声纹技术体系:从理论基础到工程实践的完整技术架构

文章目录
- 一、声纹技术的理论基础与概念内核
- 1.1 声纹的生物学本质与数学表征
- 1.2 特征提取的理论基础与实现机制
- 二、声纹识别技术的演进逻辑与方法体系
- 2.1 传统统计学方法的理论架构
- 2.2 深度学习方法的技术革新
- 2.3 损失函数的设计原理与优化策略
- 三、声纹识别系统的架构设计与模块组成
- 3.1 系统架构的整体设计逻辑
- 3.2 说话人建模的多元化策略
- 3.3 评分判决的算法设计
- 四、声纹分割聚类技术的算法实现
- 4.1 说话人分离的技术挑战
- 4.2 实时处理的在线算法
- 五、性能评估体系与指标分析
- 5.1 基础性能指标的数学定义
- 5.2 多维性能评估框架
- 六、工程实现与部署策略
- 6.1 系统架构的工程化设计
- 6.2 模型优化的技术策略
- 6.3 部署模式的选择与考量
- 七、主流技术工具与开发平台
- 7.1 开源工具包的技术特点
- 7.2 深度学习框架的应用实践
- 7.3 音频处理库的工具支持
- 八、应用场景与系统适配
- 8.1 智能客服与呼叫中心的技术需求
- 8.2 智能音箱与语音助手的个性化服务
- 8.3 金融认证的安全要求
- 8.4 物联网边缘设备的资源约束
- 九、技术发展趋势与未来挑战
- 9.1 跨域泛化的理论瓶颈
- 9.2 对抗攻击的防护机制
- 9.3 自监督学习的技术潜力
- 9.4 多模态融合的发展方向
- 专业术语附录
一、声纹技术的理论基础与概念内核
1.1 声纹的生物学本质与数学表征
声纹的独特性源理
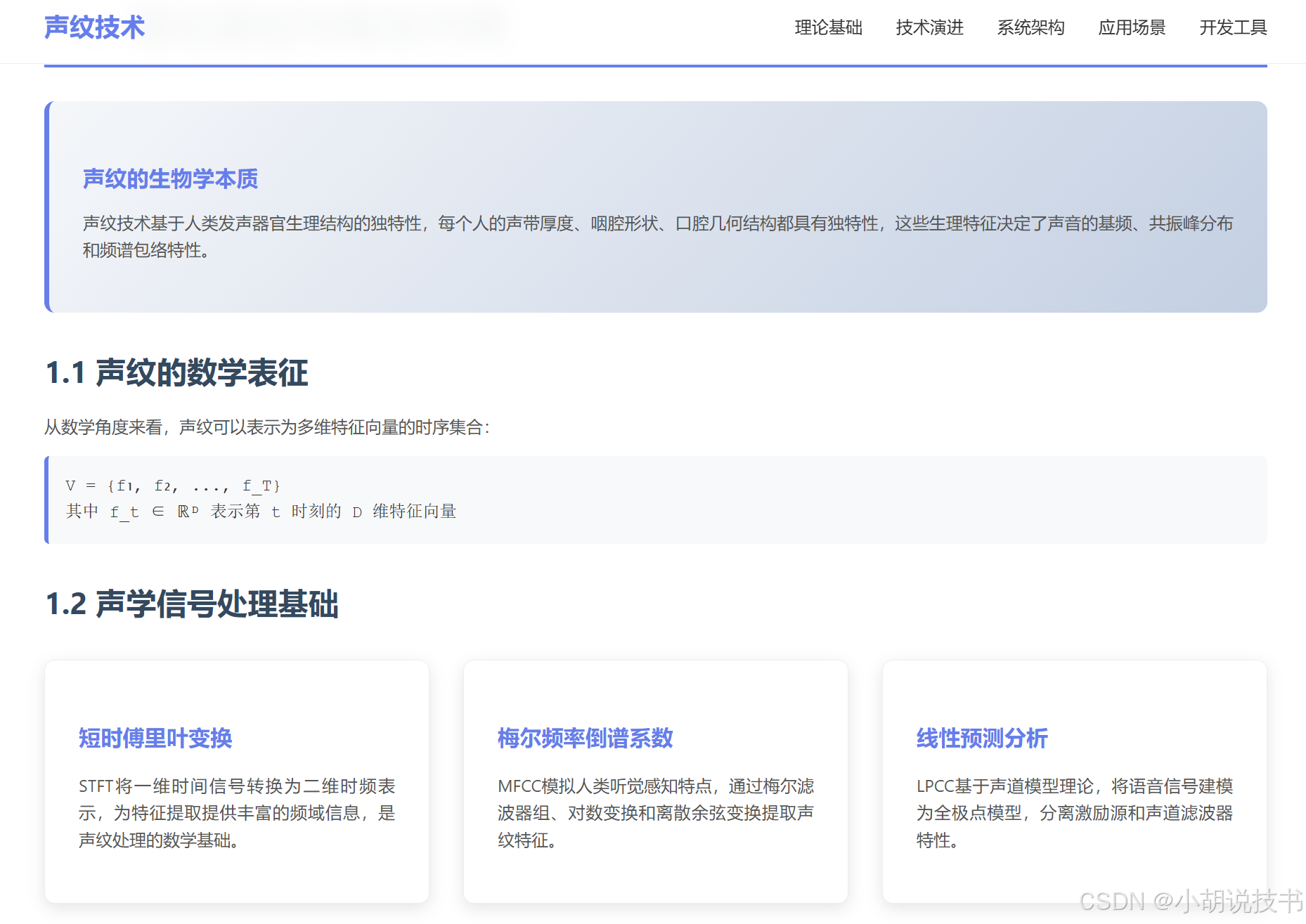
声纹(Voiceprint)本质上是人类发声器官生理结构差异在声学信号中的体现。每个人的声带厚度、咽腔形状、口腔几何结构都具有独特性,这些生理特征决定了声音的基频、共振峰分布和频谱包络特性。从数学角度来看,声纹可以表示为多维特征向量的时序集合:
V = { f 1 , f 2 , … , f T } \mathbf{V} = \{\mathbf{f}_1, \mathbf{f}_2, \ldots, \mathbf{f}_T\} V={f1,f2,…,fT}
其中 f t ∈ R D \mathbf{f}_t \in \mathbb{R}^D ft∈RD 表示第 t t t 时刻的 D D D 维特征向量, T T T 为语音段的帧数。这种数学抽象为后续的计算处理奠定了基础。
声学信号处理的数学基础
声纹处理的核心在于时频分析。由于语音信号的非平稳特性,我们使用短时傅里叶变换(STFT)进行时频联合分析:
X ( m , ω ) = ∑ n = − ∞ ∞ x [ n ] w [ n − m ] e − j ω n X(m,\omega) = \sum_{n=-\infty}^{\infty} x[n]w[n-m]e^{-j\omega n} X(m,ω)=n=−∞∑∞x[n]w[n−m]e−jωn
这里 w [ n ] w[n] w[n] 为窗函数,通常采用汉明窗或汉宁窗。通过STFT,我们将一维时间信号转换为二维时频表示,为特征提取提供了丰富的频域信息。
1.2 特征提取的理论基础与实现机制
梅尔频率倒谱系数(MFCC)的提取逻辑
MFCC作为经典的声纹特征,其设计体现了人类听觉感知的特点。提取过程包括预加重、分帧加窗、FFT变换、梅尔滤波器组处理、对数变换和离散余弦变换六个步骤。预加重公式为:
s ′ [ n ] = s [ n ] − α s [ n − 1 ] s'[n] = s[n] - \alpha s[n-1] s′[n]=s[n]−αs[n−1]
其中 α ≈ 0.97 \alpha \approx 0.97 α≈0.97,目的是平衡语音信号的频谱,补偿高频衰减。梅尔滤波器组模拟人耳的非线性频率感知,将线性频率转换为梅尔频率:
m = 2595 log 10 ( 1 + f / 700 ) m = 2595 \log_{10}(1 + f/700) m=2595log10(1+f/700)
