2024年ESWA SCI1区TOP,自适应学习灰狼算法ALGWO+无线传感器网络覆盖优化,深度解析+性能实测
目录
- 1.端午快乐
- 2.摘要
- 3.灰狼算法GWO原理
- 4.改进策略
- 5.结果展示
- 6.参考文献
- 7.代码获取
- 8.读者交流

1.端午快乐
今天端午节,祝各位朋友端午安康,阖家平安!
2.摘要
无线传感器网络(WSNs)是一种被广泛应用的新兴技术,但在实际应用中也面临诸多挑战。为了解决二维区域及更复杂的三维区域的覆盖优化问题,本文提出了一种自适应学习灰狼优化算法(ALGWO)。在 ALGWO 中,引入了动态反向学习策略与动态、非对称的搜索机制,以防止算法过早收敛,并提升其全局探索能力。此外,算法还采用了自适应维度学习策略,为个体提供邻域维度的信息,从而克服对前三只灰狼个体的依赖,提高种群的多样性。同时,每个个体在维度层面上自适应地执行探索与开发操作,以平衡全局搜索与局部优化的能力。
3.灰狼算法GWO原理
【智能算法】灰狼算法(GWO)原理及实现
4.改进策略
动态反向学习策略
GWO在求解问题时,初始解通常通过随机生成。如果初始解距离最优解较远,将影响算法的探索效率,导致收敛速度变慢。本文引入动态反向学习(DOL)策略,其通过根据随机数动态调整,将对称的搜索空间转变为非对称搜索空间。这种动态调整不仅有效防止算法跳过全局最优解,还能提升种群的多样性和探索能力。
X j O = U j + L j − X j X_j^O=U_j+L_j-X_j XjO=Uj+Lj−Xj
X j D O = X j + r 1 ∗ ( r 2 ∗ X j O − X j ) X_j^{DO}=X_j+r1*\left(r2*X_j^O-X_j\right) XjDO=Xj+r1∗(r2∗XjO−Xj)

自适应维度学习策略
邻域维度搜索策略通过扩大个体的搜索范围,有效提升了种群的多样性,促进了更优解的发现。基于维度学习的猎食搜索方法使个体能够从邻居处学习,避免陷入局部最优和多样性过早丧失,但在探索与利用的平衡方面仍存在不足。本文提出了自适应维度学习(ADL)策略。与传统灰狼算法仅依赖前三名领导狼位置不同,ADL通过共享个体之间的邻域信息,生成更具优势的候选解,从而增强了算法的全局搜索能力和种群多样性。
