【C++】23. unordered_map和unordered_set的使用
1. unordered_set系列的使用
1.1 unordered_set和unordered_multiset参考文档
https://legacy.cplusplus.com/reference/unordered_set/
1.2 unordered_set类的详细介绍
• unordered_set的声明模板如下:
template<class Key,class Hash = std::hash<Key>,class KeyEqual = std::equal_to<Key>,class Allocator = std::allocator<Key>>
class unordered_set;
其中Key就是unordered_set底层存储的关键字类型,其他三个模板参数都有默认值。
• 哈希函数要求:
- 默认情况下要求Key类型能够转换为整型(std::hash支持基本类型和字符串)
- 如果Key是自定义类型,可以通过两种方式处理:
- 特化std::hash模板
- 自定义哈希函数对象传入第二个参数
- 示例:对于自定义结构体Point的哈希函数
struct PointHash {size_t operator()(const Point& p) const {return std::hash<int>()(p.x) ^ std::hash<int>()(p.y);} };
• 键值相等比较:
- 默认使用std::equal_to进行相等比较
- 对于自定义类型,可以:
- 重载==运算符
- 自定义比较函数传入第三个参数
- 示例:自定义比较函数
struct PointEqual {bool operator()(const Point& p1, const Point& p2) const {return p1.x == p2.x && p1.y == p2.y;} };
• 内存分配器:
- 默认使用std::allocator
- 可以传入自定义内存池实现(如boost::pool_allocator)
- 主要用于性能优化和特殊内存管理需求
• 实际使用建议:
- 90%的使用场景只需要关注Key类型
- 复杂场景才需要自定义哈希/比较函数
- 更高级的内存管理需求才需要自定义分配器
• 底层实现特点:
- 使用哈希表(开链法解决冲突)
- 平均时间复杂度:
- 插入:O(1)
- 删除:O(1)
- 查找:O(1)
- 最坏情况下可能退化到O(n)
- 遍历顺序不确定(取决于哈希函数和插入顺序)
1.3 unordered_set与set的使用区别
• 查阅文档可以发现,unordered_set和set都支持增删查操作,且接口使用方式完全相同,这里不再赘述具体使用方法。
• 两者的首要区别在于对key的要求不同:
-
std::set: 元素类型Key必须支持严格的弱序比较。要么定义<运算符,要么在构造set时提供一个自定义的比较函数对象 (Compare)。 -
std::unordered_set: 元素类型Key必须满足两个要求:-
支持计算哈希值:要么有
std::hash的特化(标准类型如int,std::string通常已有),要么在构造unordered_set时提供一个自定义的哈希函数对象 (Hash)。 -
支持相等比较:要么定义
==运算符,要么在构造unordered_set时提供一个自定义的相等比较函数对象 (Pred)。
-
• 第二个区别体现在迭代器特性上:
-
元素顺序:
-
std::set: 元素是有序的。元素总是按照其内部的严格弱序(默认是<运算符,或用户提供的比较函数Compare)进行升序排序。当你遍历一个set(例如使用迭代器)时,元素会按照这个排序顺序依次出现。 -