线性预测倒谱系数(LPCC)的声道建模理论
LPCC基于声道模型理论,将语音信号建模为全极点模型:
s [ n ] = ∑ i = 1 p a i s [ n − i ] + G u [ n ] s[n] = \sum_{i=1}^{p} a_i s[n-i] + G u[n] s[n]=i=1∑pais[n−i]+Gu[n]
这里 a i a_i ai 为预测系数,反映声道的共振特性; G G G 为增益因子; u [ n ] u[n] u[n] 为激励信号。这种建模方式将语音生成过程分解为激励源和声道滤波器,为说话人特征的分离提供了理论基础。
二、声纹识别技术的演进逻辑与方法体系
2.1 传统统计学方法的理论架构
高斯混合模型(GMM)的概率建模框架
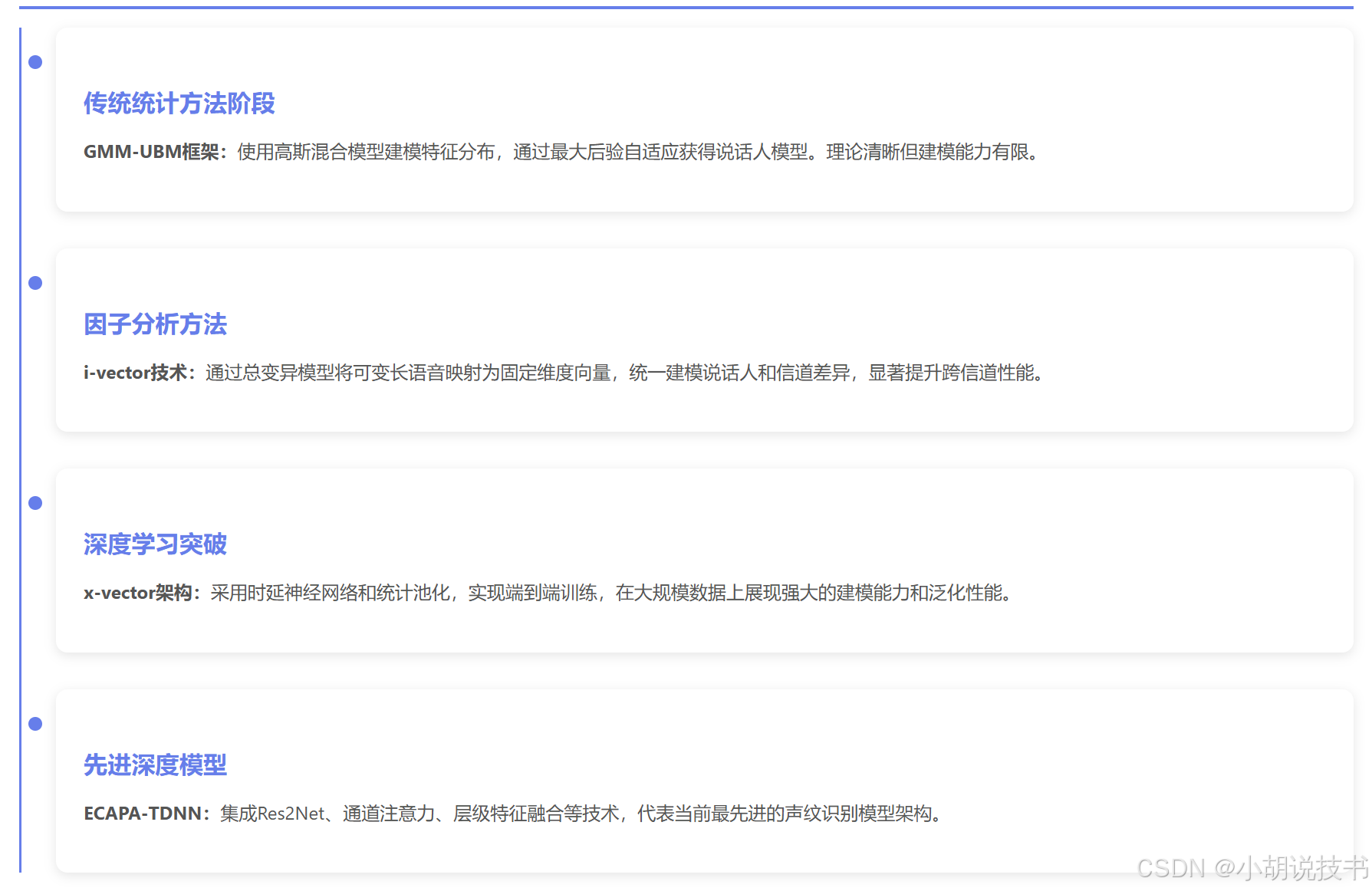
GMM-UBM(通用背景模型)框架是早期声纹识别的主流方法。其核心思想是用多个高斯分布的线性组合来建模特征分布:
p ( x ) = ∑ i = 1 K w i N ( x ∣ μ i , Σ i ) p(\mathbf{x}) = \sum_{i=1}^{K} w_i \mathcal{N}(\mathbf{x}|\boldsymbol{\mu}_i, \boldsymbol{\Sigma}_i) p(x)=i=1∑KwiN(x∣μi,Σi)
UBM作为通用声学模型,通过大量说话人数据训练得到。对于特定说话人,使用最大后验(MAP)自适应从UBM获得个性化模型,似然比计算公式为:
Λ ( X ) = p ( X ∣ λ t a r g e t ) p ( X ∣ λ U B M ) \Lambda(\mathbf{X}) = \frac{p(\mathbf{X}|\lambda_{target})}{p(\mathbf{X}|\lambda_{UBM})} Λ(X)=p(X∣λUBM)p(X∣λtarget)
这种方法的优势在于理论清晰、计算复杂度可控,但受限于建模能力和信道变异的影响。
因子分析方法的数学原理
为了解决信道变异问题,联合因子分析(JFA)方法将GMM均值超向量分解为说话人因子和信道因子。进一步,i-vector方法统一建模说话人和信道差异:
s = m + T w \mathbf{s} = \mathbf{m} + \mathbf{T}\mathbf{w} s=m+Tw
其中 s \mathbf{s} s 为说话人-信道相关的均值超向量, m \mathbf{m} m 为UBM均值超向量, T \mathbf{T} T 为全变量空间矩阵, w \mathbf{w} w 为i-vector。这种方法将可变长的语音序列映射为固定维度的向量表示,为后续处理提供了标准化的输入。
2.2 深度学习方法的技术革新
x-vector系统的网络架构设计
x-vector代表了深度学习在声纹识别中的重要突破。其网络架构包括时延神经网络(TDNN)层、统计池化层和全连接层。TDNN层提取局部时间上下文信息,统计池化层通过计算均值和标准差将变长序列映射为固定维度:
m e a n = 1 T ∑ t = 1 T h t \mathbf{mean} = \frac{1}{T} \sum_{t=1}^{T} \mathbf{h}_t mean=T1t=1∑Tht
s t d = 1 T ∑ t = 1 T ( h t − m e a n ) 2 \mathbf{std} = \sqrt{\frac{1}{T} \sum_{t=1}^{T} (\mathbf{h}_t - \mathbf{mean})^2} std=T1t=1∑T(ht−mean)2
统计池化的输出 [ m e a n , s t d ] [\mathbf{mean}, \mathbf{std}] [mean,std] 作为说话人嵌入的基础表示。
ECAPA-TDNN的先进架构
