Python训练第四十一天
DAY 41 简单CNN
知识回顾
- 数据增强
- 卷积神经网络定义的写法
- batch归一化:调整一个批次的分布,常用与图像数据
- 特征图:只有卷积操作输出的才叫特征图
- 调度器:直接修改基础学习率
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
- Flatten -> Dense (with Dropout,可选) -> Dense (Output)
一、数据增强
在图像数据预处理环节,为提升数据多样性,可采用数据增强(数据增广)策略。该策略通常不改变单次训练的样本总数,而是通过对现有图像进行多样化变换,使每次训练输入的样本呈现更丰富的形态差异,从而有效扩展模型训练的样本空间多样性。
常见的修改策略包括以下几类
1. 几何变换:如旋转、缩放、平移、剪裁、裁剪、翻转
2. 像素变换:如修改颜色、亮度、对比度、饱和度、色相、高斯模糊(模拟对焦失败)、增加噪声、马赛克
3. 语义增强(暂时不用):mixup,对图像进行结构性改造、cutout随机遮挡等
此外,在数据极少的场景长,常常用生成模型来扩充数据集,如GAN、VAE等。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
#使用设备: cpu
#Files already downloaded and verified注意数据增强一般是不改变每个批次的数据量,是对原始数据修改后替换原始数据。其中该数据集事先知道其均值和标准差,如果不知道,需要提前计算下。
二、 CNN模型
卷积的本质:通过卷积核在输入通道上的滑动乘积,提取跨通道的空间特征。所以只需要定义几个参数即可
1. 卷积核大小:卷积核的大小,如3x3、5x5、7x7等。
2. 输入通道数:输入图片的通道数,如1(单通道图片)、3(RGB图片)、4(RGBA图片)等。
3. 输出通道数:卷积核的个数,即输出的通道数。如本模型中通过 32→64→128 逐步增加特征复杂度
4. 步长(stride):卷积核的滑动步长,默认为1。
# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)上述定义CNN模型中:
1. 使用三层卷积+池化结构提取图像特征
2. 每层卷积后添加BatchNorm加速训练并提高稳定性
3. 使用Dropout减少过拟合
可以把全连接层前面的不理解为神经网络的一部分,单纯理解为特征提取器,他们的存在就是帮助模型进行特征提取的。
2.1 batch归一化
Batch 归一化是深度学习中常用的一种归一化技术,加速模型收敛并提升泛化能力。通常位于卷积层后。
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
2. Flatten -> Dense (with Dropout,可选) -> Dense (Output)
其中,BatchNorm 应在池化前对空间维度的特征完成归一化,以确保归一化统计量基于足够多的样本(空间位置),避免池化导致的统计量偏差
旨在解决深度神经网络训练中的内部协变量偏移问题:深层网络中,随着前层参数更新,后层输入分布会发生变化,导致模型需要不断适应新分布,训练难度增加。就好比你在学新知识,知识体系的基础一直在变,你就得不断重新适应,模型训练也是如此,这就导致训练变得困难,这就是内部协变量偏移问题。
通过对每个批次的输入数据进行标准化(均值为 0、方差为 1),想象把一堆杂乱无章、分布不同的数据规整到一个标准的样子。
1. 使各层输入分布稳定,让数据处于激活函数比较合适的区域,缓解梯度消失 / 爆炸问题;
2. 因为数据分布稳定了,所以允许使用更大的学习率,提升训练效率。
深度学习的归一化有2类:
1. Batch Normalization:一般用于图像数据,因为图像数据通常是批量处理,有相对固定的 Batch Size ,能利用 Batch 内数据计算稳定的统计量(均值、方差 )来做归一化。
2. Layer Normalization:一般用于文本数据,本数据的序列长度往往不同,像不同句子长短不一,很难像图像那样固定 Batch Size 。如果用 Batch 归一化,不同批次的统计量波动大,效果不好。层归一化是对单个样本的所有隐藏单元进行归一化,不依赖批次。
ps:这个操作在结构化数据中其实是叫做标准化,但是在深度学习领域,习惯把这类对网络中间层数据进行调整分布的操作都叫做归一化 。
2.2 特征图
卷积层输出的叫做特征图,通过输入尺寸和卷积核的尺寸、步长可以计算出输出尺寸。可以通过可视化中间层的特征图,理解 CNN 如何从底层特征(如边缘)逐步提取高层语义特征(如物体部件、整体结构)。MLP是不输出特征图的,因为他输出的一维向量,无法保留空间维度
特征图就代表着在之前特征提取器上提取到的特征,可以通过 Grad-CAM方法来查看模型在识别图像时,特征图所对应的权重是多少。-----深度学习可解释性
我们在后续介绍。下面接着训练CNN模型
2.3 调度器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)ReduceLROnPlateau调度器适用于当监测的指标(如验证损失)停滞时降低学习率。是大多数任务的首选调度器,尤其适合验证集波动较大的情况
这种学习率调度器的方法相较于之前只有单纯的优化器,是一种超参数的优化方法,它通过调整学习率来优化模型。
常见的优化器有 adam、SGD、RMSprop 等,而除此之外学习率调度器有 lr_scheduler.StepLR、lr_scheduler.ExponentialLR、lr_scheduler.CosineAnnealingLR 等。
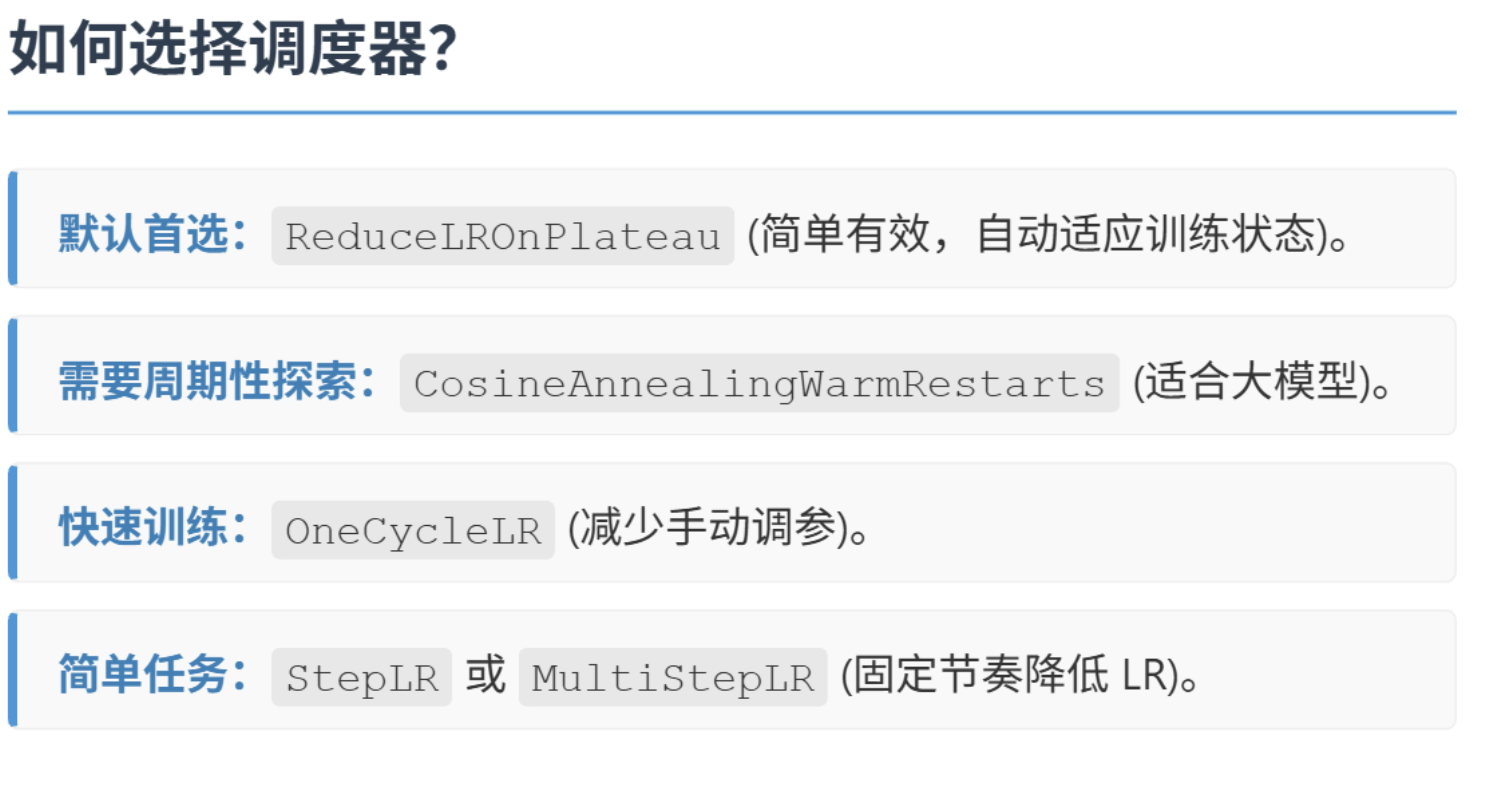
可以把优化器和调度器理解为调参手段,学习率是参数
注意,优化器如adam虽然也在调整学习率,但是他的调整是相对值,计算步长后根据基础学习率来调整。但是调度器是直接调整基础学习率。
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