std::unordered_set: 元素是无序的。元素的存储顺序取决于它们的哈希值和哈希表的内部状态(桶)。遍历unordered_set得到的元素顺序是不确定的(通常看起来是随机的),并且可能随着插入和删除操作而改变。它不保证任何特定的顺序。
-
-
内存开销:
-
std::set: 通常每个元素需要额外的指针(用于树结构中的左右子节点和父节点,以及可能的颜色信息),所以内存开销相对较高(每个元素大约需要额外 2-3 个指针的开销)。 -
std::unordered_set: 需要维护哈希表本身(桶数组)以及可能的链表(或其他解决冲突的结构)。为了保持低冲突率和 O(1) 的平均性能,哈希表通常需要比实际元素数量更多的桶(负载因子 < 1),因此也可能有较高的内存开销。具体开销取决于实现和负载因子。
-
-
迭代器稳定性:
-
std::set: 迭代器在元素被删除时(除了被删除元素本身的迭代器失效),通常保持稳定。插入操作通常不会使现有迭代器失效(除非容器重组,这在平衡树中不是每次插入都发生)。 -
std::unordered_set: 插入操作可能导致重哈希(当元素数量增加导致负载因子超过阈值时,哈希表会重建一个更大的桶数组并重新映射所有元素)。重哈希会使所有迭代器失效。删除操作只使指向被删除元素的迭代器失效。
-
• 性能差异是第三个重要区别: 多数情况下,unordered_set的增删查改操作效率更高。这是因为:
-
查找、插入和删除的平均时间复杂度:
-
std::set: 查找(find)、插入(insert)和删除(erase)操作的平均和最坏时间复杂度都是 O(log n),其中n是容器中元素的数量。这是因为平衡树的高度大约是 log n。 -
std::unordered_set: 在理想情况下(好的哈希函数、低冲突):-
查找、插入和删除的平均时间复杂度是 O(1)(常数时间)。这是哈希表的主要优势。
-
然而,最坏情况下的时间复杂度是 O(n)。这发生在哈希函数产生大量冲突(很多元素被映射到同一个哈希桶)时,导致查找退化成在链表(或类似结构)中线性搜索。选择一个好的哈希函数和适当的桶数量可以降低这种风险。
-
-
总结对比表:
| 特性 | std::set | std::unordered_set |
|---|---|---|
| 底层结构 | 平衡二叉搜索树 (红黑树) | 哈希表 |
| 元素顺序 | 有序 (按比较函数排序) | 无序 |
| 查找/插入/删除 | O(log n) (平均和最坏) | O(1) (平均), O(n) (最坏) |
| 内存开销 | 较高 (每个元素多个指针) | 较高 (桶数组 + 冲突解决结构) |
| 迭代器失效 | 插入通常不失效 (除重组), 删除只失效被删元素 | 插入可能因重哈希导致全部失效, 删除只失效被删元素 |
| 元素要求 | 需要 Compare (严格弱序) | 需要 Hash (计算哈希) 和 Pred (相等比较) |
| 典型用例 | 需要元素有序遍历, 需要稳定迭代器, 元素不易哈希或需范围查询 | 需要极快查找/插入/删除 (平均O(1)), 不关心顺序 |
如何选择?
-
如果你需要元素按顺序存储和遍历,或者需要进行范围查询(如
lower_bound,upper_bound),或者元素的类型不易定义良好的哈希函数,或者需要迭代器稳定性,那么选择std::set。 -
如果你只关心元素是否存在(成员资格测试),对顺序没有要求,并且元素类型有良好、高效的哈希函数,追求平均情况下的常数时间查找、插入和删除性能,那么选择
std::unordered_set。这是更常用的集合类型,除非有明确的排序或范围查询需求。
简单来说:要顺序用 set,要速度(平均)用 unordered_set。 选择时务必考虑你的具体需求(顺序、性能要求、元素类型特性、迭代器稳定性)。
请参考以下代码演示的对比差异:
#include<unordered_set>
#include<unordered_map>
#include<set>
#include<iostream>
