机器学习——SVM
1.什么是SVM
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。
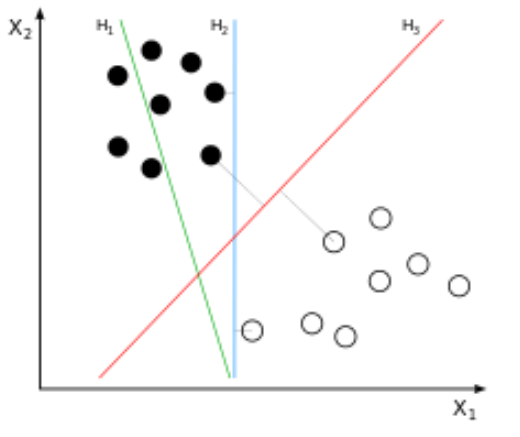
1.1 线性可分
对于一个数据集合可以画一条直线将两组数据点分开,这样的数据成为线性可分
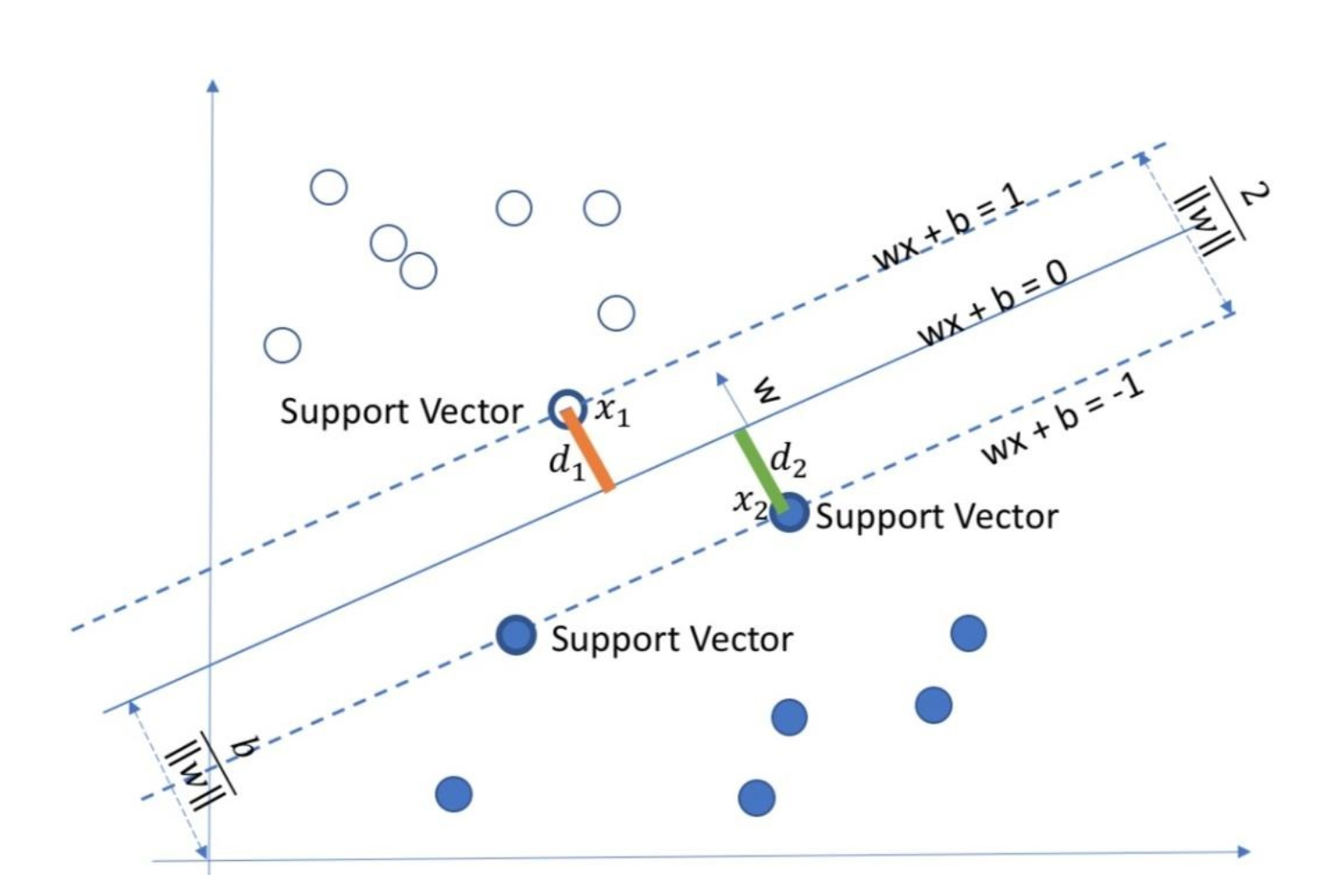
1.2超平面
将数据集分隔开来的平面称为分隔超平面。对于二维平面来说,分隔超平面就是一条直线。对于三维及三维以上的数据来说,分隔数据的是个平面,也就是分类的决策边界。
1.3间隔
点到分割面的距离,称为点相对于分割面的间隔。数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。SVM分类器就是要找最大的数据集间隔。
SVM 将会寻找可以区分两个类别并且能使间隔(margin)最大的划分超平面。比较好的划分超平面,样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。
1.4支持向量
离分隔超平面最近的那些点。
2.如何找到超平面?
Vapnik提出了一种方法,对每一种可能的超平面,我们将它进行平移,直到它与空间中的样本向量相交。我们称这两个向量为支持向量,之后我们计算支持向量到该超平面的距离d,分类效果最好的超平面应该使d最大。
2.1 寻找最大间隔
(1)分隔超平面
二维空间一条直线的方程为,y=ax+b,推广到n维空间,就变成了超平面方程,即
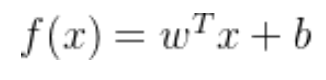
w是权重,b是截距,训练数据就是训练得到权重和截距。
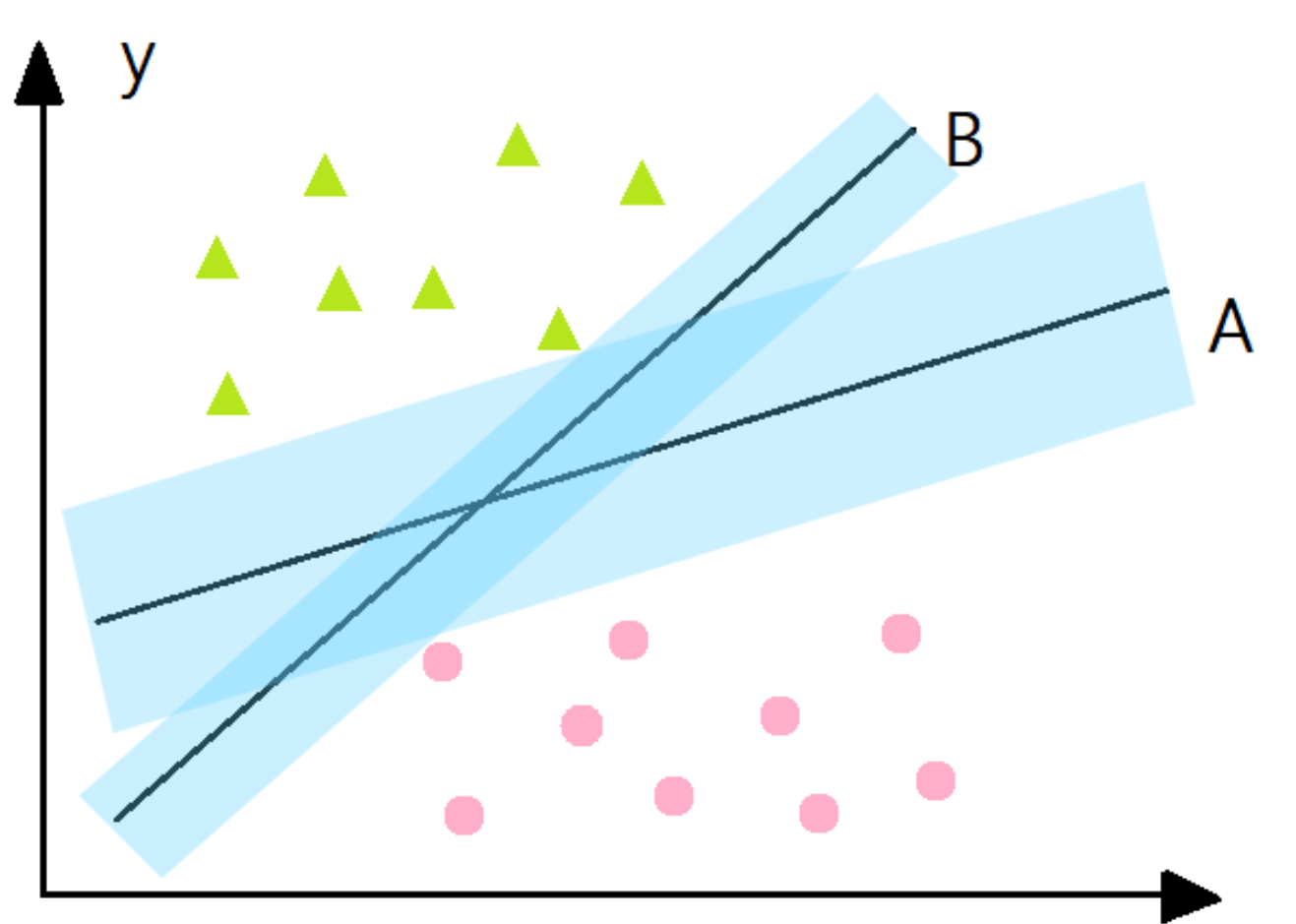
(2)如何找到最好的参数
支持向量机的核心思想: 最大间隔化, 最不受到噪声的干扰。如上图所示,分类器A比分类器B的间隔(蓝色阴影)大,因此A的分类效果更好。
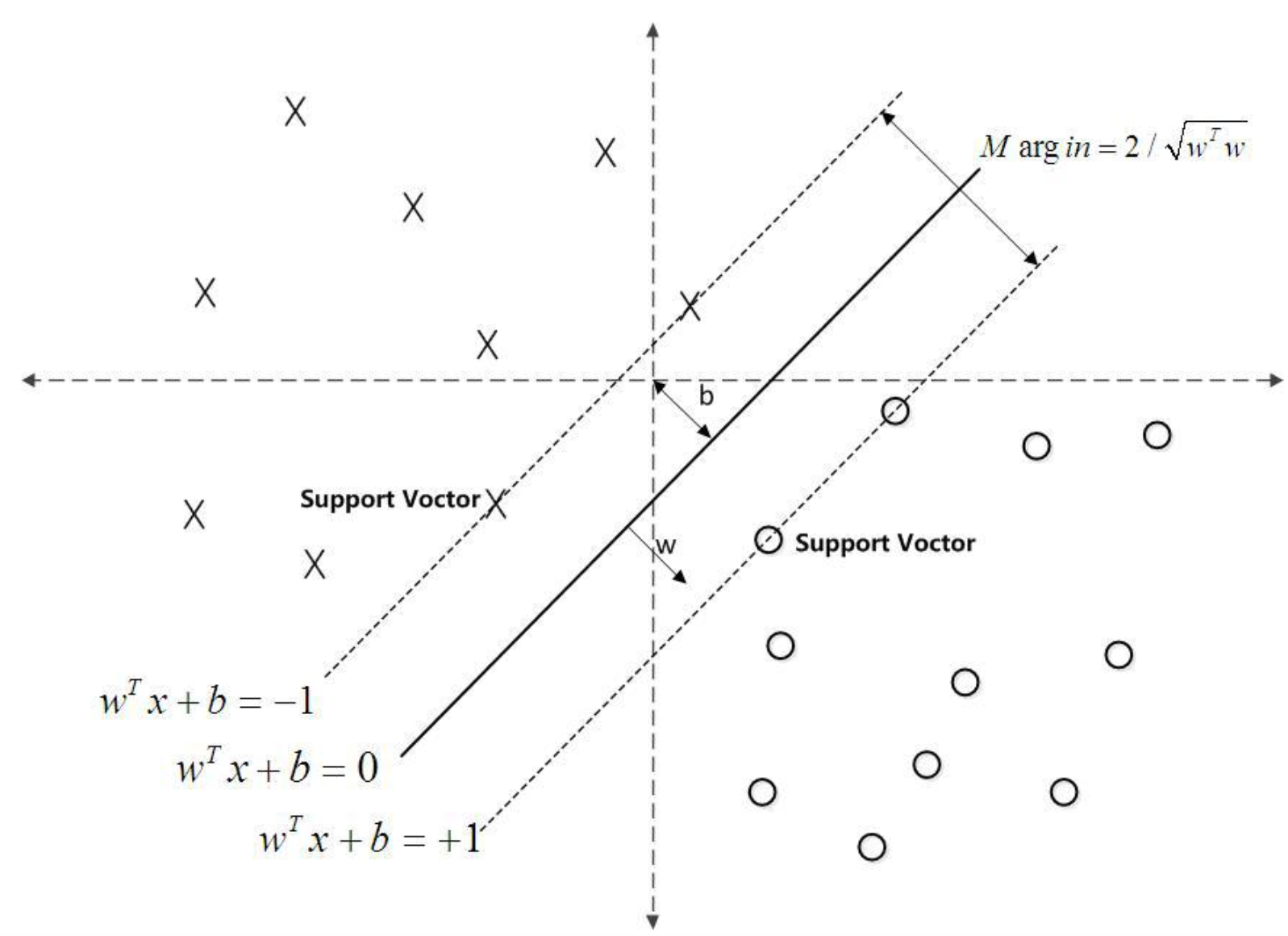
SVM划分的超平面:f(x) = 0,w为法向量,决定超平面方向,
假设超平面将样本正确划分
f(x) ≥ 1,y = +1
f(x) ≤ −1,y = −1
间隔:r=2/|w|
约束条件:
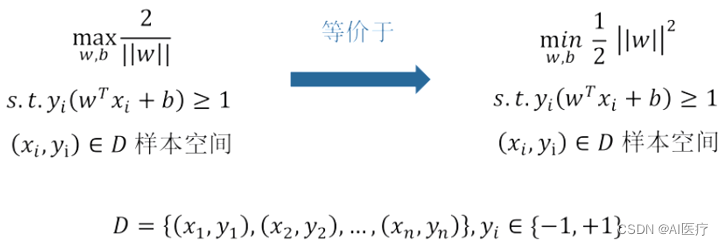
