大数据-277 Spark MLib - 基础介绍 机器学习算法 Gradient Boosting GBDT算法原理 高效实现
点一下关注吧!!!非常感谢!!持续更新!!!
大模型篇章已经开始!
- 目前已经更新到了第 22 篇:大语言模型 22 - MCP 自动操作 Figma+Cursor 自动设计原型
Java篇开始了!
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新…)
- Spark MLib (正在更新…)
Gradient Boosting
梯度提升树(Gradient Boosting)是提升树(Boosting Tree)的一种改进算法,所以在讲梯度提升树之前先来说一下提升树。
先来例子理解:假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。
如果我们迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小,最后将每次拟合的岁数加起来便是模型输出的结果
提升树算法:
初始化 f0(x)= 0
对 m = 1,2…M,计算残差 rmi = yi - fm - 1(x) , i = 1,2…N
拟合残差 rmi 学习一个回归树,得到 hm(x)
更新 fx(m) = fm - 1 + hm(x)
得到回归问题提升树:
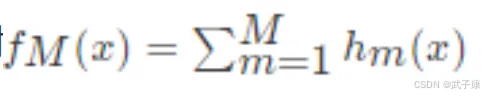
上面伪代码中的残差是什么?
在提升树算法中:
假设前一轮迭代得到的强学习器是:ft-1(x)
损失函数是:L(y, ft-1(x))
本轮迭代的目标是找到一个弱学习器:ht(x)
最小化本轮的损失:L(y, ft(x)) = L(y, ft- 1(x) + ht(x))
当采用平方损失函数时:
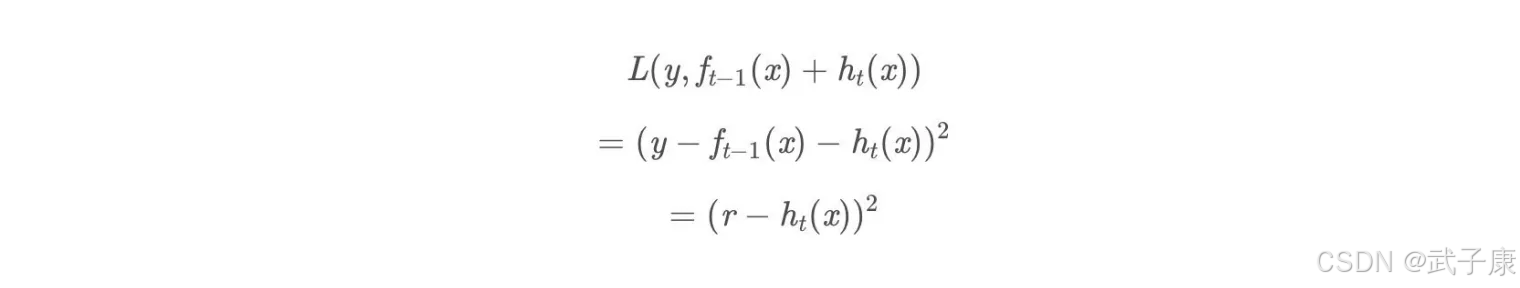
这里,r = y - ft -1(x) 是当前模型拟合数据的残差(residual)
所以,对于提升树来说只需要简单你和当前模型的残差
当损失函数是平方损失和指数损失函数时,梯度提升树每一步优化都是很简单的,但是对于一般损失函数而言,往往每一步优化起来都不那么容易。
针对这一问题,Friedman 提出了梯度提升树算法,这是利用最速下降的近似方法,其关键是利用损失函数的负梯度作为提升算法树中的残差的近似值。
那么负梯度长什么样子呢?
