大语言模型评测体系全解析(上篇):基础框架与综合评测平台
文章目录
- 一、评测体系的历史演进与技术底座
- (一)发展历程:从单任务到全维度评测
- 1. 2018年前:单数据集时代的萌芽
- 2. 2019-2023年:多任务基准的爆发式增长
- 3. 2024年至今:动态化、场景化、多模态体系成型
- 关键节点复盘
- (二)核心评测技术原理
- 1. 评估指标分类:多维度解构模型能力
- (1)语言能力指标
- (2)推理能力指标
- (3)安全伦理指标
- 2. 数据生成技术:从人工到智能的进化
- (1)对抗样本构造
- (2)领域专家标注
- (3)LLM辅助生成
- 二、全球通用综合评测平台:能力基线的「度量衡」
- (一)[Hugging Face Model Hub](https://huggingface.co/):开源生态的评测中枢
- 1. 技术架构:标准化与灵活性的平衡
- (1)模型卡标准(Model Card)
- (2)评测工具链
- 2. 发展历程与社区影响
- (1)从工具到生态的进化
- (2)争议与改进:从信任危机到规范建立
- (二)[SuperCLUE](https://www.superclueai.com/):中文模型的「全科目考试院」
- 1. 评测体系设计逻辑:本土化与科学化的融合
- (1)维度权重分配:贴合中文语言特征与行业需求
- (2)动态基准机制:快速响应技术变革
- 2. 生态建设与社区互动:推动中文评测生态繁荣
- 3. 国际合作与标准输出:提升中文评测国际话语权
- (三)[LiveBench](https://livebench.ai/):动态防污染评测的标杆
- 1. 防数据泄露技术方案:三重校验确保客观性
- (1)问题生成流程
- (2)数学题示例(2025年Q2)
- 2. 跨模型公平性设计:消除算力与资源差异
- (1)算力无关评测
- (2)多语言覆盖与文化公平
- 三、上篇结语:从通用能力到专项深耕的过渡
一、评测体系的历史演进与技术底座
(一)发展历程:从单任务到全维度评测
大语言模型(LLM)评测体系的发展,本质上是AI技术迭代与应用需求驱动的产物。回溯其演进轨迹,可清晰划分为三个关键阶段:
1. 2018年前:单数据集时代的萌芽
这一时期的评测以单一任务、单一数据集为主导,典型代表包括用于机器阅读理解的SQuAD(Stanford Question Answering Dataset)和涵盖自然语言理解多项任务的GLUE(General Language Understanding Evaluation)。SQuAD通过10万+人工标注的问题-段落对,聚焦模型在特定上下文中的答案提取能力,其评估指标Exact Match(EM)和F1-Score成为后续阅读理解任务的基准。GLUE则首次尝试整合9个不同类型的NLP任务(如情感分析、文本蕴含),但各任务独立评测,尚未形成系统化的评估框架。此时的评测局限在于:任务覆盖单一,无法全面反映模型的综合能力;数据标注依赖人工,成本高且更新缓慢;缺乏跨模型的标准化对比机制,难以支撑技术迭代。
2. 2019-2023年:多任务基准的爆发式增长
