【AI论文】推理语言模型的强化学习熵机制
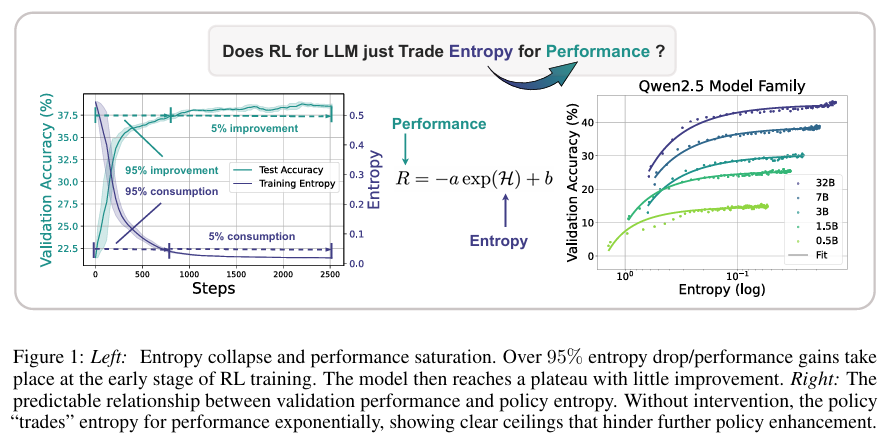
摘要:本文旨在克服将强化学习扩展到使用 LLM 进行推理的主要障碍,即策略熵的崩溃。 这种现象在没有熵干预的RL运行中一直存在,其中策略熵在早期训练阶段急剧下降,这种探索能力的减弱总是伴随着策略性能的饱和。 在实践中,我们建立了熵H和下游性能R之间的转换方程R=-a*e^H+b。这一经验定律强烈表明,政策性能是从政策熵中交易出来的,因此受到其耗尽的瓶颈限制,上限是完全可预测的H=0,R=-a+b。我们的发现需要熵管理,以便不断探索RL的扩展计算。为此,我们从理论和经验上研究了熵动态。 我们的推导强调,政策熵的变化是由行动概率与对数变化之间的协方差驱动的,这与使用类政策梯度算法时的优势成正比。 实证研究表明,协方差项和熵差的值完全匹配,支持了理论结论。 此外,协方差项在整个训练过程中大部分时间都是正的,这进一步解释了为什么策略熵会单调下降。 通过理解熵动力学背后的机制,我们通过限制高协方差令牌的更新来控制熵。 具体而言,我们提出了两种简单而有效的技术,即 Clip-Cov 和 KL-Cov,它们分别对具有高协方差的标记进行裁剪并应用 KL 惩罚。 实验表明,这些方法鼓励探索,从而帮助策略逃脱熵崩溃,实现更好的下游性能。Huggingface链接:Paper page,论文链接:2505.22617
研究背景和目的
研究背景
近年来,随着大型语言模型(LLMs)在各种自然语言处理任务中的显著成功,如何通过强化学习(RL)进一步提升这些模型的推理能力成为了一个重要的研究方向。强化学习作为一种从经验中学习的技术,能够在没有直接监督信号的情况下,通过试错来优化策略。然而,将强化学习应用于LLMs时,一个主要的障碍是策略熵的崩溃(collapse of policy entropy)。策略熵是衡量策略不确定性的一个指标,它反映了策略在行动选择过程中的探索能力。在大量RL实验中,研究人员观察到,在没有熵干预的情况下,策略熵在训练早期阶段会急剧下降,导致策略变得过于自信,探索能力减弱,进而使得策略性能达到饱和,难以进一步提升。
这种现象不仅限制了RL在LLMs推理任务中的扩展性,还引发了关于RL是否仅仅是在挖掘预训练模型中已存在的潜在行为的讨论。因此,深入理解策略熵崩溃的机制,并寻找有效的熵管理方法,对于推动RL在LLMs中的应用具有重要意义。
研究目的
本文旨在通过深入研究RL中策略熵的崩溃机制,提出有效的熵管理方法,以促进RL在LLMs推理任务中的持续探索和性能提升。具体来说,研究目的包括:
- 揭示策略熵崩溃的机制:通过理论和实证研究,分析策略熵在RL训练过程中的动态变化,特别是其崩溃的原因和机制。
- 建立熵与下游性能之间的关系:通过实证分析,建立策略熵与下游任务性能之间的定量关系,为预测策略性能提供理论基础。
- 提出熵管理方法:基于对策略熵动态变化的理解,设计有效的熵管理方法,以防止策略熵崩溃,促进持续探索。
- 验证熵管理方法的有效性:通过实验验证所提出的熵管理方法在提升RL在LLMs推理任务中的性能方面的有效性。
研究方法
理论分析
本文首先从理论上分析了策略熵的动态变化。具体来说,研究了在Softmax策略下,策略熵的变化如何由行动概率的对数与对数变化之间的协方差驱动。对于Policy Gradient和Natural Policy Gradient算法,进一步推导了策略熵变化的表达式,揭示了策略熵与行动优势之间的内在联系。
实证研究
为了验证理论分析的结论,本文进行了广泛的实证研究。实验涵盖了多个LLM家族和基础模型,包括Qwen2.5、Mistral、LLaMA和DeepSeek-Math等,并在数学和编程等可验证任务上进行了评估。实验过程中,记录了策略熵和下游任务性能的变化,并分析了它们之间的关系。
熵管理方法设计
