Parametric Retrieval Augmented Generation
Parametric Retrieval Augmented Generation
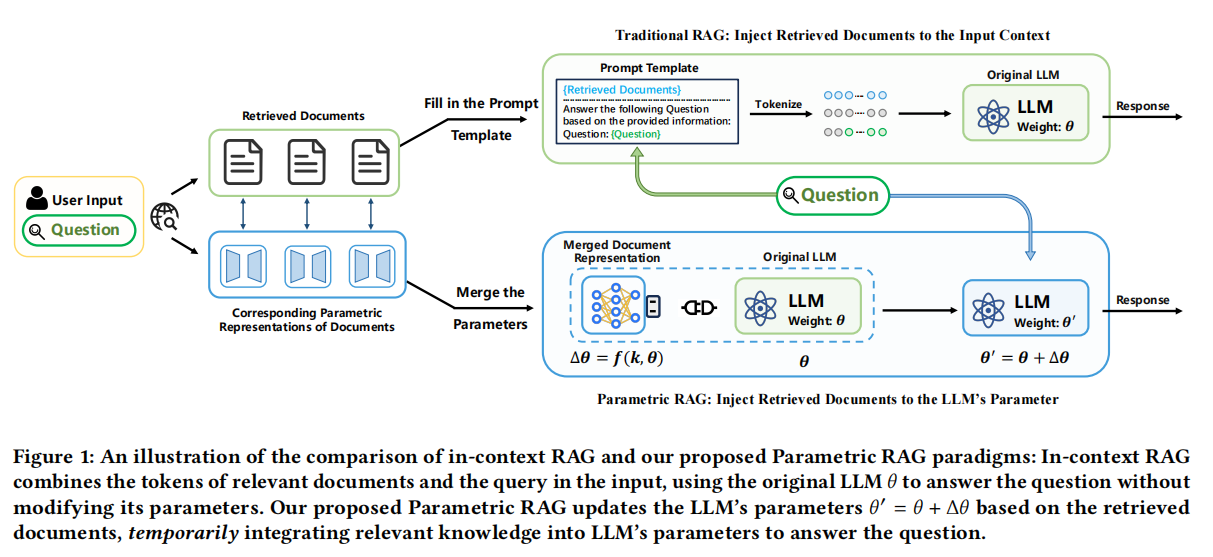
3. Methodology
3.1 Problem Formulation and Overview
| 文中原始符号 | 数学表示 | 额外解释 |
|---|---|---|
| LLM | L L L | 大模型的简化表示 |
| LLM parameters | θ \theta θ | 大模型的参数表示 |
| user query | q q q | 用户的输入 |
| external corpus | K K K | K = { d 1 , d 2 , … , d N } K = \{ d_1, d_2, \ldots, d_N \} K={d1,d2,…,dN} |
| text chunk or passages | d i d_i di | 检索的对象 |
| retrieval module | R R R | 检索的模型 |
| relevance score of each d i d_i di | { S d 1 , S d 2 , … , S d N } \{ S_{d_1}, S_{d_2}, \ldots, S_{d_N} \} {Sd1,Sd2,…,SdN} | corresponding to the q q q |
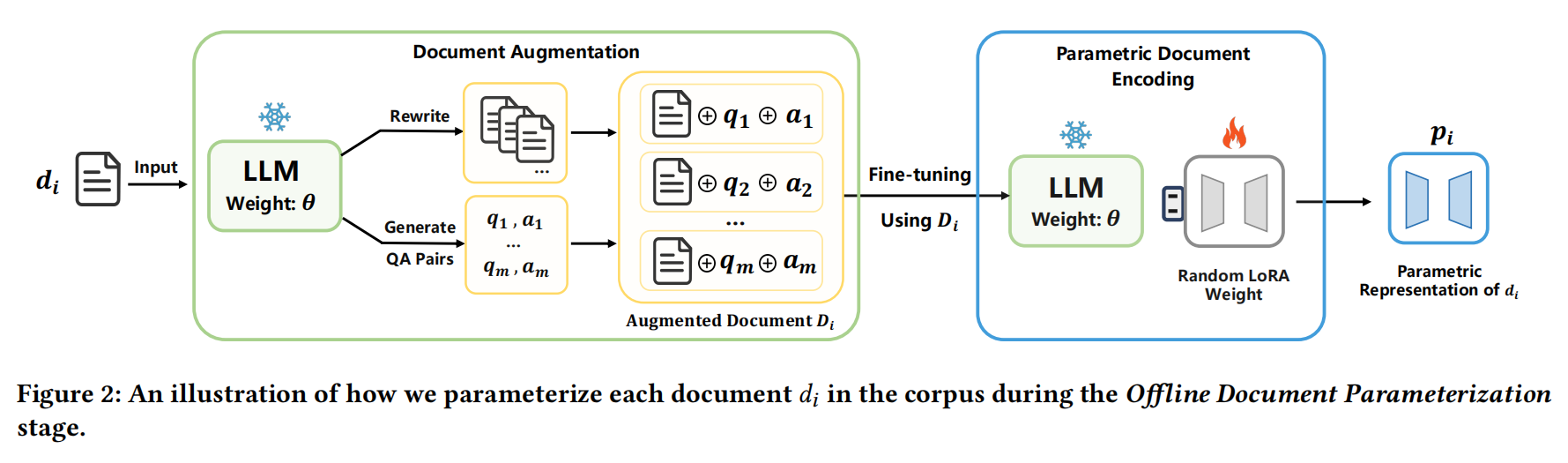
Offline document Parameterization.
