目标检测我来惹1 R-CNN
目标检测算法:
识别图像中有哪些物体和位置
目标检测算法原理:
记住算法的识别流程、解决问题用到的关键技术
目标检测算法分类:
两阶段:先区域推荐ROI,再目标分类
region proposal+CNN提取分类的目标检测框架
RCNN FASTER RCNN
端到端:一个网络,输入到输出:类别加位置
yolo SSD
目标检测的任务:
分类原理:得到每个类别的概率,取最大概率
CNN--卷积神经网络
输入层+卷积、激活、池化+全连接层+输出
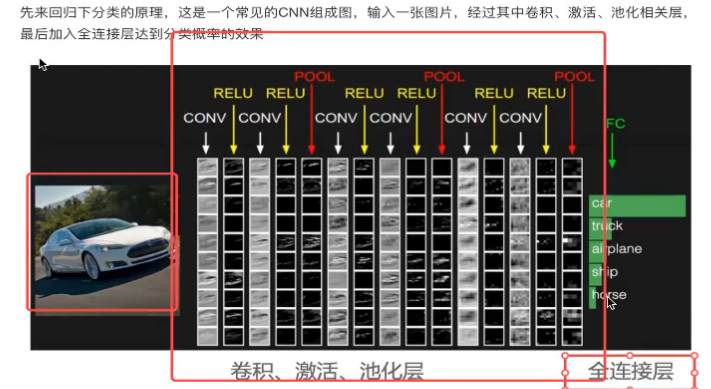
激活函数:relu、输出:softmax得出概率
损失函数:交叉熵损失函数--衡量
图片中只有一个目标:分类+定位
分类评估指标:
| 指标 | 说明 |
|---|---|
| 分类准确率(Accuracy) | 正确分类的目标数 / 所有预测目标数(仅当类别预测数量和真实相同且位置匹配时才有意义) |
| Precision(精确率) | 预测为该类中有多少是对的 |
| Recall(召回率) | 实际该类中你检测到了多少 |
定位评估指标:
| 指标 | 说明 |
|---|---|
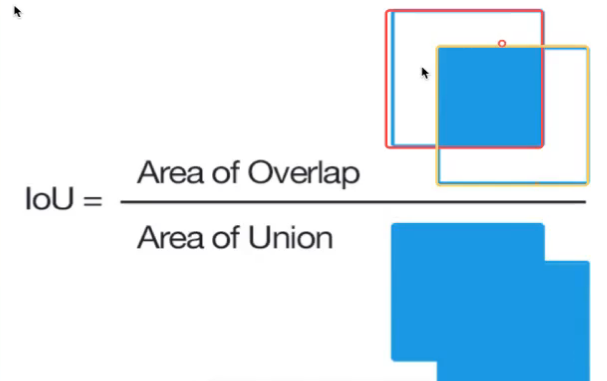
| IoU(Intersection over Union) | 预测框和真实框的重合度 |
目标框:bounding box
| 名称 | 含义 | |
|---|---|---|
| Ground Truth bounding box | 人工标注框 | 真实值 |
| Predicted bounding box | 预测标注框 | 预测值 |
| IoU交并比 | 真实框和预测框的重叠程度 | 交集/并集 重合面积除以两个框的所有面积 |

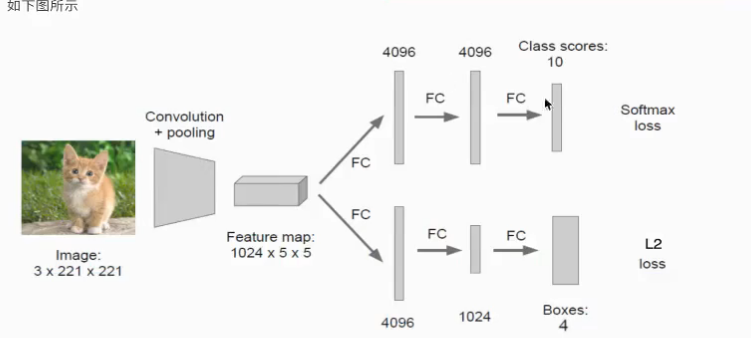
分类+定位的思路:
让网络多输出一个全连接层
1、类别概率值 softmax--分类损失函数:交叉熵损失函数
2、输出四个位置坐标-回归损失:L2 loss
位置坐标处理:每个位置除以图像的像素值--归一化
| 任务阶段 | 是否需要归一化? |
|---|---|
| 训练前准备数据 | ✅ 建议:提前归一化 GT 框(输入 label 时) |
| 模型输出 | ✅ 输出的是 [0, 1] 范围的预测值(便于训练) |
多个目标的任务!--目标检测
R-CNN基础算法
region proposal 候选区域方法
以神经网络为基础的两阶段 目标检测模型。
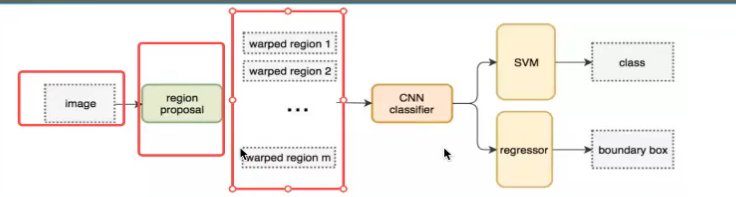
步骤(测试过程)
1.找出图像中可能存在的候选区域ROI,得出2000个候选区域
选择性搜索SS筛选区域
2.统一图片大小,输入CNN网络提取特征,得出2000个特征向量
使用AlexNet网络,统一候选区域大小227*227warped region
统一大小操作:crop和wrap,减少图像的变形
CNN网络提取出的特征向量保存在磁盘中
对 2000 个候选框,每个区域提一个 4096 维的特征 → 形成一个
2000 × 4096的特征矩阵
3.20个SVM进行分类,得到2000*20的得分矩阵
SVM特征向量训练分类器:二分类
20代表数据集中需要检测20个类别,
每个分类器判断2000个候选区域的特征向量,
第一个分类器判断:是猫?不是?那是背景
第二个分类器:是狗?不是?
输出:
2000 × 20的得分矩阵(每一行是该区域对每个类别的置信度)
4.进行NMS非极大值抑制,提出候选框
NMS:筛选候选框,得到非重叠、高置信度的目标框
比较IoU >0.5删去
5.修正候选区域,对bbox回归微调
回归过程:用于修正筛选的候选区域,使它回归ground truth
线性回归:特征值是候选区域,目标值是对应的GT。
建立回归方程学习参数

训练过程:
预训练+微调
🔹 预训练阶段:
-
用 ImageNet 数据集 训练 CNN 模型(如 AlexNet、ResNet)
-
有一个现有的模型和参数
🔹 微调阶段:
-
替换最后一层输出(从1000类 → 目标检测的20类)
-
使用 R-CNN 的候选区域图像、正负样本标签输入到model1中
-
再继续训练 CNN(特别是全连接层部分)
🔹 训练SVM特征向量分类器+bbox regressor
每个类别训练一个分类器
表现:在voc2007上准确度66%
缺点:训练阶段多;训练耗时;
总结: