DRW - 加密市场预测
1.数据集描述
在本次比赛中,数据集包含加密市场的分钟级历史数据。您的挑战是预测未来的加密货币市场价格走势。这是一项kaggle社区预测竞赛,您可以以 CSV 文件的形式或通过 Kaggle Notebooks 提交您的预测。有关使用 Kaggle Notebooks 的更多详细信息,请参阅此链接。比赛期间的公共排行榜不会进行评分,仅用于使用公共测试数据编写模型提交。一旦有效提交阶段结束,我们将使用更新的数据更新私人排行榜,这些数据将用于确定最终的团队排名。
2.文件
train.parquet
The training dataset containing all historical market data along with the corresponding labels.
timestamp: The timestamp index representing the minute associated with each row.bid_qty: The total quantity buyers are willing to purchase at the best (highest) bid price at the given timestamp.ask_qty: The total quantity sellers are offering to sell at the best (lowest) ask price at the given timestamp.buy_qty: The total trading quantity executed at the best ask price during the given minute.sell_qty: The total trading quantity executed at the best bid price during the given minute.volume: The total traded volume during the minute.X_{1,...,890}: A set of anonymized market features derived from proprietary data sources.label: The target variable representing the anonymized market price movement to be predicted.
test.parquet
The test dataset has the same feature structure as train.parquet, with the following differences:
timestamp: To prevent future peeking, all timestamps are masked, shuffled, and replaced with a unique .IDlabel: All labels in the test set are set to 0.
sample_submission.csv
3.要求
我们邀请您开发一个能够使用我们的生产数据预测加密市场价格变动的模型。通过定量方法得出的准确方向信号可以显着增强我们的交易策略并实现更精确的市场机会识别。
3.1 描述
加密货币市场代表了最具活力和发展最快的金融格局之一,为那些能够从其庞大的数据流中提取有意义见解的人提供了大量机会。然而,加密货币中的市场信息本质上具有较低的信噪比,这使得识别预测模式变得异常困难。价格变动是由流动性、订单流动态、情绪变化和结构性低效率的复杂相互作用决定的,需要复杂的定量技术来解码。
三十多年来,DRW 一直处于金融创新的前沿,采用尖端技术和严格的定量研究来优化交易策略。通过我们专门的加密交易部门 Cumberland,我们成为数字资产领域最早的机构参与者之一,帮助塑造市场结构并提高效率。作为加密货币领域最大的流动性提供商之一,我们专注于开发适应不断变化的市场环境的专有交易策略。
在本次比赛中,我们邀请您使用我们的生产特征数据以及公开可用的市场交易量统计数据构建一个模型,该模型能够预测短期加密未来价格走势。我们提供的专有生产功能是我们交易策略不可或缺的一部分,可以捕捉微妙的市场信号,帮助我们实时导航和抓住机会。此外,这些生产特征与描述更广泛市场状态的公共数据相结合,为数据挖掘和建模创建了一个丰富且具有挑战性的数据集。您的任务是将这些不同的信息来源整合到一个方向信号中,以有效预测加密货币未来的价格走势。
通过这项挑战赛,我们的目标是复制我们在 DRW 每天解决的现实世界问题——利用先进的机器学习技术从嘈杂的高维市场数据中提取结构。最成功的解决方案将提供一个学习模型,该模型有效地结合了所有数据特征之间的显式模式和隐式交互,以优化价格走势预测。
我们期待看到 Kaggle 社区如何解决这个问题,以及不同的建模技术如何增强我们对市场动态的理解。如果您对预测建模之外的复杂、高影响力的挑战感到兴奋,DRW 在定量研究、技术和交易策略开发的交叉领域提供了各种机会。
比赛名称:DRW - 加密市场预测
比赛赞助商: DRW Holdings, LLC
比赛赞助商地址:540 W Madison St Suite 2500, 芝加哥, IL 60661, 美国
比赛网站:DRW - Crypto Market Prediction | Kaggle
实现代码
# -*- coding: utf-8 -*-
# @Time : 2025/6/1 11:48
# @Author : AZshengduqiusuo
# @File : 01.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.utils import resample
from sklearn.preprocessing import StandardScaler
from sklearn.metrics.pairwise import rbf_kernel, polynomial_kernel
from xgboost import XGBRegressor
from scipy.stats import pearsonr
from scipy.special import expit # sigmoid function
import warningswarnings.filterwarnings('ignore')# 配置类
class CFG:train_path = "/kaggle/input/drw-crypto-market-prediction/train.parquet"test_path = "/kaggle/input/drw-crypto-market-prediction/test.parquet"sample_sub_path = "/kaggle/input/drw-crypto-market-prediction/sample_submission.csv"n_bootstraps = 20bootstrap_sample_size = 0.8n_features_to_analyze = 30 # 由于特征扩展而减少random_seed = 42# 数据清洗参数clip_percentile = 0.001max_allowed_value = 1e8min_allowed_value = -1e8# 变换参数enable_polynomial = Trueenable_logarithmic = Trueenable_exponential = Trueenable_trigonometric = Trueenable_kernels = Trueenable_interactions = Truepolynomial_degrees = [2, 3] # 平方和立方n_kernel_landmarks = 10 # 核特征的标志点数量interaction_top_n = 10 # 用于交互特征的前N个特征def comprehensive_data_cleaning(df, features, verbose=True):"""执行全面的数据清洗以处理所有数据质量问题"""if verbose:print("\n执行全面的数据清洗...")print(f"初始形状: {df.shape}")df_clean = df.copy()# 步骤1: 将无限值替换为NaNfor col in features:inf_count = np.isinf(df_clean[col]).sum()if inf_count > 0 and verbose:print(f" - 列 {col}: 发现 {inf_count} 个无限值")df_clean[col] = df_clean[col].replace([np.inf, -np.inf], np.nan)# 步骤2: 处理缺失值missing_counts = df_clean[features].isna().sum()if verbose and missing_counts.sum() > 0:print(f"\n在 {missing_counts[missing_counts > 0].shape[0]} 列中发现缺失值")print(" 使用中位数填充缺失值...")for col in features:if df_clean[col].isna().any():median_val = df_clean[col].median()if pd.isna(median_val):median_val = 0df_clean[col] = df_clean[col].fillna(median_val)# 步骤3: 裁剪极端值if verbose:print("\n裁剪极端值...")for col in features:lower_percentile = df_clean[col].quantile(CFG.clip_percentile)upper_percentile = df_clean[col].quantile(1 - CFG.clip_percentile)original_min = df_clean[col].min()original_max = df_clean[col].max()df_clean[col] = df_clean[col].clip(lower=lower_percentile, upper=upper_percentile)df_clean[col] = df_clean[col].clip(lower=CFG.min_allowed_value, upper=CFG.max_allowed_value)if verbose and (original_min < lower_percentile or original_max > upper_percentile):print(f" - {col}: 从 [{original_min:.2e}, {original_max:.2e}] 裁剪到 [{df_clean[col].min():.2e}, {df_clean[col].max():.2e}]")# 步骤4: 移除常数值特征constant_features = []for col in features:if df_clean[col].std() == 0:constant_features.append(col)if constant_features and verbose:print(f"\n移除 {len(constant_features)} 个常数值特征")features_clean = [f for f in features if f not in constant_features]if verbose:print("\n最终数据验证:")print(f" - 包含无限值: {np.isinf(df_clean[features_clean].values).any()}")print(f" - 包含NaN值: {df_clean[features_clean].isna().any().any()}")print(f" - 剩余特征: {len(features_clean)}")return df_clean, features_cleandef create_polynomial_features(df, features, degrees=[2, 3]):"""创建特征的多项式变换"""print(f"\n创建多项式特征 (次数: {degrees})...")new_features = {}for feature in features:for degree in degrees:new_col_name = f"{feature}_pow{degree}"new_features[new_col_name] = np.power(df[feature], degree)print(f" 创建了 {len(new_features)} 个多项式特征")return pd.DataFrame(new_features, index=df.index)def create_logarithmic_features(df, features):"""创建对数变换,正确处理负值"""print("\n创建对数特征...")new_features = {}for feature in features:# 绝对值对数+1(处理零值)new_col_name = f"{feature}_log_abs"new_features[new_col_name] = np.log1p(np.abs(df[feature]))# 保留符号的对数变换(针对可能为负的特征)if (df[feature] < 0).any():new_col_name = f"{feature}_sign_log"new_features[new_col_name] = np.sign(df[feature]) * np.log1p(np.abs(df[feature]))print(f" 创建了 {len(new_features)} 个对数特征")return pd.DataFrame(new_features, index=df.index)def create_exponential_features(df, features):"""创建指数和sigmoid变换"""print("\n创建指数特征...")new_features = {}for feature in features:# 标准化以防止溢出normalized = (df[feature] - df[feature].mean()) / (df[feature].std() + 1e-8)# 指数变换(带安全裁剪)new_col_name = f"{feature}_exp"new_features[new_col_name] = np.exp(np.clip(normalized, -10, 10))# Sigmoid变换new_col_name = f"{feature}_sigmoid"new_features[new_col_name] = expit(normalized)print(f" 创建了 {len(new_features)} 个指数特征")return pd.DataFrame(new_features, index=df.index)def create_trigonometric_features(df, features):"""创建三角函数变换"""print("\n创建三角函数特征...")new_features = {}for feature in features:# 标准化到[-π, π]范围normalized = 2 * np.pi * (df[feature] - df[feature].min()) / (df[feature].max() - df[feature].min() + 1e-8) - np.pinew_features[f"{feature}_sin"] = np.sin(normalized)new_features[f"{feature}_cos"] = np.cos(normalized)new_features[f"{feature}_tan"] = np.clip(np.tan(normalized), -10, 10) # 裁剪以避免无限值print(f" 创建了 {len(new_features)} 个三角函数特征")return pd.DataFrame(new_features, index=df.index)def create_kernel_features(df, features, n_landmarks=10):"""使用RBF和多项式核创建基于核的特征"""print(f"\n使用 {n_landmarks} 个标志点创建核特征...")new_features = {}# 为核计算标准化特征scaler = StandardScaler()features_scaled = scaler.fit_transform(df[features])# 选择标志点(基于分位数以获得更好的覆盖)landmarks_idx = []for q in np.linspace(0, 1, n_landmarks):idx = int(q * (len(df) - 1))landmarks_idx.append(idx)landmarks = features_scaled[landmarks_idx]# RBF核特征rbf_features = rbf_kernel(features_scaled, landmarks, gamma=1.0 / len(features))for i in range(n_landmarks):new_features[f"rbf_landmark_{i}"] = rbf_features[:, i]# 多项式核特征(2次)poly_features = polynomial_kernel(features_scaled, landmarks, degree=2, coef0=1)for i in range(n_landmarks):new_features[f"poly_landmark_{i}"] = poly_features[:, i]print(f" 创建了 {len(new_features)} 个核特征")return pd.DataFrame(new_features, index=df.index)def create_interaction_features(df, features, top_n=10):"""创建顶部特征间的交互特征"""print(f"\n为前 {top_n} 个特征创建交互特征...")new_features = {}# 仅使用前N个特征以限制爆炸增长features_to_interact = features[:top_n]for i, feat1 in enumerate(features_to_interact):for j, feat2 in enumerate(features_to_interact[i + 1:], i + 1):# 乘法交互new_features[f"{feat1}_x_{feat2}"] = df[feat1] * df[feat2]# 除法交互(带安全处理)denominator = df[feat2].replace(0, 1e-8)new_features[f"{feat1}_div_{feat2}"] = df[feat1] / denominatorprint(f" 创建了 {len(new_features)} 个交互特征")return pd.DataFrame(new_features, index=df.index)def apply_feature_transformations(train_df, test_df, features, config):"""应用所有启用的变换创建丰富的特征集"""print("\n" + "=" * 60)print("应用特征变换")print("=" * 60)train_transformed = train_df[features].copy()test_transformed = test_df[features].copy()all_new_features = []# 多项式特征if config.enable_polynomial:poly_train = create_polynomial_features(train_df, features[:20], config.polynomial_degrees)poly_test = create_polynomial_features(test_df, features[:20], config.polynomial_degrees)train_transformed = pd.concat([train_transformed, poly_train], axis=1)test_transformed = pd.concat([test_transformed, poly_test], axis=1)all_new_features.extend(poly_train.columns.tolist())# 对数特征if config.enable_logarithmic:log_train = create_logarithmic_features(train_df, features[:20])log_test = create_logarithmic_features(test_df, features[:20])train_transformed = pd.concat([train_transformed, log_train], axis=1)test_transformed = pd.concat([test_transformed, log_test], axis=1)all_new_features.extend(log_train.columns.tolist())# 