illustrated picture:
分为了三个模块:
- Document Augmentation.
- Parametric Document Encoding.
- Discussion on LoRA Initialization.
we defind:
K P = { p i ∣ p i = f ϕ ( d i ) , i = 1 , 2 , … , N } , K_P = \{ p_i \mid p_i = f_\phi(d_i), \quad i=1,2,\ldots,N \}, KP={pi∣pi=fϕ(di),i=1,2,…,N},
where f ϕ ( d i ) f_\phi(d_i) fϕ(di) is a mapping function that converts each document d i d_i di into its corresponding parametric representation p i p_i pi
Online Inference.
- first merges the parametric representations corresponding to the retrieved top-k documents and then plugs the merged parameters into the LLM.
- Subsequently, the updated LLM is used to answer the user’s question. This overall framework allows for more efficient and effective knowledge injection, overcoming the limitations of traditional RAG by leveraging parameterized representations of external knowledge.
3.2 Offline Document Parameterization
- Document Augmentation.
这一步的目的是为了有效的incorporating factual knowledge,为了达到这个目的,一篇文献提出了一个解决方案:
@article{allen2023physics,title={Physics of language models: Part 3.1, knowledge storage and extraction},author={Allen-Zhu, Zeyuan and Li, Yuanzhi},journal={arXiv preprint arXiv:2309.14316},year={2023}
}
(1) incorporatiing questio-answer (QA) paris derived from the document during training
(2) augmenting the document throuh multiple rewrites the express the same factual content in different forms.
随后,作者根据这两个观点进行文章的增强(document augmentation),作者将他的步骤分为两步:document rewriting and QA Pair Generation
目的是to construct robust and infomative parametric representations for documents.
-
那么对于document rewiring来说:作者使用了prompt将文档进行多次充血,使用different wording, styles, or o organizational structures. 那么对于每个文档 d i d_i di都会被重写为 n n n个不同的文档 { d i 1 , d i 2 , … , d i n } \{ d_{i}^1, d_{i}^2, \ldots, d_{i}^n \} {di1,di2,…,din},他们preserve the original facts but vary in language expression
-
那么对于QA pair Generation来说:基于original document d i d_i di, 大模型会生成一些系列的问答对 { ( q l 1 , a l 1 ) , ( q l 2 , a l 2 ) , … , ( q l m , a l m ) } \{ ( q _ { l } ^ { \ 1 } , a _ { l } ^ { \ 1 } ) , ( q _ { l } ^ { \ 2 } , a _ { l } ^ { \ 2 } ) , \ldots , ( q _ { l } ^ { \ m } , a _ { l } ^ { \ m } ) \} {(ql 1,al 1),(ql 2,al 2),…,(ql m,al m)}. 其中 m m m为tunable hyperparameter.