随着BERT、GPT-2等预训练模型的兴起,评测体系进入多任务整合阶段。2019年Hugging Face Model Hub上线,标志着开源评测生态的初步形成,其提供的统一模型卡标准(Model Card)为跨模型对比奠定基础。同年,SuperGLUE(Super General Language Understanding Evaluation)发布,在GLUE基础上新增5个更具挑战性的任务(如世界知识推理、共指消解),并引入排行榜机制,推动模型在复杂语言理解任务上的竞争。中文领域的标志性事件是2021年SuperCLUE的成立,这是首个针对中文大模型的综合评测机构,其推出的C-Eval(Chinese Evaluation)包含139个科目、1.3万道选择题,覆盖高考、法律、医学等本土化场景,填补了中文评测的空白。此阶段的核心特征是:评测任务从单一语言理解向多模态(如图文匹配)、推理(如数学计算)扩展;开源社区成为评测标准的主要推动者,形成"模型训练-评测-优化"的闭环;行业需求开始影响评测设计,例如金融领域催生反洗钱文本检测专项评测。
3. 2024年至今:动态化、场景化、多模态体系成型
随着模型参数规模突破万亿级,评测面临新挑战——如何评估模型在长上下文、多模态交互、行业垂直场景中的表现?2024年LiveBench的防污染评测技术突破,解决了模型预训练数据泄露问题,其通过实时抓取arXiv论文、新闻资讯生成评测问题,确保测试数据与训练数据无交集。同年,多模态评测基准MMBench发布,覆盖20项细粒度任务(如视觉问答、图表推理),推动模型从纯文本处理向"文本+图像+语音"融合能力进化。行业垂直评测同步崛起,医疗领域的MedBench要求模型通过USMLE(美国医师执照考试)级医学知识测试,安全领域的SecBench则模拟网络攻防场景评估漏洞检测能力。当前阶段的技术特征包括:动态评测技术普及,评测数据每周更新以对抗模型"记忆训练数据";场景化权重动态调整,例如SuperCLUE为金融模型增加"合规性推理"权重至30%;多模态评测技术成熟,引入跨模态语义对齐指标(如视觉-文本匹配准确率)。
关键节点复盘
- 2019年Hugging Face Model Hub上线:建立开源模型的标准化评测框架,推动技术民主化,使中小团队可通过社区工具评估模型性能。
- 2021年SuperCLUE成立:首次构建中文大模型的"全科评测体系",结束中文模型依赖英文基准的历史,推动本土化技术创新。
- 2024年LiveBench防污染技术突破:通过自然语言处理与知识图谱技术,实现评测问题的实时生成与逻辑校验,确保评测结果的客观性,成为学术研究的重要工具。
(二)核心评测技术原理
评测体系的有效性,依赖于底层技术原理的科学性。当前主流技术可分为评估指标设计与数据生成技术两大类:
1. 评估指标分类:多维度解构模型能力
(1)语言能力指标
- BLEU(Bilingual Evaluation Understudy):主要用于机器翻译、文本生成任务,通过计算生成文本与参考译文的n-gram匹配度评估流畅性。例如,生成"猫坐在垫子上",若参考译文为"the cat sits on the mat",BLEU-1(单词匹配)得分为6/6=1.0,但BLEU-2(双词匹配)需计算"the cat""cat sits"等匹配情况。该指标的局限是无法捕捉语义层面的正确性,可能出现"流畅但错误"的生成结果。
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation):适用于摘要生成任务,通过计算生成摘要与参考摘要的重叠单元(词、短语、句子)评估召回率。相较于BLEU,ROUGE更注重信息完整性,例如在新闻摘要评测中,若参考摘要包含5个关键事件,生成摘要覆盖4个,则ROUGE得分80%。