对于有约束条件的最优问题,利用拉格朗日乘子法与对偶即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
3.核函数
将原始空间中的向量作为输入向量,并返回特征空间(转换后的数据空间,可能是高维)中向量的点积的函数称为核函数
3.1作用
当遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的,此时就需要使用核函数。
核函数虽然也是将特征进行从低维到高维的转换,但核函数会先在低维上进行计算,而将实质上的分类效果表现在高维上,避免了直接在高维空间中的复杂计算。
核函数方法处理非线性问题的基本思想:按一定的规则进行映射,使得原来的数据在新的空间中变成线性可分的,从而就能使用之前推导的线性分类算法进行处理。计算两个向量在隐式映射过后的空间中的内积的函数叫做核函数、
4.SVM优缺点
(1)SVM的优点:
高效的处理高维特征空间:SVM通过将数据映射到高维空间中,可以处理高维特征,并在低维空间中进行计算,从而有效地处理高维数据。
适用于小样本数据集:SVM是一种基于边界的算法,它依赖于少数支持向量,因此对于小样本数据集具有较好的泛化能力。
可以处理非线性问题:SVM使用核函数将输入数据映射到高维空间,从而可以解决非线性问题。常用的核函数包括线性核、多项式核和径向基函数(RBF)核。
避免局部最优解:SVM的优化目标是最大化间隔,而不是仅仅最小化误分类点。这使得SVM在解决复杂问题时能够避免陷入局部最优解。
对于噪声数据的鲁棒性:SVM通过使用支持向量来定义决策边界,这使得它对于噪声数据具有一定的鲁棒性。
(2)SVM的缺点:
对大规模数据集的计算开销较大:SVM的计算复杂度随着样本数量的增加而增加,特别是在大规模数据集上的训练时间较长。
对于非线性问题选择合适的核函数和参数较为困难:在处理非线性问题时,选择适当的核函数和相应的参数需要一定的经验和领域知识。
对缺失数据敏感:SVM在处理含有缺失数据的情况下表现不佳,因为它依赖于支持向量的定义。
难以解释模型结果:SVM生成的模型通常是黑盒模型,难以直观地解释模型的决策过程和结果。
SVM在处理小样本数据、高维特征空间和非线性问题时表现出色,但对于大规模数据集和缺失数据的处理相对困难。同时,在模型的解释性方面也存在一定的挑战。
5.实践