using namespace std;
int test_set2()
{const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){v.push_back(rand()); // N比较大时,重复值比较多//v.push_back(rand() + i); // 重复值相对少//v.push_back(i); // 没有重复,有序}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();us.reserve(N);for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;int m1 = 0;size_t begin3 = clock();for (auto e : v){auto ret = s.find(e);if (ret != s.end()){++m1;}}size_t end3 = clock();cout << "set find:" << end3 - begin3 << "->" << m1 << endl;int m2 = 0;size_t begin4 = clock();for (auto e : v){auto ret = us.find(e);if (ret != us.end()){++m2;}}size_t end4 = clock();cout << "unorered_set find:" << end4 - begin4 << "->" << m2 << endl;cout << "插入数据个数:" << s.size() << endl;cout << "插入数据个数:" << us.size() << endl << endl;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;
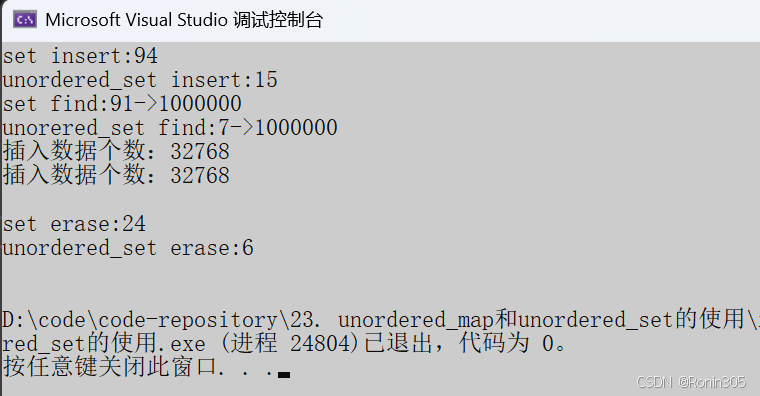
}1. 插入数据N比较大时,重复值比较多
运行结果:
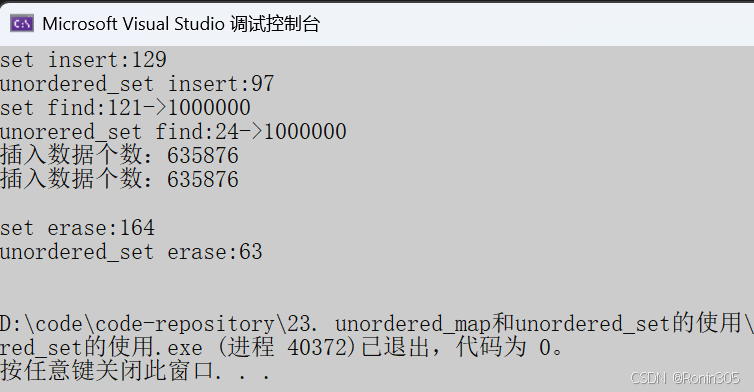
2. 插入数据重复值相对少
运行结果:
3. 没有重复,有序
运行结果:
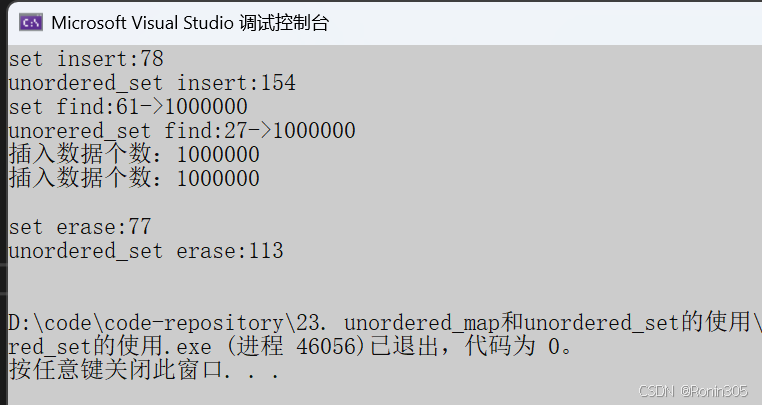
运行结果对比可以看出,只有在完全有序时,set性能才占优,其余情况都是unordered_set更具优势,另外以上代码均在release版本下运行
2. unordered_map系列的使用
2.1 unordered_set和unordered_multiset参考文档
https://legacy.cplusplus.com/reference/unordered_map/
2.2 unordered_set与set的使用区别
• 查看STL文档我们会发现unordered_map和map都支持增删查改等基本操作,它们的接口设计几乎相同,包括insert()、erase()、find()、operator[]等常用方法。例如:
std::map<int, string> m;
m.insert({1, "one"});
std::unordered_map<int, string> um;
um.insert({1, "one"});
由于两者的接口高度一致,本节将不再重复演示基本使用方法,而着重讨论它们的关键差异。
• unordered_map和map的第一个主要差异是对key类型的要求不同:
-
std::map: 键类型Key必须支持严格的弱序比较。要么定义<运算符,要么在构造map时提供自定义的比较函数对象 (Compare)。 -
std::unordered_map: 键类型Key必须满足两个要求:-
可哈希: 要么有
std::hash的特化(标准类型如int,std::string通常已有),要么在构造unordered_map时提供自定义的哈希函数对象 (Hash)。 -