ECAPA-TDNN在x-vector基础上引入了多项技术创新。Res2Net模块增强了多尺度特征提取能力,SE(Squeeze-and-Excitation)注意力机制强化了通道间的相关性建模,层级特征融合整合了不同层次的信息,注意力池化替代了简单的统计池化。这些改进显著提升了系统在复杂环境下的鲁棒性。
2.3 损失函数的设计原理与优化策略
Angular Softmax的几何意义
为了增强说话人类间的区分度,现代深度学习系统采用带边际的Softmax损失函数。Angular Softmax(A-Softmax)在角度空间引入边际:
L A − s o f t m a x = − log e ∣ ∣ W y ∣ ∣ ∣ ∣ x ∣ ∣ cos ( m θ y ) e ∣ ∣ W y ∣ ∣ ∣ ∣ x ∣ ∣ cos ( m θ y ) + ∑ j ≠ y e ∣ ∣ W j ∣ ∣ ∣ ∣ x ∣ ∣ cos ( θ j ) L_{A-softmax} = -\log \frac{e^{||\mathbf{W}_y|| ||\mathbf{x}|| \cos(m\theta_y)}}{e^{||\mathbf{W}_y|| ||\mathbf{x}|| \cos(m\theta_y)} + \sum_{j \neq y} e^{||\mathbf{W}_j|| ||\mathbf{x}|| \cos(\theta_j)}} LA−softmax=−loge∣∣Wy∣∣∣∣x∣∣cos(mθy)+∑j=ye∣∣Wj∣∣∣∣x∣∣cos(θj)e∣∣Wy∣∣∣∣x∣∣cos(mθy)
这种设计强制网络学习更加紧凑的类内分布和更大的类间距离,从几何角度优化了特征空间的分布。
三、声纹识别系统的架构设计与模块组成
3.1 系统架构的整体设计逻辑
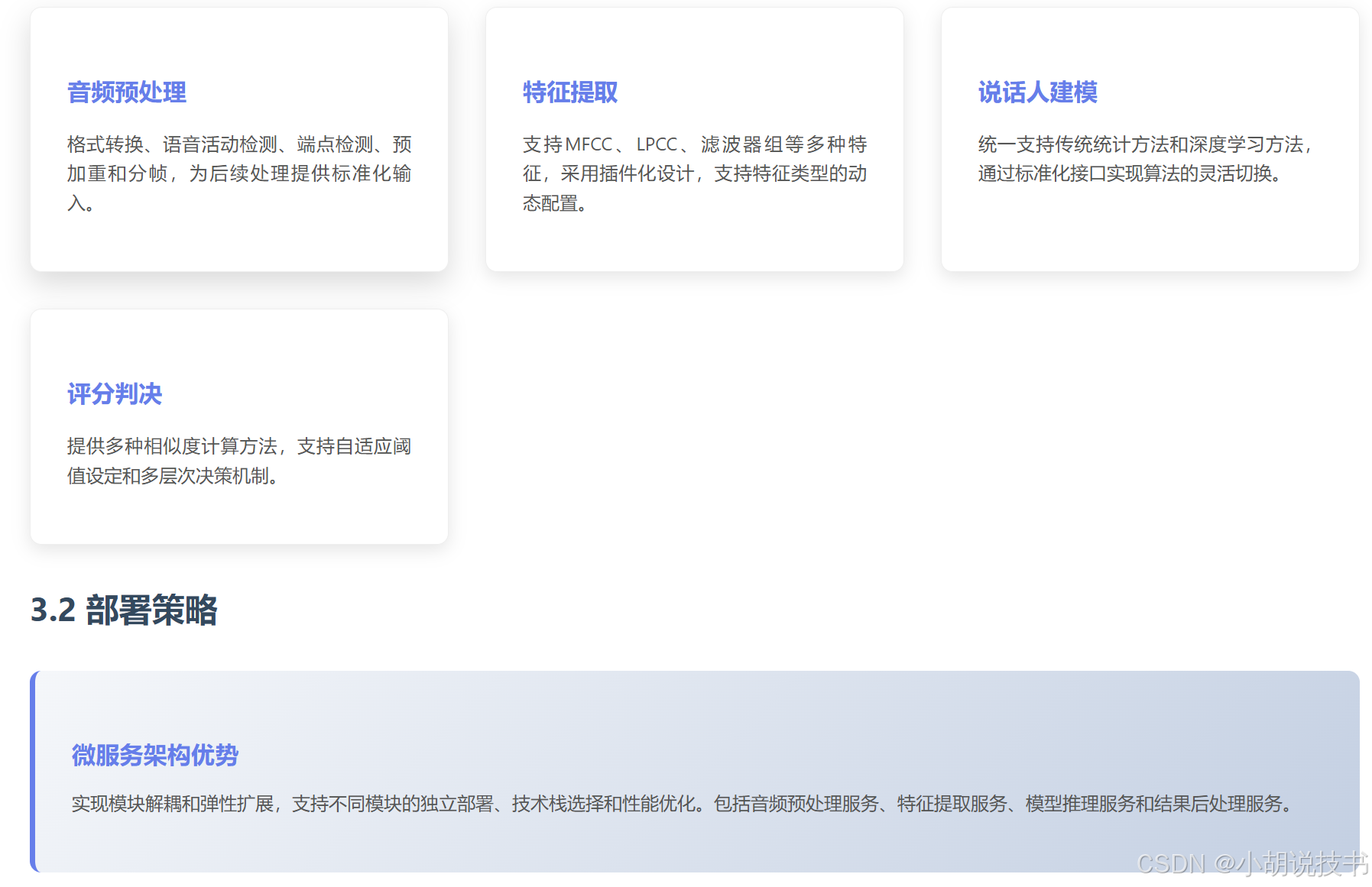
现代声纹识别系统采用模块化设计,包括音频预处理、特征提取、说话人建模、评分判决和性能评估五个核心模块。每个模块承担特定功能,通过标准化接口实现模块间的无缝协作。
音频预处理模块的技术实现
音频预处理是整个系统的基础,包括格式转换、语音活动检测(VAD)、端点检测、预加重和分帧等步骤。VAD算法通过能量检测、过零率分析或深度学习模型识别语音和非语音段,为后续处理提供干净的语音输入。预加重和分帧为特征提取做准备,通常采用25ms的帧长和10ms的帧移。
特征提取模块的多层次设计
特征提取模块支持多种特征类型的提取,包括传统的MFCC、LPCC,以及现代的滤波器组特征、梅尔谱图等。模块设计采用插件化架构,支持特征类型的动态配置和组合。对于深度学习系统,还支持端到端的特征学习,直接从原始波形或谱图学习最优特征表示。
3.2 说话人建模的多元化策略
传统统计建模的实现路径
在GMM-UBM框架下,说话人建模分为UBM训练和说话人模型自适应两个阶段。UBM训练使用期望最大化(EM)算法,在大规模背景数据上学习通用声学模型。说话人模型通过MAP自适应获得,只更新均值参数,协方差矩阵和权重保持不变。这种设计在数据稀缺情况下具有良好的泛化能力。
深度学习建模的端到端优化
深度学习方法采用端到端训练,网络同时学习特征提取和说话人分类。训练阶段使用大规模多说话人数据,通过分类损失优化网络参数。测试阶段提取嵌入层的激活作为说话人表示。这种方法的优势在于能够学习任务相关的最优特征,但需要大量标注数据和计算资源。
3.3 评分判决的算法设计
相似度计算的多种策略
评分判决模块负责计算测试语音与注册模板的相似度。传统方法使用对数似然比,深度学习方法多采用余弦相似度:
cosine ( x , y ) = x ⋅ y ∣ ∣ x ∣ ∣ ∣ ∣ y ∣ ∣ \text{cosine}(\mathbf{x}, \mathbf{y}) = \frac{\mathbf{x} \cdot \mathbf{y}}{||\mathbf{x}|| ||\mathbf{y}||} cosine(x,y)=∣∣x∣∣∣∣y∣∣x⋅y
对于i-vector系统,通常使用PLDA(概率线性判别分析)进行后端评分,能够有效补偿信道变异和噪声影响。
阈值设定的策略考量