最后,对根据重写的文档还有生成的问答对,合并成一个more comprehensive resource D i D_i Di, 他可以表示为:
D i = { ( d i k , q i j , a i j ) ∣ 1 ≤ k ≤ n , 1 ≤ j ≤ m } , D_i = \{ (d_i^k, q_i^j, a_i^j) \mid 1 \leq k \leq n,\, 1 \leq j \leq m \}, Di={(dik,qij,aij)∣1≤k≤n,1≤j≤m},
文章中生成QA对的提示词
I will provide a passage of text, and you need to generate three different questions based on the content of this passage. Each question should be answerable using the information provided in the passage. Additionally, please provide an appropriate answer for each question derived from the passage.
You need to generate the question and answer in the following format:
[{"question": "What is the capital of France?","answer": "Paris""full_answer": "The capital of France is Paris."},
]
This list should have at least three elements. You only need to output this list in the above format.
Passage:
Were Scott Derrickson and Ed Wood of the same nationality?
这一步的某一个数据的结果
{"passage": "Were Scott Derrickson and Ed Wood of the same nationality?","pid": 1,"qwen2.5-1.5b-instruct_qa": [{"answer": "Frank Capra","full_answer": "Its a Wonderful Life was written by Frank Capra.","question": "Who wrote Its a Wonderful Life?"},{"answer": "United States","full_answer": "Scott Derrickson lives in the United States.","question": "In which country does Scott Derrickson live?"},{"answer": "No","full_answer": "Ed Wood died in 2007.","question": "Is Ed Wood still alive?"}],"qwen2.5-1.5b-instruct_rewrite": "Are Scott Derrickson and Ed Wood from the same country?"
}
- Parametric Document Encoding.
作者 leverage the augmented dataset D i D_i Di to train the parametric representation p i p_i pi for each document d i d_i di.
以下为阅读代码的详细步骤:
首先先定义LoRA的结构:
peft_config = LoraConfig( # 定义Lora结构task_type=TaskType.CAUSAL_LM, target_modules=['down_proj', 'gate_proj', 'up_proj'],inference_mode=False, # 启用训练逻辑r=args.lora_rank, # LoRA的秩lora_alpha=args.lora_alpha, # 缩放系数lora_dropout=0, # !!!)
其中:
TaskType.CAUSAL_LM # 为用于因果语言模型,其余的选项还有:class TaskType(str, enum.Enum):"""Enum class for the different types of tasks supported by PEFT.Overview of the supported task types:- SEQ_CLS: Text classification.- SEQ_2_SEQ_LM: Sequence-to-sequence language modeling.- CAUSAL_LM: Causal language modeling.- TOKEN_CLS: Token classification.- QUESTION_ANS: Question answering.- FEATURE_EXTRACTION: Feature extraction. Provides the hidden states which can be used as embeddings or featuresfor downstream tasks."""SEQ_CLS = "SEQ_CLS"SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM"CAUSAL_LM = "CAUSAL_LM"TOKEN_CLS = "TOKEN_CLS"QUESTION_ANS = "QUESTION_ANS"FEATURE_EXTRACTION = "FEATURE_EXTRACTION"其中:
peft = Parameter-Efficient Fine-Tuning
其中:
target_modules=['down_proj', 'gate_proj', 'up_proj'] # 应用于FFN
Transformer Layer:├─ Self-Attention (q_proj, k_proj, v_proj, o_proj)└─ Feed-Forward Network (FFN):├─ gate_proj├─ up_proj└─ down_proj
随后进行微调:
model = train(data["question"], [augment[pid]], args, model, tokenizer, init_adapter_path, save_path)
# data["question"] 为原始问题
# augment[pid] 为关于这个问题增强后的结果
# model为经过LoRA微调冻结参数后的model
进行微调时,首先进行数据集的构建:
USER_PROMPT = "You should answer the question by referring to the knowledge provided below and integrating your own knowledge.\n\
{passages}\n\n\
Question: {question}"
ASSISTANT_PROMPT = "The answer is {answer}"def _get_prompt(question, passages=None, answer=None):question = question.strip()if not question.endswith('?'):question = question.strip() + '?'elif question.endswith(' ?'):question = (question[:-1]).strip() + '?'if passages and not isinstance(passages, list):passages = [passages]if answer is None:answer = ""else:answer = answer.strip()if not answer.endswith('.'):answer += "."return question, passages, answerdef get_prompt(tokenizer, question, passages=None, answer=None, with_cot=False):question, passages, answer = _get_prompt(question, passages, answer)contexts = ""if passages:for pid, psg in enumerate(passages):contexts += f"Passage {pid+1}: {psg}\n"if not with_cot:user_content = USER_PROMPT.format(question=question, passages=contexts)assistant_content = ASSISTANT_PROMPT.format(answer=answer)else:assert fewshot is not Noneuser_content = USER_PROMPT_WITH_COT.format(question=question, passages=contexts, fewshot=fewshot)assistant_content = ASSISTANT_PROMPT_WITH_COT.format(answer=answer)messages = [{"role": "user","content": user_content,}]inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True)inputs += tokenizer.encode(assistant_content, add_special_tokens=False)return inputs
随后,messages的样例如下:
[{'content': 'You should answer the question by referring to the knowledge provided below and integrating your own knowledge.
