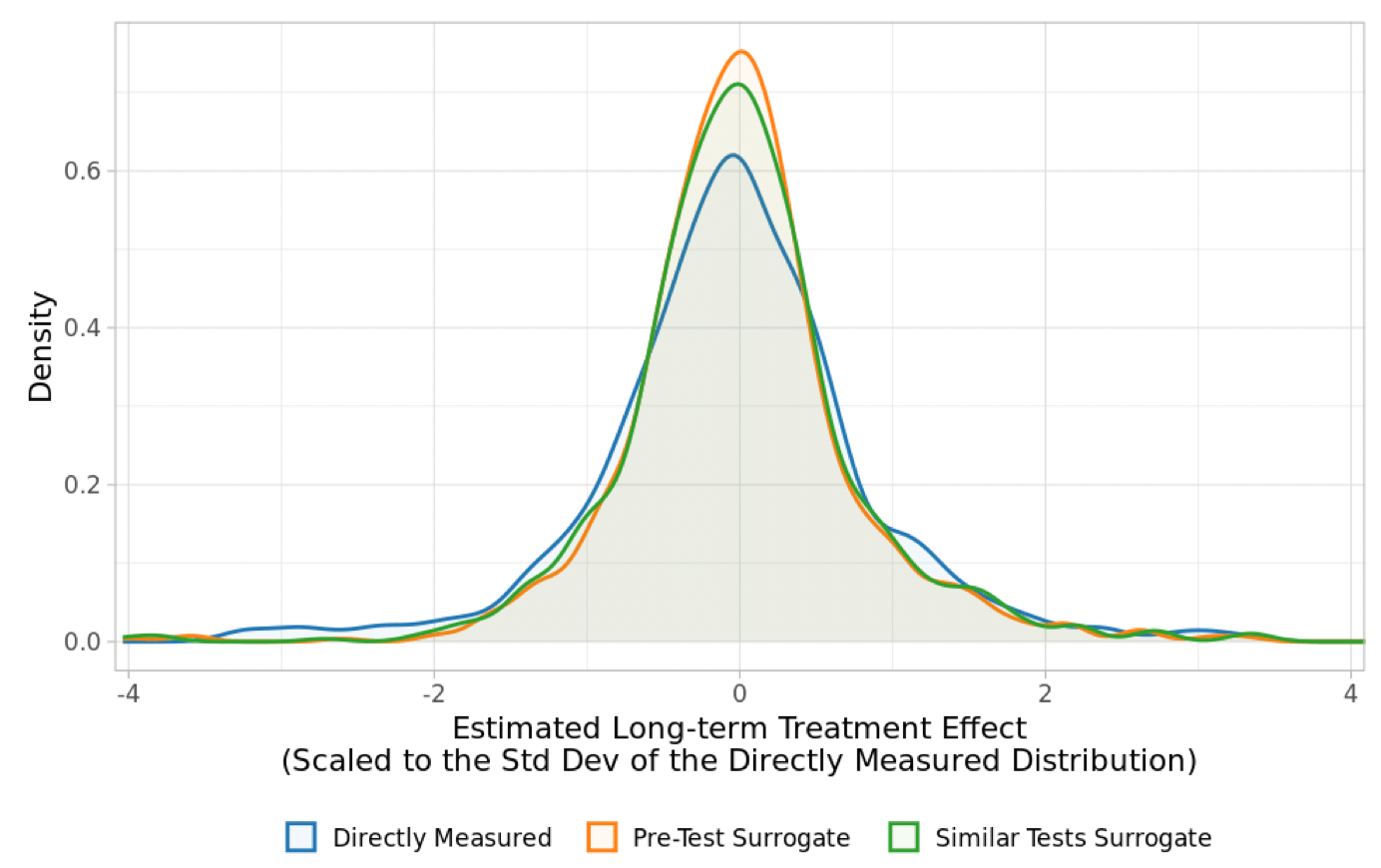
一般来说,Treatment Effect 会是一个较短的指标,当然我们也可以考虑把实验的周期拉长,这样会获得一个长期效果的指标,不过实务上这样做的成本太高了,于是与其透过 Treatment 去评估一个 Long-term effect,不如考虑一个代理指标,这个代理指标不仅与 short-term effect 有关,也可以藉由这个代理指标去估计 long-term effect。
对于 Netflix 来说,Retention → Revenue 这一段建模应该是合理的,毕竟订阅制的盈利模式相对简单,一个客户流失与否会强力地影响到他下次是否续订并提供营收,而这段模型也不用实验的参与,用 observational data 就可以处理了。
如 Fig. 1 所示,透过代理指标去估计 long-term effect,不仅 unbiased,相较于直接估计的 estimator 来说其变异更小。
3.4 生存分析与分期预测
来自文章:Netflix 如何透過短期 A/B Testing 結果估計長期成效
生存分析(Survival Analysis)或分期预测(Stage-wise Extrapolation)在长期效应评估中的常见目标是:
根据短期观测到的用户行为(如 7 天、14 天的留存或使用行为),预测更长期(如 30 天、90 天)指标的差异。
这种方法更多是在做长期反事实预测(Long-term Counterfactual Prediction),即:
如果我们对一个用户进行了 Treatment,那么他在第 30 天还会继续使用这个功能的概率是多少?