指数特征if config.enable_exponential:exp_train = create_exponential_features(train_df, features[:15])exp_test = create_exponential_features(test_df, features[:15])train_transformed = pd.concat([train_transformed, exp_train], axis=1)test_transformed = pd.concat([test_transformed, exp_test], axis=1)all_new_features.extend(exp_train.columns.tolist())# 三角函数特征if config.enable_trigonometric:trig_train = create_trigonometric_features(train_df, features[:10])trig_test = create_trigonometric_features(test_df, features[:10])train_transformed = pd.concat([train_transformed, trig_train], axis=1)test_transformed = pd.concat([test_transformed, trig_test], axis=1)all_new_features.extend(trig_train.columns.tolist())# 核特征if config.enable_kernels:kernel_train = create_kernel_features(train_df, features[:15], config.n_kernel_landmarks)kernel_test = create_kernel_features(test_df, features[:15], config.n_kernel_landmarks)train_transformed = pd.concat([train_transformed, kernel_train], axis=1)test_transformed = pd.concat([test_transformed, kernel_test], axis=1)all_new_features.extend(kernel_train.columns.tolist())# 交互特征if config.enable_interactions:interact_train = create_interaction_features(train_df, features, config.interaction_top_n)interact_test = create_interaction_features(test_df, features, config.interaction_top_n)train_transformed = pd.concat([train_transformed, interact_train], axis=1)test_transformed = pd.concat([test_transformed, interact_test], axis=1)all_new_features.extend(interact_train.columns.tolist())print(f"\n变换后的总特征数: {len(train_transformed.columns)}")print(f" 原始特征: {len(features)}")print(f" 新创建的特征: {len(all_new_features)}")# 清理变换过程中产生的任何无限值或NaN值for col in train_transformed.columns:train_transformed[col] = train_transformed[col].replace([np.inf, -np.inf], np.nan).fillna(0)test_transformed[col] = test_transformed[col].replace([np.inf, -np.inf], np.nan).fillna(0)return train_transformed, test_transformed, train_transformed.columns.tolist()def reduce_mem_usage(dataframe, dataset):"""通过转换为适当的数据类型优化内存使用"""print(f'\n优化内存使用: {dataset}')initial_mem_usage = dataframe.memory_usage().sum() / 1024 ** 2for col in dataframe.columns:col_type = dataframe[col].dtypeif col_type != object:c_min = dataframe[col].min()c_max = dataframe[col].max()if str(col_type)[:3] == 'int':if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:dataframe[col] = dataframe[col].astype(np.int8)elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:dataframe[col] = dataframe[col].astype(np.int16)elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:dataframe[col] = dataframe[col].astype(np.int32)else:if c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:dataframe[col] = dataframe[col].astype(np.float32)final_mem_usage = dataframe.memory_usage().sum() / 1024 ** 2print(f' 内存减少了 {100 * (initial_mem_usage - final_mem_usage) / initial_mem_usage:.1f}%')print(f' 最终内存使用: {final_mem_usage:.2f} MB')return dataframedef select_initial_features(train_df, n_features=50):"""使用初步分析选择顶部特征"""print(f"\n选择前 {n_features} 个特征进行分析...")feature_cols = [c for c in train_df.columns if c not in ['label', 'timestamp']]print(f"可用特征总数: {len(feature_cols)}")train_clean, feature_cols_clean = comprehensive_data_cleaning(train_df,feature_cols,verbose=False)sample_size = min(50000, len(train_clean))sample_indices = np.random.choice(len(train_clean), sample_size, replace=False)train_sample = train_clean.iloc[sample_indices]quick_params = {"tree_method": "hist","max_depth": 6,"n_estimators": 100,"learning_rate": 0.1,"subsample": 0.8,"random_state": CFG.random_seed,"n_jobs": -1,"verbosity": 0}try:X_sample = train_sample[feature_cols_clean]y_sample = train_sample['label']model = XGBRegressor(**quick_params)model.fit(X_sample, y_sample)importances = model.feature_importances_importance_df = pd.DataFrame({'feature': feature_cols_clean,'importance': importances}).sort_values('importance', ascending=False)except Exception as e:print(f"初始特征选择错误: {str(e)}")print("回退到基于相关性的选择...")correlations = train_sample[feature_cols_clean + ['label']].corr()['label'].abs()importance_df = pd.DataFrame({'feature': feature_cols_clean,'importance': correlations[feature_cols_clean]}).sort_values('importance', ascending=False)selected_features = importance_df.head(n_features)['feature'].tolist()market_features = ['bid_qty', 'ask_qty', 'buy_qty', 'sell_qty', 'volume']for mf in market_features:if mf in feature_cols_clean and mf not in selected_features:selected_features.append(mf)if len(selected_features) > n_features:selected_features = selected_features[:n_features]print(f"选择了 {len(selected_features)} 个特征")print(f"前10个特征: {selected_features[:10]}")return selected_features# 主分析
print("=" * 60)
print("加密货币市场特征稳定性分析(带变换)")
print("=" * 60)# 加载数据
print("\n加载数据集...")
train = pd.read_parquet(CFG.train_path).reset_index(drop=True)
test = pd.read_parquet(CFG.test_path).reset_index(drop=True)
print(f"训练集形状: {train.shape}")
print(f"测试集形状: {test.shape}")# 选择初始特征
FEATURES = select_initial_features(train, n_features=CFG.n_features_to_analyze)# 准备数据集
train_selected = train[FEATURES + ['label']].copy()
test_selected = test[FEATURES].copy()# 清洗数据集
print("\n清洗训练数据...")
train_clean, FEATURES_CLEAN = comprehensive_data_cleaning(train_selected, FEATURES)print("\n清洗测试数据...")
test_clean, _ = comprehensive_data_cleaning(test_selected, FEATURES_CLEAN, verbose=False)# 应用变换
train_transformed, test_transformed, ALL_FEATURES = apply_feature_transformations(train_clean, test_clean, FEATURES_CLEAN, CFG
)# 将标签添加回训练数据
train_transformed['label'] = train_clean['label']# 减少内存使用
train_transformed = reduce_mem_usage(train_transformed, "训练集(变换后)")
test_transformed = reduce_mem_usage(test_transformed, "测试集(变换后)")# 从特征列表中移除标签
FEATURES_FINAL = [f for f in ALL_FEATURES if f != 'label']# XGBoost参数
xgb_params = {"tree_method": "hist","colsample_bylevel": 0.7,"colsample_bytree": 0.7,"gamma": 1.0,"learning_rate": 0.05,"max_depth": 8,"min_child_weight": 10,"n_estimators": 300,"n_jobs": -1,"random_state": CFG.random_seed,"reg_alpha": 10,"reg_lambda": 10,"subsample": 0.8,"verbosity": 0
}# 自助采样分析
print(f"\n执行自助采样分析,样本数: {CFG.n_bootstraps}...")
print(f"分析 {len(FEATURES_FINAL)} 个特征(包括变换)\n")bootstrap_importances = []
bootstrap_rankings = []
bootstrap_predictions = []
bootstrap_scores = []
successful_bootstraps = 0for i in range(CFG.n_bootstraps):print(f"自助采样 {i + 1}/{CFG.n_bootstraps}", end='')try:sample_size = int(len(train_transformed) * CFG.bootstrap_sample_size)bootstrap_indices = resample(range(len(train_transformed)),n_samples=sample_size,random_state=CFG.random_seed + i)all_indices = set(range(len(train_transformed)))oob_indices = list(all_indices - set(bootstrap_indices))if len(oob_indices) > 0:val_size = min(len(oob_indices), int(0.2 * len(train_transformed)))val_indices = np.random.choice(oob_indices, val_size, replace=False)else:val_indices = np.random.choice(range(len(train_transformed))),int(0.2 * len(train_transformed))),replace = False)X_bootstrap = train_transformed.iloc[bootstrap_indices][FEATURES_FINAL]y_bootstrap = train_transformed.iloc[bootstrap_indices]['label']X_val = train_transformed.iloc[val_indices][FEATURES_FINAL]y_val = train_transformed.iloc[val_indices]['label']model = XGBRegressor(**xgb_params)model.fit(X_bootstrap,y_bootstrap,eval_set=[(X_val, y_val)],verbose=False)val_pred = model.predict(X_val)val_score = pearsonr(y_val, val_pred)[0]bootstrap_scores.append(val_score)print(f" - 验证分数: {val_score:.4f}")importances = model.feature_importances_bootstrap_importances.append(importances)rankings = len(FEATURES_FINAL) - np.argsort(np.argsort(importances))bootstrap_rankings.append(rankings)predictions = model.predict(test_transformed[FEATURES_FINAL])bootstrap_predictions.append(predictions)successful_bootstraps += 1except Exception as e:
print(f" - 错误: {str(e)[:50]}...")
