π0论文阅读
https://www.physicalintelligence.company/download/pi0.pdf
模型输出的token,接diffusion模型,相比自OpenVLA那样的回归模型解码出action,输出更快,精度也会更高。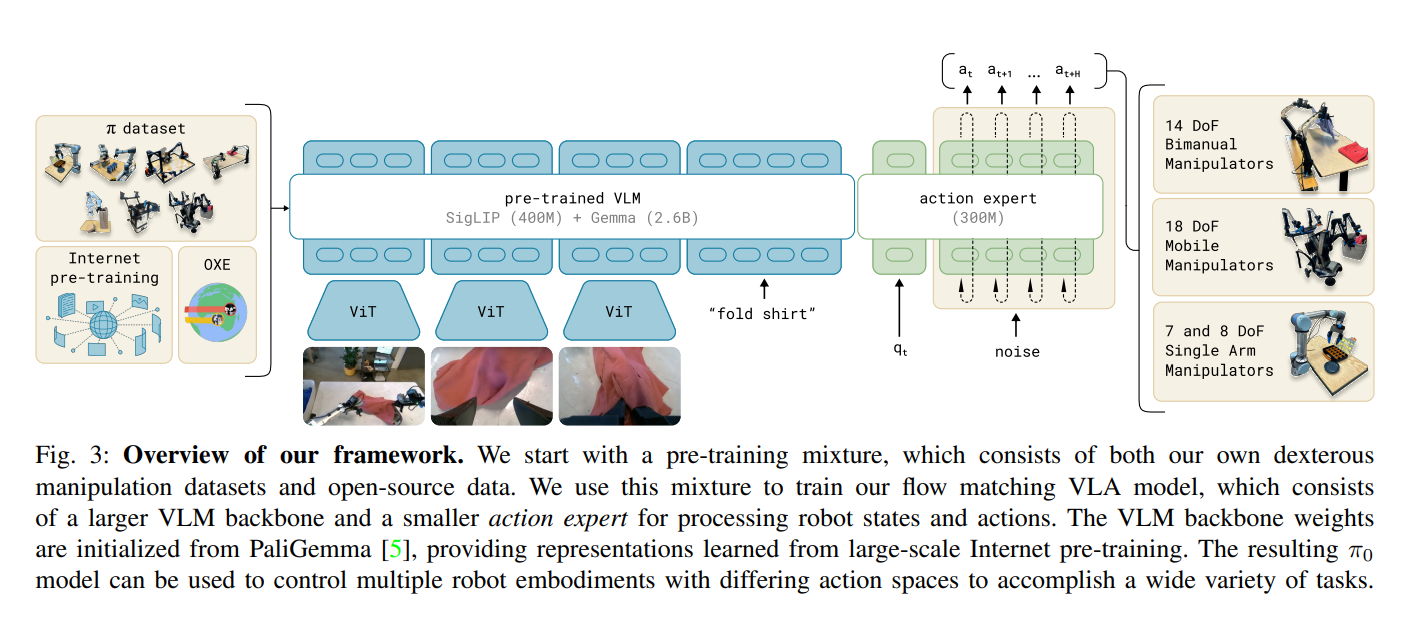
一、动作专家模块与流匹配(Flow Matching)详解
1. 动作专家模块(Action Expert)
- 定位:π₀模型的核心组件,负责将视觉-语言模型(VLM)的语义理解能力与机器人动作生成结合。
- 输入:多模态观测 ( o_t = [I_t, \ell_t, q_t] ),包括图像 ( I_t )、语言指令 ( \ell_t )、机器人本体状态(关节角度 ( q_t ))。
- 架构:
- VLM主干:基于预训练VLM(如PaliGemma),处理图像和语言输入,继承互联网级语义知识。
- 专家模块:独立于VLM的参数,专门处理机器人动作相关输入输出,包括状态 ( q_t ) 和动作序列 ( A_t )。
- 目标:将离散的语言/视觉语义映射为连续的机器人动作,支持高频(最高50Hz)精细操作(如衣物折叠、组装盒子)。
2. 流匹配(Flow Matching)技术
- 核心思想:通过建模连续动作分布,替代传统自回归离散化,直接生成未来一段时间内的动作序列(动作块 ( A_t ),含未来50步动作)。
- 数学建模:
- 条件分布:建模 ( p(A_t | o_t) ),其中 ( A_t = [a_t, a_{t+1}, …, a_{t+H-1}] )(( H=50 ) 为动作块长度)。
- 流匹配损失:通过噪声扰动和去噪过程学习动作分布,损失函数为:
[
L^\tau(\theta) = \mathbb{E}\left| v_\theta(A_t^\tau, o_t) - u(A_t^\tau | A_t) \right|^2
]
其中 ( A_t^\tau = \tau A_t + (1-\tau)\epsilon ) 为噪声动作((\tau) 为时间步,(\epsilon \sim \mathcal{N}(0, I)) 为高斯噪声),( v_\theta ) 是模型预测的去噪向量场,( u ) 是真实去噪目标(( u = \epsilon - A_t ))。
- 训练与推理:
- 训练阶段:采样不同 (\tau) 生成噪声动作,训练模型预测去噪向量 ( v_\theta ),使噪声动作逐步逼近真实动作。
- 推理阶段:从随机噪声 ( A_t^0 \sim \mathcal{N}(0, I) ) 开始,通过欧拉积分逐步积分去噪向量场,生成最终动作序列:
[
A_t^{\tau+\delta} = A_t^\tau + \delta \cdot v_\theta(A_t^\tau, o_t)
]
3. 关键优势
- 连续动作生成:直接输出连续动作分布,避免自回归离散化的量化误差,适合高频精细控制(如衣物折叠时的关节角度微调)。
- 多模态建模:支持不同机器人配置(单臂、双臂、移动机械臂),通过零填充统一动作空间维度,实现跨实体训练。
- 鲁棒性:噪声扰动训练使模型对初始状态偏差和环境噪声更鲁棒,适合真实场景中的错误恢复(如物体位置偏移时的自适应调整)。
二、传统自回归离散化(Autoregressive Discretization)对比
1. 核心原理
- 离散化处理:将连续动作(如关节角度、末端坐标)转换为离散 tokens(类似文本分词),例如将动作空间划分为1000个离散类别。
- 自回归生成:按时间步逐个预测动作 token,依赖前一步动作作为输入,如:
# 伪代码:自回归动作生成 for t in 0 to T:obs = get_observation()action_token = model.predict(obs, prev_action_token)execute(action_token)prev_action_token = action_token - 典型应用:早期视觉-语言-动作模型(如OpenVLA),用于低频任务(如物体抓取,控制频率≤10Hz)。
2. 局限性
- 量化误差:离散化丢失动作细节,难以处理精细操作(如衣物折叠时的布料捏合力度控制)。
- 低频控制:自回归逐步预测效率低,无法支持高频动作生成(如50Hz时需每秒预测50步,自回归延迟显著)。
- 跨模态不匹配:文本token与连续动作的语义映射存在鸿沟,需复杂映射层,增加训练难度。
三、流匹配代码示例(简化版)
1. 训练阶段:流匹配损失计算
import torch
import torch.nn as nnclass ActionExpert(nn.Module):def __init__(self, vlm_backbone, action_dim, hidden_dim):super().__init__()self.vlm = vlm_backbone # 预训练VLM主干self.state_encoder = nn.Linear(robot_state_dim, hidden_dim) # 本体状态编码器self.action_head = nn.Linear(hidden_dim, action_dim) # 动作预测头def forward(self, images, language_tokens, robot_state, noisy_actions, tau):# 1. VLM处理图像和语言vlm_output = self.vlm(images, language_tokens)# 2. 编码本体状态state_emb = self.state_encoder(robot_state)# 3. 拼接VLM输出、状态嵌入和噪声动作concat_input = torch.cat([vlm_output, state_emb, noisy_actions], dim=-1)# 4. 预测去噪向量场denoising_vector = self.action_head(concat_input)return denoising_vector# 流匹配损失函数
def flow_matching_loss(model, images, language_tokens, robot_state, true_actions, tau_distribution):B, H, action_dim = true_actions.shape # B=批量大小,H=动作块长度tau = tau_distribution.sample((B, 1, 1)) # 采样时间步noise = torch.randn_like(true_actions)noisy_actions = tau * true_actions + (1 - tau) * noise # 生成噪声动作pred_denoising = model(images, language_tokens, robot_state, noisy_actions, tau)target_denoising = noise - true_actions # 真实去噪目标loss = nn.MSELoss()(pred_denoising, target_denoising)return loss
2. 推理阶段:动作序列生成(欧拉积分)
def generate_actions(model, images, language_tokens, robot_state, num_steps=10):action_dim = 18 # 最大动作空间维度(如双臂+移动底座)# 初始化噪声动作current_action = torch.randn(1, 50, action_dim) # 生成未来50步的噪声动作for step in range(num_steps):tau = (step + 1) / num_steps # 线性递增时间步pred_denoising = model(images, language_tokens, robot_state, current_action, tau)current_action += 0.1 * pred_denoising # 欧拉积分(δ=0.1)# 提取当前时间步的第一个动作(后续动作用于未来预测)return current_action[0, 0, :] # 返回下一个时间步的动作
四、核心对比总结
| 特性 | 流匹配(Flow Matching) | 传统自回归离散化 |
|---|---|---|
| 动作表示 | 连续分布(直接生成关节角度等) | 离散token(需量化映射) |
| 控制频率 | 支持高频(50Hz) | 低频(≤10Hz) |
| 精细操作能力 | 优(无量化误差) | 差(依赖离散化粒度) |
| 跨实体兼容性 | 优(零填充统一动作空间) | 差(需为每个机器人定制) |
| 训练数据效率 | 高(利用噪声增强鲁棒性) | 低(需大量离散标签) |
五、论文原文支撑
- 流匹配公式:论文Section IV.B,公式 ( L^\tau(\theta) ) 和欧拉积分步骤。
- 跨实体训练:Section V.C,7种机器人配置通过零填充统一动作维度(如18DoF)。
- 高频控制:Section VI.A,衬衫折叠等任务验证50Hz控制下的高精度(成功率近100%)。
通过动作专家模块与流匹配的结合,π₀模型突破了传统自回归方法的局限,为复杂灵巧操作提供了高效的连续动作生成方案,是实现通用机器人控制的关键技术创新。