基于对策略熵动态变化的理解,本文设计了两种简单而有效的熵管理方法:Clip-Cov和KL-Cov。
- Clip-Cov:通过随机选择并裁剪具有高协方差的标记,限制这些标记对策略梯度的贡献,从而防止策略熵崩溃。
- KL-Cov:对具有高协方差的标记应用KL惩罚,以控制策略更新,保持策略的多样性。
研究结果
策略熵崩溃的机制
理论和实证研究表明,策略熵的崩溃主要是由于在训练早期阶段,策略对高优势行动的过度自信选择导致的。具体来说,当某个行动具有高优势且高概率时,策略熵会下降;相反,当某个稀有行动具有高优势时,策略熵会增加。然而,在RL训练过程中,高优势行动往往伴随着高概率,导致策略熵持续下降。
熵与下游性能之间的关系
通过实证分析,本文建立了策略熵与下游任务性能之间的定量关系,即R=-a*e^H+b。这一关系表明,策略性能是从策略熵中交易出来的,策略熵的耗尽会限制策略性能的进一步提升。此外,研究还发现,不同RL算法对策略熵与下游性能关系的影响不大,这表明该关系可能反映了策略模型和训练数据的内在特性。^[20]^
熵管理方法的有效性
实验结果表明,所提出的Clip-Cov和KL-Cov方法能够有效地控制策略熵,防止其崩溃,并促进持续探索。具体来说,与基准方法相比,使用Clip-Cov和KL-Cov方法的策略在数学和编程任务上的性能均有显著提升。此外,这些方法还能够保持较高的策略熵水平,使策略在训练过程中保持更强的探索能力。
研究局限
尽管本文在揭示RL中策略熵崩溃的机制和提出有效的熵管理方法方面取得了显著进展,但仍存在一些局限性:
-
模型和数据集的局限性:本文的实验主要基于有限的LLM家族和基础模型,以及数学和编程等可验证任务。这些模型和任务可能无法完全代表所有LLMs和RL应用场景,因此研究结果的普适性可能受到一定限制。
-
熵管理方法的复杂性:虽然Clip-Cov和KL-Cov方法在实验中表现出了良好的性能,但它们的实现可能相对复杂,需要仔细调整超参数以获得最佳效果。此外,这些方法可能不适用于所有RL算法和任务类型,需要进一步的研究来验证其通用性。
-
策略熵与性能关系的深入理解:尽管本文建立了策略熵与下游性能之间的定量关系,但对于这一关系的内在机制仍缺乏深入的理解。例如,为什么策略熵的耗尽会限制策略性能的进一步提升?是否存在最优的策略熵水平以平衡探索和利用?这些问题需要进一步的研究来解答。
未来研究方向
针对本文的研究局限和当前RL在LLMs应用中的挑战,未来的研究方向可以包括:
-
扩展模型和数据集的范围:未来的研究可以扩展到更多的LLM家族和基础模型,以及更广泛的任务类型,以验证本文研究结果的普适性。同时,可以考虑使用非可验证任务来评估熵管理方法的有效性。
-
简化熵管理方法:未来的研究可以致力于简化Clip-Cov和KL-Cov等熵管理方法的实现,降低其复杂性,并提高其通用性。例如,可以探索更自动化的超参数调整方法,或者设计更通用的熵管理策略。
-
深入理解策略熵与性能的关系:未来的研究可以进一步探索策略熵与下游性能之间的内在机制,揭示为什么策略熵的耗尽会限制策略性能的进一步提升。此外,可以研究是否存在最优的策略熵水平以平衡探索和利用,并探索如何动态调整策略熵以适应不同的训练阶段和任务需求。
-
结合其他技术提升RL性能:未来的研究可以探索将熵管理方法与其他RL技术(如经验回放、目标网络等)相结合,以进一步提升RL在LLMs推理任务中的性能。此外,还可以考虑将RL与其他机器学习技术(如迁移学习、元学习等)相结合,以推动LLMs在更广泛任务中的应用。
综上所述,本文通过深入研究RL中策略熵的崩溃机制,提出了有效的熵管理方法,为推动RL在LLMs推理任务中的应用提供了新的思路和方法。未来的研究可以进一步扩展模型和数据集的范围、简化熵管理方法、深入理解策略熵与性能的关系,并结合其他技术提升RL性能,以推动LLMs在更广泛任务中的应用和发展。