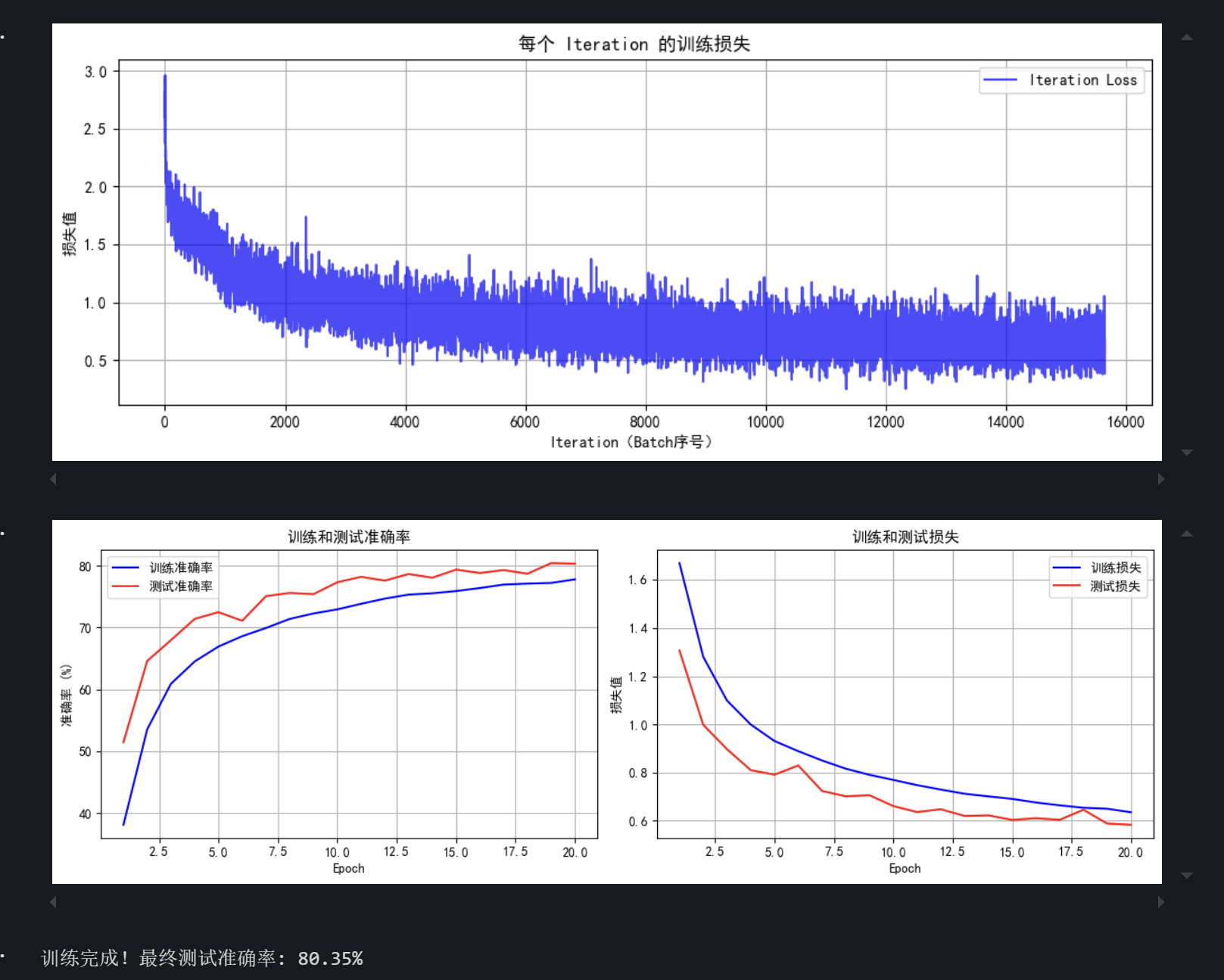
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
# print("模型已保存为: cifar10_cnn_model.pth")开始使用CNN训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.8596 | 累计平均损失: 2.0277
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.7966 | 累计平均损失: 1.9042
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.5689 | 累计平均损失: 1.8268
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.6140 | 累计平均损失: 1.7859
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.7751 | 累计平均损失: 1.7462
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.6153 | 累计平均损失: 1.7156
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.4643 | 累计平均损失: 1.6894
Epoch 1/20 完成 | 训练准确率: 38.07% | 测试准确率: 51.44%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.3450 | 累计平均损失: 1.4455
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.2012 | 累计平均损失: 1.4031
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 0.9481 | 累计平均损失: 1.3649
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.1936 | 累计平均损失: 1.3378
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.2699 | 累计平均损失: 1.3235
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.4104 | 累计平均损失: 1.3080
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.1461 | 累计平均损失: 1.2932
Epoch 2/20 完成 | 训练准确率: 53.53% | 测试准确率: 64.59%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.1695 | 累计平均损失: 1.1535
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 1.3243 | 累计平均损失: 1.1397
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.0818 | 累计平均损失: 1.1412
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 0.9975 | 累计平均损失: 1.1227
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 1.0649 | 累计平均损失: 1.1175
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.1256 | 累计平均损失: 1.1106
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.2217 | 累计平均损失: 1.1048
Epoch 3/20 完成 | 训练准确率: 60.91% | 测试准确率: 67.97%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 1.1777 | 累计平均损失: 1.0526
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 1.1869 | 累计平均损失: 1.0255
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 1.0152 | 累计平均损失: 1.0107
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.2433 | 累计平均损失: 1.0147
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.8466 | 累计平均损失: 1.0093
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.7606 | 累计平均损失: 1.0061
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 1.0964 | 累计平均损失: 1.0036
Epoch 4/20 完成 | 训练准确率: 64.52% | 测试准确率: 71.41%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.7776 | 累计平均损失: 0.9541
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 1.1065 | 累计平均损失: 0.9365
