西瓜书第五章——感知机

Numpy编写感知机对西瓜进行分类
使用感知机模型对西瓜种类进行分类:
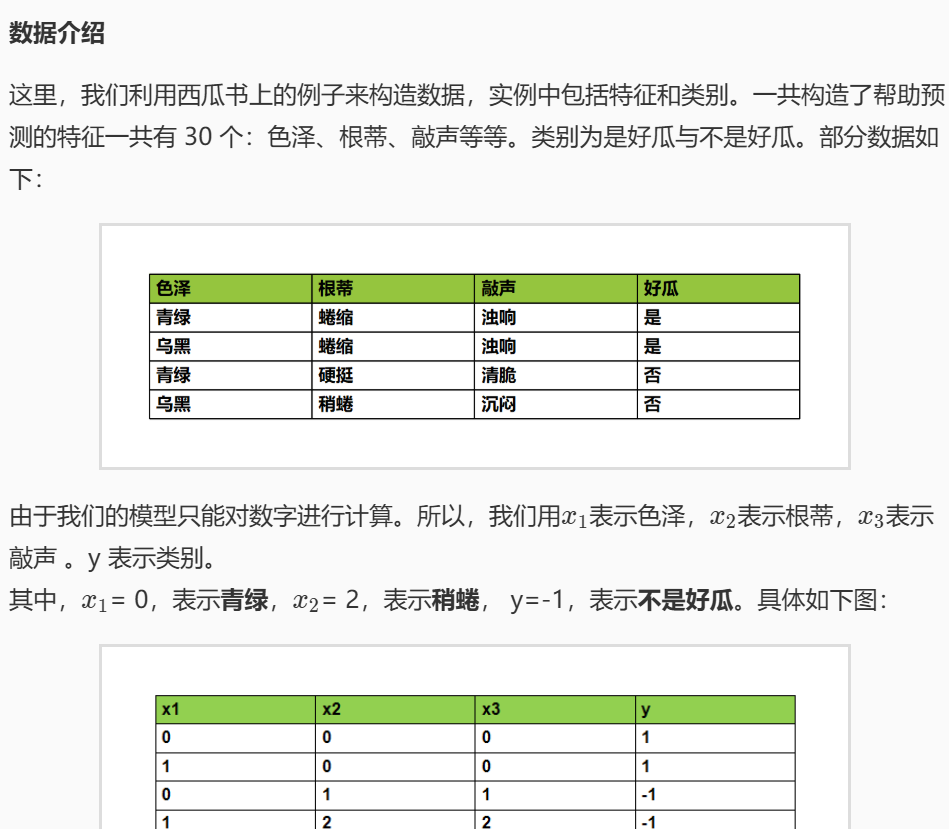
而我们的任务就是,用感知机算法建立一个模型,利用训练集上的数据对模型进行训练,并对测试集上的数据进行分类。

类似于SVM,决策为 y i ( w i x + b ) < 0 y_i(w_ix+b)<0 yi(wix+b)<0则分类错误,而 y i ( w x i + b ) > 0 y_i(wx_i+b)>0 yi(wxi+b)>0则分类正确

因此损失函数为 L ( w , b ) = − ∑ i ∼ M y i ( w x i + b ) L(w,b)=-\sum _{i\sim M} y_i(wx_i+b) L(w,b)=−∑i∼Myi(wxi+b)


需要注意的点
1.传入的data的形状是(m_samples, n_features),因此初始化w与b的时候需要取data.shape[1]获得特征维度
2.self.w与self.b不需要return,因此第一个函数不需要return
3.对于预测,首先需要初始化predict为一个数组[],然后对每个x_i运行self.w @ x_i +self.b(一次智能计算一个向量,然后是append push_back),最后return一个np.array
4.使用np.where(condition, x, y) 函数。np.where() 是 NumPy 提供的条件选择函数,根据条件从两个选项中选择返回值:
#encoding=utf8
import numpy as np
#构建感知机算法
class Perceptron(object):def __init__(self, learning_rate = 0.01, max_iter = 200):self.lr = learning_rateself.max_iter = max_iterdef fit(self, data, label):'''input:data(ndarray):训练数据特征 (m_samples, n_features)data.shape[0]=m_samples,data.shape[1]=n_featureslabel(ndarray):训练数据标签output:w(ndarray):训练好的权重b(ndarray):训练好的偏置'''#编写感知机训练方法,w为权重,b为偏置self.w=np.ones(data.shape[1])self.b=np.zeros(1)for _ in range(self.max_iter):for x_i,y_i in zip(data,label):if y_i*(self.w @ x_i + self.b)<=0:self.w -= -self.lr*y_i*x_iself.b -= -self.lr*y_i # self.w,self.b不需要return#********* Begin *********##********* End *********#def predict(self, data):'''input:data(ndarray):测试数据特征output:predict(ndarray):预测标签'''#********* Begin *********## 返回的测试结果需要时ndarray#x = self.w @ data +self.b 只能做一个sample的计算predict=[]for x_i in data:x = self.w @ x_i +self.bif x<=0:predict.append(-1)else:predict.append(1)#********* End *********#return np.array(predict)
def predict(self, data):'''input:data(ndarray):测试数据特征output:predict(ndarray):预测标签'''#********* Begin *********## 返回的测试结果需要时ndarray#x = self.w @ data +self.b 只能做一个sample的计算#********* End *********##另一个不需要逐行遍历预测的写法,使用np.dot()linear_output = np.dot(data,self.w)+self.bpredict = np.where(linear_output>=0,1,-1)return predict使用sklearn
#encoding=utf8
import os
import pandas as pd
from sklearn.linear_
model.perceptron import Perceptronif os.path.exists('./step2/result.csv'):os.remove('./step2/result.csv')#********* Begin *********#
#获取训练数据
train_data = pd.read_csv('./step2/train_data.csv')
#获取训练标签
train_label = pd.read_csv('./step2/train_label.csv')
train_label = train_label['target']
#获取测试数据
test_data = pd.read_csv('./step2/test_data.csv')clf = Perceptron(eta0=0.1,max_iter=500)
clf.fit(train_data, train_label)
result = clf.predict(test_data)pd.DataFrame(result,columns=['result']).to_csv('./step2/result.csv')
#********* End *********#