第t轮的第i个样本的损失函数的负梯度为:
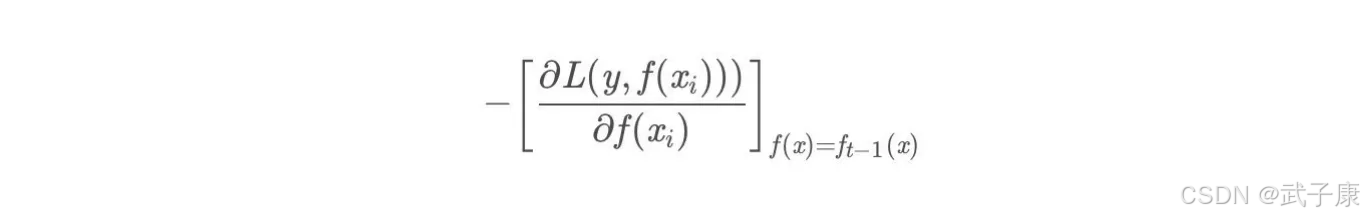
此时不同的损失函数将会得到不同的负梯度,如果选择平方损失:
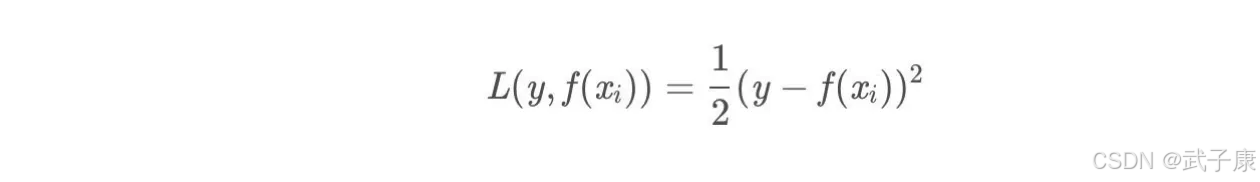
负梯度为:
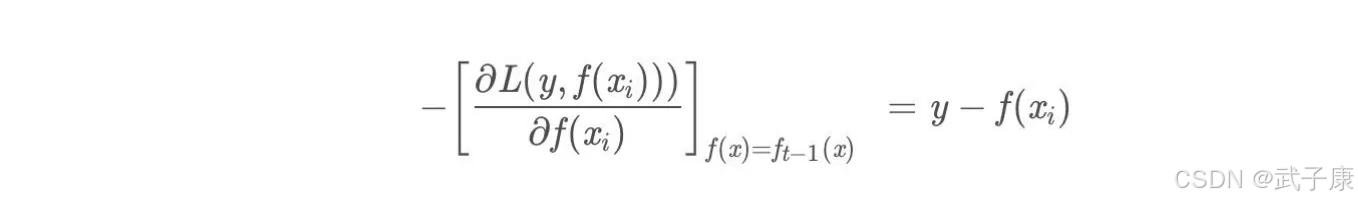
此时我们发现 GBDT 的负梯度就是残差,所以说对于回归问题,我们要拟合的就是残差。那么对于分类问题呢?二分类和多分类的损失函数都是 logloss
GBDT算法原理
将 Decision Tree 和 Gradient Boosting 这两部分组合在一起就是 GBDT 了。
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)是一类 逐步加法模型+梯度下降优化 的集成学习算法。
- Boosting:按序列方式训练多个弱学习器(一般是浅决策树),后一个模型专门弥补前面模型的错误。
- Gradient:把“如何修正错误”形式化为在损失函数上的梯度下降;每一步都在函数空间中向负梯度方向迈出一小步。
- Decision Tree:最常用的弱学习器是 CART 回归树(可处理回归或分类,经适当编码)。
初始化弱学习器
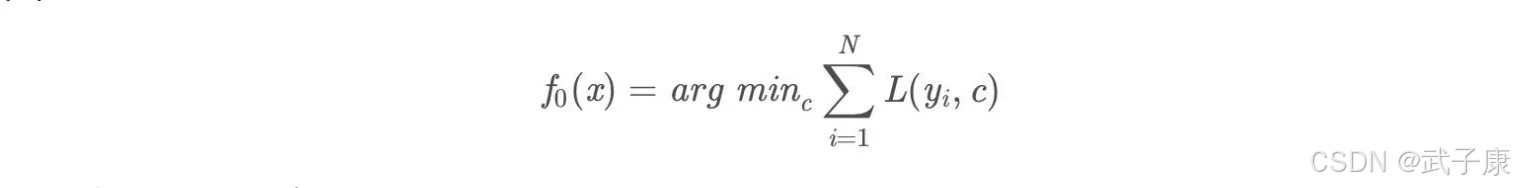
**对 m = 1,2…M **
对于每个样本 i =1,2…N 计算负梯度(即残差)
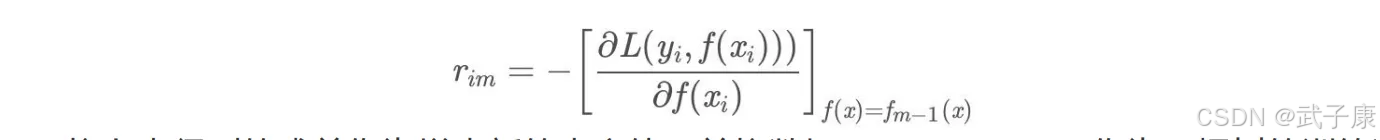
将上步得到的残差作为样本新的真实值,并将数据 (xi, rim), i = 1,2…N 作为下颗树的训练数据,得到一个新的回归树 fm(x) 其对应的叶子节点区域为 Rjm, j = 1,2…J。
其中J为回归树t的叶子节点的个数。
对叶子区域 j = 1,2…J 计算最佳拟合值