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 1.1598 | 累计平均损失: 0.9410
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 1.0376 | 累计平均损失: 0.9440
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 0.7571 | 累计平均损失: 0.9433
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.8754 | 累计平均损失: 0.9329
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 1.0174 | 累计平均损失: 0.9319
Epoch 5/20 完成 | 训练准确率: 66.93% | 测试准确率: 72.49%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 1.0345 | 累计平均损失: 0.8834
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.8648 | 累计平均损失: 0.8967
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.7777 | 累计平均损失: 0.8975
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.9294 | 累计平均损失: 0.8936
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.9792 | 累计平均损失: 0.8909
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.8154 | 累计平均损失: 0.8907
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.7559 | 累计平均损失: 0.8900
Epoch 6/20 完成 | 训练准确率: 68.60% | 测试准确率: 71.10%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.9510 | 累计平均损失: 0.8497
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.7003 | 累计平均损失: 0.8582
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.7083 | 累计平均损失: 0.8548
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.8100 | 累计平均损失: 0.8550
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 0.8166 | 累计平均损失: 0.8484
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.8500 | 累计平均损失: 0.8488
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.8870 | 累计平均损失: 0.8487
Epoch 7/20 完成 | 训练准确率: 69.93% | 测试准确率: 75.09%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.8798 | 累计平均损失: 0.8072
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.8395 | 累计平均损失: 0.8185
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.7540 | 累计平均损失: 0.8182
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.7876 | 累计平均损失: 0.8187
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.8014 | 累计平均损失: 0.8161
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.7414 | 累计平均损失: 0.8159
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.6962 | 累计平均损失: 0.8131
Epoch 8/20 完成 | 训练准确率: 71.40% | 测试准确率: 75.60%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.7372 | 累计平均损失: 0.8090
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 1.0199 | 累计平均损失: 0.8087
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.7608 | 累计平均损失: 0.8091
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.5126 | 累计平均损失: 0.8038
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.7324 | 累计平均损失: 0.7980
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 1.2076 | 累计平均损失: 0.7962
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.7310 | 累计平均损失: 0.7916
