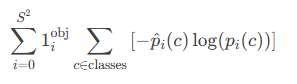YOLO-V2 (学习记录)

目录
一、记录YOLO-v2 的处理流程步骤
二、优势与不足
三、细节分析
1.候选框K-means计算细节
2.网络输出
3.损失函数(Loss Function)
学习之前,需要补充下论文中提到知识点。
1.什么是Batch Normalization
参考博文:Batch Normalization 的原理-CSDN博客
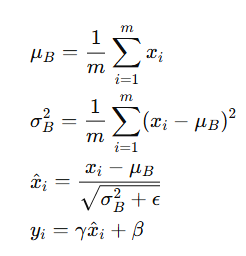
2. 什么是K-means聚类算法
参考博文:K-means聚类算法--原理及代码-CSDN博客

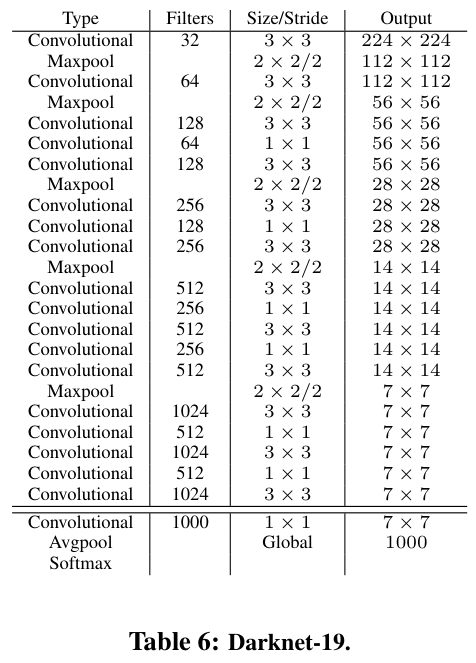
3.Darknet-19模型
参考博文:Darknet-19 模型结构-pytorch代码-CSDN博客
4.Faster RCNN
参考博文:一文读懂Faster RCNN(大白话,超详细解析)-CSDN博客
核心组成部分:
1️⃣ Backbone
-
通常是卷积神经网络(如 VGG16、ResNet)作为特征提取器。
-
输出高维度的 feature map。
2️⃣ Region Proposal Network (RPN)
-
从 backbone 的特征图中生成一系列候选框(Region Proposal,即 ROI)。
-
RPN 是一个小型的全卷积网络,预测每个 anchor box 的 foreground/background 分类(2类)和坐标回归偏移(4维)。
3️⃣ ROI Pooling / ROI Align
-
将 RPN 提供的候选框映射到特征图中,并通过池化或对齐操作,统一成固定大小的特征表示。
4️⃣ Fast R-CNN Head
-
对每个 ROI 特征做全连接层分类(多类别)+ 边框回归。
-
最终输出检测框和类别。
关键创新:
-
RPN 提速:相比原先用 Selective Search 的 RCNN/Fast-RCNN,RPN 通过 end-to-end 训练自动生成 proposal,显著加快检测速度。
-
共享特征:Backbone 特征在 RPN 和 Fast R-CNN head 之间共享,避免重复计算。
一、记录YOLO-v2 的处理流程步骤
1️⃣ 输入阶段
-
输入图像:将原图 resize 到网络输入尺寸(例如 416×416)。
-
YOLOv2 支持 多尺度训练,训练时输入尺寸在 320~608 之间随机选择(32 倍数)。
-
通道数通常是 3(RGB 彩色图像)。
2️⃣ 主干网络特征提取
-
骨干网络:Darknet-19
-
包含 19 层卷积层 + 5 层最大池化层。
-
激活函数:Leaky ReLU(0.1)。
-
作用:提取语义特征。
-
-
特征提取的输出:
-
输入 416×416 → 输出 13×13×1024
-
因为下采样了 32 倍(5 层池化,2×2,每次降一半)。
-
3️⃣ 细粒度特征融合(passthrough layer)
-
选取浅层特征图(26×26×512)。
-
通过 space-to-depth 操作(2×2 块像素重排到通道维度),变换为 13×13×2048。
-
将这个细粒度特征与深层特征图(13×13×1024)在通道维度拼接,形成 13×13×3072 的特征图。
细节:
-
这样做可以保留更多小目标细节,提升小目标检测性能。
4️⃣ 检测头(检测层)
-