continueif successful_bootstraps == 0:raise ValueError("所有自助采样迭代都失败了。")print(f"\n成功完成 {successful_bootstraps}/{CFG.n_bootstraps} 次自助采样迭代")# 转换为数组
bootstrap_importances = np.array(bootstrap_importances)
bootstrap_rankings = np.array(bootstrap_rankings)
bootstrap_scores = np.array(bootstrap_scores)# 计算稳定性指标
importance_mean = np.mean(bootstrap_importances, axis=0)
importance_std = np.std(bootstrap_importances, axis=0)
importance_cv = importance_std / (importance_mean + 1e-10)# 创建稳定性数据框
stability_df = pd.DataFrame({'feature': FEATURES_FINAL,'importance_mean': importance_mean,'importance_std': importance_std,'importance_cv': importance_cv,'feature_type': ['原始' if f in FEATURES_CLEAN else '变换' for f in FEATURES_FINAL]
})# 添加变换类型
def get_transformation_type(feature_name):if feature_name in FEATURES_CLEAN:return '原始'elif '_pow' in feature_name:return '多项式'elif '_log' in feature_name:return '对数'elif '_exp' in feature_name or '_sigmoid' in feature_name:return '指数'elif '_sin' in feature_name or '_cos' in feature_name or '_tan' in feature_name:return '三角函数'elif 'rbf_' in feature_name or 'poly_landmark' in feature_name:return '核'elif '_x_' in feature_name or '_div_' in feature_name:return '交互'else:return '其他'stability_df['transformation_type'] = stability_df['feature'].apply(get_transformation_type)# 按重要性排序
stability_df = stability_df.sort_values('importance_mean', ascending=False)print("\n" + "=" * 60)
print("特征稳定性分析结果")
print("=" * 60)
print("\n前20个最重要的特征(原始和变换):")
display_cols = ['feature', 'transformation_type', 'importance_mean', 'importance_cv']
print(stability_df[display_cols].head(20).to_string(index=False))# 增强的可视化
plt.style.use('seaborn-v0_8-darkgrid')
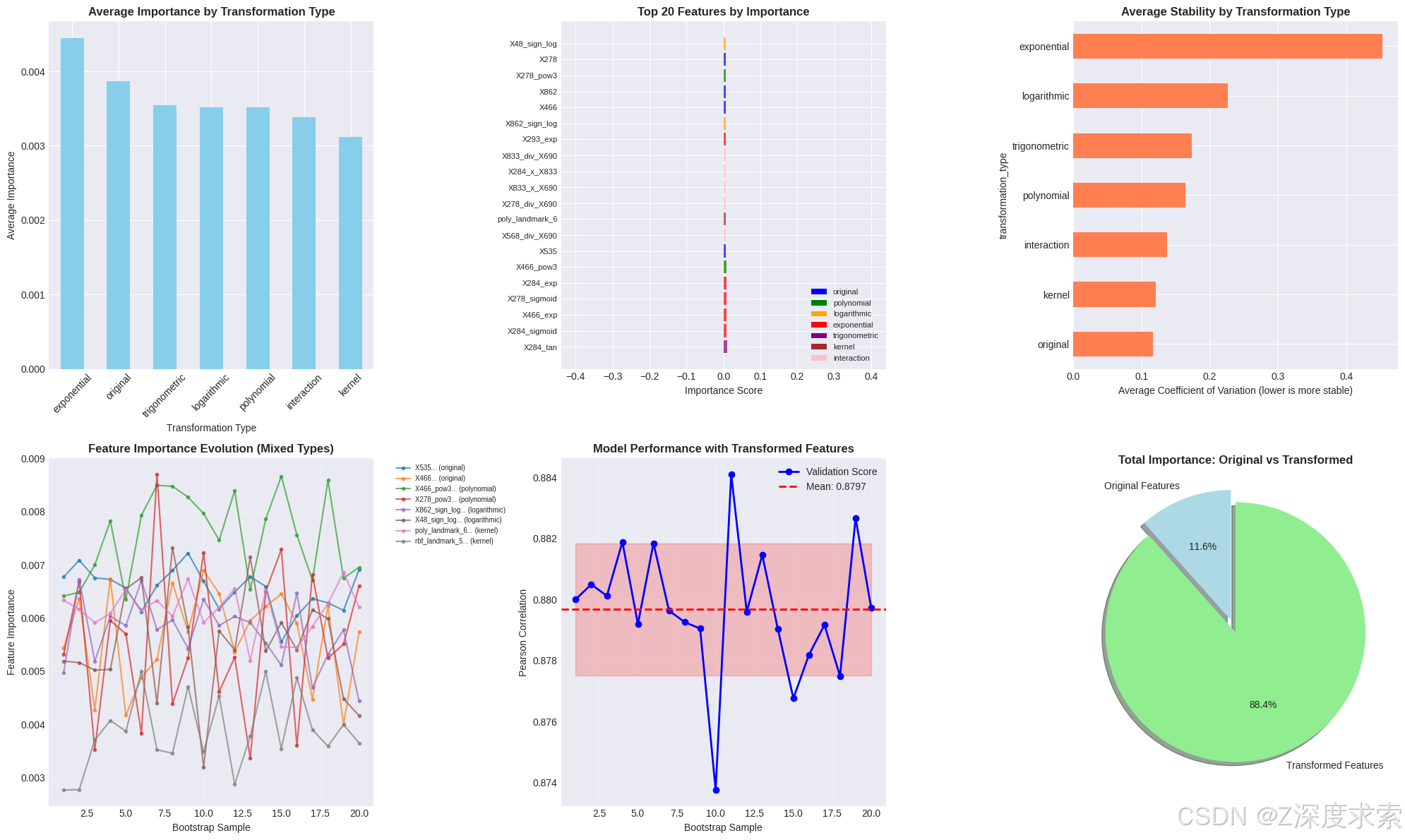
fig, axes = plt.subplots(2, 3, figsize=(20, 12))# 面板1: 按变换类型的特征重要性
ax = axes[0, 0]
transform_importance = stability_df.groupby('transformation_type')['importance_mean'].mean().sort_values(ascending=False)
transform_importance.plot(kind='bar', ax=ax, color='skyblue')
ax.set_title('按变换类型的平均重要性', fontsize=12, fontweight='bold')
ax.set_xlabel('变换类型')
ax.set_ylabel('平均重要性')
ax.tick_params(axis='x', rotation=45)# 面板2: 按变换类型着色的顶部特征
ax = axes[0, 1]
top_n = 20
top_features_df = stability_df.head(top_n)
colors_map = {'原始': 'blue','多项式': 'green','对数': 'orange','指数': 'red','三角函数': 'purple','核': 'brown','交互': 'pink'
}
colors = [colors_map.get(t, 'gray') for t in top_features_df['transformation_type']]y_pos = np.arange(top_n)
ax.barh(y_pos, top_features_df['importance_mean'], color=colors, alpha=0.7)
ax.set_yticks(y_pos)
ax.set_yticklabels(top_features_df['feature'], fontsize=8)
ax.set_xlabel('重要性分数')
ax.set_title('按重要性的前20个特征', fontsize=12, fontweight='bold')# 创建图例
for trans_type, color in colors_map.items():ax.bar(0, 0, color=color, label=trans_type)
ax.legend(loc='lower right', fontsize=8)# 面板3: 稳定性比较
ax = axes[0, 2]
stability_comparison = stability_df.groupby('transformation_type')['importance_cv'].mean().sort_values()
stability_comparison.plot(kind='barh', ax=ax, color='coral')
ax.set_title('按变换类型的平均稳定性', fontsize=12, fontweight='bold')