可相等比较: 要么定义
==运算符,要么在构造unordered_map时提供自定义的相等比较函数对象 (Pred)。 例如:
struct MyKey {int id;bool operator==(const MyKey& other) const { return id == other.id; } }; namespace std {template<> struct hash<MyKey> {size_t operator()(const MyKey& k) const { return hash<int>()(k.id); }}; } -
这种差异源于它们的底层实现机制:map基于红黑树,而unordered_map基于哈希表。
• unordered_map和map的第二个重要差异是迭代器特性:
- map的迭代器是双向迭代器(bidirectional iterator),支持++和--操作,可以向前和向后遍历。由于底层是红黑树(一种二叉搜索树),采用中序遍历时元素是有序的,因此map迭代器遍历时会得到按键值升序排列的结果,并且自动去重。例如:
map<int, string> m{{2,"b"}, {1,"a"}, {3,"c"}}; for(auto it = m.begin(); it != m.end(); ++it) cout << it->first; // 输出顺序为1,2,3 - unordered_map的迭代器是单向迭代器(forward iterator),只支持++操作。由于底层是哈希表,元素存储位置由哈希函数决定,因此迭代器遍历时是无序的(但仍保证去重)。例如:
unordered_map<int, string> um{{2,"b"}, {1,"a"}, {3,"c"}}; for(auto it = um.begin(); it != um.end(); ++it)cout << it->first; // 输出顺序不确定
• unordered_map和map的第三个关键差异是性能特点:
-
查找、插入和删除的平均时间复杂度:
-
std::map: 查找 (find)、插入 (insert) 和删除 (erase) 操作的平均和最坏时间复杂度都是 O(log n)(n 是元素数量)。平衡树保证了稳定的对数时间复杂度。 -
std::unordered_map: 在理想情况下(好的哈希函数、低冲突):-
查找、插入和删除的平均时间复杂度是 O(1)(常数时间)。这是哈希表的核心优势。
-
然而,最坏情况下的时间复杂度是 O(n)。当哈希函数产生大量冲突(许多键映射到同一个桶)时,性能会线性下降。良好的哈希函数和适当的桶大小管理至关重要。
-
-
总结对比表:
| 特性 | std::map | std::unordered_map |
|---|---|---|
| 底层结构 | 平衡二叉搜索树 (红黑树) | 哈希表 |
| 键/元素顺序 | 按键有序 (按比较函数排序) | 键无序 |
| 查找/插入/删除 | O(log n) (平均和最坏) | O(1) (平均), O(n) (最坏) |
| 内存开销 | 较高 (每个元素多个指针) | 较高 (桶数组 + 冲突解决结构) |
| 迭代器失效 | 插入通常不失效 (除重组), 删除只失效被删元素 | 插入可能因重哈希导致全部失效, 删除只失效被删元素 |
| 键要求 | 需要 Compare (严格弱序) | 需要 Hash (计算哈希) 和 Pred (相等比较) |
| 范围查询 | 支持 (lower_bound, upper_bound等) | 不支持 (只能精确查找或遍历) |
| 典型用例 | 需要按键有序遍历/范围查询, 需要稳定迭代器, 键不易哈希 | 需要极快查找/插入/删除 (平均O(1)), 不关心键顺序, 键有良好哈希 |
如何选择?
