启动你的RocketMQ之旅(七)-Store存储原理
前言:
👏作者简介:我是笑霸final。
📝个人主页: 笑霸final的主页2
📕系列专栏:java专栏
📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
🔥如果感觉博主的文章还不错的话,👍点赞👍 + 👀关注👀 + 🤏收藏🤏
上一章节:启动你的RocketMQ之旅(六)-Broker详细——主从复制
目录
- 一、消息存储概要
- 二、commitlog详情
- 2.1 文件结构
- 三、consumequeue
- 3.1 文件结构
- 四、Index 文件结构
- 五、消息接收流程和持久化
- 5.1 创建mappedFile的过程
- 5.2 刷盘操作
- 5.2.1异步刷盘(默认)
- 5.2.2同步刷新
- 六、MMAP内存映射和零拷贝机制
- 七、总结
一、消息存储概要
RocketMQ 是一种分布式消息中间件,它在存储消息时采用了多种类型的文件来确保高效的消息传递和持久化。以下是 RocketMQ 中几种主要的存储文件类型:
-
CommitLog 文件:是 RocketMQ 最核心的存储文件,所有的消息都会被顺序写入到 CommitLog 文件中。每个 Broker 上只有一个 CommitLog 文件在被写入,新的消息总是追加到最后。
-
ConsumeQueue 文件: 引入 ConsumeQueue是为了加快消息的读取过程,它是 CommitLog 的索引文件。ConsumeQueue 按 Topic 和队列(queue)组织,每一个 Topic 的每一个 queue 都对应一个 ConsumeQueue 文件。
-
IndexFile 文件:基于文件的哈希索引机制(IndexFile),用于支持按照消息key进行精确查找,它 通过构建一个哈希表来映射消息的 key 到其在 CommitLog 中的位置,从而实现对消息的快速检索。
-
Checkpoint 文件:用于记录各个文件的刷盘进度,比如 ConsumeQueue 和 IndexFile 的生成进度等,以确保在服务重启后能够正确恢复数据。
他们的对应关系大致如下
● reputFromOffset记录了本次需要拉取的消息在CommitLog中的偏移。
● index索引文件通过key和uniqKey构建索引
● key和uniqKey都在消息的properties中存储

二、commitlog详情
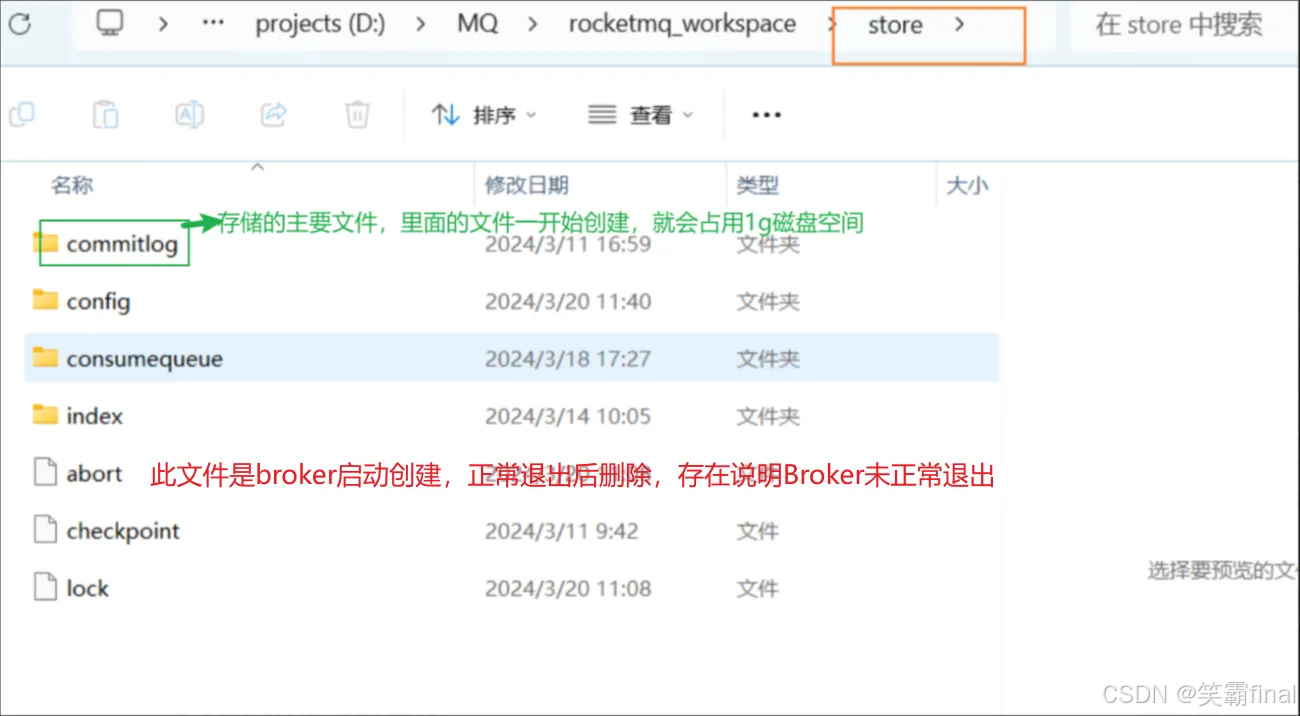
commitlog是RocketMQ用于存储消息的文件. commitlog 具有以下特征:
● commitlog文件默认创建大小为1g,用null占位,满了会自动创建一个新的文件
● 消息存储目录, 文件名当前文件所在的全局偏移量,全局偏移量不一定从00000000000000000000开始。
● 顺序写入,随机读取
● 消息非定长
● 单个CommitLog文件大小默认最大1G, 文件名长度20位,左边补零,剩余为CommitLog中消息的起始偏移量
● 文件的读写采用内存映射技术(MMAP)
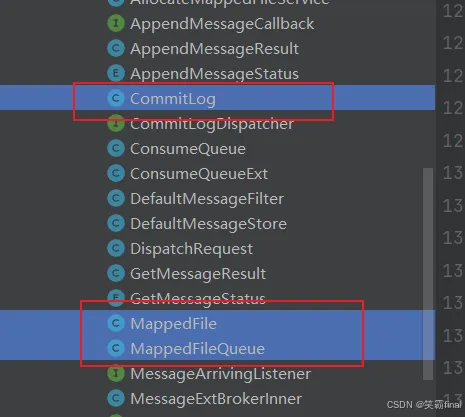
相关类:
- MappedFile :对应的是commitlog文件,比如上面的00000000000000000000文件。
- MappedFileQueue:是MappedFile 所在的文件夹,对 MappedFile 进行封装成文件队列。
- CommitLog:针对 MappedFileQueue 的封装使用。
2.1 文件结构
commitLog文件message格式源码如下:
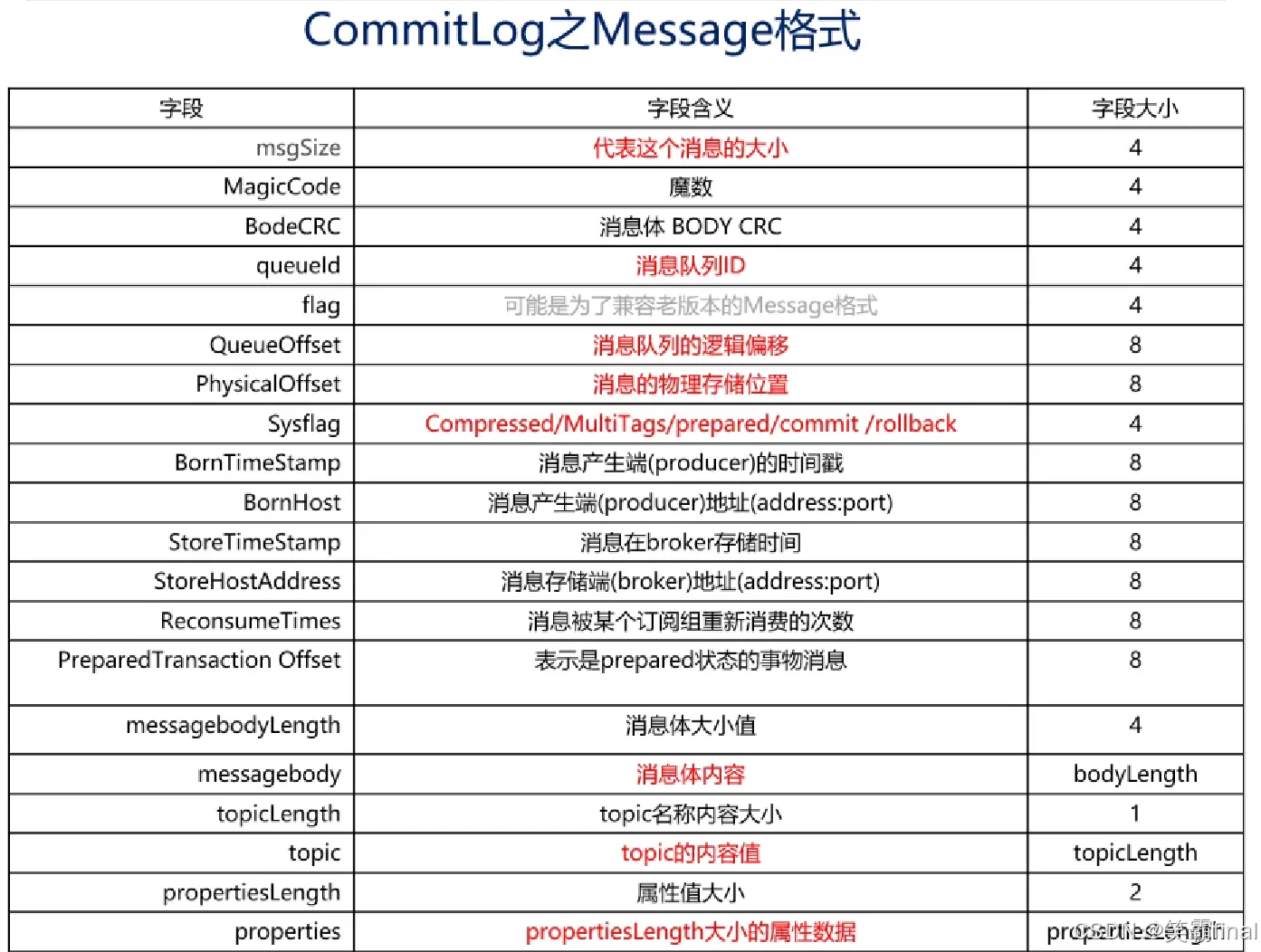
我根据源码总结:总长度:
一个message的大小91字节+
commitLog是由很多message组成,每个message的大小也不一定相等。编码完成后的 byte 数组,就是一条消息在磁盘上的真实物理结构。在MessageExtEncoder#encode中可知一个message结构如下图
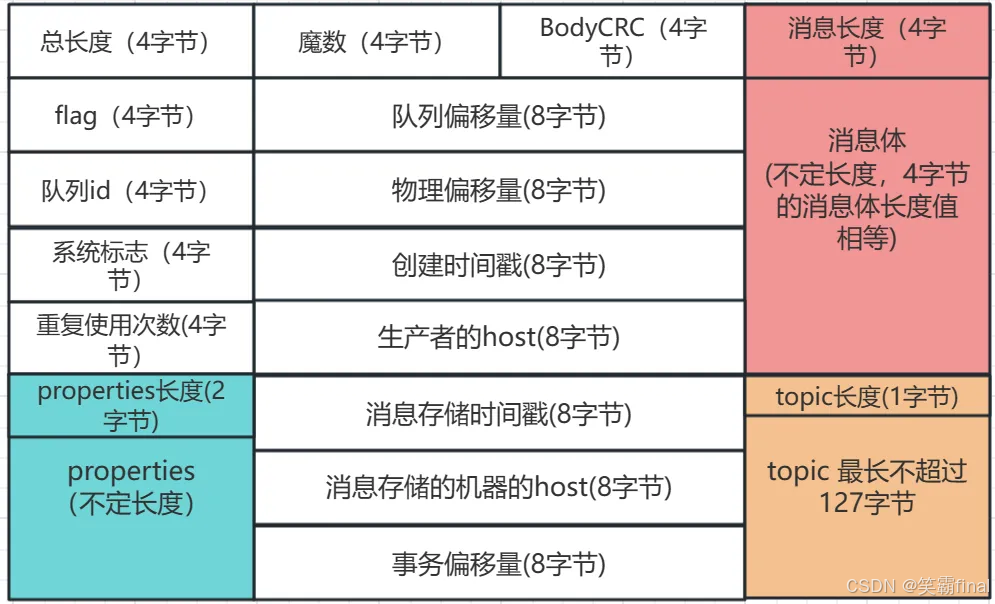
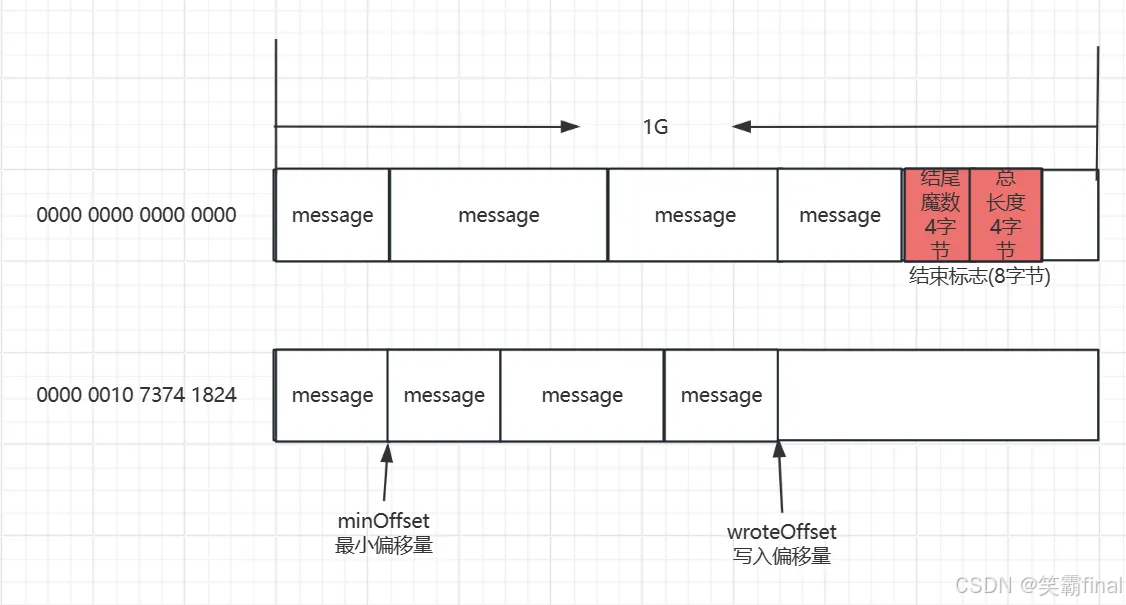
单个CommitLog文件大小默认最大1G, 文件名长度20位,左边补零。commitLog有许多message,结构如下
● minOffset:第一条未被删除的有效消息对应的偏移量作为最小偏移量
● wroteOffset:下次写入的位置
总结:CommitLog 文件管理
- CommitLog 文件默认存放在 $ROCKETMQ_HOME/store/commitlog 目录下。
- 每个 CommitLog 文件大小默认为 1GB(可通过配置调整)。
- 所有 CommitLog 文件组成一个连续的虚拟逻辑空间,通过 commitLogOffset 来定位消息。
- 写入时采用内存映射机制(MappedByteBuffer),提升 I/O 性能。
三、consumequeue
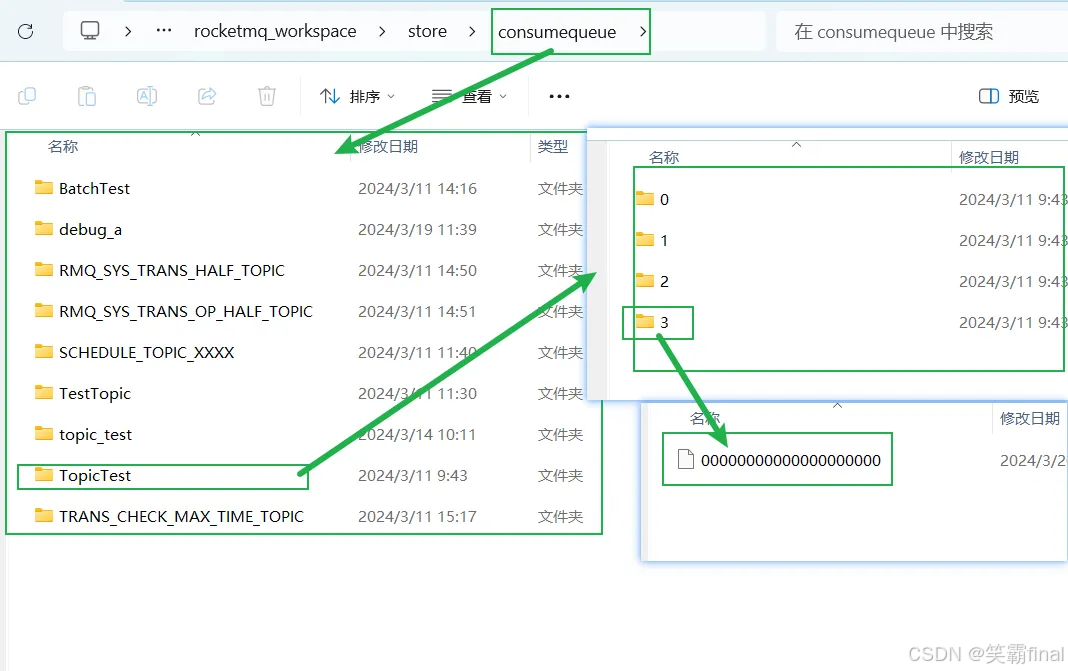
文件夹内是各种topic,topic里面的文件夹代码队列,一个队列里面的文件也是创建就生成5860KB的数据,但是这个文件并不存储消息实体,而是如下结构:
内容包含启始CommitLog offset(物理偏移量占用8字节)、size(消息大小占用4字节)和MessageTag的HashCode(消息Tag的HashCode值占用8字节一个条目大小为 8+4+8=20字节,一个文件大约有30万个条目。
ConsummeQueue是消息的逻辑队列ConsumeQueue的数据信息是消息写入CommitLog后进行构建的。存储MessageQueue的消息在CommitLog中的物理地址(文件偏移量)也可以看成是基于topic的CommitLog索引文件
消息首先会被写入CommitLog(消息存储日志),并且在写入完成后,Broker会根据消息所在的Topic和QueueId,生成对应ConsumerQueue(消费队列)的索引信息。这个索引信息主要是消息在CommitLog中的物理偏移量和其它一些必要的元数据。
当消息成功写入CommitLog并完成刷盘后,RocketMQ会启动异步进程将该消息的索引信息写入ConsumerQueue。消息先写入CommitLog并刷盘,然后尽快异步地将索引信息写入ConsumerQueue并刷盘。这两个过程是连续进行的,但并不是同一时刻同步执行的。
(RocketMQ中ConsumeQueue构建的过程主要发生在一个叫做ReputMessageService的后台服务线程中)
3.1 文件结构
ConsumeQueue是逻辑队列,大致如下:
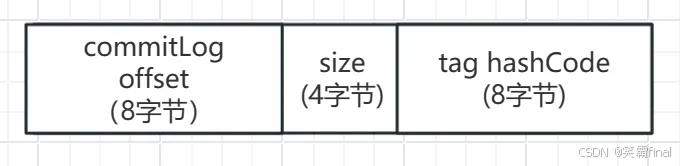
onsumequeue是由很多条目组成,每个条目大小固定,结构如下