ax.set_xlabel('平均变异系数(越低越稳定)')# 面板4: 顶部混合特征的特征演变
ax = axes[1, 0]
# 从不同变换类型中选择顶部特征
features_to_plot = []
for trans_type in ['原始', '多项式', '对数', '核']:type_features = stability_df[stability_df['transformation_type'] == trans_type].head(2)features_to_plot.extend(type_features.index.tolist())for idx in features_to_plot[:8]:feature_idx = FEATURES_FINAL.index(stability_df.loc[idx, 'feature'])ax.plot(range(1, successful_bootstraps + 1),bootstrap_importances[:, feature_idx],marker='o',markersize=3,label=f"{stability_df.loc[idx, 'feature'][:20]}... ({stability_df.loc[idx, 'transformation_type']})",alpha=0.7,linewidth=1.5)ax.set_xlabel('自助采样样本')
ax.set_ylabel('特征重要性')
ax.set_title('特征重要性演变(混合类型)', fontsize=12, fontweight='bold')
ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left', fontsize=7)
ax.grid(True, alpha=0.3)# 面板5: 模型性能
ax = axes[1, 1]
ax.plot(range(1, successful_bootstraps + 1),bootstrap_scores,'bo-',label='验证分数',markersize=6,linewidth=2
)
ax.axhline(np.mean(bootstrap_scores),color='red',linestyle='--',label=f'平均: {np.mean(bootstrap_scores):.4f}',linewidth=2
)
ax.fill_between(range(1, successful_bootstraps + 1),np.mean(bootstrap_scores) - np.std(bootstrap_scores),np.mean(bootstrap_scores) + np.std(bootstrap_scores),alpha=0.2,color='red'
)
ax.set_xlabel('自助采样样本')
ax.set_ylabel('皮尔逊相关系数')
ax.set_title('使用变换特征的模型性能', fontsize=12, fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)# 面板6: 原始vs变换特征重要性
ax = axes[1, 2]
original_importance = stability_df[stability_df['transformation_type'] == '原始']['importance_mean'].sum()
transformed_importance = stability_df[stability_df['transformation_type'] != '原始']['importance_mean'].sum()sizes = [original_importance, transformed_importance]
labels = ['原始特征', '变换特征']
colors = ['lightblue', 'lightgreen']
explode = (0.1, 0)ax.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', shadow=True, startangle=90)
ax.set_title('总重要性: 原始vs变换', fontsize=12, fontweight='bold')plt.tight_layout()
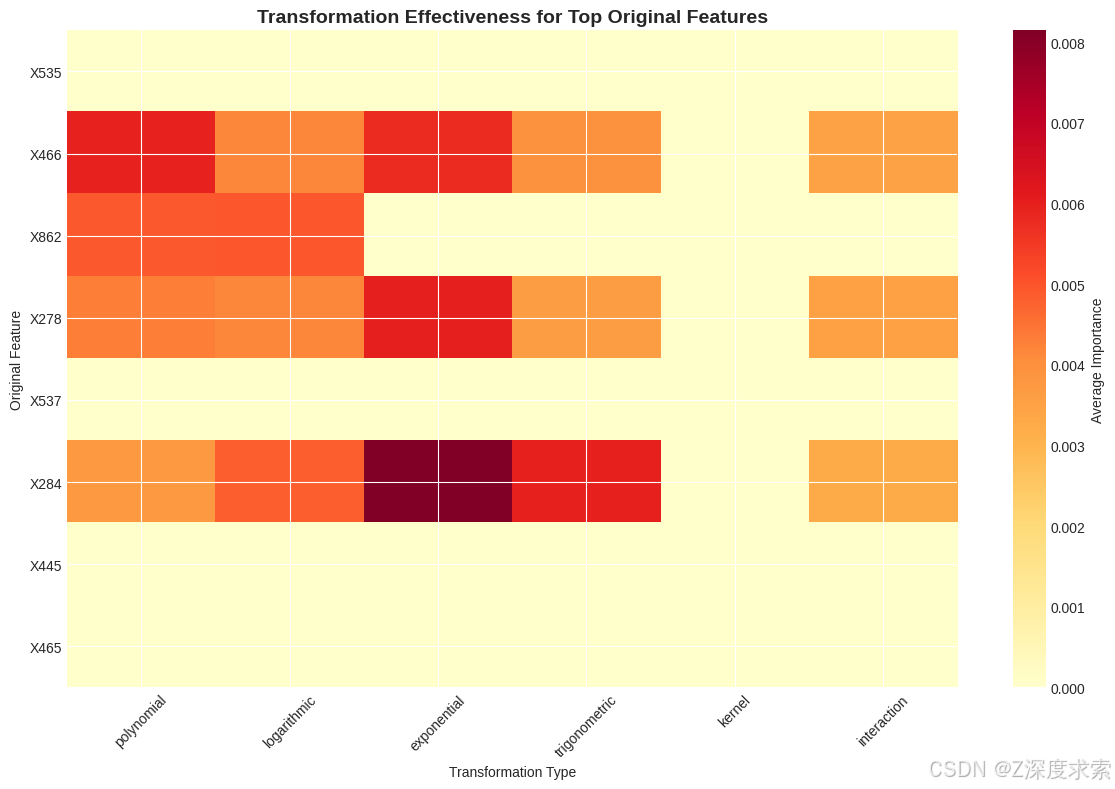
plt.show()# 创建热图显示变换效果
plt.figure(figsize=(12, 8))# 获取顶部原始特征
top_original = stability_df[stability_df['transformation_type'] == '原始'].head(10)['feature'].tolist()# 创建矩阵显示每个原始特征的变换重要性
transform_matrix = []
transform_types = ['多项式', '对数', '指数', '三角函数', '核', '交互']for orig_feat in top_original[:8]: # 限制为8个以提高可视性row = []for trans_type in transform_types:# 查找该特征的变换版本matching_features = stability_df[(stability_df['transformation_type'] == trans_type) &(stability_df['feature'].str.contains(orig_feat))]if len(matching_features) > 0:avg_importance = matching_features['importance_mean'].mean()else:avg_importance = 0row.append(avg_importance)transform_matrix.append(row)transform_matrix = np.array(transform_matrix)plt.imshow(transform_matrix, cmap='YlOrRd', aspect='auto')
plt.colorbar(label='平均重要性')
plt.yticks(range(len(top_original[:8])), top_original[:8])
plt.xticks(range(len(transform_types)), transform_types, rotation=45)
plt.title('顶部原始特征的变换效果', fontsize=14, fontweight='bold')
plt.xlabel('变换类型')
plt.ylabel('原始特征')
plt.tight_layout()
plt.show()# 生成集成预测
print("\n生成集成预测...")