# main.py
from utils import load_vocab, email_to_feature_vector
from model import train_svm_classifier, evaluate_model
from visualization import plot_decision_boundary, plot_top_features
import scipy.io
import numpy as npdef main():# 1. 加载数据vocab = load_vocab('E:\\University\\2xia\MachineLearning\\pythonProject6\\data\\vocab.txt')train_data = scipy.io.loadmat('E:\\University\\2xia\\MachineLearning\\pythonProject6\\data\\spamTrain.mat')test_data = scipy.io.loadmat('E:\\University\\2xia\\MachineLearning\\pythonProject6\\data\\spamTest.mat')X_train = train_data['X']y_train = train_data['y'].ravel()X_test = test_data['Xtest']y_test = test_data['ytest'].ravel()# 2. 训练模型clf = train_svm_classifier(X_train, y_train)# 3. 评估模型train_acc, test_acc = evaluate_model(clf, X_train, y_train, X_test, y_test)print(f"训练集准确率: {train_acc * 100:.2f}%")print(f"测试集准确率: {test_acc * 100:.2f}%")# 4. 可视化plot_decision_boundary(clf, X_train, y_train, vocab)plot_top_features(clf, vocab)# 5. 测试示例邮件with open('emailSample1.txt', 'r') as f:sample_email = f.read()prediction = classify_email(sample_email, vocab, clf)print(f"\n示例邮件分类结果: {prediction}")if __name__ == "__main__":main()# model.py