卷积降维:通过一个 3×3 卷积层,将通道数从 3072 降到 1024,再通过一个 1×1 卷积输出 13×13×125。
-
125 = 5×(4 + 1 + 20),其中:
-
5:每个 cell 预测 5 个 anchor box
-
4:框回归参数 (tx, ty, tw, th)
-
1:置信度(objectness score)
-
20:PASCAL VOC 20 类的类别概率(C=20)
-
5️⃣ Anchor Box 机制
-
论文中引入 anchor box(先验框),类似 Faster R-CNN 中的 anchor。
-
通过 K-means 聚类 在训练集的 GT box 上生成 5 个 anchor(w, h)。
-
在检测层,每个 cell 负责预测 5 个 anchor box。
6️⃣ 输出预测
-
输出是一个 13×13×125 的特征图:
-
每个 cell 对应 5 个 anchor box。
-
每个 anchor box 预测 (tx, ty, tw, th, objectness, 20×class scores)。
-
7️⃣ 预测框参数解码
在得到预测结果后,需要将它解码成实际的边界框坐标:
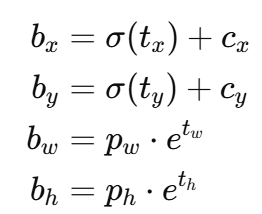
其中:
-
(cx,cy):cell 左上角坐标
-
(pw,ph):anchor box 的宽高
-
σ(⋅):sigmoid 函数,确保中心偏移在 0~1 之间
-
预测框坐标再映射回到原图像空间
8️⃣ 后处理(NMS)
-
生成所有预测框后,应用 非极大值抑制(NMS),过滤掉冗余框,保留最终的检测结果。
流程总结图示
输入图像(416×416×3)↓
Darknet-19 特征提取↓
浅层特征 passthrough 融合↓
特征拼接(13×13×3072)↓
卷积降维输出(13×13×125)↓
anchor box 解码 → 得到候选框↓
类别 softmax(或 sigmoid)得到概率↓
NMS → 输出最终检测框
🟩 YOLOv2 主要改进点总结
anchor box:K-means 生成 5 个 anchor。
细粒度特征融合:passthrough 层,保留小目标细节。
多尺度输入训练:每隔 10 个 batch,随机换输入尺寸。
更深更快的骨干网(Darknet-19):19 层卷积,轻量高效。
全卷积结构:输入大小可变,推理灵活。
YOLOv2 相比 YOLOv1 改进点总结
| 改进点 | YOLOv1 | YOLOv2 改进 |
|---|---|---|
| Anchor Boxes | 无(直接回归) | 引入 Anchor Boxes |
| 骨干网络 | GoogLeNet | Darknet-19,轻量化+BN |
| 预测方式 | 直接回归坐标 | 预测 anchor 的坐标偏移 |
| 多尺度训练 | 无 | 有 |
| 输入分辨率 | 固定 | 动态调整多尺度 |
| 召回率和小目标检测能力 | 差 | 提升显著 |
二、优势与不足
优势:
-
速度快:单阶段检测,适合实时应用(如视频监控)。
-
精度提升:mAP较YOLOv1显著提高(VOC 2007上从63.4%到78.6%)。
-
多尺度适应性:支持不同分辨率输入。
不足:
-
对小目标和密集目标的检测仍弱于两阶段方法(如Faster R-CNN)。
-
YOLOv2的联合训练在实际检测任务中泛化能力有限。
三、细节分析
1.候选框K-means计算细节
论文中的候选框是通过K-means计算得到的,这个过程用于计算的输入框是什么?距离是怎么表示的?