Passage 1: In what city did the "Prince of tenors" star in a film based on an opera by Giacomo Puccini?
Question: Which city was the 'Prince of Tenors' featured in a film adaptation of an opera written by Giacomo Puccini?', 'role': 'user'}]
assistant_content的样例如下:
'The answer is Milan.'
具体的train函数为:
def train(question, augments, args, model, tokenizer, init_adapter_path, save_path):prompt_ids = get_train_data(args.augment_model, augments, tokenizer, args)train_data = TrainingData(prompt_ids, tokenizer)train_dataloader = torch.utils.data.DataLoader(train_data,batch_size=args.per_device_train_batch_size,collate_fn=TrainingDataCollator(tokenizer, model.device),shuffle=False,)model = PeftModel.from_pretrained(model, init_adapter_path, is_trainable=True)model.is_parallelizable = Truemodel.model_parallel = Truemodel_parameters = filter(lambda p: p.requires_grad, model.parameters())optimizer = torch.optim.AdamW(model_parameters, lr=args.learning_rate)for epoch in range(args.num_train_epochs):for step, batch in enumerate(train_dataloader):optimizer.zero_grad()outputs = model(**batch)loss = outputs.lossloss.backward()optimizer.step()os.makedirs(save_path, exist_ok=True)model.save_pretrained(save_path)model = model.unload()torch.cuda.empty_cache()gc.collect()return model
4. 具体的执行例子为如下所示:
输入的一个数据:
{"qid": "5a8b57f25542995d1e6f1371","question": "Were Scott Derrickson and Ed Wood of the same nationality?",
}
经过增高后,输出两个东西,一个是修改后的问题,还有一个对应的qa问答对:
{"augment": [{"passage": "Were Scott Derrickson and Ed Wood of the same nationality? (斯科特-德里克森和艾德-伍德是同一国籍吗?)","pid": 0,"qwen2.5-1.5b-instruct_qa": [{"answer": "No","full_answer": "Scott Derrickson was American, while Ed Wood was Canadian. Therefore, they did not share the same nationality.","question": "Did Scott Derrickson and Ed Wood share the same nationality? (斯科特-德里克森和艾德-伍德的国籍相同吗?)"},{"answer": "Yes","full_answer": "Scott Derrickson was born in the United States.","question": "Was Scott Derrickson born in America? (斯科特-德里克森出生在美国吗?)"},{"answer": "Canada","full_answer": "Ed Wood was born in Canada.","question": "Where was Ed Wood originally from? (艾德-伍德最初来自哪里?)"}],"qwen2.5-1.5b-instruct_rewrite": "Are both Scott Derrickson and Ed Wood considered to be American filmmakers?"}]
}
其中,rewrite的实现方式如下:
def get_rewrite(passage, model_name, model=None, tokenizer=None, generation_config=None):""":param passage: 输入的原问题:param model_name: :param model: :param tokenizer: :param generation_config: :return: prompt 翻译:重写以下段落。在保持实体、专有名词和关键细节(如名称、位置和术语)完整的同时,创建一个新版本的文本,以不同的方式表达相同的想法。确保修订后的文章与原文不同,但保留了核心含义和相关信息。\n{段落}"""rewrite_prompt = "Rewrite the following passage. While keeping the entities, proper nouns, and key details such as names, locations, and terminology intact, create a new version of the text that expresses the same ideas in a different way. Make sure the revised passage is distinct from the original one, but preserves the core meaning and relevant information.\n{passage}"return model_generate(rewrite_prompt.format(passage=passage), model, tokenizer, generation_config)
其中,实现QA问答对的提示词如下:
qa_prompt_template = "I will provide a passage of text, and you need to generate three different questions based on the content of this passage. Each question should be answerable using the information provided in the passage. Additionally, please provide an appropriate answer for each question derived from the passage.\n\
