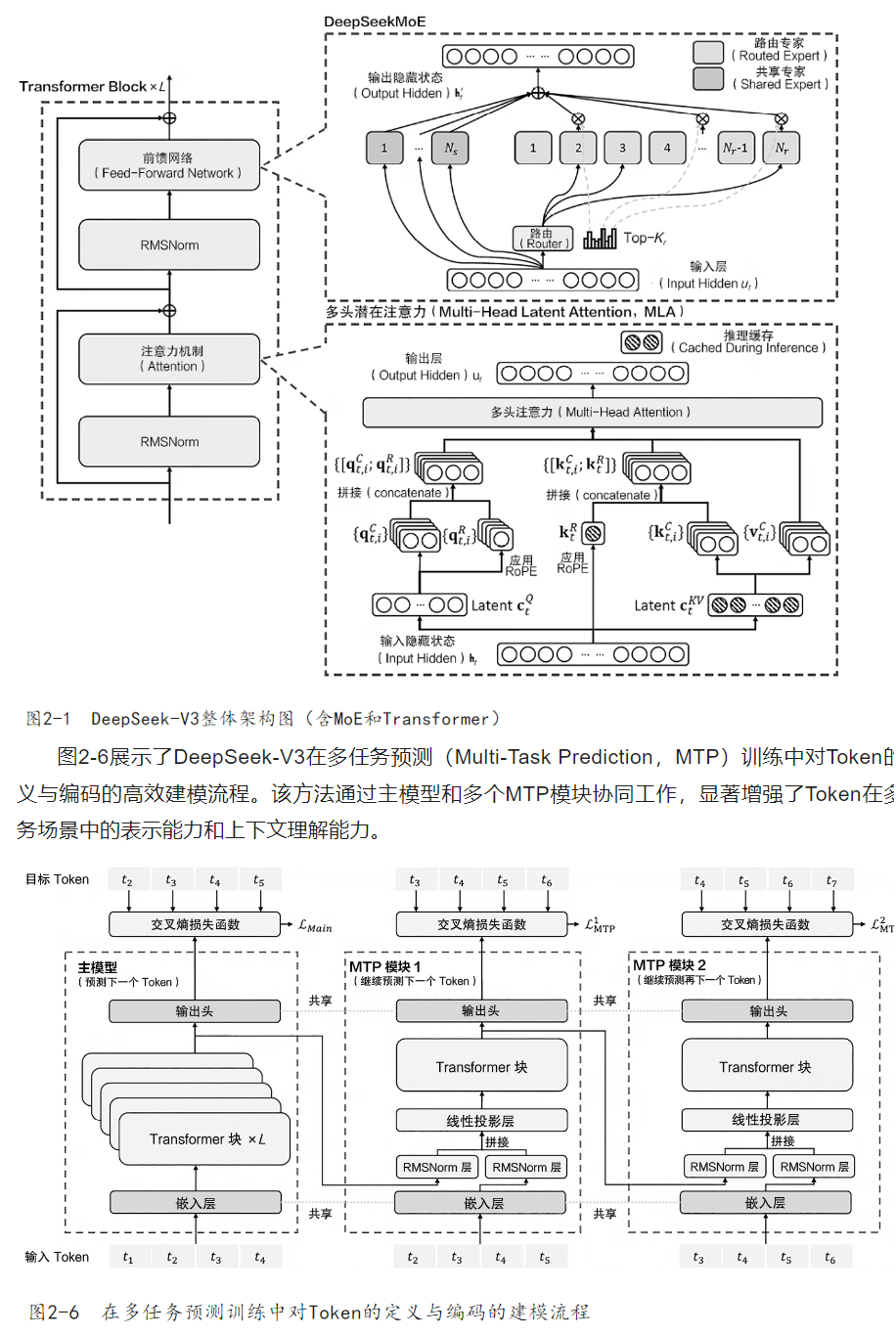
deepseek原理和项目实战笔记2 -- deepseek核心架构
混合专家(MoE)
混合专家(Mixture of Experts, MoE) 是一种机器学习模型架构,其核心思想是通过组合多个“专家”子模型(通常为小型神经网络)来处理不同输入,从而提高模型的容量和效率。MoE的关键特点是动态激活:对于每个输入,仅调用部分相关的专家进行计算,而非全部,从而在保持模型规模的同时降低计算成本。
MoE架构是一种创新的模型架构,通过引入多个“专家网络”来提升模型的表达能力和计算效率。在MoE架构中,多个专家网络被独立设计为处理不同的特定任务或特定特征,模型根据输入数据的特点动态选择部分专家{L-End}参与计算,而不是同时激活所有专家网络。这种“按需计算”的方式显著减少了资源消耗,同时提升了模型的灵活性和任务适配能力。MoE的核心思想是通过动态路由机制,在每次推理或训练中只激活一部分专家,从而在大规模模型中实现参数规模的扩展,而不会显著增加计算开销。
MoE的优势与意义
MoE架构的引入为大规模模型解决了参数扩展与计算效率之间的矛盾,在以下几个方面形成了优势。
(1)参数规模的扩展:MoE架构允许模型拥有超大规模的参数量,但每次计算中只需要激活一小部分参数,从而大幅提升模型的表达能力。
(2)高效资源利用:通过动态选择专家,MoE架构避免了计算资源的浪费,同时节省了显存和计算成本。
(3)任务适配能力增强:不同的专家网络可以针对不同任务进行优化,使模型在多任务环境中具备更强的适应性。
(4)分布式训练的友好性:MoE架构天然适配分布式计算环境,通过将不同的专家网络分布到多个计算节点,显著提升了并行计算效率。