E D i ( t ) = ∥ X i ( t ) − X i − G W O ( t + 1 ) ∥ ED_i(t)=\|X_i(t)-X_{i-GWO}(t+1)\| EDi(t)=∥Xi(t)−Xi−GWO(t+1)∥
当 X i ( t ) X_i(t) Xi(t)与 X j ( t ) X_j(t) Xj(t)之间的距离小于 E D i ( t ) ED_i(t) EDi(t):
X i − N ( t ) = { X i ( t ) , ∥ X i ( t ) − X j ( t ) ∥ ≤ E D i ( t ) , X j ( t ) ∈ population } X_{i-N}(t)=\left\{X_i(t),\|X_i(t)-X_j(t)\|\leq ED_i(t),X_j(t)\in\text{population }\right\} Xi−N(t)={Xi(t),∥Xi(t)−Xj(t)∥≤EDi(t),Xj(t)∈population }
ADL策略能够根据迭代阶段自适应调整更新方式,实现探索与开发的动态切换,从而提升算法的整体效率和稳定性:
X i − A D L , d ( t + 1 ) = { X i , d ( t ) + r a n d ∗ ( X i − N , d ( t ) − X r 1 , d ( t ) ) , if r a n d < 1 − ( i t e r M a x i t e r ) X α , d ( t ) + r a n d ∗ ( X r 2 , d ( t ) − X r 3 , d ( t ) ) , otherwise X_{i-ADL,d}(t+1) = \begin{cases} X_{i,d}(t) + rand * \left( X_{i-N,d}(t) - X_{r1,d}(t) \right), & \text{if } rand < 1 - \left(\frac{iter}{Max_{iter}}\right) \\ X_{\alpha,d}(t) + rand * \left( X_{r2,d}(t) - X_{r3,d}(t) \right), & \text{otherwise} \end{cases} Xi−ADL,d(t+1)={Xi,d(t)+rand∗(Xi−N,d(t)−Xr1,d(t)),Xα,d(t)+rand∗(Xr2,d(t)−Xr3,d(t)),if