You need to generate the question and answer in the following format:\n\
[\n\{{\n\\"question\": \"What is the capital of France?\",\n\\"answer\": \"Paris\"\n\\"full_answer\": \"The capital of France is Paris.\"\n\}}, \n\
]\n\n\
This list should have at least three elements. You only need to output this list in the above format.\n\
Passage:\n\
{passage}""""
提示词翻译为中文为:
qa_prompt_template = "我将提供一段文字,您需要根据这段文字的内容生成三个不同的问题。每个问题都应能用这段文字中提供的信息来回答。此外,请为从这段文字中得出的每个问题提供一个合适的答案。
您需要按照以下格式生成问题和答案:\n\
[\n\{{\n\\question\": \What is the capital of France?\answer: \Paris (巴黎)\full_answer: \The capital of France is Paris.}}, \n\
]/n\n
这个列表应该至少有三个元素。您只需要以上述格式输出这个列表即可。
Passage:\n\
{passage}”"""
随后要把文档变成参数:
具体函数为:
def get_train_data(aug_model, augments, tokenizer, args):from prompt_template import get_promptprompt_ids = []for aug in augments:psg = aug["passage"] # 原始问题rew = aug[f"{aug_model}_rewrite"] # 重写后的问题qas = aug[f"{aug_model}_qa"] # 构建的QA问答对qpa_cnt = (len(qas) + 1) // 2 # 划分前一半数据集和后一半数据集for qid, qa in enumerate(qas):if qid < qpa_cnt:for ppp in [psg, rew]: # 同时使用原始段落(psg)和重写段落(rew) 分别构造 prompt,即一个问答对会生成 两个 prompt(一个基于 psg,一个基于 rew)prompt_ids.append(get_prompt(tokenizer, qa["question"], [ppp], qa["answer"] if not args.with_cot else qa["full_answer"], with_cot=args.with_cot))else:prompt_ids.append(get_prompt(tokenizer, qa["question"], None, qa["answer"] if not args.with_cot else qa["full_answer"], with_cot=args.with_cot))return prompt_ids
get_prompt函数为:
def get_prompt(tokenizer, question, passages=None, answer=None, with_cot=False):""":param tokenizer::param question: qa对里面的问题:param passages: 这是原始的问题:param answer: 这个是qa对里面的答案:param with_cot: 是否需要采用cot:return:"""question, passages, answer = _get_prompt(question, passages, answer)contexts = ""if passages:for pid, psg in enumerate(passages):contexts += f"Passage {pid+1}: {psg}\n"if not with_cot:user_content = USER_PROMPT.format(question=question, passages=contexts) # question是qa问答对中的question,然而context是原始的问题assistant_content = ASSISTANT_PROMPT.format(answer=answer)else:assert fewshot is not Noneuser_content = USER_PROMPT_WITH_COT.format(question=question, passages=contexts, fewshot=fewshot)assistant_content = ASSISTANT_PROMPT_WITH_COT.format(answer=answer)messages = [{"role": "user","content": user_content,}]inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True)inputs += tokenizer.encode(assistant_content, add_special_tokens=False)return inputs
把每一个重写的问题和QA对都进行结合,以下为一个结合的例子,其中USER_PROMPT的passages为原始的问题,question为LLM重写的问题:
USER_PROMPT = "You should answer the question by referring to the knowledge provided below and integrating your own knowledge.\n\
{passages}\n\n\
Question: {question}"
// 前一半Example
[{"role": "user","content": "You should answer the question by referring to the knowledge provided below and integrating your own knowledge.\nPassage 1: Which American film director hosted the 18th Independent Spirit Awards in 2002?\n\n\nQuestion: Who hosted the 18th Independent Spirit Awards in 2002?"}
]
// 后一半Example
[{"role": "user","content": "You should answer the question by referring to the knowledge provided below and integrating your own knowledge.\\n\\n\\nQuestion: Did any other films win awards at the 18th Independent Spirit Awards in 2002?"}
]
这里,对于前一半的QA对,会包含passages和question,对于后一半的qa对,就不包含passages,也就是不包含原始问题。
随后,再生成对应的assistant_content,这里包含的是qa对对应的答案,
assistant_content的样例如下:
# 前一半Example
'The answer is Robert Redford.'