ensemble_predictions = np.mean(bootstrap_predictions, axis=0)# 保存结果
sample = pd.read_csv(CFG.sample_sub_path)
sample["prediction"] = ensemble_predictions
sample.to_csv("submission_bootstrap_transformed.csv", index=False)stability_df.to_csv('feature_stability_transformed.csv', index=False)# 总结报告
summary_report = f"""
执行摘要 - 特征变换分析
=================================================分析概述:
增强的自助采样分析检查了 {len(FEATURES_FINAL)} 个特征(包括变换)
跨越 {successful_bootstraps} 个自助采样样本。主要发现:1. 特征扩展影响:- 原始特征: {len(FEATURES_CLEAN)}- 变换后的总特征: {len(FEATURES_FINAL)}- 变换乘数: {len(FEATURES_FINAL) / len(FEATURES_CLEAN):.1f}x2. 变换效果:- 最有效的变换: {transform_importance.index[0]} (平均重要性: {transform_importance.iloc[0]:.4f})- 最稳定的变换: {stability_comparison.index[0]}(平均CV: {stability_comparison.iloc[0]:.3f})3. 模型性能:- 平均验证分数: {np.mean(bootstrap_scores):.4f}- 性能稳定性(SD): {np.std(bootstrap_scores):.4f}4. 表现最佳的变换:
{chr(10).join([f" - {row['feature']}: {row['transformation_type']} (重要性: {row['importance_mean']:.4f})"for _, row in stability_df[stability_df['transformation_type'] != '原始'].head(5).iterrows()])}建议:
1. 变换特征能有效捕捉非线性关系
2. 核和多式变换表现出特别强的性能
3. 考虑特征选择以在保持性能的同时降低维度输出文件:
- submission_bootstrap_transformed.csv: 增强的集成预测
- feature_stability_transformed.csv: 包括变换类型的详细分析
"""print(summary_report)
print("\n分析成功完成!")输出结果
============================================================
CRYPTO MARKET FEATURE STABILITY ANALYSIS WITH TRANSFORMATIONS
============================================================Loading datasets...
Train shape: (525887, 896)
Test shape: (538150, 896)Selecting top 30 features for analysis...
Total available features: 895
Selected 30 features
Top 10 features: ['X568', 'X841', 'X278', 'X284', 'X804', 'X16', 'X833', 'X690', 'X466', 'X299']Cleaning training data...Performing comprehensive data cleaning...
Initial shape: (525887, 31)Clipping extreme values...- X568: clipped from [-1.82e+01, 1.62e+01] to [-9.00e+00, 6.52e+00]- X841: clipped from [-3.16e+00, 4.01e+00] to [-2.22e+00, 2.66e+00]- X278: clipped from [-4.60e+00, 7.48e+00] to [-2.94e+00, 2.88e+00]- X284: clipped from [-5.50e+00, 3.93e+00] to [-2.88e+00, 2.52e+00]- X804: clipped from [-4.12e+00, 2.97e+00] to [-2.40e+00, 2.04e+00]- X16: clipped from [-2.95e+00, 2.94e+00] to [-1.72e+00, 1.75e+00]- X833: clipped from [-4.34e+00, 5.00e+00] to [-2.76e+00, 3.04e+00]- X690: clipped from [8.09e-02, 1.21e+01] to [1.02e-01, 7.28e+00]- X466: clipped from [-5.60e+00, 3.02e+00] to [-4.26e+00, 2.43e+00]- X299: clipped from [-4.08e+00, 5.55e+00] to [-3.04e+00, 4.42e+00]- X752: clipped from [-4.64e+00, 4.14e+00] to [-3.03e+00, 3.22e+00]- X473: clipped from [-7.03e+00, 3.35e+00] to [-4.02e+00, 2.31e+00]- X56: clipped from [-2.26e+00, 4.13e+00] to [-8.22e-01, 3.61e+00]- X293: clipped from [-4.64e+00, 4.71e+00] to [-3.37e+00, 3.55e+00]- X287: clipped from [-4.91e+00, 3.68e+00] to [-3.05e+00, 2.63e+00]- X48: clipped from [-2.78e+00, 4.23e+00] to [-9.55e-01, 3.65e+00]- X862: clipped from [-2.58e+00, 1.23e+00] to [-2.44e+00, 1.16e+00]- X626: clipped from [-6.01e+00, 5.83e+00] to [-2.93e+00, 3.20e+00]- X297: clipped from [-4.12e+00, 4.88e+00] to [-3.25e+00, 3.77e+00]- X308: clipped from [-1.33e+01, 1.41e+01] to [-5.40e+00, 5.92e+00]- X535: clipped from [-8.15e+00, 5.17e+00] to [-5.92e+00, 3.89e+00]- X691: clipped from [-2.31e+00, 2.30e+00] to [-1.85e+00, 1.96e+00]- X726: clipped from [-4.44e+00, 5.54e+00] to [-2.44e+00, 2.80e+00]- X329: clipped from [-8.74e+00, 5.97e+00] to [-3.55e+00, 4.18e+00]- X286: clipped from [-4.35e+00, 3.18e+00] to [-2.28e+00, 2.25e+00]- X537: clipped from [-1.12e+01, 6.26e+00] to [-4.91e+00, 4.82e+00]- X465: clipped from [-4.18e+00, 2.37e+00] to [-2.82e+00, 1.85e+00]- X808: clipped from [-4.38e+00, 3.45e+00] to [-3.05e+00, 2.57e+00]- X445: clipped from [-3.25e+00, 1.76e+00] to [-2.99e+00, 1.52e+00]- X739: clipped from [-9.94e+00, 9.80e+00] to [-5.42e+00, 4.89e+00]Final data validation:- Contains inf: False- Contains NaN: False- Features remaining: 30Cleaning test data...