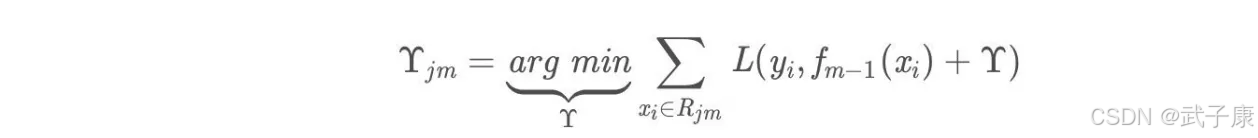
更新强学习器
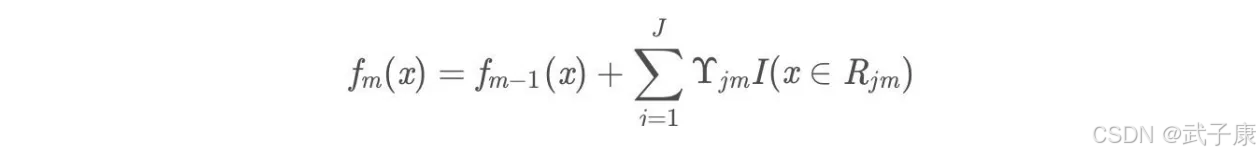
得到最终学习器
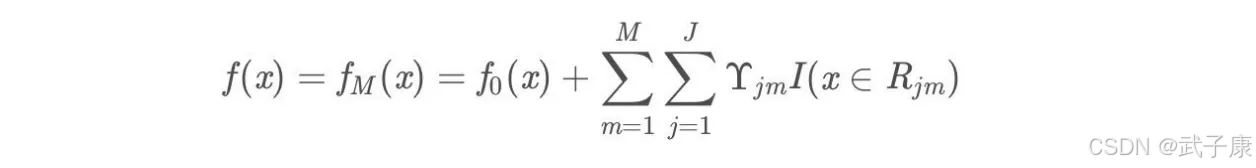
为什么效果好
- 任意可导损失:统一框架下同时处理回归、二分类、多分类、排名、异常检测(自定义损失)。
- 高阶非线性:树天然捕获特征交互,无需显式交叉特征工程。
- 抗尺度:对不同量级特征无需标准化。
- 可解释:基于树的内部结构可做特征重要度、SHAP 解释。
常见高效实现
- XGBoost:二阶近似、稀疏感知、Block 近似直方图,加 L1/L2 正则。
- LightGBM:GOSS 行采样+EFB 特征并列,叶子优先生长,高速+低耗内存。
- CatBoost:针对类别特征的有序目标编码,内置对称树,支持文本特征。
它们都在经典 GBDT 框架上做了大量工程与算法加速,但核心思想(负梯度+浅树叠加)不变。
何时使用 / 何时不用
- 适用:结构化表格数据、特征之间存在复杂非线性关系、不想做大量特征工程。
- 不适:高维稀疏文本、图像、语音等深度学习占优场景;数据量极大但特征简单时线性模型更高速。
这里可以放一小段代码:
from xgboost import XGBClassifier
model = XGBClassifier(n_estimators=300,max_depth=6,learning_rate=0.05,subsample=0.8,colsample_bytree=0.8,objective='binary:logistic',eval_metric='auc'
)
model.fit(X_train, y_train,eval_set=[(X_val, y_val)],early_stopping_rounds=50)