● commitLog offset :消息在commitLog中的物理偏移量
● size:消息的总大小
● tag hashCode: 消息Tag的HashCode值
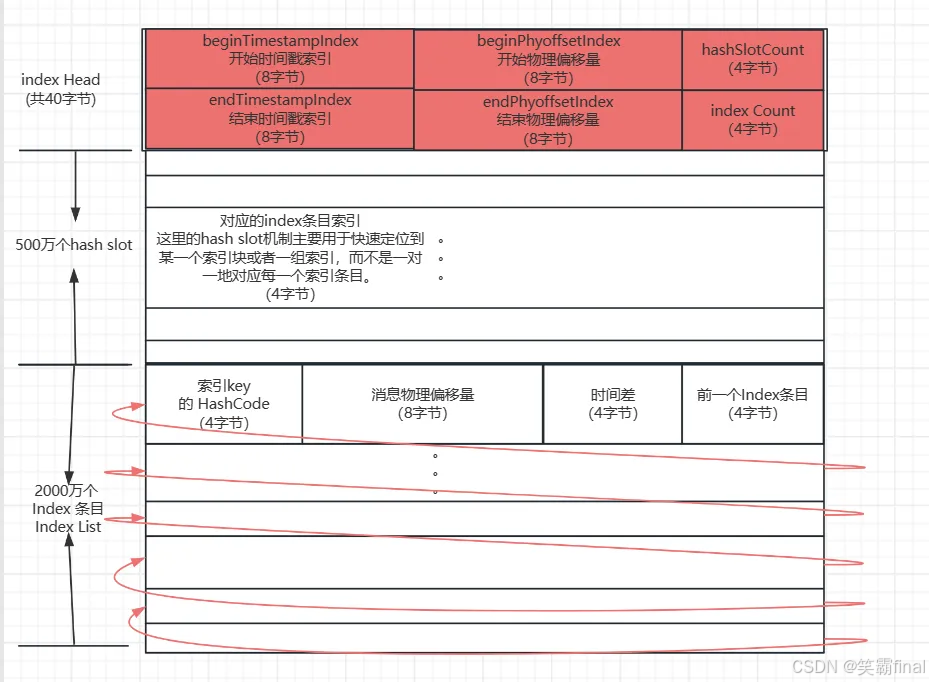
四、Index 文件结构
ndex下目录下的文件是专门为消息订阅设计的索引文件, 通过索引加快检索速度。
RocketMQ引入Hash索引机制,为消息建立索引,它的键就是Message Key 和 Unique Key
RocketMQ 的 IndexFile 是一个固定大小的文件,默认大小为 500MB。
文件头(IndexHeader):共 40 字节,记录元信息哈希槽数组(Hash Slot Table): 默认有 500 万个槽位(slot),每个槽占 4 字节,即占用 20MB(5,000,000 * 4 bytes)索引项数组(Index Item Table):每个索引项占 20 字节结构如下:
五、消息接收流程和持久化
SendMessageProcessor.asyncSendMessage()的源码如下
private CompletableFuture<RemotingCommand> asyncSendMessage(ChannelHandlerContext ctx, RemotingCommand request,SendMessageContext mqtraceContext,SendMessageRequestHeader requestHeader) {// 获取消息体内容 final byte[] body = request.getBody();int queueIdInt = requestHeader.getQueueId();TopicConfig topicConfig = this.brokerController.getTopicConfigManager().selectTopicConfig(requestHeader.getTopic());// 拼凑message对象MessageExtBrokerInner msgInner = new MessageExtBrokerInner();msgInner.setTopic(requestHeader.getTopic()); msgInner.setQueueId(queueIdInt);msgInner.setBody(body);msgInner.setFlag(requestHeader.getFlag());MessageAccessor.setProperties(msgInner, MessageDecoder.string2messageProperties(requestHeader.getProperties()));// 消息扩展属性,例如延迟级别、事务状态msgInner.setPropertiesString(requestHeader.getProperties());// 生产者创建时间戳msgInner.setBornTimestamp(requestHeader.getBornTimestamp());// 发送方 IP 地址msgInner.setBornHost(ctx.channel().remoteAddress());// 当前 Broker 的地址msgInner.setStoreHost(this.getStoreHost());// 被消费者重试消费的次数msgInner.setReconsumeTimes(requestHeader.getReconsumeTimes() == null ? 0 : requestHeader.getReconsumeTimes());CompletableFuture<PutMessageResult> putMessageResult = null;Map<String, String> origProps = MessageDecoder.string2messageProperties(requestHeader.getProperties());// ==========真正接收消息的方法 写入缓冲区================putMessageResult = this.brokerController.getMessageStore().asyncPutMessage(msgInner);return handlePutMessageResultFuture(putMessageResult, response, request, msgInner, responseHeader, mqtraceContext, ctx, queueIdInt);
}
参数说明:
- ctx: Netty 的上下文,用于获取连接信息、发送响应。
- request: 客户端发送过来的完整请求对象(包含 header 和 body)。
- mqtraceContext: 消息轨迹追踪上下文,用于链路追踪(如 OpenTelemetry 集成)。
- requestHeader: 请求头对象,包含 Topic、队列 ID、属性等元数据。
返回值是一个 CompletableFuture 是一个异步非阻塞的消息发送处理方法,最终会构造一个响应命令返回给客户端。
将消息写入 CommitLog(核心操作)
putMessageResult = this.brokerController.getMessageStore().asyncPutMessage(msgInner);源码如下
@Override
public CompletableFuture<PutMessageResult> asyncPutMessage(MessageExtBrokerInner msg) {CompletableFuture<PutMessageResult> putResultFuture = this.commitLog.asyncPutMessage(msg);putResultFuture.thenAccept((result) -> {......});return putResultFuture;
}
接下来his.commitLog.asyncPutMessage(msg);源码如下