-
选择
std::map当:-
你需要按键排序遍历元素。
-
你需要进行范围查询(例如,“找出所有键在 A 和 B 之间的元素”)。
-
键的类型不易或无法定义良好的哈希函数。
-
你需要迭代器在插入操作后保持相对稳定。
-
你能接受 O(log n) 的查找/插入/删除时间。
-
-
选择
std::unordered_map当:-
你只关心通过键快速查找、插入和删除值,对键的顺序完全不在意。
-
键的类型有高效、低冲突的哈希函数可用。
-
平均情况下的常数时间 (O(1)) 性能是你的首要目标。
-
你不需要范围查询。
-
迭代器失效(尤其是插入可能导致的重哈希)在你的使用场景中可以接受或容易管理。
-
简单来说:需要键有序遍历或范围查询用 map;需要最快的平均查找速度且不关心顺序用 unordered_map。 根据你的具体应用场景(对顺序、性能、键类型、迭代器稳定性的要求)做出选择。unordered_map 因其平均 O(1) 的访问速度,在不需要顺序的场景下通常是首选。
请参考以下代码演示的对比差异:
int test_set1()
{const size_t N = 1000000;unordered_map<int, int> um;map<int, int> m;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){v.push_back(rand()); // N比较大时,重复值比较多//v.push_back(rand() + i); // 重复值相对少//v.push_back(i); // 没有重复,有序}size_t begin1 = clock();for (auto e : v){m.insert({e, e});}size_t end1 = clock();cout << "map insert:" << end1 - begin1 << endl;size_t begin2 = clock();um.reserve(N);for (auto e : v){um.insert({e, e});}size_t end2 = clock();cout << "unordered_map insert:" << end2 - begin2 << endl;int m1 = 0;size_t begin3 = clock();for (auto e : v){auto ret = m.find(e);if (ret != m.end()){++m1;}}size_t end3 = clock();cout << "map find:" << end3 - begin3 << "->" << m1 << endl;int m2 = 0;size_t begin4 = clock();for (auto e : v){auto ret = um.find(e);if (ret != um.end()){++m2;}}size_t end4 = clock();cout << "unorered_map find:" << end4 - begin4 << "->" << m2 << endl;cout << "插入数据个数:" << m.size() << endl;cout << "插入数据个数:" << um.size() << endl << endl;size_t begin5 = clock();for (auto e : v){m.erase(e);}size_t end5 = clock();cout << "map erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){um.erase(e);}size_t end6 = clock();cout << "unordered_map erase:" << end6 - begin6 << endl << endl;return 0;
}1. 插入数据N比较大时,重复值比较多
运行结果:
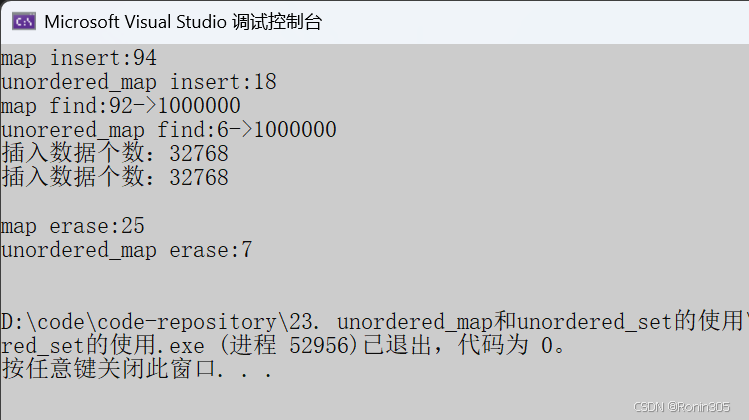
2. 插入数据重复值相对少
运行结果:
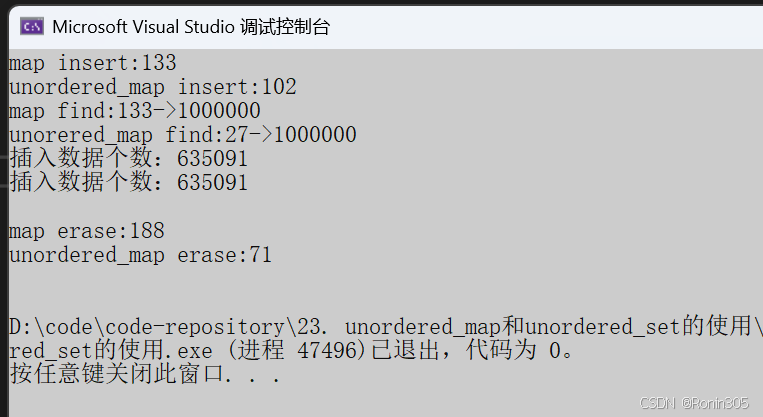
3. 没有重复,有序
运行结果:
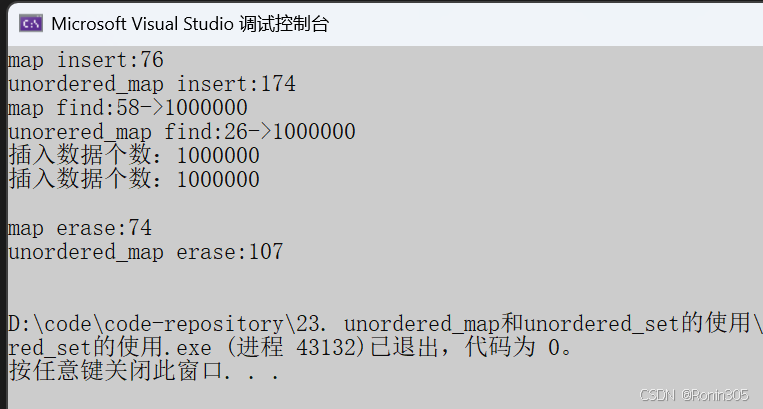
测试结果显示,在大多数场景下unordered_map的操作速度更快。但需要注意:
- 哈希表性能受负载因子影响,可能需要rehash
- 在最坏情况下(大量哈希冲突),unordered_map性能会退化到O(N)
- map的优势在于能保持元素有序,且性能稳定
3. unordered_multimap/unordered_multiset
• 功能特性:与multimap/multiset类似,支持键值冗余存储
• 主要差异体现在以下三个方面:
- 对键值(Key)的要求不同
- 迭代器及遍历顺序的差异
- 性能表现的区别
这里就不过多阐述
4. unordered_xxx的哈希相关接口
unordered_xxx容器提供了两类重要的哈希相关接口:
4.1 Buckets系列接口
这些接口主要用于操作和管理哈希桶(bucket),包括:
bucket_count(): 返回当前哈希表中桶的数量bucket_size(n):返回第n个桶中的元素数量bucket(key):返回给定键所在的桶编号begin(n)/end(n):返回指向第n个桶首尾的迭代器
例如:
std::unordered_map<std::string, int> umap;
// 获取哈希表当前使用的桶数量
size_t bucket_num = umap.bucket_count();
// 获取键为"apple"的元素所在的桶编号
size_t bucket_idx = umap.bucket("apple");
4.2 Hash policy系列接口
这些接口用于管理哈希策略,特别是负载因子(load factor)相关设置:
load_factor(): 返回当前负载因子(元素数量/桶数量)max_load_factor(): 获取或设置最大允许负载因子rehash(n):将容器桶数量设置为至少nreserve(n):预留至少n个元素的存储空间
例如可以通过以下方式调整哈希表性能:
// 设置最大负载因子为0.5
umap.max_load_factor(0.5f);
// 预留100个元素的存储空间
umap.reserve(100);
从日常使用角度来说,我们不需要过多关注这些底层接口。当后续学习了哈希表底层实现原理后,这些接口的作用将会一目了然。哈希表的高效性很大程度上依赖于合理的桶数量和负载因子设置,但在大多数应用场景中,STL提供的默认值已经足够优化。