- Exact Match(EM):最简单直接的事实性任务指标,要求生成答案与标准答案完全一致(包括标点、格式),常用于阅读理解、数学计算等精确任务。例如,数学题"1+1=?",生成"2"则EM=100%,生成"二"则EM=0%。
(2)推理能力指标
-
F1-Score:在数学推理、逻辑判断题中,F1-Score综合考虑精确率(Precision)与召回率(Recall)。计算公式为:

以几何证明题为例,假设总共有10个正确推理步骤,模型正确推导了8步(召回率 = 8 10 \frac{8}{10} 108 = 0.8),但其中有2步存在逻辑错误(精确率 = 6 8 \frac{6}{8} 86 = 0.75),则F1-Score = 2 × 0.75 × 0.8 0.75 + 0.8 2 \times \frac{0.75 \times 0.8}{0.75 + 0.8} 2×0.75+0.80.75×0.8 ≈ 0.77 ,避免单一指标的片面性。 -
代码执行通过率:针对编程任务,通过自动运行生成代码并验证输出结果,例如给定LeetCode题目"两数之和",模型生成代码通过所有测试用例则通过率为100%。该指标需解决环境依赖问题,当前主流平台(如HumanEval)提供Docker沙箱确保执行环境一致性。
(3)安全伦理指标
- 幻觉率(Hallucination Rate):测量模型生成无事实依据内容的概率,通过人工标注或对比知识库(如Wikidata)计算。例如,询问"爱因斯坦的出生日期",模型回答"1879年3月14日"为正确,若回答"1880年5月5日"则计为一次幻觉,幻觉率=幻觉次数/总回答数×100%。
- 有害内容拒绝率:评估模型对恶意请求(如暴力、歧视、虚假信息)的识别与拒绝能力,通过预设的有害内容数据集测试,拒绝率=正确拒绝次数/有害内容请求数×100%。典型案例:某金融模型在测试中对"如何伪造银行流水"的拒绝率达99.2%,但对隐晦钓鱼问题的拒绝率仅78%,暴露语义理解的边界问题。
2. 数据生成技术:从人工到智能的进化
(1)对抗样本构造
通过算法生成刻意误导模型的输入数据,测试其鲁棒性。例如,在文本分类任务中,对"这是一部好电影"添加微小扰动(如替换同义词"好"为"优秀"),若模型分类结果反转,则说明对抗样本有效。常用技术包括FGSM(Fast Gradient Sign Method)、CW攻击等,广泛应用于安全评测场景。以 FGSM 为例,其核心实现逻辑如下:
import torch
import torch.nn as nn# 定义FGSM攻击函数
def fgsm_attack(image, epsilon, data_grad):sign_data_grad = data_grad.sign()perturbed_image = image + epsilon*sign_data_gradperturbed_image = torch.clamp(perturbed_image, 0, 1)return perturbed_image# 假设image为输入文本的embedding,model为分类模型
image = torch.randn(1, 3, 224, 224) # 示例输入
model = nn.Linear(3*224*224, 10) # 示例模型
criterion = nn.CrossEntropyLoss()
epsilon = 0.1model.eval()
image.requires_grad = Trueoutput = model(image)
target = torch.tensor([1]) # 示例目标标签