/*** 自 4.0.x 开始引入。确定放置消息时是否使用互斥锁* this.putMessageLock = defaultMessageStore.getMessageStoreConfig().isUseReentrantLockWhenPutMessage()* ? new PutMessageReentrantLock() : new PutMessageSpinLock();* 默认是 new PutMessageSpinLock(), ReentrantLock() 非公平锁* PutMessageSpinLock() ,是AtomicBoolean的CAS方法 ,自旋锁* 同步刷盘 建议是使用非公平锁*/putMessageLock.lock(); //spin or ReentrantLock ,depending on store configtry {// 获取最后一个文件,MappedFile就是commitlog目录下的那个0000000000文件MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();long beginLockTimestamp = this.defaultMessageStore.getSystemClock().now();this.beginTimeInLock = beginLockTimestamp;// 这里设置都存储了时间戳,以保证全局有序msg.setStoreTimestamp(beginLockTimestamp);if (null == mappedFile || mappedFile.isFull()) {//兜底操作,mappedFile = this.mappedFileQueue.getLastMappedFile(0); // Mark: NewFile may be cause noise}........其他代码 // 把Broker内部的Message刷新到MappendFile(此时还未刷盘)result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext);........其他代码........其他代码switch (result.getStatus()) {........其他代码case END_OF_FILE: // Message刷新到MappendFile(commitlog)失败 空间不足 创建一个新的commitlogunlockMappedFile = mappedFile;// Create a new file, re-write the messagemappedFile = this.mappedFileQueue.getLastMappedFile(0);if (null == mappedFile) {// XXX: warn and notify melog.error("create mapped file2 error, topic: " + msg.getTopic() + " clientAddr: " + msg.getBornHostString());beginTimeInLock = 0;return CompletableFuture.completedFuture(new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, result));}result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext);break;........其他代码}} finally {putMessageLock.unlock();}// 后面有刷盘操作case END_OF_FILE:大致流程
● 使用非公平锁加锁(可以修改配置为false 就是使用的CAS
● 获取最后一个文件 (如果没有或者MappedFile满 就进行兜底操作 创建一个)
● 在把msg刷新到MappendFile之前 设置msg的时间戳,保证消息全局有序
● 使用appendMessage把Message刷新到MappendFile(此时还未刷盘)
● 如果MappendFile空间不够 则创 建新的MappendFile
● 最后释放锁
● 刷盘操作

对获取最后一个文件,MappedFile就是commitlog目录下的那个0000000000文件的兜底
this.mappedFileQueue.getLastMappedFile(0)最终调用的下面的方法,参数分别是0和true
在尝试获取一个新的MappendFile也就是MappendFile创建的过程,该对象指定了文件的路径和文件的大小,并放入到 requestQueue 队列中。
5.1 创建mappedFile的过程
先看源码
public MappedFile putRequestAndReturnMappedFile(String nextFilePath, String nextNextFilePath, int fileSize) {int canSubmitRequests = 2;// 启用堆外内存池if (this.messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {if (this.messageStore.getMessageStoreConfig().isFastFailIfNoBufferInStorePool()&& BrokerRole.SLAVE != this.messageStore.getMessageStoreConfig().getBrokerRole()) {//if broker is slave, don't fast fail even no buffer in pool//根据堆外内存池数量重新计算可创建CommitLog的数量//如果堆外内存池默认分配了5个,如果当前待创建的CommitLog有4个,// 那么还能创建一个,canSubmitRequests=1canSubmitRequests = this.messageStore.getTransientStorePool().availableBufferNums() - this.requestQueue.size();}}创建下一个文件的AllocateRequest对象AllocateRequest nextReq = new AllocateRequest(nextFilePath, fileSize);//将创建MappedFile的请求放入到requestTable中boolean nextPutOK = this.requestTable.putIfAbsent(nextFilePath, nextReq) == null;if (nextPutOK) {if (canSubmitRequests <= 0) {log.warn("[NOTIFYME]TransientStorePool is not enough, so create mapped file error, " +"RequestQueueSize : {}, StorePoolSize: {}", this.requestQueue.size(), this.messageStore.getTransientStorePool().availableBufferNums());this.requestTable.remove(nextFilePath);return null;}将创建MappedFile的请求放入到阻塞队列中,AllocateMappedFileService线程会从该队列取boolean offerOK = this.requestQueue.offer(nextReq);if (!offerOK) {log.warn("never