正则表达式笔记
正则表达式笔记
- 前言
- 一、基本字符匹配
- 二、字符类
- 三、量词
- 四、定位符
- 五、贪婪匹配和非贪婪匹配
- 六、旗标
- 七、分组和引用
- 八、前瞻
- 九、后顾
前言
参考GeekHour视频和资料,讲的挺好的,B站有[GeekHour正则表达式]
正则表达式在线工具网站:https://regexr.com
一、基本字符匹配

补充:
①‘ . ’代表换行符外的任意单个字符,如果我们要匹配‘ . ’本身,需要转义符‘ \ ’,’ . '就代表 ‘ . ’本身。
②[ ] 方括号:其中有且仅有一个满足即可,等价于( | )
③[ ] 中无需转义符转移。
二、字符类

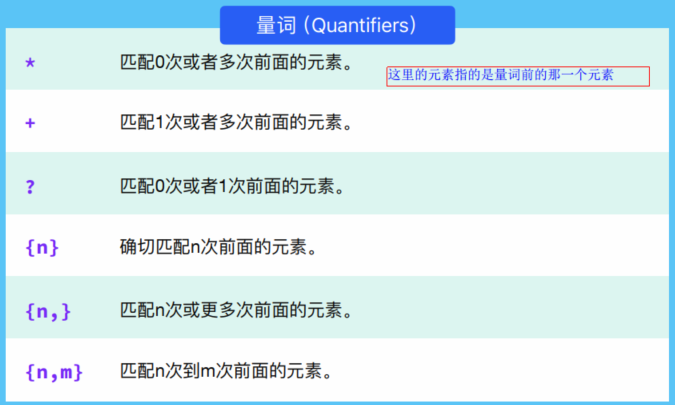
三、量词
四、定位符
补充:
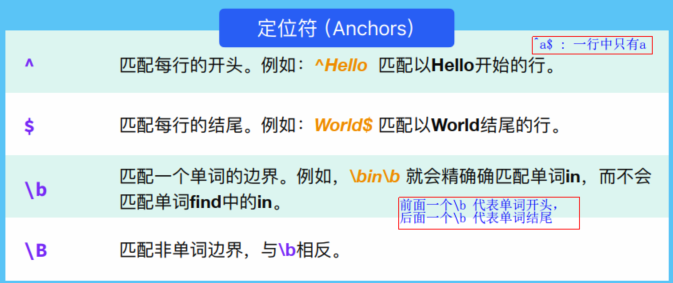
①^at$ : 代表这一行的开头和结尾之间只有一个at。
②^at|at$ :以at开头,以at结尾。②包括①。
③\bin :代表以in开头的单词。
④in\b : 代表以in结尾的单词。
⑤\bin\b :代表 in 这个单词。
五、贪婪匹配和非贪婪匹配

六、旗标

补充:
①正则表达式格式:/具体内容/flags
七、分组和引用

补充:
①分组是分组,捕获是捕获,只有分组后才能捕获,使用捕获后可以进行引用。
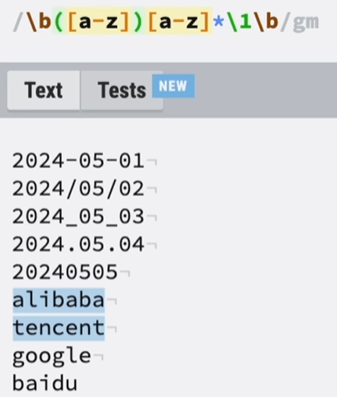
②多日期格式匹配:
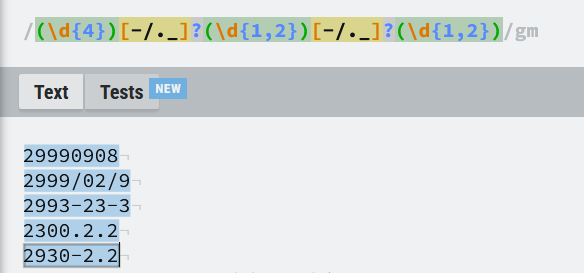
③捕获引用:\b……\b 代表以完整单词为单位。
八、前瞻

补充:
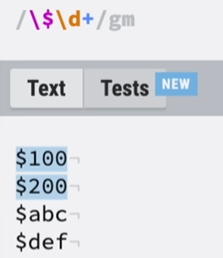
①正向前瞻:整个字符匹配成功($数字),但只需要前面的一部分($)。
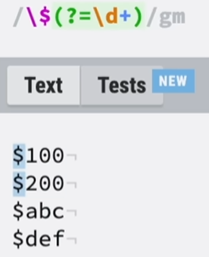
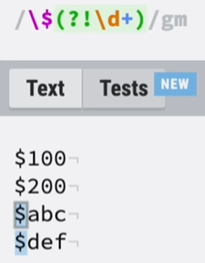
②负向前瞻:前面部分匹配($),后面部分不匹配(\d+),且只需要前面的部分。
九、后顾

补充:
①正向后顾:整个字符匹配成功($数字),但只需要后面的一部分(数字)。
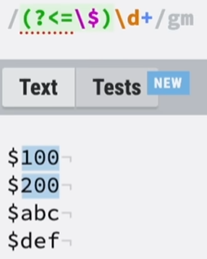
②负向后顾:前面部分不匹配($),后面部分匹配(\d+),且只要后面部分
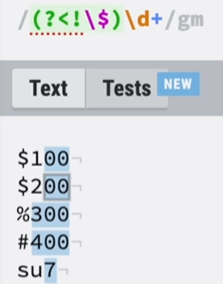
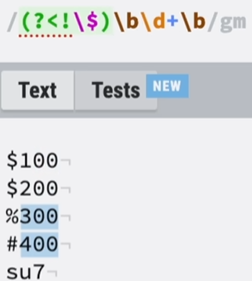
(?<!\$)\b\d+\b : 可以理解为 (?<!\$)、\b\d+\b
(?<!\$) :以非$ 的符号,这里字母不行,所以su7没有被选中。
\b\d+\b:数字整体为单位。