from sklearn import svm
from sklearn.metrics import accuracy_scoredef train_svm_classifier(X_train, y_train, C=1.0):"""训练SVM分类器"""clf = svm.SVC(kernel='linear', C=C)clf.fit(X_train, y_train)return clfdef evaluate_model(clf, X_train, y_train, X_test, y_test):"""评估模型性能"""train_pred = clf.predict(X_train)test_pred = clf.predict(X_test)train_acc = accuracy_score(y_train, train_pred)test_acc = accuracy_score(y_test, test_pred)return train_acc, test_acc# utils.py
import numpy as npdef load_vocab(vocab_file):"""加载词汇表文件"""vocab = {}with open(vocab_file) as f:for line in f:idx, word = line.strip().split('\t')vocab[word] = int(idx)return vocabdef email_to_feature_vector(email, vocab):"""将电子邮件文本转换为特征向量"""features = np.zeros(len(vocab))words = email.lower().split()for word in words:word = ''.join([c for c in word if c.isalpha()])if word in vocab:features[vocab[word] - 1] += 1return featuresdef classify_email(email_content, vocab, clf):"""分类单个邮件"""features = email_to_feature_vector(email_content, vocab)prediction = clf.predict([features])return "垃圾邮件" if prediction[0] == 1 else "非垃圾邮件"import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.decomposition import PCAdef plot_decision_boundary(clf, X, y, vocab):"""仅绘制两个类别样本点、超平面和软间隔边界"""# 使用PCA降维pca = PCA(n_components=2)X_2d = pca.fit_transform(X)# 在降维数据上重新训练SVMclf_2d = SVC(kernel='linear', C=1.0) # 使用默认软间隔参数clf_2d.fit(X_2d, y)# 创建网格x_min, x_max = X_2d[:, 0].min() - 1, X_2d[:, 0].max() + 1y_min, y_max = X_2d[:, 1].min() - 1, X_2d[:, 1].max() + 1h = (x_max - x_min) / 200 # 增加网格密度xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))# 绘制超平面和软间隔边界plt.figure(figsize=(10, 8))# 绘制两个类别的训练样本点plt.scatter(X_2d[y == 0][:, 0], X_2d[y == 0][:, 1],c='blue', marker='o', s=50, alpha=0.7, label='Class 0')plt.scatter(X_2d[y == 1][:, 0], X_2d[y == 1][:, 1],c='red', marker='x', s=50, alpha=0.7, label='Class 1')# 计算超平面和间隔边界Z = clf_2d.decision_function(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)# 