expected here, add a request to preallocate queue failed");}canSubmitRequests--;}//创建下下个文件的AllocateRequest对象AllocateRequest nextNextReq = new AllocateRequest(nextNextFilePath, fileSize);boolean nextNextPutOK = this.requestTable.putIfAbsent(nextNextFilePath, nextNextReq) == null;if (nextNextPutOK) {if (canSubmitRequests <= 0) {log.warn("[NOTIFYME]TransientStorePool is not enough, so skip preallocate mapped file, " +"RequestQueueSize : {}, StorePoolSize: {}", this.requestQueue.size(), this.messageStore.getTransientStorePool().availableBufferNums());this.requestTable.remove(nextNextFilePath);} else {boolean offerOK = this.requestQueue.offer(nextNextReq);if (!offerOK) {log.warn("never expected here, add a request to preallocate queue failed");}}}if (hasException) {log.warn(this.getServiceName() + " service has exception. so return null");return null;}AllocateRequest result = this.requestTable.get(nextFilePath);try {if (result != null) {//通过CountDownLatch 同步等待 MappedFile 创建完成boolean waitOK = result.getCountDownLatch().await(waitTimeOut, TimeUnit.MILLISECONDS);if (!waitOK) {log.warn("create mmap timeout " + result.getFilePath() + " " + result.getFileSize());return null;} else {this.requestTable.remove(nextFilePath);return result.getMappedFile();}} else {log.error("find preallocate mmap failed, this never happen");}} catch (InterruptedException e) {log.warn(this.getServiceName() + " service has exception. ", e);}return null;}
这个方法负责管理和调度MappedFile的预分配请求,确保在符合系统配置和资源限制的前提下,有序、高效地创建内存映射文件,以供后续的消息存储使用。
会连续创建两个MappedFile创建 CommitLog 的 AllocateRequest 由 AllocateMappedFileService 来执行。在 Broker 启动 MessageStore 组件中,启动了一个 AllocateMappedFileService 服务线程。其 run() 方法中不断的从 requestQueue 队列中获取 AllocateRequest,接着执行MappedFile 映射文件的创建和预分配工作。
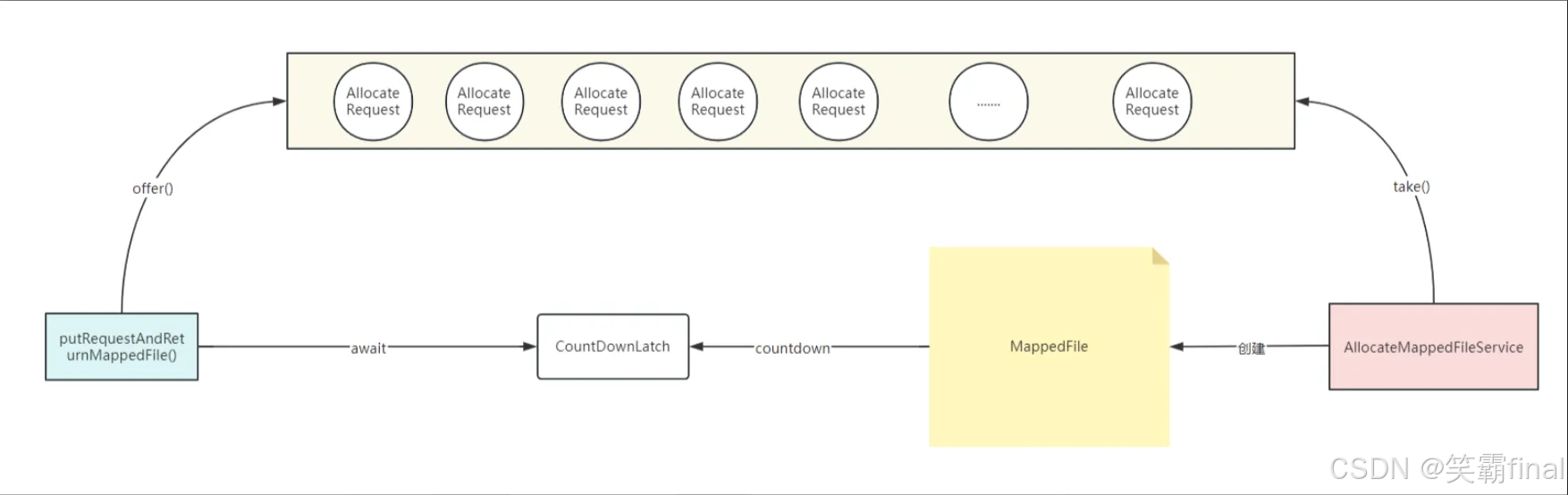
具体的创建过程在 AllocateMappedFileService 的 run() 方法中,该方法中调用了 mmapOperation() 进行创建 MmapedFile:如下代码
private boolean mmapOperation() {boolean isSuccess = false;AllocateRequest req = null;try {//从阻塞队列中获取AllocateRequest对象req = this.requestQueue.take();//从requestTable中获取对应的AllocateRequest对象AllocateRequest expectedRequest = this.requestTable.get(req.getFilePath());if (null == expectedRequest) {log.warn("this mmap request expired, maybe cause timeout " + req.getFilePath() + " "+ req.getFileSize());return true;}//两个 AllocateRequest对象做校验,正常来说是一样的if (expectedRequest != req) {log.warn("never expected here, maybe cause timeout " + req.getFilePath() + " "+ req.getFileSize() + ", req:" + req + ", expectedRequest:" + expectedRequest);return true;}//开始创建MmapedFileif (req.getMappedFile() == null) {long beginTime = System.currentTimeMillis();MappedFile mappedFile;//利用TransientStorePool堆外内存池中获取相应的DirectByteBuffer来构建MappedFileif (messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {try {mappedFile = ServiceLoader.load(MappedFile.class).iterator().next();mappedFile.init(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool());} catch (RuntimeException e) {log.warn("Use default implementation.");mappedFile = new