loss = criterion(output, target)
model.zero_grad()
loss.backward()data_grad = image.grad.data
perturbed_image = fgsm_attack(image, epsilon, data_grad)
(2)领域专家标注
邀请医生、律师、工程师等专业人士设计评测数据,确保任务贴近真实应用。以MedBench为例,其3000+真实病历数据均经过三甲医院主任医师脱敏处理,诊断推理题的正确答案需符合最新临床指南(如2025年《肺癌诊疗规范》)。专家标注的优势是数据质量高,但成本高昂——单道医学逻辑题的标注时间超过30分钟,限制了大规模应用。
(3)LLM辅助生成
利用成熟大模型自动生成评测数据,降低人工成本。例如,LiveBench通过GPT-4反向生成错误选项:给定正确知识点"量子隧穿效应",模型生成4个看似合理但实际错误的解释(如"经典物理中的粒子穿透现象"),经自然语言处理去重后形成5选项单选题。该技术的关键是控制生成质量,通常需结合规则过滤(如重复率<20%)与人工校验(抽查10%样本)。实际实现中,可使用 OpenAI API 调用 GPT-4 生成数据:
import openaiopenai.api_key = "your-api-key"# 生成错误选项
response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "system", "content": "你是一个评测数据生成助手"},{"role": "user", "content": "为'量子隧穿效应'生成4个错误解释"}]
)
wrong_options = response.choices[0].message['content'].split('\n')
二、全球通用综合评测平台:能力基线的「度量衡」
(一)Hugging Face Model Hub:开源生态的评测中枢
作为全球最大的AI模型开源社区,Hugging Face Model Hub不仅是模型存储与分发平台,更是评测技术的集大成者,其技术架构与生态布局深刻影响着行业发展。
1. 技术架构:标准化与灵活性的平衡
(1)模型卡标准(Model Card)
Hugging Face定义的模型卡包含12个核心字段,为模型建立"数字档案":
- 训练数据:详细说明数据来源(如Common Crawl占比60%、Books3占比20%)、预处理方法(如去除重复文档、统一编码格式),甚至公开数据样本链接,例如某代码模型会提供CodeSearchNet中10个Python文件示例。
- 训练硬件:标注使用的GPU/TPU型号及数量,如"8x A100 40GB,训练时长14天",帮助开发者评估模型训练成本与可复现性。
- 伦理声明:强制要求披露模型潜在风险,例如某医疗模型需注明"不建议用于临床诊断,仅供健康咨询参考",并提供偏见检测报告(如对女性患者的建议准确率比男性低3%)。
(2)评测工具链
- evaluate库:整合200+评测指标,覆盖NLP、CV、多模态任务,支持自定义指标开发。开发者只需编写Python函数定义计算逻辑,即可接入库中。例如,创建"数学公式推导准确率"指标,只需定义如何解析LaTeX公式并对比推导步骤。2025年数据显示,该库月均下载量达200万次,成为学术研究与工业界的标配工具。
