Python 训练营打卡 Day 32-官方文档的阅读
我们已经掌握了相当多的机器学习和python基础知识,现在面对一个全新的官方库,看看是否可以借助官方文档的写法了解其如何使用
我们以pdpbox这个机器学习解释性库来介绍如何使用官方文档
以鸢尾花三分类项目来演示如何查看官方文档
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier# 加载鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target # 添加目标列(0-2类:山鸢尾、杂色鸢尾、维吉尼亚鸢尾)# 特征与目标变量
features = iris.feature_names # 4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
target = 'target' # 目标列名# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=42
)# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)训练完成后,选择pdpbox库的info_plots模块下的InteractTargetPlot进行解释性分析
import pdpbox
from pdpbox.info_plots import PredictPlot# 选择待分析的特征
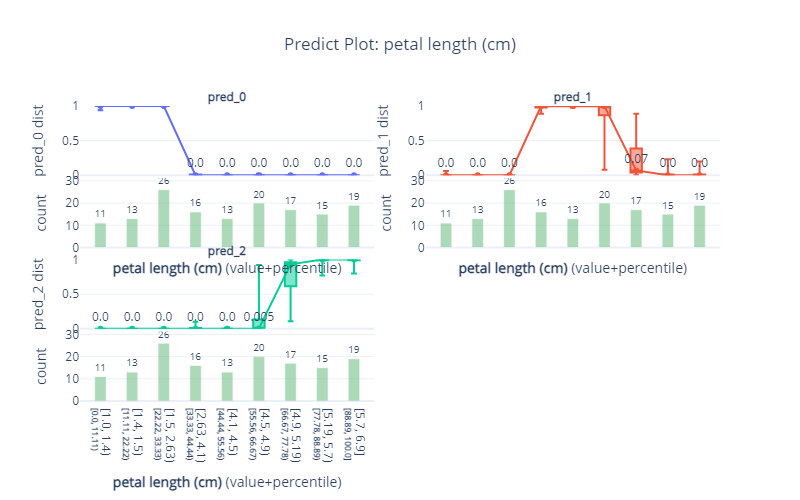
feature = 'petal length (cm)'
feature_name = feature # 特征显示名称# 初始化PredictPlot对象
predict_plot = PredictPlot(df=df, # 原始数据(需包含特征和预测结果列)feature=feature, # 目标特征列feature_name=feature_name, # 特征名称(用于绘图标签)model=model, # 需要传入训练好的模型对象model_features=features , # 需要传入模型使用的特征列表grid_type='percentile', # 分桶方式:百分位num_grid_points=10 # 划分为10个桶
)
fig, axes, summary_df = predict_plot.plot(which_classes=None, # 绘制所有类别show_percentile=True, # 显示百分位线engine='plotly',template='plotly_white'
)# 手动设置图表尺寸和标题
fig.update_layout(width=800,height=500,title=dict(text=f'Predict Plot: {feature_name}', x=0.5) # 修改标题为Predict Plot
)fig.show()
@浙大疏锦行