MappedFile(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool());}//使用Mmap的方式来构建MappedFile实例} else {mappedFile = new MappedFile(req.getFilePath(), req.getFileSize());}long elapsedTime = UtilAll.computeElapsedTimeMilliseconds(beginTime);if (elapsedTime > 10) {int queueSize = this.requestQueue.size();log.warn("create mappedFile spent time(ms) " + elapsedTime + " queue size " + queueSize+ " " + req.getFilePath() + " " + req.getFileSize());}// pre write mappedFileif (mappedFile.getFileSize() >= this.messageStore.getMessageStoreConfig().getMappedFileSizeCommitLog()&&this.messageStore.getMessageStoreConfig().isWarmMapedFileEnable()) {//CommitLog文件预热mappedFile.warmMappedFile(this.messageStore.getMessageStoreConfig().getFlushDiskType(),this.messageStore.getMessageStoreConfig().getFlushLeastPagesWhenWarmMapedFile());}//传入创建好的MappedFile到Request对象中req.setMappedFile(mappedFile);this.hasException = false;isSuccess = true;}} catch (InterruptedException e) {//............} catch (IOException e) {//.........} finally {if (req != null && isSuccess)//最后进行countdown操作,说明文件创建完成,唤醒线程进行消息存储req.getCountDownLatch().countDown();}return true;
}
最后我们看到有文件预热这段代码。mappedFile.warmMappedFile(this.messageStore.getMessageStoreConfig().getFlushDiskType(),
this.messageStore.getMessageStoreConfig().getFlushLeastPagesWhenWarmMapedFile());,源码如下
public void warmMappedFile(FlushDiskType type, int pages) {//记录时间long beginTime = System.currentTimeMillis();ByteBuffer byteBuffer = this.mappedByteBuffer.slice();int flush = 0;long time = System.currentTimeMillis();//写入假数据for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) {// 初始化两个计数器变量i和j,i用于遍历内存映射文件的每一个字节位置,// 每次迭代增加MappedFile.OS_PAGE_SIZE(通常是操作系统页大小,如4KB)// j用于统计循环次数。循环条件是i小于文件大小(this.fileSize)//在内存映射文件的i位置写入字节0,即把每个操作系统页的内存初始化为0,预热文件的同时也清理了原有可能存在的数据。byteBuffer.put(i, (byte) 0);// force flush when flush disk type is syncif (type == FlushDiskType.SYNC_FLUSH) { //检查刷盘类型是否为同步刷盘if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) {flush = i;mappedByteBuffer.force();//强制刷盘,确保预热的数据立即写入磁盘,这对于同步刷盘模式至关重要。}}// prevent gc 防止gcif (j % 1000 == 0) {log.info("j={}, costTime={}", j, System.currentTimeMillis() - time);time = System.currentTimeMillis();try {// 虽然表面上看起来没有使线程睡眠,但实际上会触发一次操作系统级别的上下文切换,// 这有助于缓解GC压力,防止长时间内CPU过度集中于当前线程而导致GC问题。Thread.sleep(0);} catch (InterruptedException e) {log.error("Interrupted", e);}}}// force flush when prepare load finishedif (type == FlushDiskType.SYNC_FLUSH) {log.info("mapped file warm-up done, force to disk, mappedFile={}, costTime={}",this.getFileName(), System.currentTimeMillis() - beginTime);mappedByteBuffer.force();}log.info("mapped file warm-up done. mappedFile={}, costTime={}", this.getFileName(),System.currentTimeMillis() - beginTime);//预热完后将分配到的物理内存锁死,防止被回收//底层调用C语言代码this.mlock();}
文件预热:创建完 MappedFile 后,还进行了消息预热的操作。消息预热有什么用呢?首先我们要明白,我们通过 MappedByteBuffer 将一个磁盘文件映射到内存时,其实并没有马上将磁盘文件的数据读到物理内存中,只是分配了一个虚拟的内存地址。当真正将数据 读取/写入 Buffer 时,会发生缺页,此时才会从磁盘文件读取数据加载到物理内存中,并将虚拟内存地址和物理内存地址作映射。
预热的作用就是提前进行这一过程,防止当真正写入消息时发生缺页,触发内存的分配和映射。
5.2 刷盘操作
刷盘大致如下流程
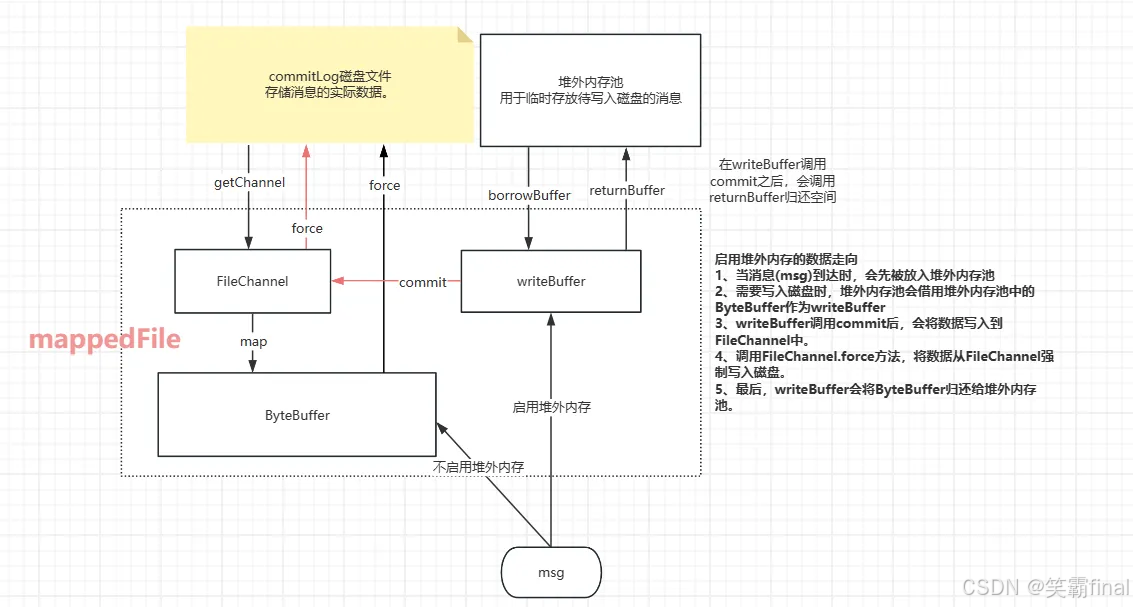