阈值设定需要平衡假接受率(FAR)和假拒绝率(FRR)。在安全敏感应用中,通常设置较高阈值以降低FAR;在用户体验优先的场景中,则适当降低阈值以提高通过率。阈值可以通过ROC曲线分析或在验证数据集上优化DCF来确定。
四、声纹分割聚类技术的算法实现
4.1 说话人分离的技术挑战
说话人分离(Speaker Diarization)旨在回答"谁在什么时候说话"的问题,是多说话人环境下的核心技术。该任务面临说话人数量未知、语音重叠、信道变异等挑战,需要综合运用语音活动检测、特征提取、聚类分析和后处理技术。
聚类算法的数学基础
K-means聚类通过最小化簇内平方和实现说话人分组:
J = ∑ i = 1 K ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 J = \sum_{i=1}^{K} \sum_{\mathbf{x} \in C_i} ||\mathbf{x} - \boldsymbol{\mu}_i||^2 J=i=1∑Kx∈Ci∑∣∣x−μi∣∣2
谱聚类基于图论,将聚类问题转化为图分割:构建相似性矩阵,计算拉普拉斯矩阵的特征值分解,使用前K个特征向量进行最终聚类。这种方法能够发现非凸形状的聚类,适合复杂的说话人分布。
端到端神经网络分离
现代分离系统采用端到端训练,网络直接从混合语音生成分离结果。置换不变性训练(PIT)解决了输出标签的排列歧义:
L P I T = min π ∈ Π ∑ i = 1 C L ( y i , y ^ π ( i ) ) L_{PIT} = \min_{\pi \in \Pi} \sum_{i=1}^{C} L(y_i, \hat{y}_{\pi(i)}) LPIT=π∈Πmini=1∑CL(yi,y^π(i))
这种训练方式使得网络能够自动学习最优的分离策略,无需手工设计聚类算法。
4.2 实时处理的在线算法
增量聚类的数学模型
对于流式音频处理,需要设计增量聚类算法以支持实时处理。聚类中心的更新公式为:
μ i ( t + 1 ) = n i ( t ) μ i ( t ) + x t + 1 n i ( t ) + 1 \boldsymbol{\mu}_i^{(t+1)} = \frac{n_i^{(t)} \boldsymbol{\mu}_i^{(t)} + \mathbf{x}_{t+1}}{n_i^{(t)} + 1} μi(t+1)=ni(t)+1ni(t)μi(t)+xt+1
同时设计自适应阈值机制处理未知说话人数量:
τ a d a p t i v e = μ d i s t + k × σ d i s t \tau_{adaptive} = \mu_{dist} + k \times \sigma_{dist} τadaptive=μdist+k×σdist
这种设计能够在处理过程中动态调整聚类参数,适应说话人数量的变化。
五、性能评估体系与指标分析
5.1 基础性能指标的数学定义
等错误率(EER)的统计意义
EER是声纹识别系统最重要的性能指标,定义为误接受率(FAR)和误拒绝率(FRR)相等时的错误率。通过ROC曲线分析确定:
- 误接受率: F A R = N f a N i m p FAR = \frac{N_{fa}}{N_{imp}} FAR=NimpNfa
- 误拒绝率: F R R = N f r N g e n FRR = \frac{N_{fr}}{N_{gen}} FRR=NgenNfr
EER提供了系统性能的单一标量度量,便于不同系统间的比较。
检测代价函数(DCF)的实用价值
DCF考虑了不同类型错误的相对代价,更贴近实际应用需求:
D C F = C m i s s × P m i s s × P t a r g e t + C f a × P f a × ( 1 − P t a r g e t ) DCF = C_{miss} \times P_{miss} \times P_{target} + C_{fa} \times P_{fa} \times (1-P_{target}) DCF=Cmiss×Pmiss×Ptarget+Cfa×Pfa×(1−Ptarget)