绘制超平面(实线黑色)plt.contour(xx, yy, Z, levels=[0], linewidths=2.5, linestyles='-', colors='black')# 绘制间隔边界(虚线黑色)plt.contour(xx, yy, Z, levels=[-1, 1], linewidths=2, linestyles='--', colors='black')# 添加图例和标签plt.legend(fontsize=12)plt.grid(True, linestyle='--', alpha=0.5)plt.xlabel('PCA Component 1', fontsize=12)plt.ylabel('PCA Component 2', fontsize=12)plt.title('SVM Hyperplane and Soft Margins with Two Classes', fontsize=14)plt.tight_layout()plt.savefig('svm_hyperplane_margins.png', dpi=300) # 保存高分辨率图像plt.close()def plot_top_features(clf, vocab, n=20):"""绘制最重要的特征词汇"""weights = clf.coef_[0]idx_to_word = {idx: word for word, idx in vocab.items()}# 获取最重要的词汇top_indices = np.argsort(np.abs(weights))[-n:][::-1]top_words = [idx_to_word[idx + 1] for idx in top_indices]top_weights = weights[top_indices]plt.figure(figsize=(10, 8))colors = ['red' if w > 0 else 'blue' for w in top_weights]bars = plt.barh(top_words, top_weights, color=colors)plt.xlabel('特征权重', fontsize=12)plt.ylabel('特征词汇', fontsize=12)plt.title('最重要的20个特征词汇', fontsize=14)# 添加数据标签for bar in bars:width = bar.get_width()plt.text(width, bar.get_y() + bar.get_height() / 2,f'{width:.2f}', ha='left', va='center', fontsize=10)plt.tight_layout()plt.savefig('top_features.png', dpi=300)plt.close()运行结果
思路
该项目构建一个垃圾邮件分类系统,利用支持向量机(SVM)算法对邮件进行分类。项目的整体思路如下:
数据准备
从 vocab.txt 文件中加载词汇表,将其存储为字典形式,方便后续将邮件文本转换为特征向量。同时,使用 scipy.io.loadmat 函数加载 spamTrain.mat 和 spamTest.mat 文件,分别作为训练集和测试集。
特征提取
通过 email_to_feature_vector 函数将邮件文本转换为特征向量。该函数首先将邮件文本转换为小写,并按空格分割成单词。然后,去除每个单词中的非字母字符,并检查该单词是否在词汇表中。如果存在,则将对应位置的特征值加 1。
模型训练
使用 train_svm_classifier 函数训练 SVM 分类器。该函数使用线性核函数和默认的软间隔参数 C=1.0 进行训练。
模型评估
使用 evaluate_model 函数评估模型的性能。该函数分别计算训练集和测试集的准确率,并打印输出。
可视化
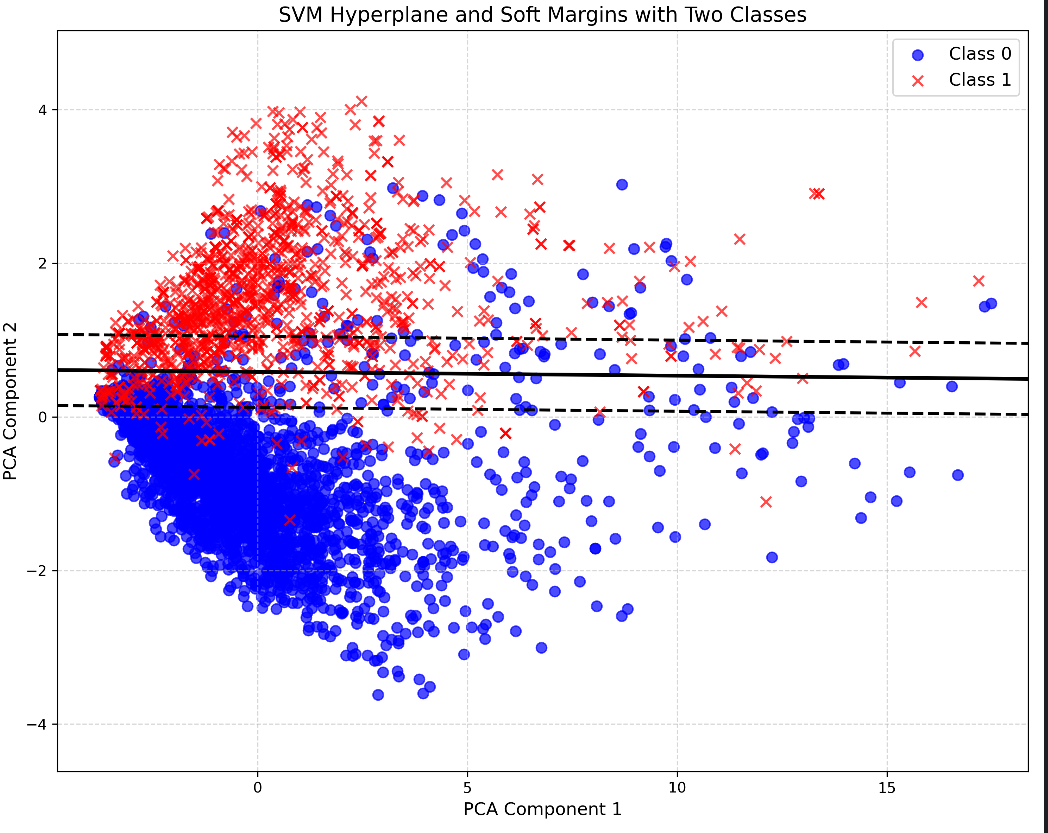
使用 plot_decision_boundary 函数绘制 SVM 的决策边界和软间隔边界。该函数首先使用主成分分析(PCA)将高维数据降维到二维,然后在降维后的数据上重新训练 SVM 分类器。最后,使用 matplotlib 库绘制样本点、超平面和软间隔边界,并保存为 svm_hyperplane_margins.png 文件。
使用 plot_top_features 函数绘制最重要的特征词汇。该函数首先获取 SVM 分类器的权重,然后选择权重绝对值最大的前 20 个特征词汇。最后,使用 matplotlib 库绘制这些特征词汇及其权重,并保存为 top_features.png 文件。
测试示例邮件
使用 classify_email 函数对示例邮件进行分类。该函数首先将邮件文本转换为特征向量,然后使用训练好的 SVM 分类器进行预测,并输出分类结果。