# 后一半Example
'The answer is Yes.'
最终结果Example
[151644, 8948, 198, 2610, 525, 1207, 16948, 11, 3465, 553, 54364, 14817, 13, 1446, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 2610, 1265, 4226, 279, 3405, 553, 22023, 311, 279, 6540, 3897, 3685, 323, 53852, 697, 1828, 6540, 4192, 14582, 25, 14568, 894, 1008, 12351, 3164, 22344, 518, 279, 220, 16, 23, 339, 21994, 16899, 22658, 304, 220, 17, 15, 15, 17, 30, 151645, 198, 151644, 77091, 198, 785, 4226, 374, 7414, 13]
随后,利用这个数据开始进行微调,每一个qa对和对应重写的文档都会生成一个参数
{"qid": "5a8c7595554299585d9e36b6","test_id": 1,"question": "What government position was held by the woman who portrayed Corliss Archer in the film Kiss and Tell?","answer": "Chief of Protocol","augment": [{"pid": 0,"passage": "What government position was held by the woman who portrayed Corliss Archer in the film Kiss and Tell?","qwen2.5-1.5b-instruct_rewrite": "Which official role did the actress portray when she played Corliss Archer in the movie Kiss and Tell?","qwen2.5-1.5b-instruct_qa": [{"question": "Who held the government position that the woman played Corliss Archer in the movie Kiss and Tell?","answer": "Actress","full_answer": "The woman who portrayed Corliss Archer in the movie Kiss and Tell held a government position."},{"question": "What type of government position did the actress play in the movie Kiss and Tell?","answer": "Actress","full_answer": "In the movie Kiss and Tell, the actress portrayed Corliss Archer as a government official or employee."},{"question": "Which specific role did the actress portray in the movie Kiss and Tell?","answer": "Corliss Archer","full_answer": "The actress portrayed Corliss Archer, which was likely a high-ranking government position such as Secretary of State or Assistant Secretary of State."}]}],"passages": ["What government position was held by the woman who portrayed Corliss Archer in the film Kiss and Tell?"]
}
验证过程:
每一个question, 他都会有对应的answer,每一个question,有对应的相似的句子,每个句子,都会让他进行重写,构建qa对,所以每一个question,会获取到他所有的相似的句子的重写和对应的qa对的参数。
首先,当融入了所有的相关参数之后,用原先的question作为模型的输入,得出对应的答案,以下是融入代码。
for pid in range(len(passages)):adapter_path = os.path.join(load_adapter_path, filename, f"data_{test_id}", f"passage_{pid}")if pid == 0:model = PeftModel.from_pretrained(model, # 基础模型adapter_path, # 适配器adapter_name = "0", # 适配器的名字is_trainable = False # 他非可训练)else:model.load_adapter(adapter_path, adapter_name = str(pid)) # 给后面的适配器进行命名
# merge
model.add_weighted_adapter( # 合并适配器的参数adapters = [str(i) for i in range(len(passages))], weights = [1] * len(passages),adapter_name = "merge", combination_type = "cat",
)
随后就是融入后的模型进行生成:
def evaluate(pred, ground_truth, with_cot=False):if not with_cot:pred = pred.strip()stop_list = [".", "\n", ","]for stop in stop_list:end_pos = pred.find(stop)if end_pos != -1:pred = pred[:end_pos].strip()else:if "the answer is" in pred:pred = pred[pred.find("the answer is") + len("the answer is"):]pred = pred.strip()stop_list = [".", "\n", ","]for stop in stop_list:end_pos = pred.find(stop)if end_pos != -1:pred = pred[:end_pos].strip() em = BaseDataset.exact_match_score(prediction=pred,ground_truth=ground_truth,)["correct"]f1_score = BaseDataset.f1_score(prediction=pred,ground_truth=ground_truth,)f1, prec, recall = f1_score["f1"], f1_score["precision"], f1_score["recall"]return {"eval_predict": pred,"em": str(em),"f1": str(f1),"prec": str(prec),"recall": str(recall),}
分词,取交际,看相同的词有几个