通过调整代价权重和先验概率,DCF能够反映不同应用场景的性能要求。
5.2 多维性能评估框架
鲁棒性评估的量化方法
系统鲁棒性评估包括信道鲁棒性和噪声鲁棒性两个维度。信道鲁棒性通过计算不同信道条件下的性能变异系数评估,噪声鲁棒性在不同信噪比条件下测试系统性能。相对性能衰减公式:
Δ p e r f = P e r f m i s m a t c h − P e r f m a t c h e d P e r f m a t c h e d \Delta_{perf} = \frac{Perf_{mismatch} - Perf_{matched}}{Perf_{matched}} Δperf=PerfmatchedPerfmismatch−Perfmatched
识别任务的评估策略
识别任务使用Top-N准确率评估:
A c c T o p − N = 1 M ∑ i = 1 M I ( y i ∈ Top-N ( f ( x i ) ) ) Acc_{Top-N} = \frac{1}{M} \sum_{i=1}^{M} \mathbb{I}(y_i \in \text{Top-N}(f(\mathbf{x}_i))) AccTop−N=M1i=1∑MI(yi∈Top-N(f(xi)))
这个指标反映了系统在闭集条件下的检索能力,对于大规模身份识别应用具有重要意义。
六、工程实现与部署策略
6.1 系统架构的工程化设计
微服务架构的技术优势
现代声纹识别系统采用微服务架构,实现模块解耦和弹性扩展。主要服务包括音频预处理服务、特征提取服务、模型推理服务和结果后处理服务。这种架构支持不同模块的独立部署、技术栈选择和性能优化。
流式处理的实时架构
实时应用需要流式处理架构,包括音频缓冲、特征计算、模型推理和结果输出四个环节。通过异步处理和流水线优化,系统能够在保证精度的同时满足实时性要求。负载均衡和GPU调度确保系统在高并发下的稳定运行。
6.2 模型优化的技术策略
量化技术的理论基础
模型量化通过降低参数精度减少计算复杂度。INT8量化将32位浮点参数转换为8位整数,量化误差的理论分析为:
E q u a n t = Δ 2 12 E_{quant} = \frac{\Delta^2}{12} Equant=12Δ2
其中 Δ \Delta Δ 为量化步长。动态量化和静态量化分别适用于不同的部署场景。
知识蒸馏的模型压缩
知识蒸馏通过教师-学生网络实现模型压缩:
L d i s t i l l = α L C E ( y , σ ( z s ) ) + ( 1 − α ) L K D ( σ ( z t / T ) , σ ( z s / T ) ) L_{distill} = \alpha L_{CE}(y, \sigma(z_s)) + (1-\alpha) L_{KD}(\sigma(z_t/T), \sigma(z_s/T)) Ldistill=αLCE(y,σ(zs))+(1−α)LKD(σ(zt/T),σ(zs/T))
这种方法能够在保持精度的同时显著减少模型大小和计算量。
6.3 部署模式的选择与考量
边缘计算部署的技术挑战
边缘部署适合实时性要求高、数据敏感的场景,但面临计算资源限制、存储约束和功耗管理等挑战。需要通过模型压缩、算法优化和硬件加速等技术手段解决。
云端集中部署的架构优势
云端部署具有资源弹性、版本管理便利、成本效益高等优势。通过负载均衡、缓存策略和容错机制,能够支持大规模、高并发的应用需求。
七、主流技术工具与开发平台
7.1 开源工具包的技术特点
Kaldi的经典地位
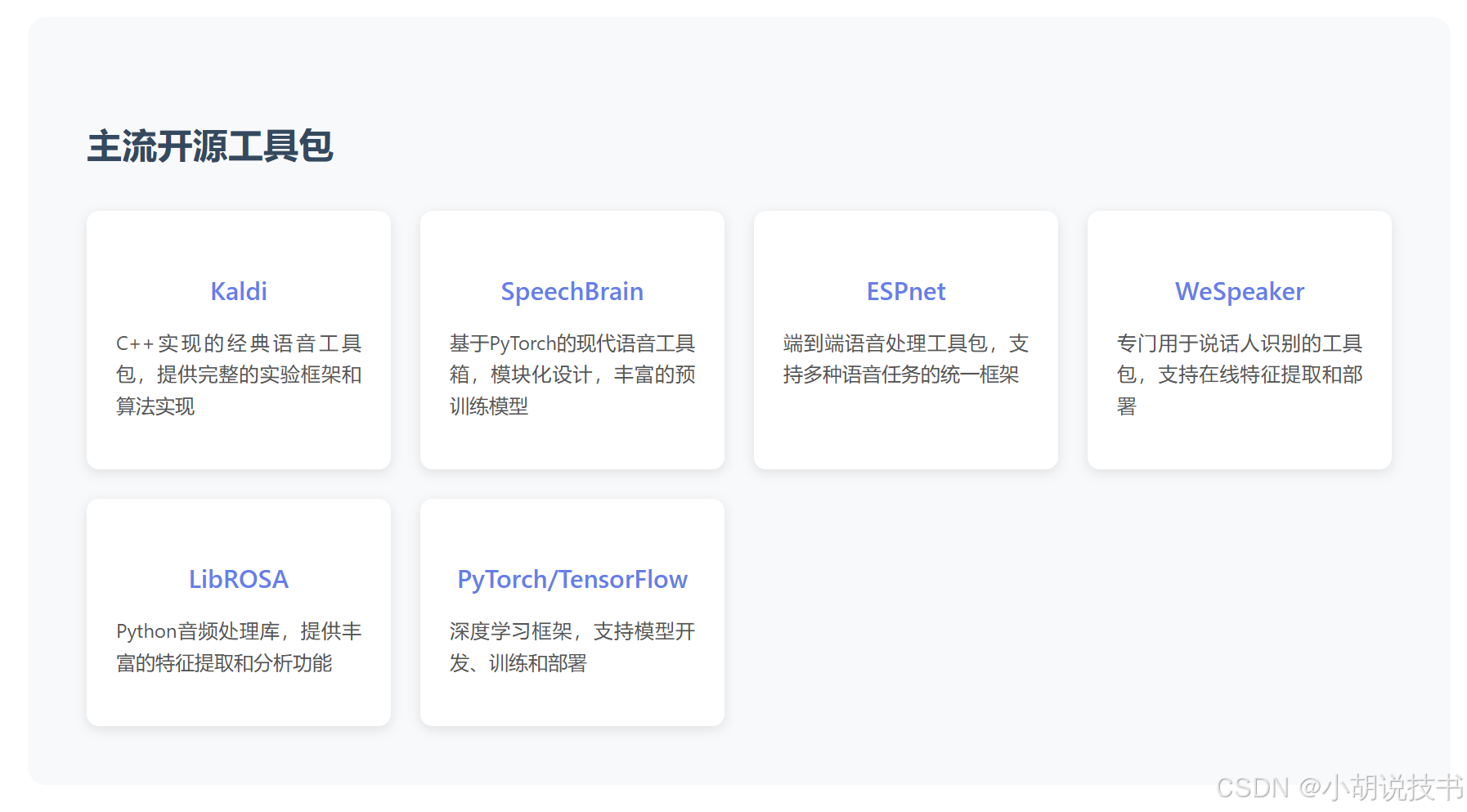
Kaldi作为C++实现的开源语音工具包,提供了完整的声纹识别实验框架。其特点包括丰富的算法实现、完备的实验脚本、强大的数据处理能力和高效的计算性能。Kaldi支持从特征提取到模型训练的全流程处理,是传统方法的首选平台。
SpeechBrain的现代化设计
