GNSS终端授时之四:高精度的PTP授时
我们在GNSS终端的授时之三:NTP网络授时中介绍了NTP网络授时的基本原理。我们知道了NTP授时的精度跟网络环境相关,即使在局域网中NTP授时的精度也只能到ms级别。如果广域网,经过多级交换机,路由器,由于传输路径和延时的不确定性,NTP授时的精度在百ms的级别。
为什么NTP授时精度只能到ms(局域网),百ms(广域网)呢?
在上一个文章中也提到了,导致NTP授时精度比较低的原因主要有2个:
-
CPU的处理延时
NTP授时原理中的四个时间戳,T1、T2、T3、T4,都是CPU处理时间数据包的时刻,并不是数据包从网口发送/接收的时刻。
CPU处理数据包的时刻 和 数据包从网口上输入/输出的时刻 ,肯定存在差异,这个也会引起授时精度降低。
而且由于CPU都带有操作系统,是多线程运行的,带来的结果是CPU的处理延时并不是一个确定的数值,没法进行补偿。
-
网络环境的延时
在 NTP 授时原理中,假定从服务器到客户端的网络传输延时 T1 和从客户端到服务器的网络传输延时 T2 相等且对称。而实际网络环境中,存在多级交换机,多级路由器,上面的两个时间T1和T2不可能是相等、对称的。
这就带来了NTP授时的误差。随着广域网中国路由器的数量增多,从服务器到客户端的路由路径 和从客户端到服务器的路由路径 会有很大的差异,导致T1和T2的差异更大,所以授时精度也会到百ms的级别。
那么,有没有一种办法,能够让网络授时精度达到1us以下呢?
今天我们就来聊聊这个话题。
授时精度能够达到1us以下精度的网络授时方式是有的,这就是PTP授时。
PTP授时中的第一个“P”的意思就是Precise,精确的意思。
我们从NTP授时精度差的痛点开始介绍。
CPU处理延时怎么解决
既然
-
CPU处理存在延时
-
应该记录的是数据包从网口发送和接收的时刻
那么
我们给T1、T2、T3和T4打时间戳的时候,直接在物理层(PHY)或者网卡(NIC)记录时间,这样就绕过了操作系统和软件协议栈的延时抖动,不存在由于操作系统的调度,中断处理等导致的随机延时了。
就像下面这个图上所表示的:
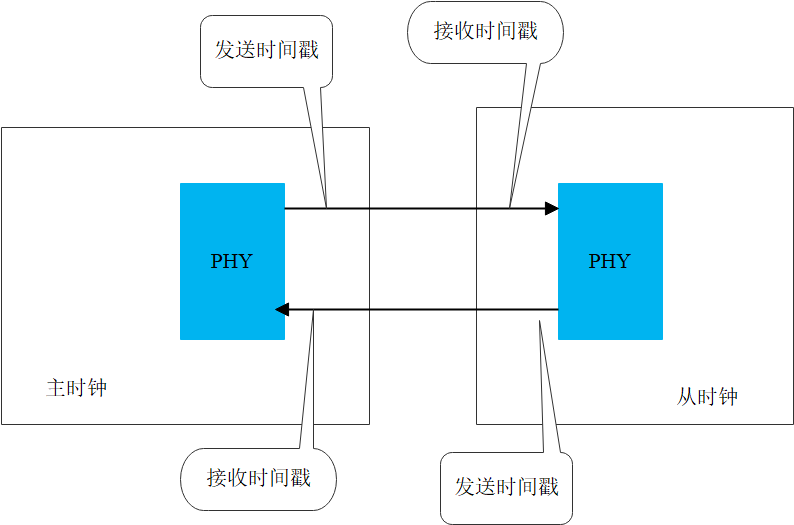
时间戳
网络环境延时怎么解决
中间节点延时补偿
网络中数据包经过的交换机、路由器这些中间节点的时候,在节点的内部都存在处理时间,这个交换机和路由器的处理时间,称为驻留时间(Residence Time)。
如果我们能够把驻留时间测量出来,然后作为补偿值放在时间数据包的专用字段中,发送到下一级。
下一级节点收到数据包之后,经过处理,在对外发送的时候,把自己的驻留时间和上一级的驻留时间相加,相加的结果放在时间数据包的专用字段中。
。。。。
这样一级一级的传递下去,等到数据包从主时钟到达从时钟的时候,从时钟不仅知道了从主时钟到从时钟的总路径延时T,还知道了中间各个节点总的驻留时间Tr。
在主从时钟之间传输的数据包中有专门的时间校正字段correctionField。
我们假定主时钟和从时钟之间有2个路由器,第一个路由器的驻留时间是3us,第二个路由器的驻留时间是2us。主时钟发送的数据包从第一个路由器发出的时候,数据包的correctionField字段写上了3us,数据包从第二个路由器发出的时候,数据包的correctionField字段写上了5us。
从时钟拿到数据包之后,从correctionField字段中拿到了5us,就知道网络路径上的路由器节点增加了5us延迟,那么
总路径延时T减去总驻留时间Tr=5us,不就是实际的网络传输延时吗?