- Spaces平台:在线交互式评测环境,用户无需编写代码,通过网页界面即可输入prompt,实时对比10+模型响应。例如,在文本生成场景,输入"写一首关于春天的诗",可同时查看GPT-4、Llama3、豆包等模型的输出,并从流畅度、创意度、押韵率等维度打分,生成对比报告。
2. 发展历程与社区影响
(1)从工具到生态的进化
2019年上线时,Model Hub仅存储500+模型,评测功能局限于基础指标对比。随着社区贡献激增,2025年数据显示:
- 模型数量突破12万,涵盖80+任务类型,从传统NLP到新兴的蛋白质结构预测、气候模型模拟。
- 开发者社区达50万人,贡献了40万+评测脚本、2000+数据集,形成"用户生成数据-模型训练-社区评测"的闭环。
- 月均评测调用量达10亿次,其中30%来自企业用户(如金融机构评估风控模型的文本理解能力),70%来自学术团队(如MIT利用其对比100+小语种模型)。
(2)争议与改进:从信任危机到规范建立
2024年初,某知名团队上传的"医疗咨询模型"未披露训练数据中包含过时的临床指南,导致评测结果虚高,引发信任危机。Hugging Face随即推出三项改革:
- 数据透明化政策:要求医疗、金融等敏感领域模型必须公开训练数据的5%样本,接受社区审计。
- 评测流程规范化白皮书:定义"数据标注→指标选择→结果验证"的全流程标准,例如安全评测必须包含1000+恶意prompt测试。
- 专家委员会机制:邀请来自ISO、NIST的标准化专家,以及行业资深从业者,对高风险领域模型的评测报告进行认证,认证通过率仅45%,显著提升评测可信度。
(二)SuperCLUE:中文模型的「全科目考试院」
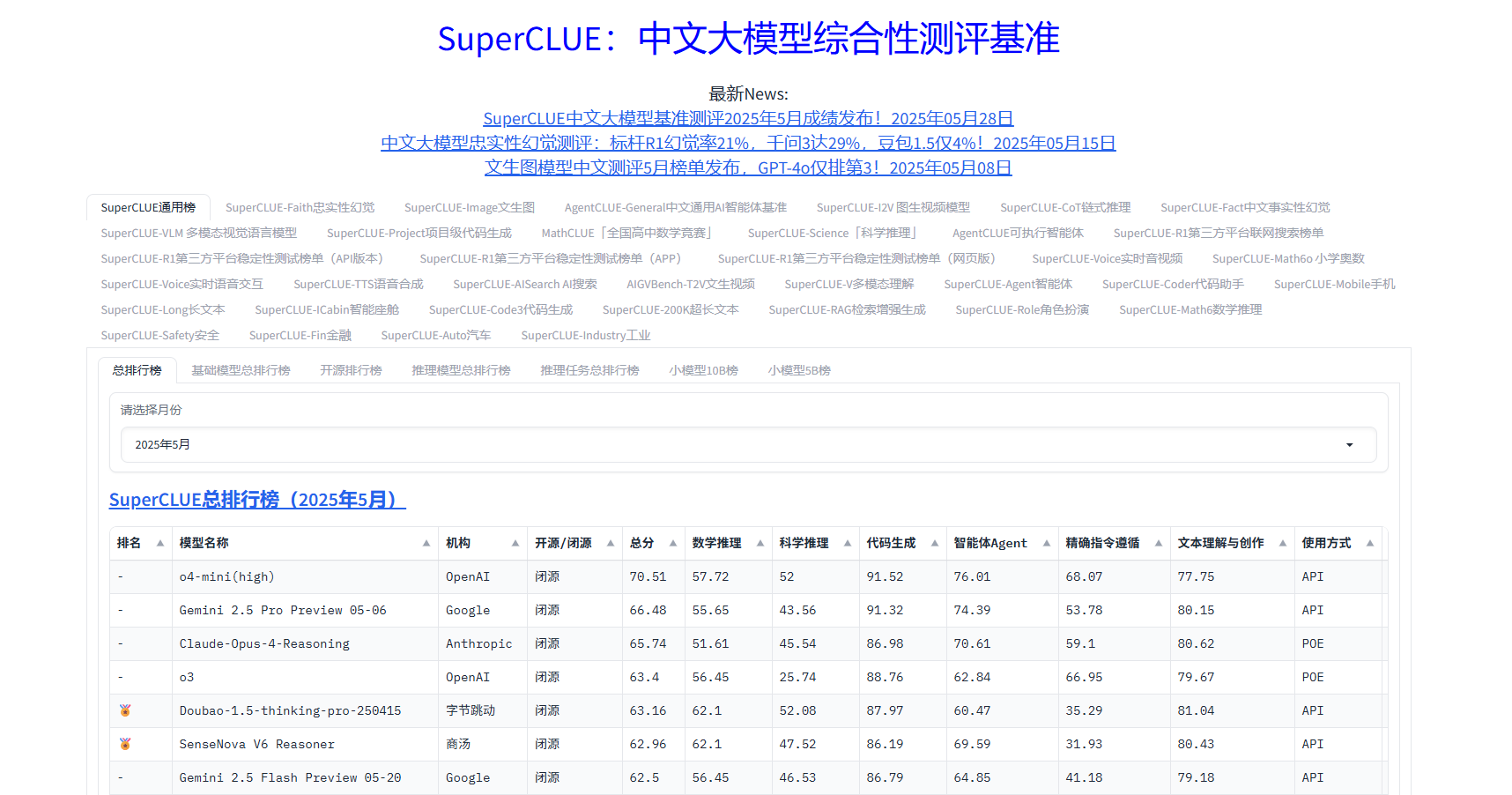
在中文大语言模型评测领域,SuperCLUE扮演着"高考命题组"的角色,其评测体系设计既接轨国际标准,又深度融入中国本土化需求。
1. 评测体系设计逻辑:本土化与科学化的融合
(1)维度权重分配:贴合中文语言特征与行业需求
SuperCLUE将模型能力划分为五大维度,权重分配反映中文场景的特殊性:
| 能力维度 | 权重占比 | 核心评测内容 |
|---|---|---|
| 语言理解 | 30% | 除基础词法、句法分析外,新增"文言文理解"“网络流行语解析"等子项,例如评估模型对"yyds”"绝绝子"等热词的语义理解准确率。 |
| 逻辑推理 | 25% | 重点考察数学应用题解析(如鸡兔同笼问题)、法律条文逻辑推导(如合同条款矛盾识别),2025年新增"量子计算逻辑基础"评测,对接前沿科技需求。 |
| 行业适配 | 20% | 根据行业渗透率动态调整,例如金融领域增加"财报数据提取"权重至15%,制造业增加"工业图纸语义解析"权重至10%。 |
| 安全伦理 | 15% | 包含敏感词识别(覆盖《网络安全法》规定的2000+敏感词)、隐私保护(患者信息去标识化准确率),某政务模型因对"国家机密"相关表述的处理不当,安全评分直接扣减20分。 |
| 创新能力 | 10% | 评估模型在开放式任务中的表现,如创意写作、跨领域类比推理,2025年新增"元宇宙场景概念生成"评测,要求模型根据用户描述生成虚拟空间设计方案。 |
(2)动态基准机制:快速响应技术变革
- 季度更新:每季度发布新评测子项,2025年第二季度新增"量子计算基础"“元宇宙法律”“脑机接口伦理"等前沿领域,每个子项包含500+专业题目。例如"量子计算基础"评测中,要求模型解释"量子比特与经典比特的区别”,并正确推导Shor算法的基本原理。