Epoch 9/20 完成 | 训练准确率: 72.28% | 测试准确率: 75.41%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.6593 | 累计平均损失: 0.7873
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.6741 | 累计平均损失: 0.7771
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.6662 | 累计平均损失: 0.7847
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.5484 | 累计平均损失: 0.7795
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.6702 | 累计平均损失: 0.7728
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.7078 | 累计平均损失: 0.7714
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.9456 | 累计平均损失: 0.7685
Epoch 10/20 完成 | 训练准确率: 72.94% | 测试准确率: 77.33%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.6052 | 累计平均损失: 0.7386
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 1.0197 | 累计平均损失: 0.7347
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.7137 | 累计平均损失: 0.7442
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.6888 | 累计平均损失: 0.7425
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.6714 | 累计平均损失: 0.7445
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.8366 | 累计平均损失: 0.7477
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.9278 | 累计平均损失: 0.7477
Epoch 11/20 完成 | 训练准确率: 73.84% | 测试准确率: 78.21%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.6034 | 累计平均损失: 0.7343
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.7667 | 累计平均损失: 0.7332
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.5853 | 累计平均损失: 0.7301
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.7661 | 累计平均损失: 0.7310
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.6942 | 累计平均损失: 0.7275
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.7077 | 累计平均损失: 0.7278
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.7543 | 累计平均损失: 0.7301
Epoch 12/20 完成 | 训练准确率: 74.68% | 测试准确率: 77.60%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.6659 | 累计平均损失: 0.7118
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.8487 | 累计平均损失: 0.6974
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.6342 | 累计平均损失: 0.6970
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 1.0145 | 累计平均损失: 0.7063
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.6711 | 累计平均损失: 0.7065
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.8102 | 累计平均损失: 0.7112
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.5348 | 累计平均损失: 0.7126
Epoch 13/20 完成 | 训练准确率: 75.33% | 测试准确率: 78.67%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.6031 | 累计平均损失: 0.7088
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.7181 | 累计平均损失: 0.7106
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.6364 | 累计平均损失: 0.7035
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.7606 | 累计平均损失: 0.6989
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.8685 | 累计平均损失: 0.7017
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.7426 | 累计平均损失: 0.6962
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.7584 | 累计平均损失: 0.7003
Epoch 14/20 完成 | 训练准确率: 75.55% | 测试准确率: 78.07%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.7551 | 累计平均损失: 0.6830
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.6817 | 累计平均损失: 0.7008
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.5927 | 累计平均损失: 0.6904
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.6278 | 累计平均损失: 0.6832
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.7499 | 累计平均损失: 0.6861
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.7494 | 累计平均损失: 0.6886
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.8442 | 累计平均损失: 0.6878
Epoch 15/20 完成 | 训练准确率: 75.91% | 测试准确率: 79.38%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.6315 | 累计平均损失: 0.6651
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.5422 | 累计平均损失: 0.6771
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.5292 | 累计平均损失: 0.6749
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.8075 | 累计平均损失: 0.6772
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.5710 | 累计平均损失: 0.6723
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.7765 | 累计平均损失: 0.6730
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.6454 | 累计平均损失: 0.6729
Epoch 16/20 完成 | 训练准确率: 76.40% | 测试准确率: 78.83%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.6142 | 累计平均损失: 0.6614
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.5320 | 累计平均损失: 0.6578
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.7445 | 累计平均损失: 0.6527
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.6682 | 累计平均损失: 0.6578
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.5534 | 累计平均损失: 0.6600
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.7424 | 累计平均损失: 0.6619
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.6657 | 累计平均损失: 0.6599
Epoch 17/20 完成 | 训练准确率: 76.96% | 测试准确率: 79.31%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.8689 | 累计平均损失: 0.6439
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.7023 | 累计平均损失: 0.6516
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.5702 | 累计平均损失: 0.6487
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.7089 | 累计平均损失: 0.6460
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.5225 | 累计平均损失: 0.6542
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.5909 | 累计平均损失: 0.6518
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.5893 | 累计平均损失: 0.6532
Epoch 18/20 完成 | 训练准确率: 77.11% | 测试准确率: 78.71%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.8123 | 累计平均损失: 0.6225