以此类推,如果有N级路由器,每个路由器都把自己的处理驻留时间加到correctionField字段上去。
我们可以用下面这个图来说明。
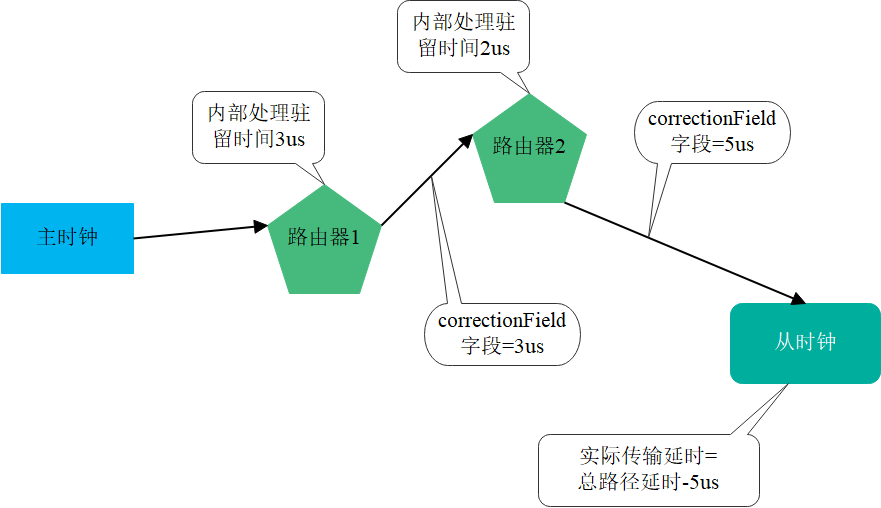
驻留时间分析
通过上述的办法,可以消除交换机、路由器内部处理带来的延时影响,即使经过了多级交换机,多级路由器也没关系了。
中间节点延时补偿,在业内有一个专门的术语“透明时钟”,意思也就是说,数据包通过节点是完全“透明”的,没有增加延时,原因是延时已经被补偿掉了。
强制路由
中间节点延时补偿能够消除路由器、交换机内部处理延时的影响。但是我们从服务器到客户端的路由路径,和,从客户端到服务器的路由路径 不同的话,仍然会存在路径延时的误差,导致往返延时的不对称,最终影响授时的精度。
所以,我们可以对网络路由进行优化,通过配置路由协议,强制服务器到客户端之间双向往返流量走相同的物理路径,从而保证往返延迟的对称性。
另外如果能够为PTP时间数据包划分独立的VLAN或者物理链路,就更好了,不仅保证了双向链路走了相同的物理路径,还避免了路径上的数据堵塞可能导致的随机延迟。
具体实现方式
上面根据NTP授时精度不高的痛点,提出了提高授时精度的解决方法。而PTP授时就是利用上面的方法来提高授时精度的。
首先PTP时间协议中的时间戳,都是基于网卡NIC或者物理层PHY的时间,是数据包从网口发送/接收的时刻,消除了CPU处理延时的影响。
在网络中的节点,交换机和路由器,都是测量自己的处理时间(驻留时间)Tr,然后把自己的驻留时间加到总的驻留时间中
具体的实现方式如下:
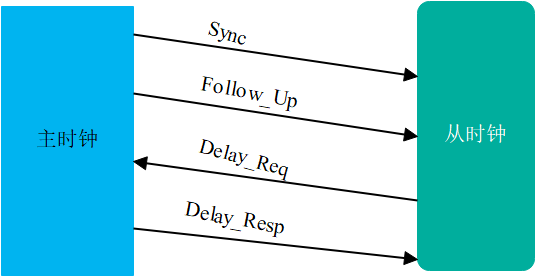
主从时间传递
(1) Sync 和 Follow_Up 消息(主 → 从)
主时钟发送同步信息Sync。如果硬件时间的话,就把网口的发送时间T1放在Sync数据包中发送出去。