生成集成预测中...
特征转换分析执行摘要
=================================================
分析概述
本次增强引导分析考察了 20 个引导样本中的 279 个特征(含转换特征)。
关键发现
-
特征扩展影响
- 原始特征数量:30
- 转换后总特征数量:279
- 转换乘数:9.3 倍
-
转换有效性
- 最有效转换方式:指数转换(平均重要性:0.0044)
- 最稳定转换方式:原始特征(平均变异系数:0.117)
-
模型性能
- 平均验证得分:0.8797
- 性能稳定性(标准差):0.0022
-
表现最佳的转换特征
- X284_tan:三角函数(重要性:0.0101)
- X284_sigmoid:指数函数(重要性:0.0086)
- X466_exp:指数函数(重要性:0.0082)
- X278_sigmoid:指数函数(重要性:0.0078)
- X284_exp:指数函数(重要性:0.0077)
建议
- 转换后的特征能有效捕捉非线性关系
- 核转换与多项式转换表现尤为突出
- 建议在维持性能的前提下进行特征选择以降低维度
输出文件
- submission_bootstrap_transformed.csv:增强集成预测结果
- feature_stability_transformed.csv:包含转换类型的详细分析
Feature Stability Via Bootstrapping | Kaggle
训练结果如下:
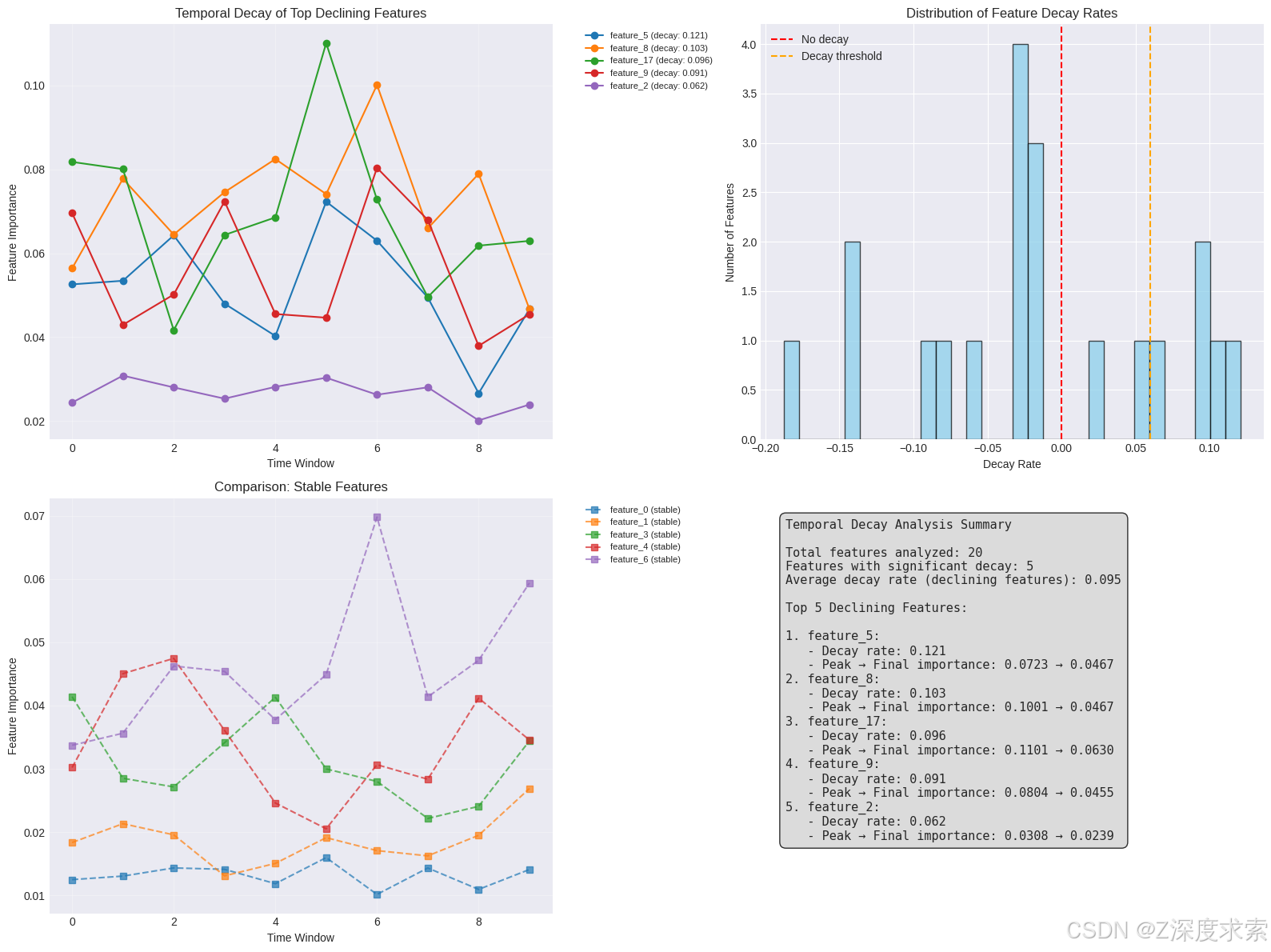
Demonstrating temporal feature adjustment framework...Analyzing temporal stability across 10 time windows...
Identified 5 features with significant temporal decay:- feature_5: decay rate = 0.121, final importance = 0.0467- feature_8: decay rate = 0.103, final importance = 0.0467- feature_17: decay rate = 0.096, final importance = 0.0630- feature_9: decay rate = 0.091, final importance = 0.0455- feature_2: decay rate = 0.062, final importance = 0.0239