回到org.apache.rocketmq.store.CommitLog.asyncPutMessage(msg) 关注刷盘操作
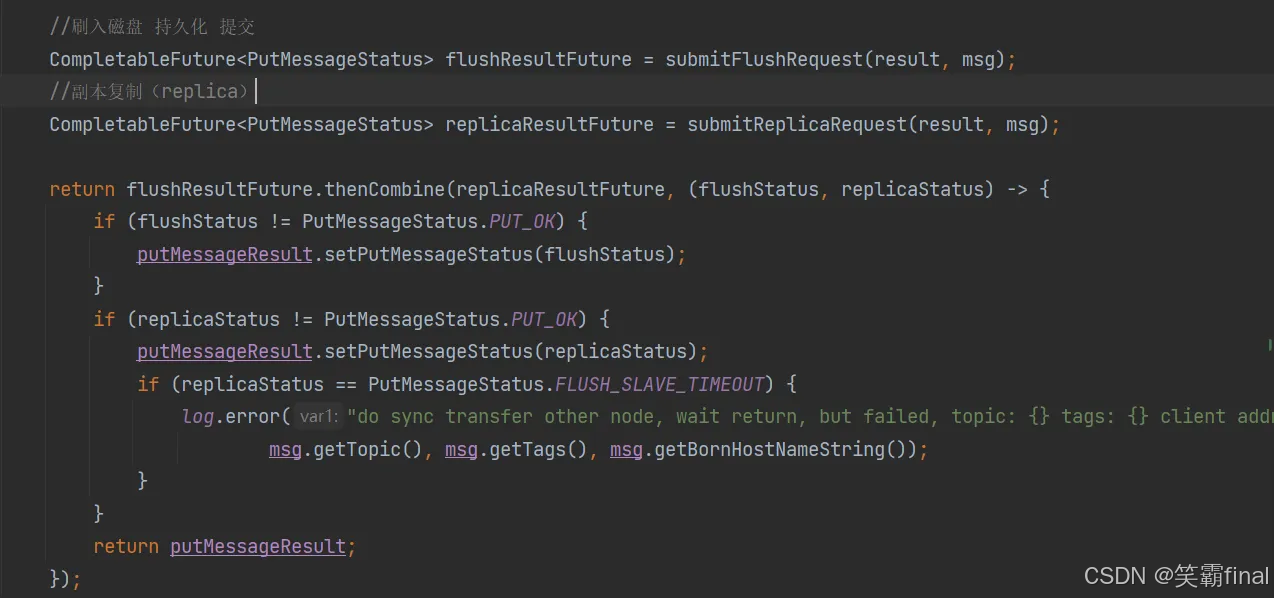
进入 submitFlushRequest()方法
public CompletableFuture<PutMessageStatus> submitFlushRequest(AppendMessageResult result, MessageExt messageExt) {// Synchronization flush 同步刷盘if (FlushDiskType.SYNC_FLUSH == this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {// 默认不走这 走异步刷盘final GroupCommitService service = (GroupCommitService) this.flushCommitLogService;if (messageExt.isWaitStoreMsgOK()) {GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes(),this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());service.putRequest(request);return request.future();} else {service.wakeup();return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);}}// Asynchronous flush 异步刷盘else {//涉及两种存储模式的选择以及唤醒相应的服务进行消息的刷盘操作。//(是否启用了瞬时存储池功能。如果禁用了瞬时存储池 返回false)if (!this.defaultMessageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {// 仅当 transientStorePoolEnable 为 true 且 FlushDiskType 为 ASYNC_FLUSH 时,才启用暂时性 commitLog 存储池// 默认会进入这里 禁用了瞬时存储池flushCommitLogService.wakeup();} else {//启用了瞬时存储池commitLogService.wakeup();}return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);}}
5.2.1异步刷盘(默认)
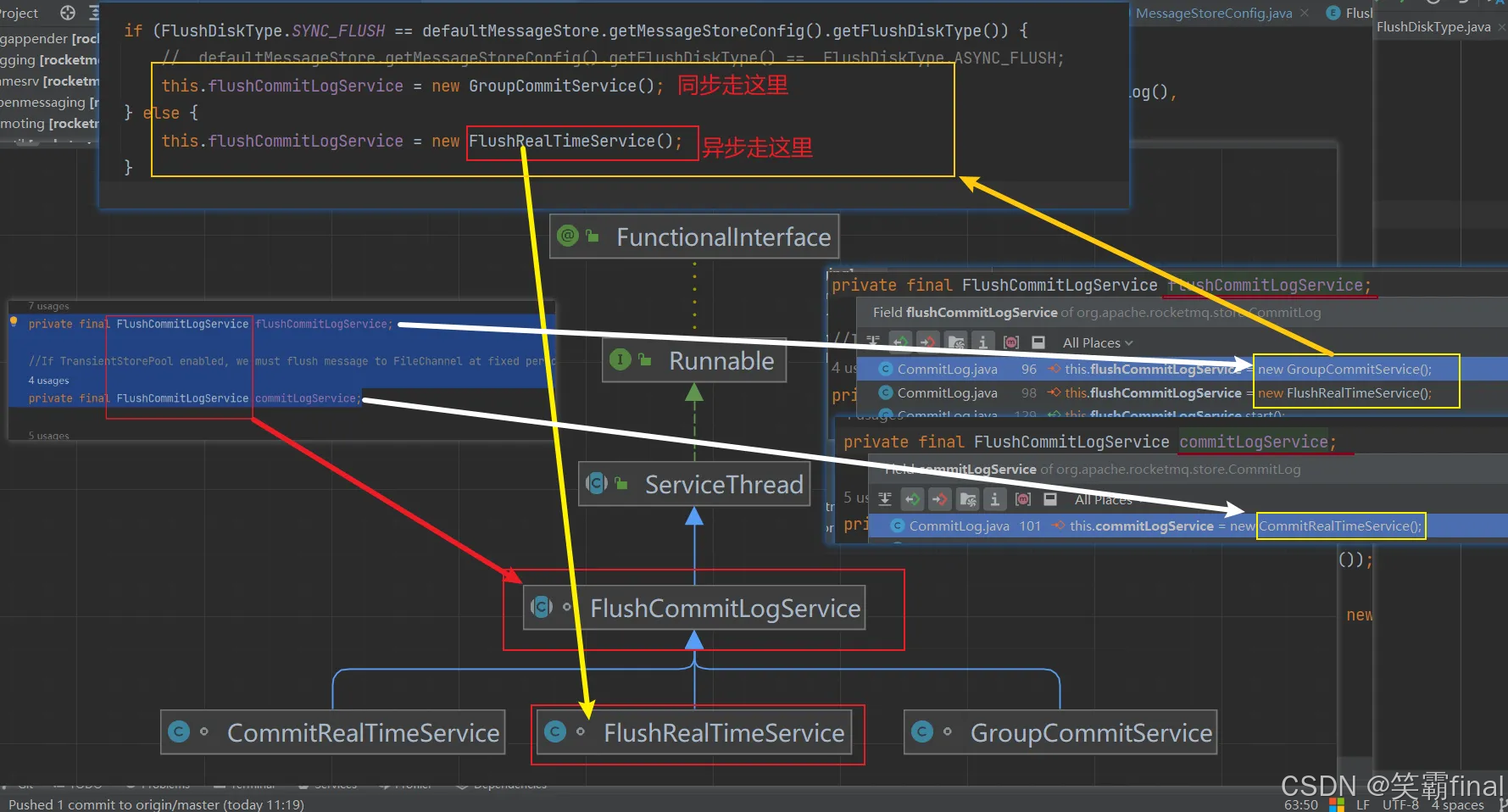
异步刷盘分为两种:如果使用堆外内存来构建 MappedFile,就需要先将堆外内存写入到文件映射中再存盘,并由 CommitRealTimeService 服务线程负责刷盘;如果直接使用MappedByteBuffer 来构建 MmapedFile,则由 FlushRealTimeService 进行刷盘
在 Broker 启动过程中启动上述服务线程

接着 看看 FlushRealTimeService的run 方法,源码如下
public void run() {CommitLog.log.info(this.getServiceName() + " service started");while (!this.isStopped()) {// true 启用计划刷新boolean flushCommitLogTimed = CommitLog.this.defaultMessageStore.getMessageStoreConfig().isFlushCommitLogTimed();//刷新间隔 500int interval = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushIntervalCommitLog();// 刷新commitlog时 刷新4页int flushPhysicQueueLeastPages = CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushCommitLogLeastPages();// 1000 * 10 彻底刷盘(flush)物理队列的时间间隔; 每隔 10s 彻底地将内存中的CommitLog数据全部刷入磁盘int flushPhysicQueueThoroughInterval =CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushCommitLogThoroughInterval();boolean printFlushProgress = false;// Print flush progress ==== 打印刷新进度long currentTimeMillis = System.currentTimeMillis();if (currentTimeMillis >= (this.lastFlushTimestamp + flushPhysicQueueThoroughInterval)) {this.lastFlushTimestamp = currentTimeMillis;flushPhysicQueueLeastPages = 0;printFlushProgress = (printTimes++ % 10) == 0;}try {if (flushCommitLogTimed) { //true// Thread.sleep(500);Thread.sleep(interval);} else {this.waitForRunning(interval);}if (printFlushProgress) {//falsethis.printFlushProgress();}long begin = System.currentTimeMillis();// 调用mappedFileQueue的flush方法 CommitLog.this.mappedFileQueue.flush(flushPhysicQueueLeastPages);long storeTimestamp = CommitLog.this.mappedFileQueue.getStoreTimestamp();if (storeTimestamp > 0) {CommitLog.this.defaultMessageStore.getStoreCheckpoint().setPhysicMsgTimestamp(storeTimestamp);}long past = System.currentTimeMillis() - begin;if (past > 500) {log.info("Flush data to disk costs {} ms", past);}} catch (Throwable e) {CommitLog.log.warn(this.getServiceName() + " service has exception. ", e);this.printFlushProgress();}}// Normal shutdown, to ensure that all the flush before exitboolean result = false;for (int i = 0; i < RETRY_TIMES_OVER && !result; i++) {result = CommitLog.this.mappedFileQueue.flush(0);CommitLog.log.info(this.getServiceName() + " service shutdown, retry " + (i + 1) + " times " + (result ? "OK" : "Not OK"));}this.printFlushProgress();CommitLog.log.info(this.getServiceName() + " service end");}
每隔500ms刷盘 执行CommitLog.this.mappedFileQueue.flush()刷盘
如果是选择固定周期来执行刷盘,会根据配置设置固定间隔 interval(默认是 500ms),服务线程会 sleep() 固定时间再去刷盘。可以看出,如果在这段时间内,服务器出现宕机,那么就会导致这段时间内的数据丢失
接着看mappedFileQueue.flush()方法
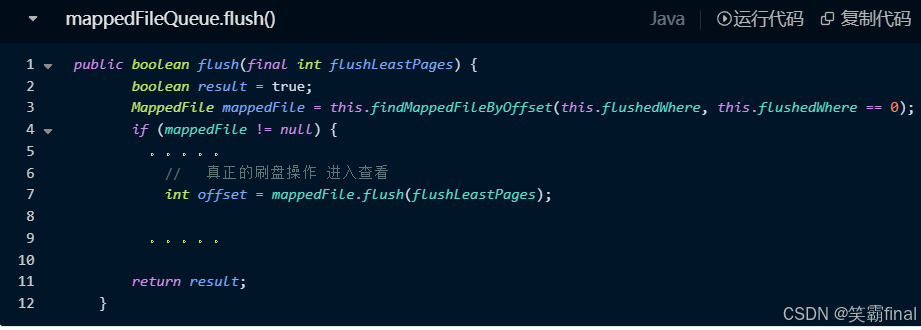
进入真正的刷盘mappedFile.flush(flushLeastPages)
public int flush(final int flushLeastPages) {if (this.isAbleToFlush(flushLeastPages)) {if (this.hold()) {//调用hold方法尝试获取刷盘所需的资源锁int value = getReadPosition();try {//We only append data to fileChannel or mappedByteBuffer, never both.// 我们只将数据附加到 fileChannel 或 mappedByteBuffer, 而不是同时附加两者if (writeBuffer != null || this.fileChannel.position() != 0) {this.fileChannel.force(false);} else {this.mappedByteBuffer.force();}} catch (Throwable e) {log.error("Error occurred when force data to disk.", e);}this.flushedPosition.set(value);this.release();//释放锁} else {log.warn("in flush, hold failed, flush offset = " + this.flushedPosition.get());this.flushedPosition.set(getReadPosition());}}// 返回当前刷盘的位置return this.getFlushedPosition();}
● flushPhysicQueueLeastPages,代表每次刷盘最少数据大小;
● flushPhysicQueueThoroughInterval:代表一个周期,每经过该周期都会执行一次刷盘,原因也很简单,因为不是每次刷盘到都能满足 flushCommitLogLeastPages 大小,因此,需要一定周期进行一次强制刷盘;
● flushCommitLogTimed:根据该参数选择执行刷盘的时机是固定周期还是等待唤醒。默认配置是后者,在上面的 submitFlushRequest() 方法最后会调用 flushCommitLogService.wakeup() 唤醒该服务线程进行刷盘
堆外内存和堆内存比较
- 使用堆外内存
优点
● 减少jvm的内存压力,避免频繁gc。
● 堆外内存有更多更大的连续内存空间,更适合大规模的消息写入
缺点
● 堆外内存不受jvm的管理,需要程序员手动释放空间,容易造成内存泄漏
● 管理不当,容易造成系统故障。
● 写入磁盘文件需要先经过 FileChannel,在刷到磁盘 - 使用堆内存
优点
● JVM自动进行内存管理和垃圾回收,管理成本较低
● 内存溢出等状况更容易定位和处理
● 使用了0拷贝
缺点
● 连续较大的内存空间较少,容易有内存碎片
● 频繁GC可能带来性能波动,影响消息写入和处理的性能。
5.2.2同步刷新
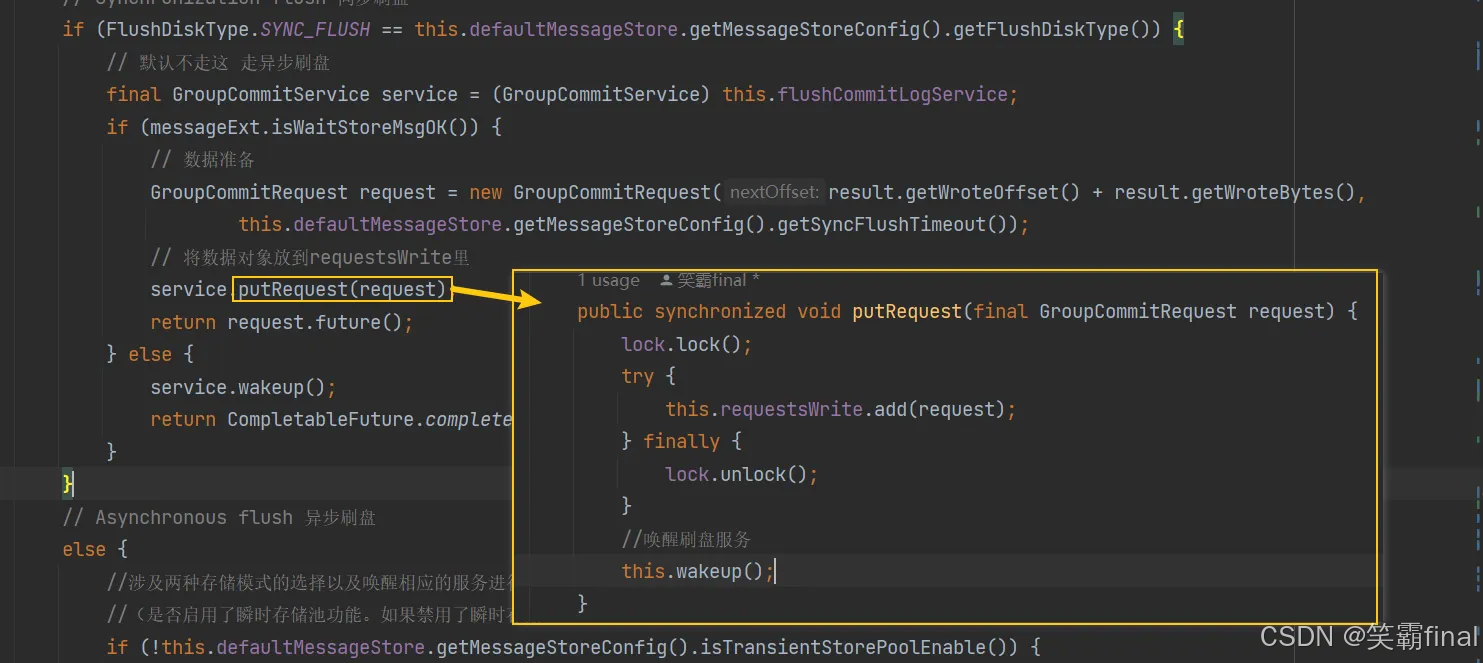
立刻唤醒 GroupCommitService 服务线程进行刷盘
public void run() {CommitLog.log.info(this.getServiceName() + " service started");// // 进入无限循环,直到服务被停止while (!this.isStopped()) {try {//睡眠10msthis.waitForRunning(10);// 执行真正的提交操作this.doCommit();} catch (Exception e) {CommitLog.log.warn(this.getServiceName() + " service has exception. ", e);}}// Under normal circumstances shutdown, wait for the arrival of the// request, and then flush 在正常关闭服务时,等待一小段时间(10毫秒),确保可能到达的所有请求得以处理try {Thread.sleep(10);} catch (InterruptedException e) {CommitLog.log.warn("GroupCommitService Exception, ", e);}// 进行同步操作,交换请求队列中的请求synchronized (this) {this.swapRequests();}// 在退出前最后一次执行提交操作,确保所有数据都已持久化this.doCommit();CommitLog.log.info(this.getServiceName() + " service end");}
// 在退出前最后一次执行提交操作,确保所有数据都已持久化
this.doCommit();
// 执行提交操作,主要处理GroupCommitRequest列表中的请求