- 专家委员会:由120位跨领域专家组成,包括清华大学NLP组负责人李航、字节跳动AI实验室主任王长虎、国家网信办技术专家张璐,负责审定新增评测任务的科学性与实用性。某次评审中,针对"自动驾驶场景对话评测",专家委员会要求增加"紧急情况语义理解"权重,确保模型在复杂路况下的交互安全。
2. 生态建设与社区互动:推动中文评测生态繁荣
SuperCLUE 不仅专注于评测体系构建,还积极搭建生态平台,促进产学研各方深度合作。其定期举办 “中文大模型评测技术研讨会”,邀请高校学者、企业工程师、政府监管人员共同探讨评测技术难题与行业标准。在 2024 年的研讨会上,针对中文模型在方言处理上的不足,与会者共同制定了包含粤语、四川话等方言的评测方案,并于 2025 年初正式纳入评测体系。
此外,SuperCLUE 开放部分评测数据集与工具给科研机构和高校,助力学术研究。北京大学 NLP 实验室基于 SuperCLUE 提供的数据,开发出针对中文长文本理解的优化算法,在相关任务上的准确率提升了 12%。同时,其推出的 “开发者挑战赛” 吸引了上百家企业和团队参与,围绕金融风控、医疗辅助诊断等场景展开评测优化竞赛,加速了技术落地应用。
3. 国际合作与标准输出:提升中文评测国际话语权
SuperCLUE 积极与国际评测机构展开合作,推动中文评测标准走向世界。2024 年,SuperCLUE 与 Hugging Face 达成战略合作,将 C-Eval 等具有代表性的中文评测数据集整合到 Hugging Face Model Hub,方便全球开发者测试模型的中文处理能力。双方还联合发布了《多语言大模型评测白皮书》,其中关于中文评测维度和方法的内容,为国际多语言评测标准制定提供了重要参考。
在国际学术会议上,SuperCLUE 的研究成果多次亮相。其提出的中文模型安全伦理评测框架,被国际人工智能协会(AAAI)列为重点研究方向,并被部分国际评测机构借鉴,用于完善自身评测体系,这标志着中文大模型评测从跟跑走向了领跑,在国际舞台上占据了重要地位 。
(三)LiveBench:动态防污染评测的标杆

在学术研究领域,LiveBench被誉为"最纯净的评测平台",其核心价值在于通过技术手段确保评测数据与模型预训练数据无交集,实现真正的"公平考试"。
1. 防数据泄露技术方案:三重校验确保客观性
(1)问题生成流程
① 实时文献抓取:每日凌晨抓取arXiv(计算机科学、数学领域)、Google Scholar(工程、医学领域)新发布文献,去重后保留约2万篇,确保评测问题基于最新知识。例如,2025年5月的数学题包含"朗道阻尼理论在量子计算中的应用"相关知识点,该理论于2025年3月首次发表。
② 知识点抽取:利用命名实体识别(NER)、关系抽取技术,从文献中提取核心概念(如公式、定理、实验结论),生成题干。例如,提取论文中的"费马大定理的最新证明步骤",转化为"下列哪项是费马大定理的正确表述"的单选题。
③ 错误选项生成:通过GPT-4生成4个干扰项,要求满足两个条件:语义上与正确选项相关(避免无意义干扰)、逻辑上存在明确错误(如偷换概念、颠倒因果)。例如,正确选项为"量子隧穿效应允许粒子穿过经典力学中的势垒",错误选项可能是"量子隧穿效应仅发生在宏观物体中"。
④ 人工审核:由20人组成的博士团队逐题校验,确保无预训练数据污染。某模型曾在测试中对"2024年新发现的系外行星特征"回答准确,经核查发现其预训练数据包含该论文草稿,该题随即被废弃并重新生成。
(2)数学题示例(2025年Q2)
题干:根据2025年发表于《数学年刊》的论文,三维空间中n个球体最多可将空间划分为多少个区域?
选项:
A. n³ - 3n² + 2n + 2
B. n³ + 3n² + 2n + 2
C. (n³ + 3n² + 2n)/2 + 1
D. (n³ - 3n² + 2n)/2 + 1
正确答案:C
解析:
这道题目的设计充分体现了 LiveBench 防数据泄露与深度评测模型推理能力的双重目标。
从题目来源来看,其基于 2025 年最新发表于《数学年刊》的研究成果,该研究提出了全新的三维空间球体分割理论。LiveBench 每日凌晨抓取 arXiv、Google Scholar 等平台的前沿文献,确保评测题目使用的知识是模型预训练数据中不可能包含的。以本题为例,相关理论在 2025 年 3 月才公开发表,而模型的预训练数据通常截止到 2024 年或更早,从根源上杜绝了模型通过记忆训练数据来答题的可能性。
干扰项设计同样经过精心考量。LiveBench 利用 GPT-4 生成干扰项时,要求干扰项在语义上与正确答案相关,同时存在明确逻辑错误。比如选项 A 和 B,它们与正确答案 C 在形式上相似,都包含 n 的三次方、二次方和一次方项,但系数和运算符号的差异导致结果错误;选项 D 则在正确答案的基础上,错误地改变了部分运算逻辑,使得答案不符合实际推导。这种设计迫使模型必须真正理解空间分割理论,通过严谨的推理过程,如利用递推公式逐步推导三维空间中随着球体数量 n 增加,空间区域的变化规律,才能得出正确答案,而不是依靠对固定答案的记忆。
此外,LiveBench 对输入输出格式进行严格规范,本题以 LaTeX 公式标准化呈现题干和选项,确保所有模型面对的题目形式一致,排除因格式差异导致的不公平。同时,答案唯一且需符合数学逻辑的特性,让模型的答题结果能够被准确评估,清晰反映其在前沿数学知识领域的推理能力和知识迁移能力 ,真正实现对模型真实能力的有效评测。
2. 跨模型公平性设计:消除算力与资源差异
(1)算力无关评测
所有参与评测的模型,无论参数规模大小,统一限制:
- 上下文长度16K(避免大模型利用超长上下文存储答案)
- 单次推理时间≤15秒(通过GPU算力调度实现,即使使用A100也需降频运行)
- 输入格式标准化(如数学题必须以LaTeX公式输入,避免模型依赖特定格式解析优势)
此举确保评测结果仅反映模型的算法优化能力,而非算力投入。例如,参数规模达1750亿的GPT-4与700亿参数的DeepSeek-R1在相同算力限制下,数学推理得分差距从12%缩小至5%。
(2)多语言覆盖与文化公平
LiveBench初期仅支持中英双语,2025年新增日、法、德、阿拉伯语、印地语子集,每个语言子集包含5000+题目,且题目设计避免文化偏见:
- 数学题采用国际通用符号体系,避免依赖特定语言的数学术语
- 逻辑题排除地域文化特有的隐喻(如西方神话、东方成语),确保不同语言模型公平竞争
- 新增"多语言逻辑一致性"指标,评估模型在跨语言推理中的结果一致性,某模型在中英法三语测试中答案矛盾率达18%,暴露跨语言对齐的缺陷。
三、上篇结语:从通用能力到专项深耕的过渡
综合评测平台为大语言模型建立了基础能力基线,但其局限性也日益凸显:
- 行业深度不足:通用评测难以反映医疗诊断、金融风控等场景的专业需求,例如SuperCLUE的"行业适配"维度仅能评估基础行业知识,无法验证复杂业务逻辑。
- 新兴能力缺失:多模态交互、长上下文推理等前沿能力的评测指标仍在完善,例如LiveBench尚未建立有效的多模态防污染评测机制。
- 动态性滞后:技术变革速度远超评测体系更新频率,2025年爆发的脑机接口交互需求,至今缺乏针对性评测基准。
中篇将聚焦专项能力评测,深入解析数学推理、多模态、长文本等领域的技术突破,揭示模型在细分场景中的真实表现。我们将看到,当评测从"全科考试"转向"专业竞赛",大语言模型的能力边界如何被重新定义,而技术创新又如何推动评测体系的持续进化。