rand<1−(Maxiteriter)otherwise

5.结果展示
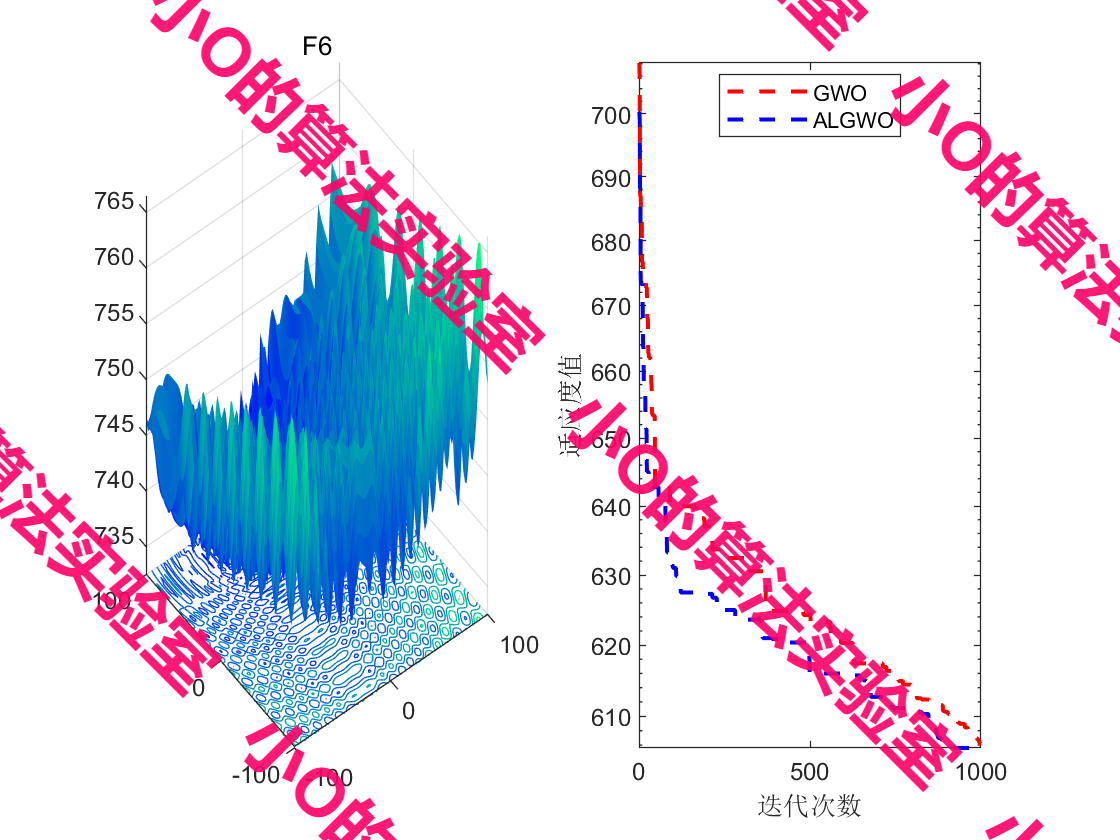
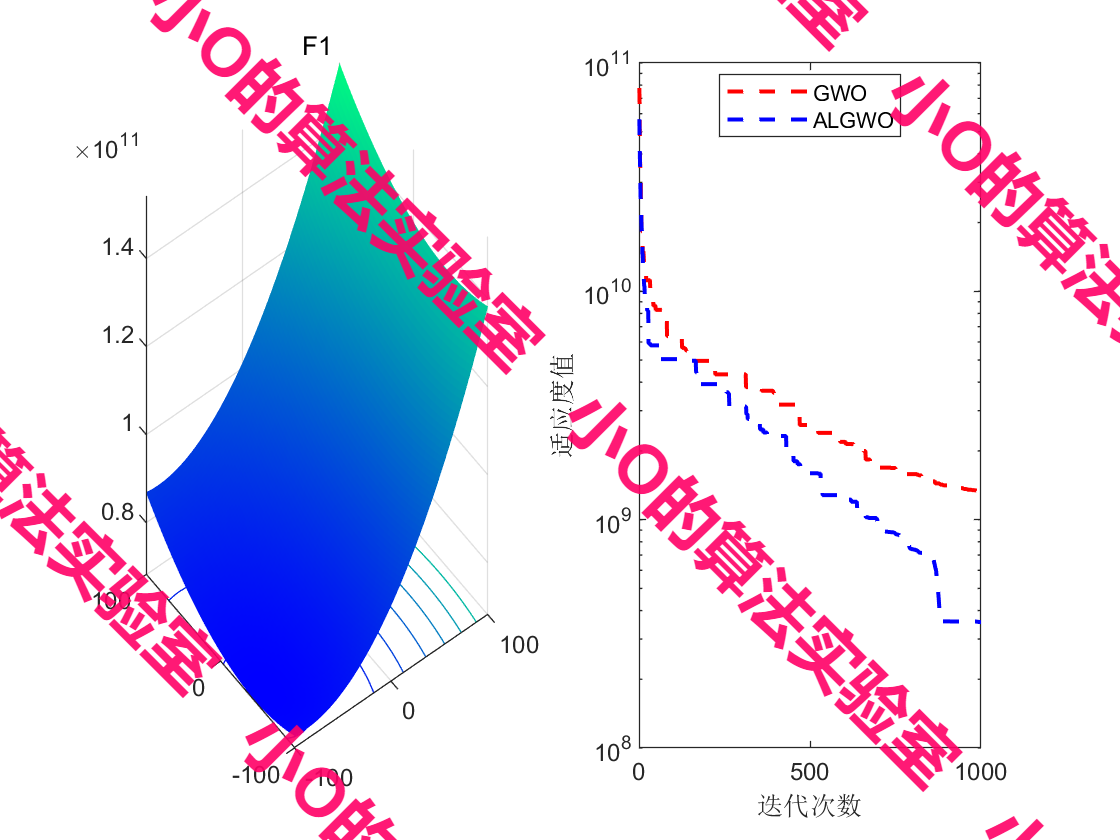
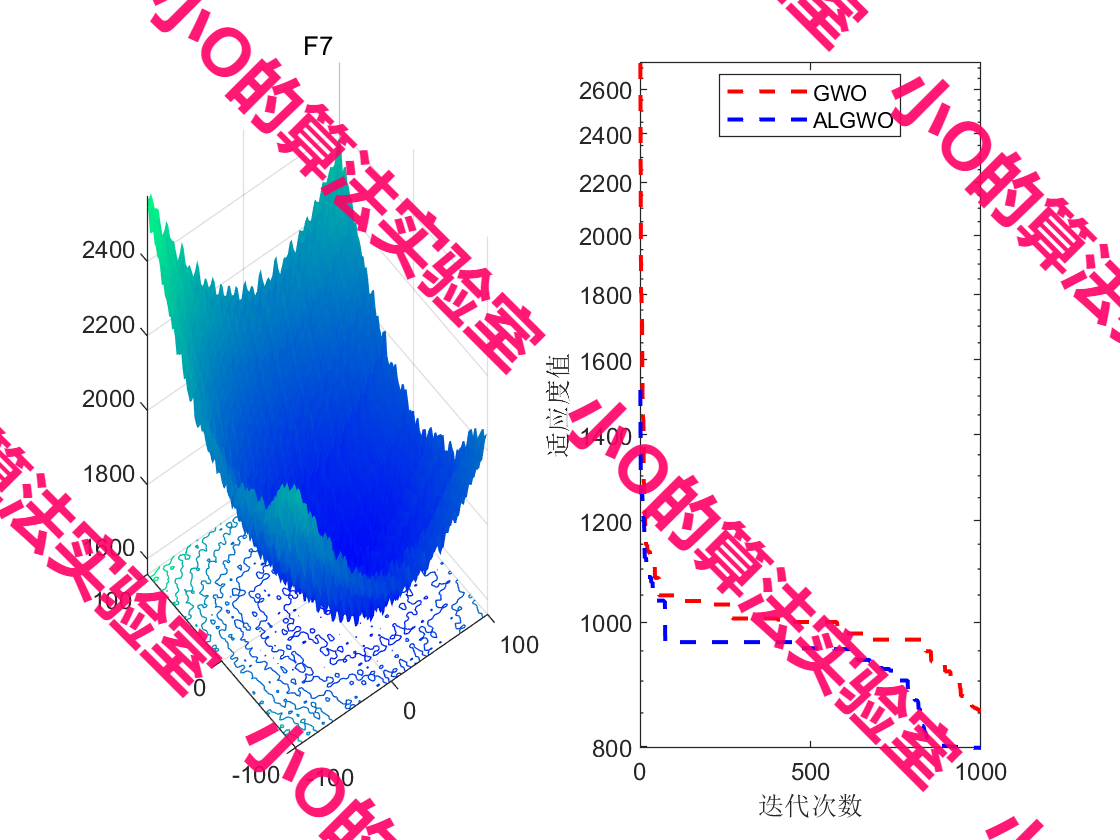
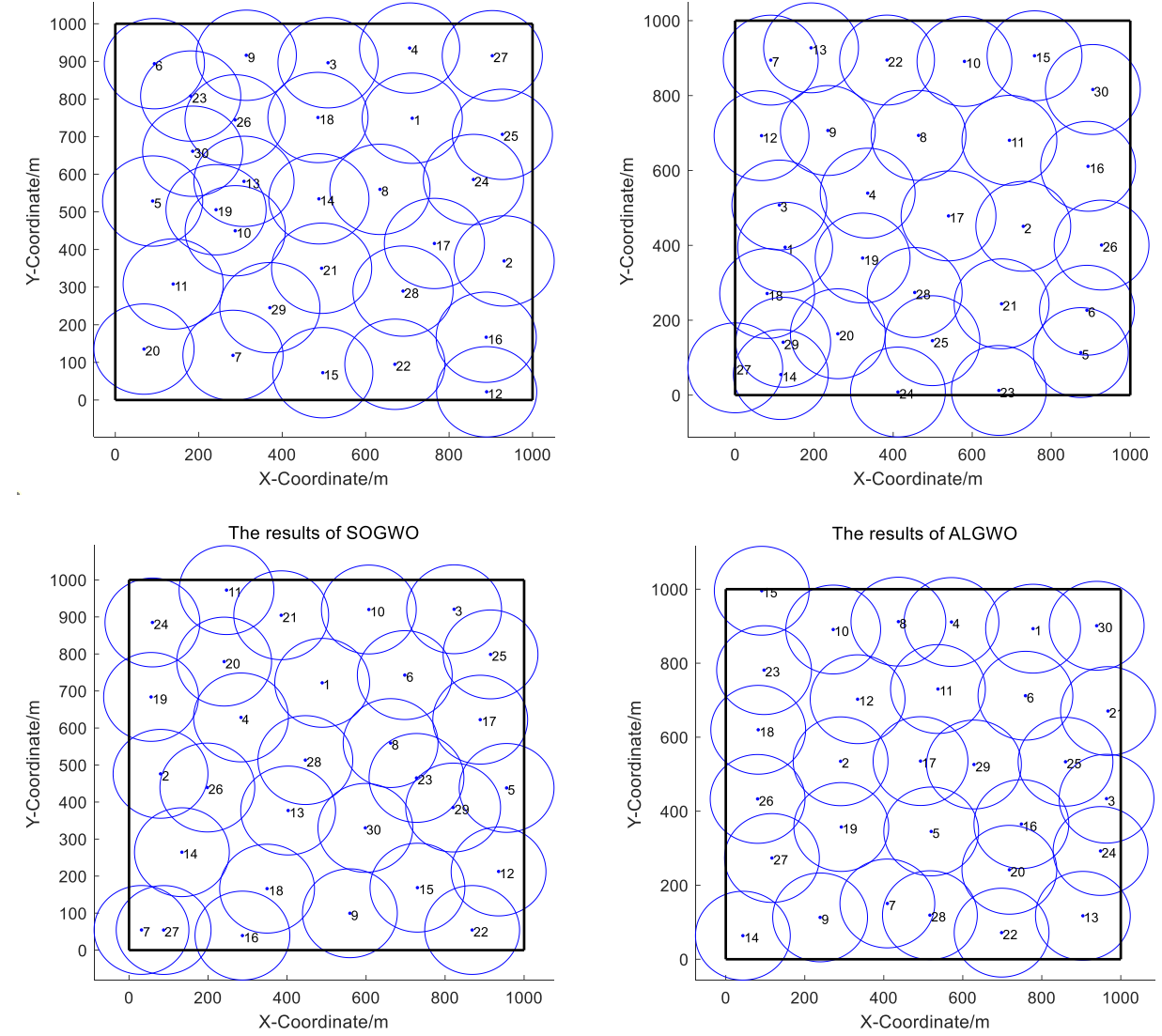
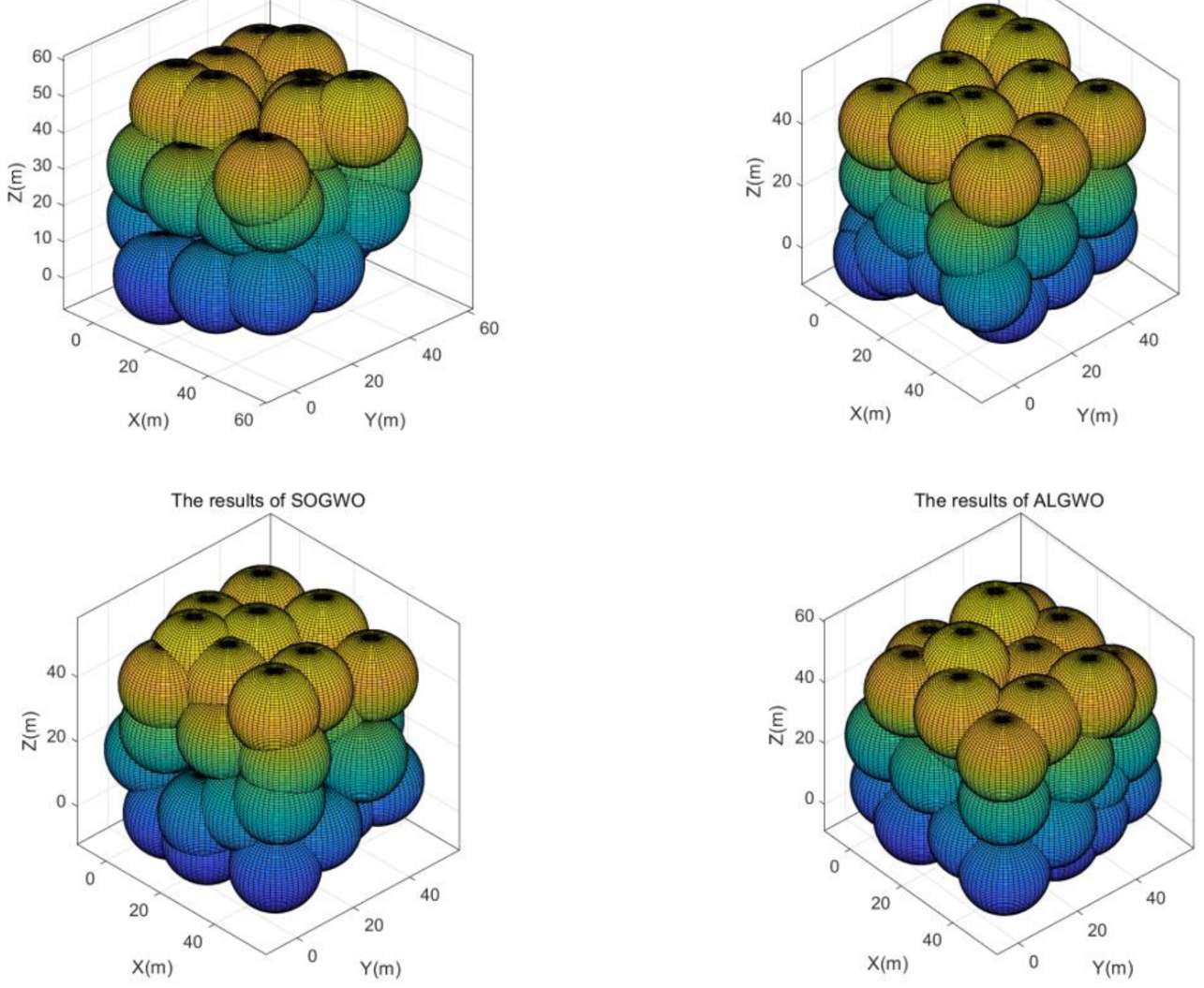
PS:
6.参考文献
[1] Yu X, Duan Y, Cai Z, et al. An adaptive learning grey wolf optimizer for coverage optimization in WSNs[J]. Expert systems with applications, 2024, 238: 121917.
7.代码获取
xx