private void doCommit() {// 检查是否有待处理的GroupCommitRequestif (!this.requestsRead.isEmpty()) {// 遍历所有待处理的GroupCommitRequestfor (GroupCommitRequest req : this.requestsRead) {// 检查当前已经刷盘的位置是否大于或等于目标请求的下一个偏移量boolean flushOK = CommitLog.this.mappedFileQueue.getFlushedWhere() >= req.getNextOffset();// 如果尚未满足条件,最多尝试两次刷盘操作for (int i = 0; i < 2 && !flushOK; i++) {// 触发MappedFileQueue的刷盘操作CommitLog.this.mappedFileQueue.flush(0);// 检查是否满足刷盘位置条件flushOK = CommitLog.this.mappedFileQueue.getFlushedWhere() >= req.getNextOffset();}// 根据刷盘结果唤醒客户,并传递相应的状态req.wakeupCustomer(flushOK ? PutMessageStatus.PUT_OK : PutMessageStatus.FLUSH_DISK_TIMEOUT);}// 获取MappedFileQueue中最新消息的存储时间戳,并更新物理消息存储的时间戳long storeTimestamp = CommitLog.this.mappedFileQueue.getStoreTimestamp();if (storeTimestamp > 0) {CommitLog.this.defaultMessageStore.getStoreCheckpoint().setPhysicMsgTimestamp(storeTimestamp);}// 清空已处理完的requestsRead列表this.requestsRead = new LinkedList<>();} else {// 如果没有GroupCommitRequest需要处理,但由于个别消息设置了非同步刷盘,也会来到这个流程// 因此这里仍然触发一次MappedFileQueue的刷盘操作CommitLog.this.mappedFileQueue.flush(0);}
}
六、MMAP内存映射和零拷贝机制
零拷贝(Zero Copy) 技术被广泛应用于提高消息传输效率,减少数据在内核态和用户态之间的复制次数,从而提升性能。
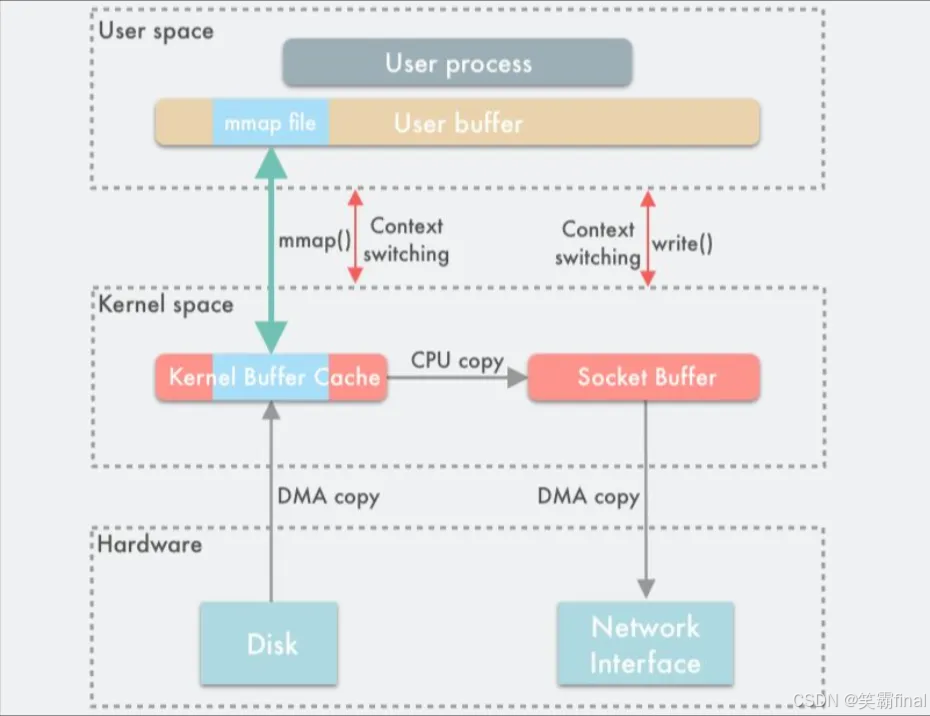
Linux 中使用 mmap() 在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。所以我们可以利用 mmap() 把用户进程空间的一段内存缓冲区映射到文件所在的内核缓冲区上,这样操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。这种机制在 Java 中是通过 NIO 包中的 MappedByteBuffer 实现的
零拷贝在rocketmq中的应用
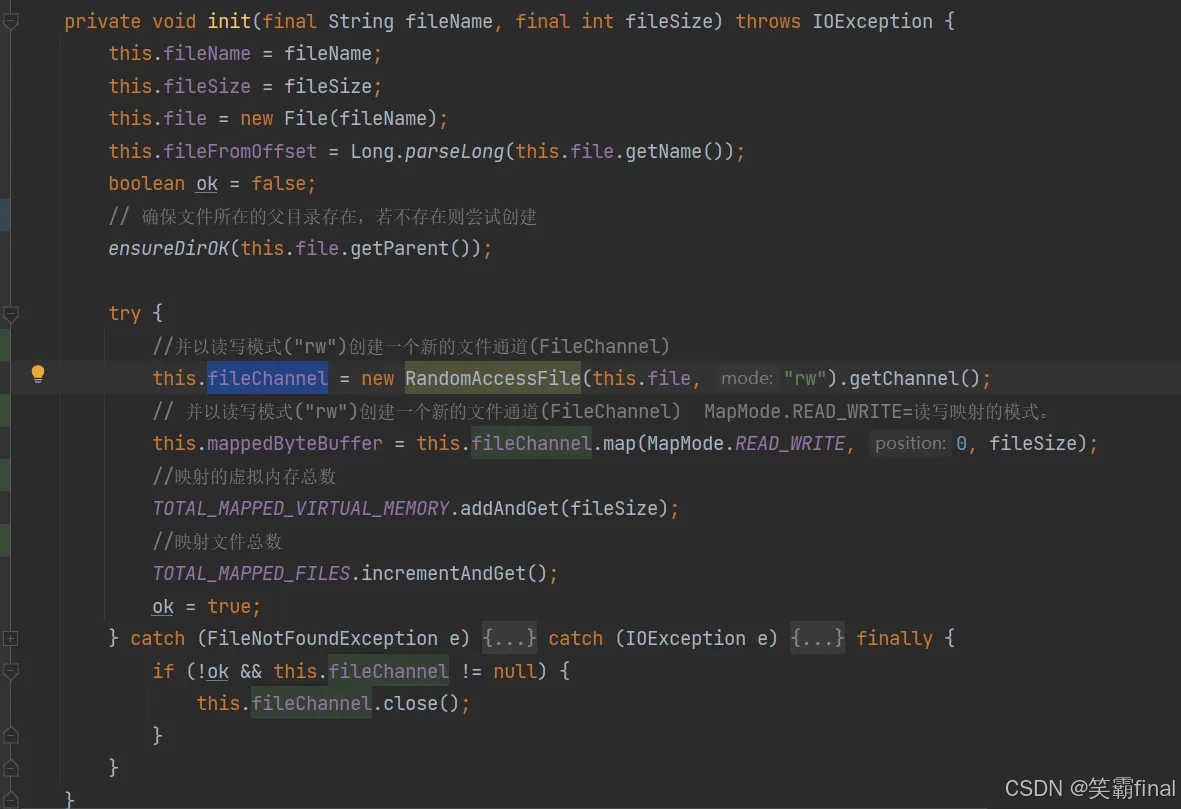
1)使用RandomAccessFile创建文件 然后使用file Channel.map()映射内存
2)往创建的文件中写入数据
当调用BytBuffer slice()方法时,它会创建一个新的缓冲区视图, 该视图共享原缓冲区的底层数据存储区域,但具有独立的位置、限制和容量。这意味着当我们对切片后的缓冲区进行读写操作时,实际上就是在对映射到内存的磁盘文件进行操作,而不需要将数据复制到新的缓冲区。
3)读写操作

RocketMQ 零拷贝技术对性能影响的几个关键方面:
- 减少CPU使用率:通过内存映射(mmap):RocketMQ 能够避免将数据从内核空间复制到用户空间,这减少了 CPU 在处理数据传输时的工作量。尤其是在高吞吐量场景下,这种减少可以显著降低 CPU 的负载。
- 提高I/O性能:RocketMQ 使用了 MappedByteBuffer 来进行内存映射。这种方式允许直接在内存中操作文件内容,而不是每次都进行实际的磁盘 I/O 操作。这样不仅加快了文件访问速度,还利用了操作系统的页面缓存机制来进一步提升性能
- 降低延迟:减少了不必要的数据复制步骤,RocketMQ 可以更快速地处理消息的存储和转发任务.
限制
尽管零拷贝带来了许多好处,但它也有一定的局限性:
- 内存管理:使用 Mmap 的内存可能被换出到交换分区(swap),需要适当的配置来优化内存使用。
- 适用场景:更适合中小型消息的频繁读写,而非超大文件的传输。例如,Kafka 更倾向于使用 sendfile 技术来处理大文件传输,而 RocketMQ 则更适合于小块业务消息的持久化和传输。
七、总结
- 使用非公平锁加锁(可以修改配置为false 就是使用的CAS ;在消息写入过程中会先从 MappedFileQueue 队列中获取最后一个 MappedFile,因为 CommitLog 是顺序写入的,前面的 CommitLog 文件都已经写满了,只有最后一个 MappedFile 文件可写入。
- 如果当前还没有创建过 CommitLog 文件(获取到的 MappedFile 为 null) 或者 当前 CommitLog 已经写满了,就会新建一个新的 CommitLog 文件,并通过计算文件起始偏移量作为 CommitLog 文件名。
- MappedFile的创建 使用mmap来创建的MappedFile
● MappedFile 的创建过程是将构建一个 AllocateRequest 对象,该对象指定了文件的路径和文件的大小,并放入到 requestQueue 队列中(是一个优先级阻塞队列)。最后通过同步工具类 CountDownLatch 等待 MappedFile 创建完成。
● RocketMQ 会连续创建两个 MappedFile。RocketMQ 中预分配MappedFile 的设计非常巧妙,下次获取时候直接返回,可以不用等待 MappedFile 创建分配所产生的时间延迟。通过优先级队列,利用 CommitLog 文件名中的偏移量设置优先级(偏移量越小优先级越高)
● 创建mappedFile会进行文件预热(1清理原有数据。2防止当真正写入消息时发生缺页,触发内存的分配和映射- 获取到 MmapedFile 后,调用 appendMessagesInner() 方法将消息写入到映射的物理内存中(byteBuffer)。如果空间不够则创建新的物理映射,然后将消息存入【一个消息不能跨两个commitlog】
- 消息刷盘 异步/同步
● 刷盘之前会释放锁
● Broker端拿到消息后先将消息、topic、queue等内容存到ByteBuffer里,然后去持久化到commitlog文件中。commitlog文件大小为1G,超出大小会新创建commitlog文件来存储,采取的nio方式。( NIO 的 force() )
● 都使用mmap来加速消息的写入。