如果硬件不能支持的话,就由CPU读取网口发送时间T1,随后再发送一个Follow_UP数据包,把T1放在Follow_UP数据包中发送出去。
(2) Delay_Req 消息(从 → 主)
从时钟收到Sync数据包之间,记录自己的网口接收时刻T2,然后向主时钟发送Delay_Req数据包,同时记录自己网口的发送时刻T3。
在这个过程中,T2 和 T3 这两个时间戳都不需要向主时钟回传。
(3) Delay_Resp回传信息(主→从)
主时钟收到Delay_Req之后,记录自己网口的接收时间T4,然后通过Delay_Resp数据包把T4返回给从时钟。
那么现在从时钟手里有了T1、T2、T3和T4,应该怎么处理才能得到主从时钟时间的时间差offset呢?
跟NTP授时的时候类似,我们可以如下计算:

从时钟计算出了offset之后,将自己的时钟调整offset,就可以完成跟主时钟时间的同步了。
为什么PTP授时仍然能够假定主从之间的往返路径延时是对称的呢?就是因为:
透明时钟消除了各个节点的内部处理驻留时间,强制路由限定了主从之间相同的路径,保证了主从往返延时的对称性。
时钟传递,从时钟变成下一级的主时钟
如果网络过于复杂,即使经过上述处理,主从之间的往返延时仍然是不对称的。还有一种办法能够提高授时精度,就是把主时钟到从时钟之间的长链路分割为多个短链路。
假定主时钟A需要给从时钟B授时,但是A和B之间网络比较复杂,还可以中间增加一个PTP的节点C,C具备从主时钟A获取时间的能力,把自己的时间同步到主时钟。
同时C还可以作为新的主时钟,给下一级的时钟B提供时间。
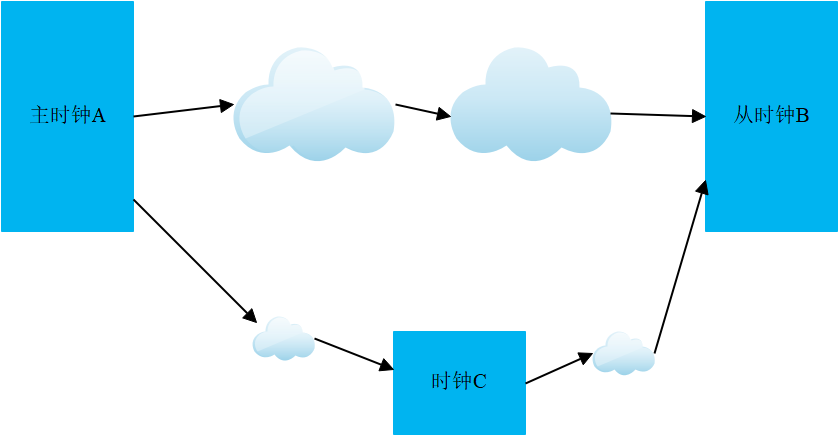
时钟传递
由于长链路分成了多个短链路,每个短链路的往返延时就更容易保证对称了。
示例
下面是某PTP授时板卡的技术指标和说明

PTP授时板