沿着【3.3】,Netflix假设每个用户在离开平台(如取消订阅)的概率θ服从Beta分布,离开时间呈几何分布,并将θ参数化为用户特征函数.
在观测了初期几个月的留存差异后,可用这种模型预测更长时间范围内的总体留存率变化,从而估计长期收入提升。
该方法要求不同时间加入的用户对新功能的反应规律相似
只需拟合最早一批用户随时间的处理效应(第1个月的效应序列),即可根据对角线共用假设推断其他批次(vertical)和未来时间(horizontal)的效应。
此类模型将用户特征纳入参数估计,能够捕捉不同群体的异质性,但其准确性取决于模型假设是否成立。
具体操作步骤为:
在生存函数模型中,如 Cox 比例风险模型(Cox PH Model),可以将“是否接受 treatment”作为一个协变量
h ( t ∣ x ) = h 0 ( t ) ∗ e x p ( β 1 ⋅ t r e a t m e n t + β 2 ⋅ x 1 + β 3 ⋅ x 2 + . . . ) h(t | x) = h0(t) * exp(β1·treatment + β2·x1 + β3·x2 + ...) h(t∣x)=h0(t)∗exp(β1⋅treatment+β2⋅x1+β3⋅x2+...)
其中:
- h ( t ∣ x ) h(t | x) h(t∣x) 是在时间 t 上的风险函数;
- t r e a t m e n t treatment treatment 是是否接受干预的指示变量;
- x1, x2 是其他协变量;
- β 1 β1 β1 的估计值可以告诉我们 treatment 是否延长/缩短了“生存期”。
公司会建两个模型:
- 一个是对 control 组用户 的留存进行生存建模;
- 一个是对 treatment 组用户 的留存建模。
然后比较两个生存曲线在第 30 天的差异(例如平均剩余生命周期的差距),即可估计 treatment 的长期效果。
生存分析/预测类方法其实是一个更弱假设、但回避显式因果结构的“预测”方法。它不能保证预测的结果是纯粹的“因果效应”,除非在实验设计中 严格控制了干预
额外的,一些方法正在将因果推断和生存分析结合起来,提出:Causal Survival Analysis(因果生存分析):通过结构建模来估计某干预对生存时间的因果效应
3.5 强化学习估计长期价值
将 A/B 策略看作是策略 π 的不同版本,构造马尔可夫决策过程(MDP)或部分可观测 MDP(POMDP),用强化学习方法来学习和评估 Treatment 策略下的长期累积回报(reward)。
YY一个实践步骤:
Step 1:定义 MDP 结构
马尔可夫决策过程 (MDP) 通常由以下几部分构成:
- 状态(s):用户的行为或画像,如过去点击、留存天数、是否开通会员等;
- 动作(a):策略下采取的行为,比如是否推送优惠券、是否推荐某功能;
- 奖励(r):比如用户的活跃时长、购买次数、30天留存等;
- 状态转移( P ( s ′ ∣ s , a ) P(s' | s,a) P(s′∣s,a)):用户如何因为某个动作而状态改变;
- 策略 π ( a ∣ s ) π(a | s) π(a∣s):在某个状态下采取哪个动作的概率;
- 初始状态分布( d 0 d₀ d0):用户开始使用产品的状态分布。
Treatment 在这里就是“不同的策略 π”
Step 2:将实验策略建模为不同的 Policy(π)
- Control 策略( π 0 π₀ π0):原始系统在状态 s 下怎么推荐;
- Treatment 策略( π 1 π₁ π1):实验策略(如新推荐算法)在状态 s 下怎么推荐。
这时候你就可以比较 π 0 π₀ π0 和 π 1 π₁ π1 在长期 reward 上的表现差异。
Step 3:学习模型(环境建模)
你通常只有实验日志数据,比如用户在过去某些状态下点击了什么,系统推荐了什么(动作),之后产生了什么行为(状态变化、是否留存、消费等)。
你可以采用以下方式之一建模环境:
- Model-Based 方法:学习状态转移概率 P(s’ | s, a) 和奖励函数 r(s, a);
- Model-Free 方法:直接从行为策略下的数据做 off-policy 评估;
- 模拟环境(Simulators):工业界如 Meta 会构建用户模拟器,基于历史数据生成反事实轨迹。
Step 4:估计长期价值(即策略 π₁ 的 Vπ₁)
使用强化学习的方法评估策略 π₁ 在当前环境下的长期回报:
Off-policy Evaluation(OPE)方法:
- Inverse Propensity Scoring (IPS)
- Doubly Robust Estimator
- Importance Sampling
Step 5:解释 Treatment 的因果效应
假如你能评估出:
- V(π₁):新策略的长期回报(例如用户留存、收入);
- V(π₀):老策略的长期回报;
那么两者之差:
Δ = V(π₁) – V(π₀) 就是策略的“长期因果效应”。
4 长期异质性效应
未完待续