SpeechBrain基于PyTorch构建,提供了数百个实验配方和预训练模型。其模块化设计支持快速原型开发和实验验证,特别适合深度学习方法的研究和开发。工具包包含说话人识别、验证、分离等多个任务的完整实现。
7.2 深度学习框架的应用实践
PyTorch的灵活性优势
PyTorch作为动态计算图框架,在研究和开发中具有显著优势。其动态特性支持复杂模型的构建和调试,丰富的生态系统提供了众多预训练模型和工具库。在声纹识别领域,PyTorch被广泛用于x-vector、ECAPA-TDNN等先进模型的实现。
TensorFlow的工程化优势
TensorFlow在生产部署方面具有优势,TensorFlow Serving、TensorFlow Lite等工具支持模型的高效部署。其静态计算图和自动优化能力适合大规模工程应用。
7.3 音频处理库的工具支持
LibROSA的功能全面性
LibROSA作为Python音频处理库,提供了丰富的音频分析功能,包括特征提取、时频分析、节奏分析等。其API设计简洁,文档完善,是音频预处理和特征提取的重要工具。
专业音频工具的集成应用
在工程实践中,通常需要集成多种工具以实现最佳效果。Kaldi负责传统方法的实现,SpeechBrain处理深度学习模型,LibROSA进行音频预处理,这种混合使用策略能够充分发挥各工具的优势。
八、应用场景与系统适配

8.1 智能客服与呼叫中心的技术需求
在呼叫中心场景中,声纹识别替代传统的PIN码验证,提升用户体验和安全性。系统需要处理电话信道的带宽限制、压缩失真和背景噪声等挑战。技术实现上采用信道自适应算法和噪声鲁棒特征,确保在恶劣条件下的识别准确性。
多方通话的分离需求
呼叫中心经常涉及多方通话,需要实时分离和识别不同说话人。系统采用在线分割聚类算法,结合语音活动检测和说话人嵌入技术,实现"谁在什么时候说话"的实时标注。
8.2 智能音箱与语音助手的个性化服务
智能音箱需要在家庭环境中识别不同成员,提供个性化服务。系统面临多说话人环境、可变语音长度和背景噪声等挑战。技术解决方案包括多麦克风阵列、声源定位、波束形成和说话人适应等。
本地与云端的混合架构
考虑到隐私保护和响应速度,智能音箱通常采用混合架构:简单的验证任务在本地处理,复杂的识别任务上传云端。这种设计平衡了性能、隐私和资源消耗的需求。
8.3 金融认证的安全要求
金融应用对安全性要求极高,需要抵御录音重放、语音合成等攻击。系统集成反欺骗检测模块,采用多模态验证和风险评估机制。技术实现包括活体检测、语音质量评估和异常行为分析。
数据安全与隐私保护
金融场景的声纹数据需要端到端加密,模型训练采用联邦学习或差分隐私技术保护用户隐私。系统设计遵循最小权限原则,确保数据安全和合规性。
8.4 物联网边缘设备的资源约束
IoT设备的计算资源和存储空间有限,需要轻量化的模型和算法。技术策略包括模型压缩、量化、剪枝和知识蒸馏。算法设计优先考虑计算效率,采用简化的特征提取和快速匹配算法。
功耗优化的设计考量
边缘设备的功耗管理至关重要,需要在算法层面优化计算复杂度,在硬件层面选择低功耗芯片。通过任务调度和休眠机制,最小化系统功耗。
九、技术发展趋势与未来挑战
9.1 跨域泛化的理论瓶颈
当前声纹识别系统在跨域应用中面临显著的性能衰减问题。域自适应理论提供了理论分析框架,目标域误差的上界为:
R t ( h ) ≤ R s ( h ) + 1 2 d H Δ H ( D s , D t ) + λ R_t(h) \leq R_s(h) + \frac{1}{2}d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_s, \mathcal{D}_t) + \lambda Rt(h)≤Rs(h)+21dHΔH(Ds,Dt)+λ
解决跨域问题需要从算法和数据两个层面入手:算法层面发展域自适应和迁移学习技术,数据层面构建多域训练集和标准评估协议。
9.2 对抗攻击的防护机制
随着语音合成和转换技术的发展,声纹识别系统面临越来越复杂的对抗攻击。对抗样本的数学定义为:
x a d v = x + δ \mathbf{x}_{adv} = \mathbf{x} + \boldsymbol{\delta} xadv=x+δ