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.6337 | 累计平均损失: 0.6336
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.5614 | 累计平均损失: 0.6452
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.5720 | 累计平均损失: 0.6460
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.5872 | 累计平均损失: 0.6492
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.6150 | 累计平均损失: 0.6496
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.7645 | 累计平均损失: 0.6496
Epoch 19/20 完成 | 训练准确率: 77.23% | 测试准确率: 80.43%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.6415 | 累计平均损失: 0.6323
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.5903 | 累计平均损失: 0.6223
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.8536 | 累计平均损失: 0.6257
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.7344 | 累计平均损失: 0.6274
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.7595 | 累计平均损失: 0.6307
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.4456 | 累计平均损失: 0.6351
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.5326 | 累计平均损失: 0.6336
Epoch 20/20 完成 | 训练准确率: 77.80% | 测试准确率: 80.35%
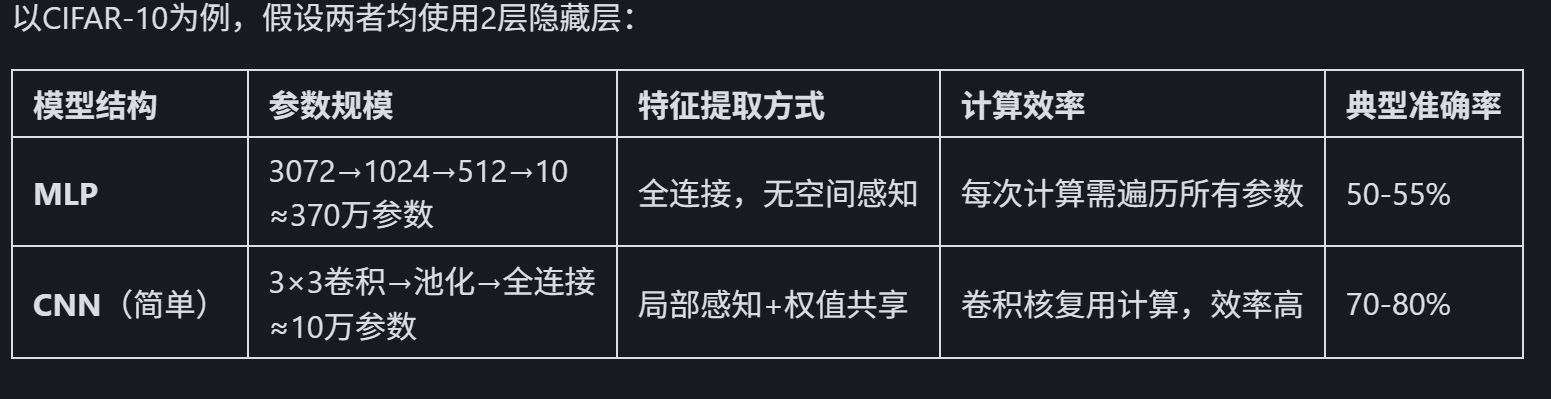
作业
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers# 加载和预处理数据
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype("float32") / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype("float32") / 255.0
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)# 定义简单的 CNN 模型
def simple_cnn():model = keras.Sequential([layers.Conv2D(16, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(10, activation='softmax')])return model# 定义复杂的 CNN 模型
def complex_cnn():model = keras.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(256, activation='relu'),layers.Dense(128, activation='relu'),layers.Dense(10, activation='softmax')])return model# 定义不同的优化器
optimizers = {'SGD': keras.optimizers.SGD(learning_rate=0.01),'Adam': keras.optimizers.Adam(learning_rate=0.001)
}# 训练不同的模型和优化器组合
epochs = 5
batch_size = 64for model_name, model_fn in [('Simple CNN', simple_cnn), ('Complex CNN', complex_cnn)]:for optimizer_name, optimizer in optimizers.items():model = model_fn()model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])print(f"Training {model_name} with {optimizer_name} optimizer:")history = model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, y_test))train_loss = history.history['loss']train_acc = history.history['accuracy']val_loss = history.history['val_loss']val_acc = history.history['val_accuracy']print(f"Training Loss: {train_loss}")print(f"Training Accuracy: {train_acc}")print(f"Validation Loss: {val_loss}")print(f"Validation Accuracy: {val_acc}")@浙大疏锦行