YOLOv2 中的 K-means 聚类是对 训练集标注的目标框(ground truth boxes) 做的。
在 YOLOv2 中,作者提出使用 K-means 对真实目标框进行聚类,以找到更合适的 anchor box 尺寸。目的是让 anchor box 更贴近数据集中的实际目标大小和长宽比例,从而提高模型的召回率和检测精度。
🎯 聚类的对象:
-
对象:所有 训练集中的 ground truth 边界框(ground truth bounding boxes)。
-
维度:每个框的宽度和高度 (w, h)。
📦 具体流程:
1️⃣ 从训练集提取所有标注的目标框,得到其宽度和高度:
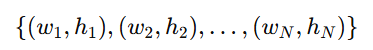
2️⃣ 采用 K-means 聚类对这些 (w, h) 进行分组。
-
注意:YOLOv2 用的不是欧几里得距离,而是 1 − IOU 作为距离度量。
-
这样可以避免因为大目标的宽高差异太大而导致聚类效果不好,直接用 IOU 作为相似度,更符合检测目标。
公式推导(距离计算)
对于两个边界框(w1, h1)和(w2, h2):
-
交集面积:
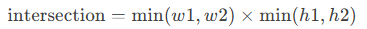
-
并集面积:
![]()
-
IoU距离:

3️⃣ 聚类完成后,得到 K 个聚类中心:
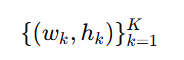
这里和标准的 k-means 思路相同,区别在于距离度量。更新中心点时,仍然是对每个簇内的宽高求平均:
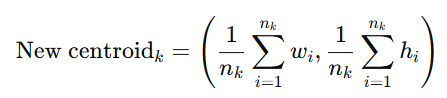
其中:
-
n_k:第 k 个簇中的样本数。
-
(w_i, h_i):簇中每个样本的宽高。
这些中心就作为最终的 Anchor Box 尺寸。
💡 为什么这样做?
-
如果 anchor box 的形状和真实目标差异太大,网络需要学到很大的回归偏移量,学习难度增大。
-
K-means 聚类后的 anchor box 更贴合实际分布,模型只需学习相对较小的偏移量,效果更好。
例如:
-
如果你的数据集里主要是长条形物体,直接使用 YOLOv1 中的固定 anchor box 可能不合适。
-
使用 k-means 后,anchor box 的形状更贴合,模型训练更高效。
📝 具体流程小结:
1. 从所有 GT 框中收集 (w, h) 数据。
2. 随机选择 5 个中心点 (w, h)(初始化)。
3. 对所有框,计算和 5 个中心的 1 - IOU 距离,分配到最近的中心点簇。
4. 对每个簇,重新计算中心点:对簇内所有样本 (w, h) 均值。
5. 重复 3、4 直到收敛(或者迭代次数达到设定值)
2.网络输出
网络输出:
-
每个 anchor box 预测:
-
偏移量 (tx, ty)
-
尺寸缩放 (tw, th)
-
置信度
-
类别概率
-
最终:
-
每个 anchor box 尺寸:
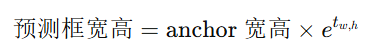
预测框中心点:
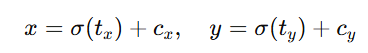
其中 c_x, c_y 是 cell 在特征图中的位置索引。
需要注意:
➡️ 网络输出13×13 特征图中的 每个单元格 叫做一个 “cell” 或者 “grid cell”。
➡️ 这个 “cell” 其实是一个“感受野区域”的抽象,不是像素。
每个 cell 有多个 通道(channel),不是单通道像素:
-
例如,输出形状是 (13, 13, 125):
-
125 = 5 × (5 + C),其中 5 是 anchor 数量。
-
每个 cell 输出 125 个数,不是单个像素值!
-
每个 cell 预测 5 个 anchor box(因为 anchor 数量是 5)。
每个 anchor box 输出:
-
4 个回归偏移量(tx, ty, tw, th)
-
1 个置信度(objectness)
-
C 个类别概率(对 C 分类问题)
所以每个 anchor box 输出 5 + C 维。
例子:输出特征图形状
假设类别数 C=20(PASCAL VOC):
-
每个 anchor box 输出 (5 + 20)=25。
-
5 个 anchor → 25×5=125。
-
所以最终输出形状是 (13, 13, 125)。
Loss 计算核心思路
✅ 不是直接把 125 通道卷积成 1 通道。
✅ 而是把 125 通道 reshape 成 13×13×5×(5 + C) 维度。
这样就能:
-
把 125 通道 → anchor box 维度 + 预测向量维度,分块处理。
-
每个 cell 有 5 组 (5 + C) 向量。
3.损失函数(Loss Function)
YOLOv2的损失函数包含三部分:
坐标损失(Coordinate Loss):
仅对正样本(含目标的锚框)计算,使用MSE损失。
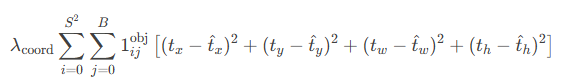
置信度损失(Confidence Loss):
区分正负样本,使用交叉熵损失。
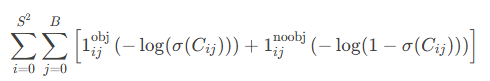
类别损失(Class Loss):
仅对正样本计算,使用交叉熵损失。