其中 ∣ ∣ δ ∣ ∣ p ≤ ϵ ||\boldsymbol{\delta}||_p \leq \epsilon ∣∣δ∣∣p≤ϵ,且 f ( x a d v ) ≠ f ( x ) f(\mathbf{x}_{adv}) \neq f(\mathbf{x}) f(xadv)=f(x)。防护策略包括对抗训练、输入预处理、模型集成和检测机制等。
9.3 自监督学习的技术潜力
自监督学习为无标签数据的利用提供了新途径。对比学习通过构建正负样本对学习通用表示:
L c o n t r a s t i v e = − log exp ( sim ( z i , z j ) / τ ) ∑ k = 1 2 N I k ≠ i exp ( sim ( z i , z k ) / τ ) L_{contrastive} = -\log \frac{\exp(\text{sim}(\mathbf{z}_i, \mathbf{z}_j)/\tau)}{\sum_{k=1}^{2N} \mathbb{I}_{k \neq i} \exp(\text{sim}(\mathbf{z}_i, \mathbf{z}_k)/\tau)} Lcontrastive=−log∑k=12NIk=iexp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
wav2vec 2.0等预训练模型在语音表示学习方面取得了显著进展,为声纹识别提供了更强的特征基础。
9.4 多模态融合的发展方向
多模态声纹识别通过融合音频和视觉信息提高识别准确性和鲁棒性。融合策略包括早期融合、晚期融合和注意力融合。跨模态学习的损失函数设计为:
L t o t a l = L t a s k + λ i n t r a L i n t r a + λ i n t e r L i n t e r L_{total} = L_{task} + \lambda_{intra} L_{intra} + \lambda_{inter} L_{inter} Ltotal=Ltask+λintraLintra+λinterLinter
未来发展将更加注重模态间的互补性和一致性建模。
通过本文的系统性分析,我们构建了声纹技术从理论基础到工程实践的完整技术体系。声纹技术作为人工智能在语音处理领域的重要应用,其发展呈现出从传统统计方法向深度学习方法演进的清晰脉络。
从技术本质来看,声纹识别的核心在于利用人类发声器官的生理差异性,通过数学建模和机器学习技术实现身份认证和识别。从GMM-UBM的统计建模到x-vector的深度学习表示,从简单的余弦相似度到复杂的PLDA评分,技术的每一步演进都体现了对问题本质认识的深化和解决方案的优化。
在工程实践中,声纹识别系统需要综合考虑算法性能、计算资源、部署环境和应用需求等多个维度。微服务架构、模型优化、边缘计算等技术手段为系统的工程化部署提供了有力支撑。同时,开源工具包的丰富生态为技术的普及和应用奠定了基础。
展望未来,声纹技术将在跨域泛化、对抗鲁棒性、自监督学习和多模态融合等方向继续发展。技术的进步不仅推动着算法性能的提升,更重要的是拓展了应用场景的边界,从传统的安全认证扩展到智能交互、个性化服务等新兴领域。
理解声纹技术的完整体系,掌握其技术内核和发展逻辑,将有助于我们在面对实际应用需求时做出科学的技术选择和系统设计决策,推动声纹技术在更广阔的领域发挥价值。
专业术语附录
A-F术语解释
- AAM-Softmax (Additive Angular Margin Softmax): 加性角度边际Softmax,一种改进的损失函数,在角度空间增加固定边际以增强类间区分度
- AUC (Area Under Curve): ROC曲线下的面积,用于评估二分类模型的整体性能,数值范围0-1,越大表示性能越好
- Angular Softmax: 角度Softmax,基于角度margin的损失函数,通过在角度空间引入边际提高特征的区分度
- Cepstrum (倒谱): 信号对数功率谱的傅里叶变换,用于分离激励和声道信息,是语音信号处理的重要工具
- DCF (Detection Cost Function): 检测代价函数,NIST提出的评估指标,考虑不同错误类型代价的加权组合
- EER (Equal Error Rate): 等错误率,误接受率和误拒绝率相等时的错误率,是声纹识别系统的关键性能指标
- ECAPA-TDNN: 强调通道注意力、传播与聚合的时延神经网络,集成了多种先进技术的说话人嵌入模型
- FFT (Fast Fourier Transform): 快速傅里叶变换,高效计算离散傅里叶变换的算法,是数字信号处理的基础
G-L术语解释
- GMM (Gaussian Mixture Model): 高斯混合模型,用多个高斯分布的线性组合建模数据分布的统计方法
- i-vector (Identity Vector): 身份向量,通过因子分析将可变长语音映射为固定维度向量的特征提取方法
- JFA (Joint Factor Analysis): 联合因子分析,同时建模说话人和信道变异的统计方法,是i-vector的前身
- Kaldi: 著名的开源语音处理工具包,基于C++实现,提供完整的ASR和说话人识别算法
- LPCC (Linear Prediction Cepstral Coefficients): 线性预测倒谱系数,基于声道模型的语音特征提取方法
- LibROSA: Python音频分析库,提供丰富的音频处理和特征提取功能,广泛用于研究和开发
M-P术语解释
- MFCC (Mel-Frequency Cepstral Coefficients): 梅尔频率倒谱系数,模拟人耳听觉特性的经典语音特征
- MAP (Maximum A Posteriori): 最大后验估计,用于GMM模型参数自适应的统计方法
- PIT (Permutation Invariant Training): 置换不变性训练,解决多输出任务中标签排列歧义问题的训练策略
- PLDA (Probabilistic Linear Discriminant Analysis): 概率线性判别分析,用于i-vector后处理的概率模型
R-T术语解释
- ResNet (Residual Network): 残差网络,通过引入跳跃连接解决深度网络退化问题的卷积神经网络架构
- ROC (Receiver Operating Characteristic): 受试者工作特征曲线,展示分类器在不同阈值下的性能变化
- RTF (Real-Time Factor): 实时因子,处理时间与音频时长的比值,用于衡量系统的实时性能
- SNR (Signal-to-Noise Ratio): 信噪比,信号功率与噪声功率的比值,通常用分贝(dB)表示
- STFT (Short-Time Fourier Transform): 短时傅里叶变换,对非平稳信号进行时频联合分析的方法
- SpeechBrain: 基于PyTorch的开源语音工具包,提供模块化的语音处理解决方案
- TDNN (Time Delay Neural Network): 时延神经网络,专门处理时序信息的神经网络架构,广泛用于语音处理
U-Z术语解释
- UBM (Universal Background Model): 通用背景模型,GMM-UBM框架中用于建模通用声学空间的高斯混合模型
- VAD (Voice Activity Detection): 语音活动检测,区分语音和非语音段的预处理技术
- VoxCeleb: 大规模说话人识别数据集,包含数千名名人的语音数据,是评估算法性能的标准数据集
- wav2vec 2.0: Facebook提出的自监督语音预训练模型,基于Transformer架构,能够学习强大的语音表示
- x-vector: 基于深度神经网络提取的说话人嵌入向量,是现代声纹识别系统的主流特征表示方法
- 声纹 (Voiceprint): 个人语音特征的总和,包括声学特征和发音模式,用于唯一标识说话人身份